GBase与梧桐数据库窗口函数使用的比较
一、前言
窗口函数可以进行复杂的数据分析,使数据处理变得更加灵活和强大。通过这些函数,用户可以在不同的窗口范围内对数据进行汇总、平均、计数等操作,以下介绍一些常用的窗口函数分别在梧桐数据库和GBase数据库中的使用。
二、创建测试用例
为更好的体现函数的使用,现创建一个测试表来验证各类窗口函数的使用及返回结果;
1、建表
-- gbase数据库建表create table rows_test ( user_id varchar(10), --用户idprod_id varchar(10), --产品idsale_cnt decimal(10,0) --销售数量);-- 梧桐数据库建表create table rows_test ( user_id character varying(10), --用户idprod_id character varying(10), --产品idsale_cnt numeric(10,0) --销售数量);
2、测试用例
insert into rows_test values('AAA','pd_1',2),
('AAA','pd_2',5),
('BBB','pd_1',1),
('BBB','pd_2',2),
('BBB','pd_3',3),
('CCC','pd_1',3),
('CCC','pd_3',4),
('DDD','pd_1',2),
('DDD','pd_3',4);--梧桐数据库与GBase数据插入语法相同
三、排序类窗口函数
1、简介
排序类窗口函数常用的有 row_number()、rank()、dense_rank();
-
row_number():为每个行分配一个唯一的连续整数,从1开始。它不会为任何行跳过数字,即使有并列(ties)也不会跳过;
-
rank() :在遇到并列时会为相同的值分配相同的排名,并且后续的排名会跳过已使用的数字。例如,如果有两行并列第一,它们的排名都是1,下一行的排名会是3,而不是2;
-
dense_rank():在处理并列时会为相同的值分配相同的排名,并且下一个排名会紧接着上一个排名,即使有并列也不会跳过数字;
2、函数使用
以产品 ‘prod_1’ 的销售数量对用户进行排名,分别使用上述函数实现:
梧桐数据库与GBase数据库语法相同,不做重复赘述
select *,row_number() over(partition by prod_id order by sale_cnt desc) row_id from rows_test ;select *,rank() over(partition by prod_id order by sale_cnt desc) rank_id from rows_test ;select *,dense_rank() over(partition by prod_id order by sale_cnt desc) dense_rank_id from rows_test ;
梧桐数据库执行结果
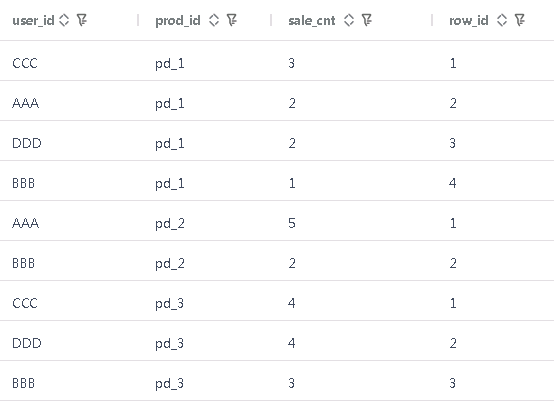
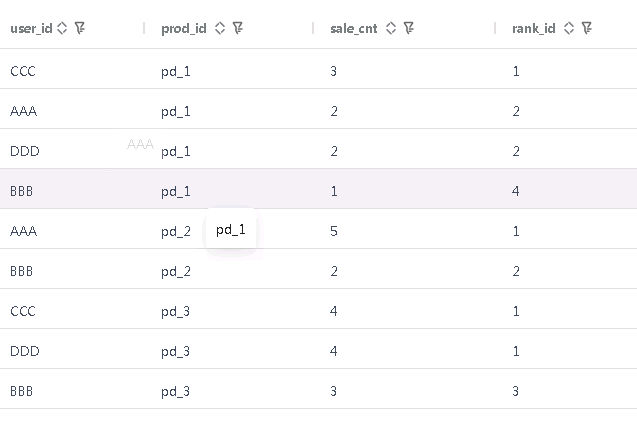
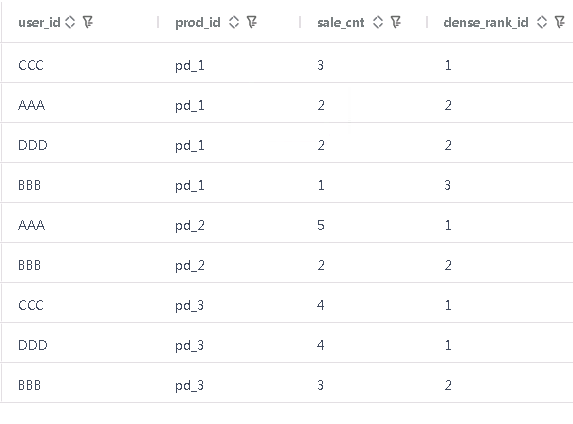
GBase 执行结果
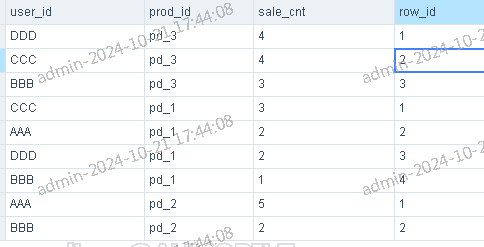
-
over子句用来定义窗口的分区及排序方式 -
partition by定义排序分区 -
order by定义排序方式
如上结果:
row_number() 会为每一行赋予一个整数不会跳过,当排序条件相同时,会随机一行排序;
rank()在排序条件相同时会赋予相同的值,下一个值会跳过;
dense_rank()在排序条件相同时会赋予相同的值,下一个值会接上一个;
四、统计类窗口函数
统计类窗口函数常用的有 count()、sum()、avg()、max()、min() 等,其效果与聚合函数相同,具体如下:
-
sum(column_1):对column_1字段求和,字段必须是整型或浮点型; -
count(column_1):对column_1字段计数; -
avg(column_1):对column_1字段求平均值,字段必须是整型或浮点型; -
max(column_1):对column_1字段求最大值,字段是整型或浮点型,也可是字符串; -
min(column_1):对column_1字段求最小值,字段是整型或浮点型,也可是字符串;
示例:
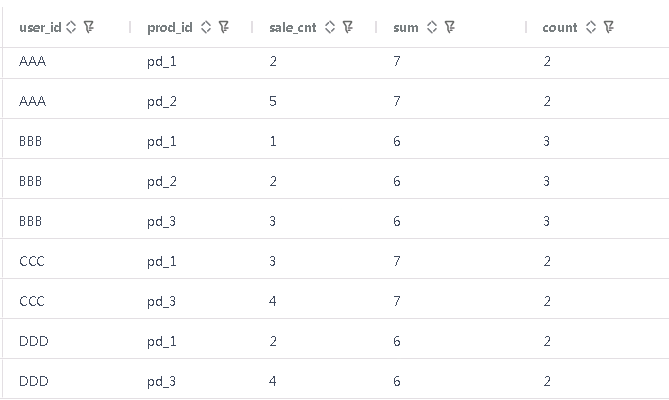
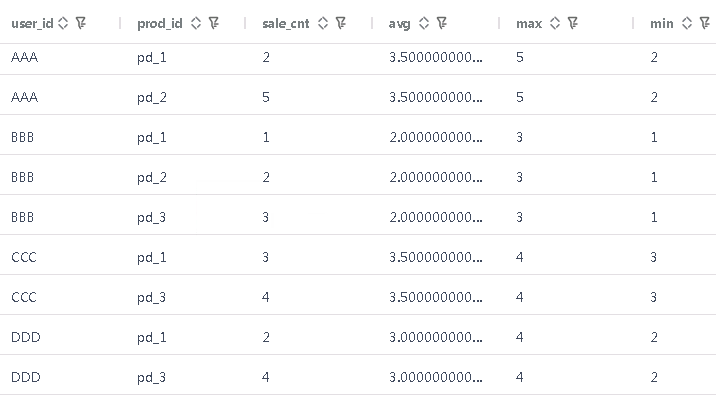
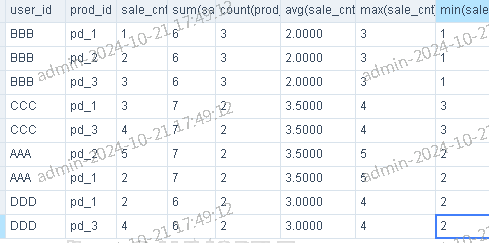
select *,sum(sale_cnt) over (partition by user_id),count(prod_id) over (partition by user_id),avg(sale_cnt) over (partition by user_id),max(sale_cnt) over (partition by user_id),min(sale_cnt) over (partition by user_id)from rows_test
示例解释:
-
sum(sale_cnt) over (partition by user_id)以用户id为分区计算销量的和,返回值为用户所有产品销量的和; -
count(prod_id) over (partition by user_id)以用户id为分区计算销售产品数量,返回值为用户销售的产品个数; -
avg(sale_cnt) over (partition by user_id)以用户id为分区计算销售产品销量的平均值,返回值为用户平均每个产品的销量; -
max(sale_cnt) over (partition by user_id)以用户id为分区计算产品最大销量,返回值为用户销售最多的产品个数; -
min(sale_cnt) over (partition by user_id)以用户id为分区计算销售产品数量,返回值为用户销售最少的产品个数;
梧桐数据库测试结果如图:
五、总结
对比梧桐数据库与GBase数据窗口函数的语法及使用基本相同,其避免了使用子查询或连接,可以显著提高查询性能;提供了对数据进行灵活分析的能力,可以轻松适应不同的数据分析需求,增强了数据的分析能力;
窗口函数的应用场景也非常广泛,可以用于各种数据分析和处理任务;例如通过排序类函数可以计算套餐销量top;地市、区县业务发展情况的top等;汇总、累计类函数可以统计用户出账等收入分析。