八大排序总结

相信你坚持的,坚持你相信的!
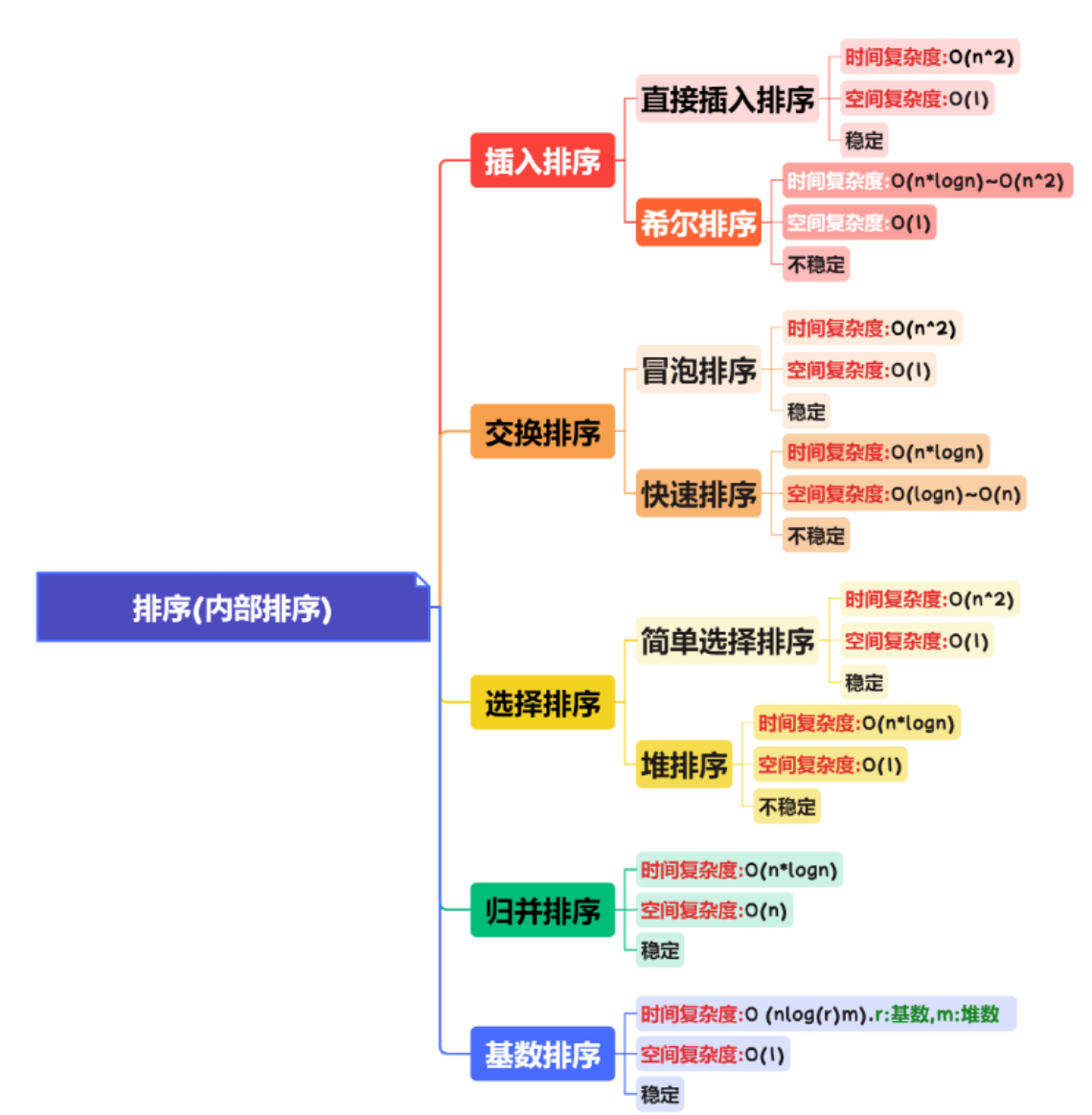
排序
| 排序 | 算法描述 | 时间复杂度 | 备注 | 空间复杂度 | 备注 | 稳定性 | 备注 |
|---|---|---|---|---|---|---|---|
| 直接插入排序 | 揭牌,从后往前找比当前数字小的,找到后插入到小数字后面,同时把大的数字往后挪 | O(n^2) | 越有序越快 | O(1) | 稳定 | ||
| 希尔排序 | 分组后进行插入排序,分组一般5,3,1 | O(n^1.3) | 利用直接插入排序越有序越快的特点 | O(1) | 稳定 | ||
| 冒泡排序 | 两两比较,大的往后走 | O(n^2) | O(1) | 稳定 | |||
| 快速排序 | 从后往前找小的,往前挪动,从前往后找大的,往后挪动 | O(nlogn) | 性能好,越有序越慢,一次划分的时间复杂度是O(n) | O(logn) | 不稳定 | ||
| 选择排序 | 每次选择一个最小的和待排序的数据交换 | O(n^2) | O(1) | 不稳定 | |||
| 堆排序 | 调整成为大根堆,然后把堆顶元素与最后一个元素交换,交换过的不用再次交换 | O(nlogn) | 系数大,如果想要空间复杂度小,选堆排 | O(1) | 不稳定 | ||
| 归并排序 | 将两段有序的数据合并成一段有序的数据,直到所有的数据有序 | O(nlogn) | 如果想要稳定,一般选归并 | O(n) | 稳定 | ||
| 基数排序(桶排序) | 所有的数据按照个位依次进桶,出桶,循环count次,count为最大值的位数 | O(d*n) | O(n) | 稳定 | 不处-号 |
排序的考点:
-
算法描述(会说)
-
代码的实现
-
各个排序的时间和空间复杂度,稳定性
稳定性:针对关键字相同的数据,排序前如果A在A1前面,排序后还能保证A在A1前面,则算法稳定,否则不稳定。
如果两个5的相对顺序不变,那么稳定,否则不稳定
判断方法:判断是否有跳跃式地交换数据

1.插入排序
-
插入排序,简单插入排序,直接插入排序(与理顺扑克牌类似)
-
O(N*N) O(1) 稳定
-
从后往前找比当前数字小的,找到后插入到小数字后面,同时把大的数字往后挪
-
直接插入排序的特点:越有序越快,完全有序为O(n);(考点) 在一组数据基本有序的情况下,用什么排序?直接插入排序
void InsertSort(vector<int>&v)//传引用
{
int j;
for (int i = 1;i < v.size();i++)//既是趟数,也是当前数字的下标
{
int tmp = v[i];//当前数字
for (j = i - 1;j >= 0;j--)//从后往前
{
if (v[j] > tmp)//从后往前找,如果前面的数字比当前数字大,大的往后移动
v[j + 1] = v[j];//
else
break;//找到比当前数字小的位置
}
v[j + 1] = tmp;//他的后一个数字应该是tmp
}
}
int main()
{
vector<int>v{ 6,8,10,17,0,-5,8,16,13,12 };
InsertSort(v);
for (auto i : v)
cout << i << " ";
return 0;
}
2.希尔排序
-
希尔排序:利用直接插入排序越有序越快的特点,然后进行分组直接插入排序排序
-
缩小分组:希尔排序又称为缩小增量分组, 分为5组,3组,1组
希尔排序核心思想就是:1,分组;2,直接插入排序:越有序越快
希尔排序就是多次利用直接插入排序的一个排序算法.
希尔排序的算法思想:间隔式分组,利用直接插入排序让组内有序,然后缩小分组再次排序,直到组数为1
希尔排序的理论基础就是直接插入排序越有序越快;
-
效率分析:时间复杂度O(n^1.3-n^1.5) 空间复杂度O(1) 稳定性:不稳定
//希尔排序:利用直接插入排序越有序越快的特点,然后进行分组直接插入排序排序
//间隔式分组
void One_Shell(vector<int>&v,int gap)//一趟希尔排序,把原数组间隔下来,直接插入排序的变体
{
int j;
for (int i = gap;i < v.size();i++)//大方向还是一个一个遍历
{
int tmp = v[i];
for (j = i - gap;j >= 0;j -= gap)//中间的细节是此数字的上一个gap数字
{
if (v[j] > tmp)
v[j + gap] = v[j];//大的往后移动
else
break;//找到位置
}
v[j + gap] = tmp;//替换
}
}
void Shell_Sort(vector<int>& v)
{
vector<int>group = { 5,3,1 };//分组数,每组数字间隔531,最后一个一定为1
for (int i = 0;i <group.size();i++)
One_Shell(v, group[i]);
}
int main()
{
vector<int>v{ 6,8,10,17,0,-5,8,16,13,12 };
Shell_Sort(v);
for (auto i : v)
cout << i << " ";
return 0;
}
3.冒泡排序
两两比较,大的数字往后走
效率分析:时间复杂度 O(n^2) 空间复杂度O(1) 稳定性:稳定
//3.冒泡排序
//两两比较,大的往后移动
void Bubble_Sort(vector<int>&v)
{
for (int i = 0;i < v.size();i++)
{
for (int j = 0;j +1< v.size()-i;j++)
{
if (v[j] > v[j + 1])
{
int tmp = v[j];
v[j] = v[j + 1];
v[j + 1] = tmp;
}
}
}
}
int main()
{
vector<int>v{ 6,8,10,17,0,-5,8,16,13,12 };
Bubble_Sort(v);
for (auto i : v)
cout << i << " ";
return 0;
}
4.选择排序
选择排序算法: 每次都从待排序中选出最小的一个和待排序的第一个数据交换; 选择排序代码实现:
效率分析:时间复杂度O(n^2) 空间复杂度O(1) 稳定性:不稳定
void SelectSort(int* arr, int len)//O(n^2),O(1),不稳定
{
int tmp;
int minIndex;//最小值的下标;
for (int i = 0; i < len - 1; i++)
{
minIndex = i;
for (int j = i + 1; j < len; j++)
{
if (arr[minIndex] > arr[j])
{
minIndex = j;
}
}
if (minIndex != i)
{
tmp = arr[minIndex];
arr[minIndex] = arr[i];
arr[i] = tmp;
}
}
}
5.快速排序(重点)
找到一个基准(第一个数据),
1)从后往前找比基准小的数据往前移动,
2)从前往后找比基准大的数据往后移动
3)重复1)和2)直到找到基准位置 这个就是快速排序的 一次划分
快速排序的缺点:越有序越慢,完全有序退化成选择排序,空间复杂度大,变成O(N^2) 不稳定
时间复杂度:O(nlogn)
空间复杂度:O(logn) 原因:使用了栈
int Partion(int* arr, int low, int high)
{
while (low < high)
{
//从后往前找小的,大的往后挪动
while (low<high && arr[high]>tmp)
{
high--;
}//找到了
if (low < high)
arr[low] = arr[high];//把小的数值往前挪
//从前往后找小的,小的往前挪动
while (low < high && arr[low] < tmp)
{
low++;
}//找到了
if (low < high)//把大的数值往后挪动
arr[high] = arr[low];
}
arr[low] = tmp;
return low;
}
void Quick(int* arr, int low, int high)
{
int par = Partion(arr, low, high);//par是下标,是经过一次划分过后的下标
if (low < par - 1)//如果左边超过一个数据
Quick(arr, low, par - 1);
if (par + 1 < high)//如果右边超过一个数据
Quick(arr, par + 1, high);
}
//递归地调用快速排序
void QuickSort(int* arr, int len)//对外表现都是两个参数,自己内部需要三个参数,自己内部解决
{
Quick(arr, 0, len - 1);//把下标传进去
}
int main()
{
int arr[] = { 12,3,4,5 };
QuickSort(arr, sizeof(arr) / sizeof(arr[0]));
for (int i = 0;i < sizeof(arr) / sizeof(arr[0]);i++)
printf("%d ", arr[i]);
return 0;
}
6.堆排序
-
建立 大根堆的时间复杂度: O(n) 堆调整 的时间复杂度是O(logn) 空间复杂度:O(1) 不稳定
一些基本概念:
-
叶子:没有子节点的节点叫叶子节点
-
大根堆:所有的父亲大于儿子
-
小根堆:所有的儿子大于父亲
-
父亲于儿子的的下标关系:
父亲的下标为i ,那么左孩子的下标为2*i+1,右孩子的下标为2i+2
子的下标是i ,父的下标为(i-1)/2
-
图解:调整成一次大根堆,可以使一个数据有序
-
用哪一个排序可以快速找到第k大的数字 :堆排序
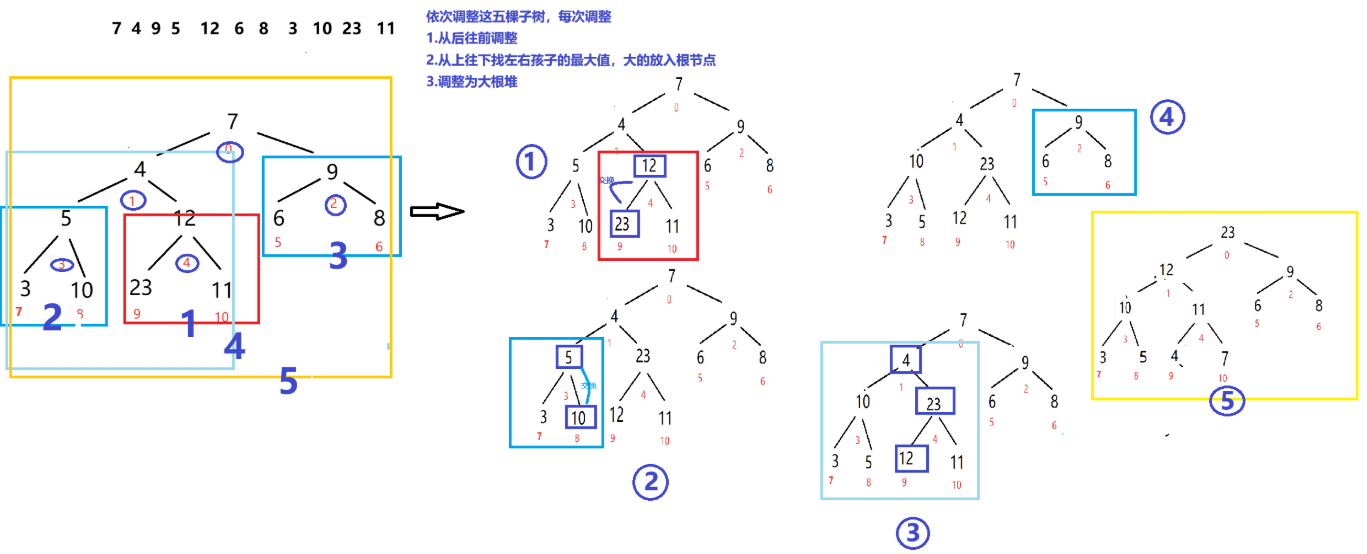
void HeapAdjust(int* arr, int start, int end)//堆调整,从倒数第二层开始调整
{
int tmp = arr[start];//先把start的值保存下来,要不然丢失数据
//先找左孩子,2*strat+1,
for (int i = 2 * start + 1; i <= end; i = 2 * i + 1)
{
//把i定位为左右孩子的最大值下标
if (i < end && arr[i] < arr[i + 1])//有右孩子,并且左孩子的值小于右孩子
{
i++;
}//i一定是左右孩子的最大值
//找到左右孩子的最大值后
if (arr[i] > tmp)
{
arr[start] = arr[i];//把左右孩子的最大值给strat
start = i;//start赋值为i
}
else
{
break;//如果越界,跳出循环
}
}
arr[start] = tmp;//最后把原来start的值给补上
}
void HeapSort(int* arr, int len)//堆排序,O(nlogn),O(1),不稳定
{
int i;//数组下标
//第一次建立大根堆,从后往前,多次调整
//子是i,父是(子-1)/2
for (i = (len - 1 - 1) / 2; i >= 0; i--)//O(n)数学证明
//这个i是倒数第二层根的下标,比如说有11个数字,那么要从4下标开始调整
{
HeapAdjust(arr, i, len - 1);//第一次建立大根堆
//这里的len-1,不影响调整,放大了不影响
}
//每次将0下标的数字和待排序的最后一个交换,然后再次调整 堆调整的时间复杂度是logn
int tmp;//临时变量
for (i = 0; i < len - 1; i++) //O(nlogn) 11个数字交换10次
{
//交换
tmp = arr[0];
arr[0] = arr[len - 1 - i];//len-1-i是因为调整好了的数字不要再动了
arr[len - 1 - i] = tmp;
//再次调整
HeapAdjust(arr, 0, len - 1 - i - 1);//堆调整
//len-1-i-1的解释:len-1-i是要交换的数字,交换完的数字不需要再参加调整
}
}
7.归并排序
-
时间复杂度:O(nlogn) 空间复杂度O(n),稳定
//一次归并
//gap:归并段的长度
static void Merge(int* arr, int len, int gap)//O(n),O(n)
{
int low1 = 0;//第一个归并段的起始下标
int high1 = low1 + gap - 1;//第一个归并段的结束下标
int low2 = high1 + 1;//第二个归并段的起始下标
int high2 = low2 + gap <len ? low2+gap-1:len-1;//第二个归并段的结束下标
int* brr = (int*)malloc(len * sizeof(int));//存放归并好的数据
assert(brr != NULL);
int i = 0;//i为brr的下标
//有两个归并段
while (low2 < len)
{
//两个归并段都还有数据,需要比
while (low1 <= high1 && low2 <= high2)
{
if (arr[low1] <= arr[low2])
{
brr[i++] = arr[low1++];
}
else
{
brr[i++] = arr[low2++];
}
}
//一个归并段的数据已经完成了,另一个还有数据
while (low1 <= high1)
{
brr[i++] = arr[low1++];
}
while (low2 <= high2)
{
brr[i++] = arr[low2++];
}
//下两个归并段
low1 = high2 + 1;
high1 = low1 + gap - 1;
low2 = high1 + 1;
high2 = low2 + gap < len ? low2 + gap - 1 : len - 1;
}
//只有一个归并段
while(low1 < len)
{
brr[i++] = arr[low1++];
}
//将归并好的数据拷贝到arr中
for (i = 0; i < len; i++)
{
arr[i] = brr[i];
}
free(brr);
}
//归并排序
void MergeSort(int* arr, int len)//O(nlog n),O(n),稳定
{
for (int i = 1; i < len; i *= 2)//O(log n)
{
Merge(arr, len, i);
}
}
8.基数排序
基数排序的效率分析: O(n),O(n),稳定; 注:基数排序不能处理负数;
void RadixSort(int* arr, int len)//O(d*n),O(n),稳定的
{
//需要利用10个队列,存放进队的数字
HNode queArr[10];//定义10个队头
for (int i = 0; i < 10; i++)
{
InitQueue(&queArr[i]);
}
//得到最大数字的位数,确定入队和出队的趟数
int count = GetFigur(arr, len);
int index;//队列的下标
for (int i = 0; i < count; i++)//i有两层含义:1.控制趟数2.处理每个数字从右往左的第i个数字
{
//入队
for (int j = 0; j < len; j++)//遍历arr数组并入队
{
index = GetNum(arr[j], i);//index是保存arr[j]应该进入的队列的下标
Push(&queArr[index], arr[j]);//将数字放入对应的队列
}
//依次出队
int j = 0;//arr的下标
for (int k = 0; k < 10; k++)
{
while (!IsEmpty(&queArr[k]))
{
Pop(&queArr[k], &arr[j++]);
}
}
}
for (int i = 0; i < 10; i++)
{
Destroy(&queArr[i]);
}
}
//获取最大数字的位数
static int GetFigur(int* arr, int len)
{
int max = arr[0];//max保存最大值
for (int i = 0; i < len; i++)
{
if (max < arr[i])
{
max = arr[i];
}
}
//丢弃个位
int count = 0;
while (max != 0)
{
count++;
max /= 10;
}
return count;
}
//获取十进制整数右数第figur位的数,figur从0开始
//例如(123,0)->3,(123,1)->2,(123,2)->1,(123,3)->0
static int GetNum(int n, int figur)
{
for (int i = 0; i < figur; i++)
{
n /= 10;
}
return n % 10;
}