yolov8涨点系列之Concat模块改进
文章目录
- Concat模块修改步骤
- (1) BiFPN_Concat3模块编辑
- (2)在__init_.py+conv.py中声明
- (3)在task.py中声明
- yolov8引入BiFPN_Concat3模块
- yolov8.yaml
- yolov8.yaml引入C2f_up模块
在YOLOv8中,
concat模块主要用于将多个特征图连接在一起。其具体介绍如下:
- 作用:
- 增强特征表达:通过将不同层次的特征图进行组合,能够捕捉到更多的上下文信息,从而增强模型对目标的理解能力,显著提高目标检测的准确性和效率。不同层次的特征图包含了不同尺度和语义级别的信息,将它们拼接起来可以让模型综合利用这些信息进行更准确的预测。
- 应用位置:通常出现在网络的不同层次之间,比如在YOLOv8的颈部(neck)部分经常会使用到
concat操作。在颈部,需要对来自骨干网络(backbone)不同阶段的特征图进行融合,以便更好地检测不同大小的目标。例如,将低分辨率但富含语义信息的特征图与高分辨率但语义信息较少的特征图进行拼接,从而形成一个更大的输出特征图,这种跨层连接的方式能够同时兼顾细节和感知范围。 - 实现方式:在PyTorch等深度学习框架中,
concat操作可以通过torch.cat函数实现,一般是沿着某个维度(如通道维度)将多个特征图拼接起来。但在实际应用中,由于YOLO架构中的不同层可能具有不同的空间分辨率,所以在concat之前,通常需要对特征图进行上采样或下采样以匹配所需的尺寸。
以YOLOv8中的C2f模块为例,它包含了concat操作。首先对输入的特征图进行一次卷积使其通道数变为原来的两倍,然后将其拆分成两部分,一部分进入多个bottleneck模块进行处理,另一部分直接传递到后续的拼接操作。最后,将所有bottleneck模块的输出以及之前直接传递的那部分特征图进行拼接,增加特征的多样性,之后再通过一个卷积层将拼接后的特征图通道数压缩到所需的输出通道数。
Concat模块修改步骤
(1) BiFPN_Concat3模块编辑
Concat模块位置位于ultralytics/nn/modules/conv.py内,如下图所示:

class Concat(nn.Module):
"""Concatenate a list of tensors along dimension."""
def __init__(self, dimension=1):
"""Concatenates a list of tensors along a specified dimension."""
super().__init__()
self.d = dimension
def forward(self, x):
"""Forward pass for the YOLOv8 mask Proto module."""
return torch.cat(x, self.d)
改进后代码:
class BiFPN_Concat3(nn.Module):
def __init__(self, dimension=1):
super(BiFPN_Concat3, self).__init__()
self.d = dimension
# 设置可学习参数 nn.Parameter的作用是:将一个不可训练的类型Tensor转换成可以训练的类型parameter
# 并且会向宿主模型注册该参数 成为其一部分 即model.parameters()会包含这个parameter
# 从而在参数优化的时候可以自动一起优化
self.w = nn.Parameter(torch.ones(3, dtype=torch.float32), requires_grad=True)
self.epsilon = 0.0001
def forward(self, x):
w = self.w
weight = w / (torch.sum(w, dim=0) + self.epsilon) # 将权重进行归一化
# Fast normalized fusion
x = [weight[0] * x[0], weight[1] * x[1], weight[2] * x[2]]
return torch.cat(x, self.d)
(2)在__init_.py+conv.py中声明
在这里插入图片描述


(3)在task.py中声明

yolov8引入BiFPN_Concat3模块
yolov8.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
yolov8.yaml引入C2f_up模块
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 6 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 6, 12], 1, BiFPN_Concat3, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/8-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/16-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
改进前:

改进后:
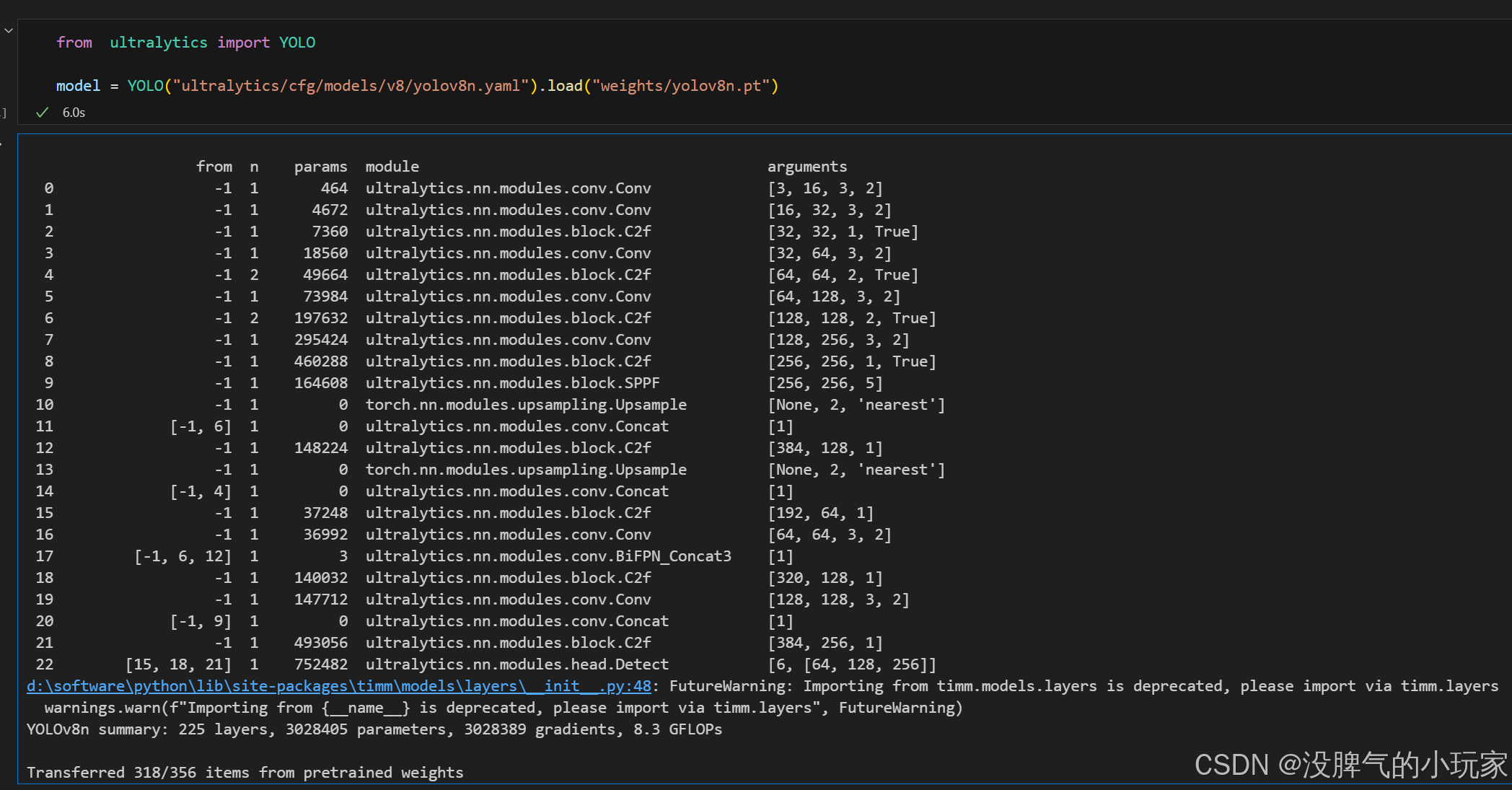
YOLOv8的concat模块与BiFPN模块融合具有多方面的好处:
- 增强多尺度特征融合能力:
- 更全面的信息整合:
concat模块主要是将不同层次的特征图进行连接,能捕捉到多尺度的上下文信息,但简单的连接可能无法充分考虑不同特征的重要性差异。BiFPN模块引入了双向连接,允许信息在不同分辨率级别之间双向传播,使得高层语义信息和低层细节信息能够更充分地交互和融合。与concat模块融合后,不仅能将多尺度特征图连接起来,还能通过BiFPN的双向路径更好地整合这些特征,让模型更全面地理解不同大小的目标,提高对多尺度物体的检测性能。- 例如,对于远处的小目标,通过BiFPN的双向信息传播,可以将高层的语义信息传递到低层,增强对小目标特征的理解,再结合
concat模块将不同尺度特征图连接起来,有助于更准确地检测小目标。
- 自适应特征调整:BiFPN采用加权特征融合机制,拥有可学习的权重参数来调整不同层级特征的贡献程度。在与
concat模块融合后,可以根据不同任务和数据的特点,自适应地调整融合后的特征,使得重要的特征得到更突出的表达,进一步提高特征的质量和有效性。相比之下,单纯的concat操作对所有特征的融合是平等对待的,缺乏这种自适应调整能力。
- 更全面的信息整合:
- 提高模型的准确性和鲁棒性:
- 优化特征传递:
concat模块在连接特征图时,只是简单地将它们拼接在一起,但在特征传递过程中可能会存在信息丢失或不充分利用的情况。BiFPN模块的引入可以改善这种情况,其独特的网络结构和连接方式能够优化特征在不同层级之间的传递,使特征的传递更加高效和准确。与concat模块融合后,能够更好地利用和传递特征信息,减少信息的损失,从而提高模型的准确性。 - 增强模型的鲁棒性:在复杂的场景中,目标的大小、形状、姿态等变化多样,对模型的鲁棒性提出了很高的要求。
concat模块与BiFPN模块的融合可以使模型更好地适应这些变化,通过多尺度特征融合和优化的特征传递,能够更准确地识别和定位不同形态的目标,提高模型在复杂场景下的检测能力和鲁棒性。
- 优化特征传递:
- 提升模型的灵活性和可扩展性:
- 灵活的模块组合:将
concat模块与BiFPN模块融合,可以根据具体的需求和任务进行灵活的调整和优化。例如,可以根据不同的数据集和目标检测任务,调整BiFPN的层数、节点连接方式以及concat模块的连接位置和方式,以获得更好的性能。这种灵活性使得模型能够适应不同的应用场景,提高了模型的通用性和可扩展性。 - 易于与其他模块集成:BiFPN模块的模块化设计使其易于与其他模块集成,与
concat模块融合后,也可以方便地与其他改进模块或技术相结合,如注意力机制、残差连接等,进一步提升模型的性能。这种可扩展性为模型的不断优化和改进提供了便利,使得模型能够不断适应新的挑战和需求。
- 灵活的模块组合:将