使用DJL和PaddlePaddle的口罩检测详细指南
使用DJL和PaddlePaddle的口罩检测详细指南
完整代码
该项目利用DJL和PaddlePaddle的预训练模型,构建了一个口罩检测应用程序。该应用能够在图片中检测人脸,并将每张人脸分类为“戴口罩”或“未戴口罩”。我们将深入分析代码的每个部分,以便清晰了解每一步。
代码关键组件
-
缩放比例和置信度阈值配置:
scale:控制图像缩放比例;值越小检测速度越快,但精度会降低。可根据应用场景的精度要求调整。threshold:设定检测结果的最低置信度,用于过滤低置信度的检测结果。
-
人脸和口罩检测模型的初始化:
- 初始化
FaceDetection用于定位人脸区域,FaceMaskDetect则用于对检测出的人脸区域进行口罩状态的分类。
- 初始化
-
模型加载和预测:
- 使用DJL的
ZooModel类加载人脸检测和口罩分类模型。人脸检测模型识别图像中的人脸区域,分类模型判断每张人脸是否佩戴口罩。 - 遍历资源目录中的所有图像文件,分别进行检测和分类,并将结果保存和记录。
- 使用DJL的
优化后的代码讲解
以下是代码的改进版本,加入了详细的注释来说明每一步的操作:
@SneakyThrows
@Test
public void test1() {
// 设置人脸检测的缩放比例和置信度阈值
float scale = 0.5f; // 缩小图像尺寸,提升检测速度
float threshold = 0.7f; // 仅保留置信度大于0.7的检测结果
// 初始化人脸检测和口罩检测模型
FaceDetection faceDetection = new FaceDetection();
FaceMaskDetect faceMaskDetect = new FaceMaskDetect();
try (
// 加载人脸检测模型
ZooModel<Image, DetectedObjects> model = ModelZoo.loadModel(faceDetection.criteria(scale, threshold));
Predictor<Image, DetectedObjects> faceDetector = model.newPredictor();
// 加载口罩分类模型
ZooModel<Image, Classifications> classifyModel = ModelZoo.loadModel(faceMaskDetect.criteria());
Predictor<Image, Classifications> classifier = classifyModel.newPredictor()) {
// 遍历资源目录中的图像文件
for (File file : new File("src/test/resources").listFiles()) {
// 读取并处理图像
BufferedImage img = ImageIO.read(file);
Image image = ImageFactory.getInstance().fromImage(img);
// 使用人脸检测和口罩分类器进行预测
DetectedObjects detections = faceMaskDetect.predict(faceDetector, classifier, image);
// 保存检测结果,绘制边框并记录到指定目录
ImageUtils.saveBoundingBoxImage(image, detections, file.getName(), "build/output");
// 日志输出检测结果
logger.info("{}", detections);
}
}
}
各步骤详细解读
Step 1: 设置检测参数
scale参数控制图像缩放的比率。缩小图像的尺寸会提升检测速度,但可能会损失一些精度。该值可以根据需求灵活调整。
threshold参数设定了最小置信度,用于过滤低置信度的检测结果。例如,0.7的阈值意味着仅保留置信度在70%以上的结果。
Step 2: 初始化检测模型
这里分别初始化FaceDetection和FaceMaskDetect两个对象。FaceDetection对象用于人脸检测,即识别图像中的人脸位置。FaceMaskDetect对象则用于口罩检测,即对识别出的人脸区域进一步分类。
Step 3: 加载模型和初始化预测器
ModelZoo.loadModel(faceDetection.criteria(scale, threshold))通过criteria加载人脸检测模型,并将其转化为DJL的ZooModel对象。
Predictor<Image, DetectedObjects> faceDetector = model.newPredictor()创建一个Predictor,用于接收Image对象并返回人脸检测的DetectedObjects。
同样,口罩分类模型通过faceMaskDetect.criteria()加载,并使用Predictor<Image, Classifications>进行分类预测。
Step 4: 遍历图像文件
使用listFiles()方法遍历指定目录下的所有图像文件,以便逐个进行人脸检测和口罩分类。
Step 5: 执行人脸检测和口罩分类
faceMaskDetect.predict(faceDetector, classifier, image)方法同时使用人脸检测器faceDetector和分类器classifier,首先检测人脸位置,然后在检测到的人脸区域内进行口罩状态的分类。
Step 6: 保存检测结果
使用ImageUtils.saveBoundingBoxImage()方法,将检测结果绘制到图像上,并保存到build/output目录下。该方法会在图片上标注检测框及口罩状态,便于直观观察检测效果。
Step 7: 输出检测结果
使用日志记录检测结果,包含分类结果(“MASK” 或 “NO MASK”)、置信度、检测框的坐标和尺寸等信息。控制台示例输出如下:
运行效果示例
执行该代码后,在控制台中可以看到每张图片的检测结果,包括人脸位置和是否佩戴口罩的分类信息。以下是示例输出:
[INFO ] - [
class: "MASK", probability: 0.95524, bounds: [x=0.415, y=0.234, width=0.319, height=0.425]
]
[INFO ] - [
class: "MASK", probability: 0.99275, bounds: [x=0.274, y=0.226, width=0.412, height=0.523]
]
[INFO ] - [
class: "MASK", probability: 0.99931, bounds: [x=0.489, y=0.289, width=0.234, height=0.443]
]
[INFO ] - [
class: "NO MASK", probability: 0.99916, bounds: [x=0.489, y=0.311, width=0.171, height=0.395]
]
[INFO ] - [
]
[INFO ] - [
class: "MASK", probability: 0.99964, bounds: [x=0.190, y=0.187, width=0.309, height=0.538]
]
检测效果图示例
以下展示了原图和检测后的效果图:
| 原图 | 检测图 |
|---|---|
 |  |
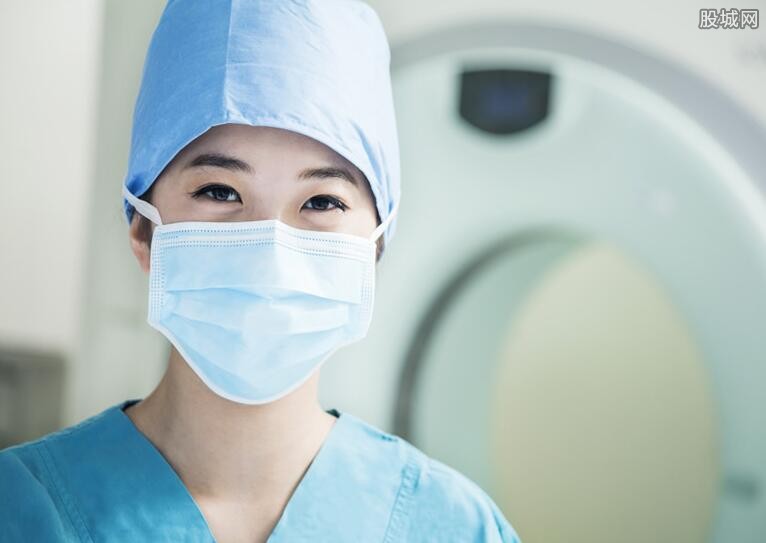 | 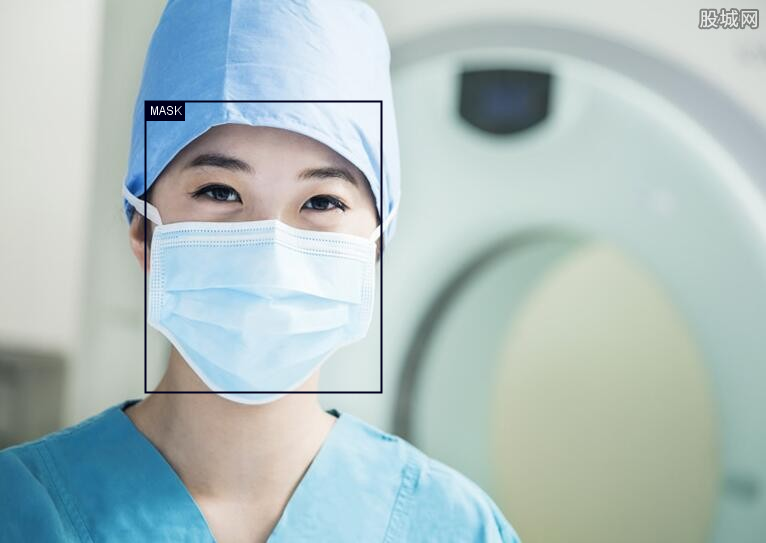 |
总结与优化建议
该系统能够精准地检测人脸并判断口罩佩戴状态,可应用于各类检测场景。可以根据实际需求,调整缩放比例scale和置信度阈值threshold以平衡速度和精度。
完整代码