Selenium 使用指南:从基础到反爬虫的实践
掌握Selenium
文章目录
- 掌握Selenium
- 复杂动态网页解决方案
- Selenium简介
- Selenium + chromedriver 安装
- 打开自动化浏览器
- 初始化机器人
- 访问url——browser.get(url)
- 全屏打开网页——browser.maximize_window()
- 关闭窗口——browser.close()
- 指定selenium参数
- 需要的库
- 网页元素定位
- 获取元素的属性值
- opt.add_argument('--disable-blink-features=AutomationControlled')
- 理由解析
- 常见的自动化检测机制
- 代码示例
- 结论
- 输入和点击
- 登录校园网
- 设置元素等待及加载策略
- 设置webdriver等待
- 隐式等待
- 显式等待
- 使用显式等待
- EC模块支持的条件
- 使用EC的方法
- 循环访问元素
- 切换窗口
- 固定模板
- 切换句柄handles(网页)
- 打开新的页面/窗口
- 切换表单---frame
- 退出表单回到页面
- 动作链
- 什么是动作链
- 把鼠标悬停在车票上
- 执行一系列连续的动作
- 勾选selsect类
- 常用动作链
- 案例 -- 查询车票
- 反检测方法
- stealth.min.js文件
- 下载地址
- 执行脚本
- debugging模式
- 创建并配置浏览器
- 详细配置步骤
- 爬虫-反爬-反反爬
- 常见反爬手段
- 反反爬
- user-agent
- IP代理
- cookie
复杂动态网页解决方案
直接抓包分析调用的接口,然后通过代码请求这个接口。
- 优点:可以直接请求到数据,不需要做一些解析工作,代码量少,性能高
- 缺点:分析接口比较复杂,特别是一些通过js混淆的接口,需要is逆向功底
使用Selenium+ chromedriver模拟浏览器行为获取数据
- 优点:浏览器能请求到的数据,使用sclenium也能请求到,爬虫更稳定,且适用于所有类型的动态渲染网页。
- 缺点:代码量多,性能低,容易被反爬:
这里针对的就是一些比较火的网址,像是京东,淘宝等等,都有反爬技术,对于小白而言,没有js逆向技术,就是痴人说梦
比如下面的这些接口,使用了js混淆技术,根本不知道原来的信息是什么了
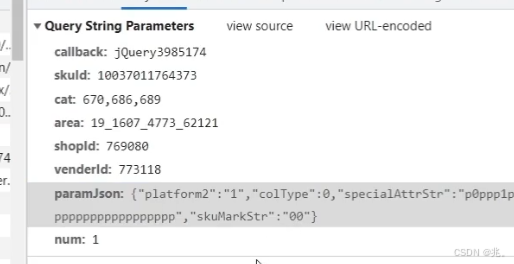
所以提供了一个比较笨拙但是能用的方法——浏览器driver——浏览器机器人,模拟用户访问浏览器
Selenium简介
Selenium相当于是一个机器人。可以模拟人类在浏览器上的一些行为,自动处理浏览器上的一些行为,比如点击,填充数据,删除cookie等。
chromedriver是一个驱动Chrome浏览器的驱动程序,针对不同的浏览器有不同的driver。
Selenium + chromedriver 安装
-
安装Selenium: 在命令行输入 pip install selenium
-
安装chromedriver:
先下载chromedriver.exe,注意版本要和Chrome浏览器对应
http://chromedriver.storage.googleapis.com/index.htm
将安装文件Python解释器安装目录
Selenium相关资料:
https://selenium-python.readthedocs.io/
打开自动化浏览器
初始化机器人
from selenium import webdriver
from selenium.webdriver.edge.service import Service
service = Service(executable_path=fr'D:\Python\msedgedriver.exe')
browser = webdriver.Edge(service=service)
第一个是selenium模块的webdriver这个类
然后第二行是webdriver方法+浏览器类型+service
第三行是定位机器人的文件位置,也就是导入机器人的驱动
第四行是初始化机器人
访问url——browser.get(url)
先把url写好了
使用browser.get()的方法可以打开网址
不过打开的页面一般是占半个屏幕的网页,想要全屏打开还需要有另外的方法
全屏打开网页——browser.maximize_window()
想要全屏打开这个网页,需要在打开网页之前,给机器人传给命令
browser.maximize_window()
这句话一定要在browser.get(url)之前
关闭窗口——browser.close()
browser.close()
这个是浏览器关闭,运行此方法时会关闭窗口
指定selenium参数
我们可以对打开的浏览器窗口进行操作
import time
from numpy.f2py.rules import options
from selenium import webdriver
from selenium.webdriver.edge.service import service, Service
from selenium.webdriver.edge.options import Options
url = 'https://www.csdn.net/'
url1 = 'https://www.bilibili.com/'
service = Service(fr'D:\Python\msedgedriver.exe')
opt = Options()
opt.add_argument('--disable-blink=features=AutomationControlled') # 这个参数可以隐藏机器人的痕迹,降低反爬的概率
browser = webdriver.Edge(service=service,options=opt) # opt里面就是参数,传给了机器人browser
# browser.maximize_window() # 全屏打开窗口
browser.set_window_position(500,20) # 设置窗口打开的位置,分别是打开页面的左上角xy像素点
browser.set_window_size(800,800) # 设置打开窗口的大小
browser.get(url) # 打开链接
time.sleep(2)
browser.get(url1) # 打开新链接还是在已有的窗口里面,会覆盖上面的网址
time.sleep(1)
browser.back() # 回退页面,也就是关闭当前网页url1,回到之前的网页url
time.sleep(1)
browser.forward() # 向前页面,也就是url1出现,url消失
time.sleep(1)
browser.refresh() # 刷新页面
time.sleep(1)
page_text = browser.page_source # 获取当前页面源代码
print(page_text)
browser.close() # 关闭一个标签
time.sleep(2)
browser.quit() # 关闭整个浏览器
需要的库
from selenium.webdriver.edge.options import Options
- 页面回退——browser.back()
- 页面前进——browser.forward()
- 刷新页面——browser.refresh()
- 关闭浏览器——browser.quit()
- 关闭一个页面——browser.close()
- 获取网页源代码——browser.page_source——源代码需要接收一下
- 设置页面的位置——browser.set_window_position(500,20)
- 设置页面的大小——browser.set_window_size(800,800)
网页元素定位
就是我们针对网页特定位置进行操作,比如搜索框等等
需要引入头文件:
from selenium.webdriver.common.by import By
定位的方法:
-
根据ID定位: driver.find_element(By.ID, ‘ID’)
-
根据class定位: driver.find element(By.CLASS_NAME, ‘CLASS_NAME’)
-
根据标签名定位: driver.find element(By.TAG NAME, ‘TAG_NAME’)
-
根据CSS选择器定位: driver.find_element(By.CSS SELECTOR, ‘CSS_SELECTOR’)
-
根据name定位: driver.find _element(By.NAME, 'NAME)
-
使用XPath定位: driver.find_element(By.XPATH, ‘XPATH’)
-
根据链接文本定位: driver.find element(By.LINK_TEXT, ‘LINK TEXT’)
加粗的是常用方法
获取元素的属性值
在定位到网页元素之后,可以使用get_attribute(‘属性名’)的方式得到属性值
opt.add_argument(‘–disable-blink-features=AutomationControlled’)
添加 opt.add_argument('--disable-blink-features=AutomationControlled') 是一种常见的方法,用于帮助绕过网站的自动化检测机制。具体来说,这个参数的作用有以下几点:
理由解析
-
干预 Blink 特性:
- Blink 是 Chromium (Chrome 和基于 Chromium 的浏览器如 Edge) 使用的渲染引擎。
--disable-blink-features=AutomationControlled的主要作用是禁用某些对自动化行为的检测特性。 - 当启动浏览器时,这个标志会关掉特定功能,比如
navigator.webdriver属性的设置。这通常会使网站检测不到你正在使用 Selenium 或其他自动化工具。
- Blink 是 Chromium (Chrome 和基于 Chromium 的浏览器如 Edge) 使用的渲染引擎。
-
模拟真实用户行为:
- 通过移除
AutomationControlled特性,网站将更难识别出你正在使用自动化工具。浏览器会表现得更像是普通用户使用的实例,而不是一个被自动化程序控制的实例。
- 通过移除
-
提高成功率:
- 对于一些网站而言,简单地通过改变 User-Agent 或隐藏 WebDriver 特征可能不足以完全避免检测。而这个参数可以显著提高你的请求成功率。
常见的自动化检测机制
- 许多现代网站使用综合的检测机制,包括但不限于:
- 检查 HTTP 请求头(如 User-Agent、Referer 等)。
- 监测脚本环境,寻找特征标识(如
navigator.webdriver)。 - 检查浏览器的行为模式,譬如是否存在诸如
window对象上被注入的函数。
代码示例
若要使用该参数,只需在设置 Selenium 的选项时添加它,如下所示:
from selenium import webdriver
from selenium.webdriver.edge.service import Service
from selenium.webdriver.edge.options import Options
service = Service(r'D:\Python\msedgedriver.exe')
opt = Options()
opt.add_argument('--disable-blink-features=AutomationControlled')
opt.add_argument("user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36")
browser = webdriver.Edge(service=service, options=opt)
browser.maximize_window()
url = 'https://bot.sannysoft.com/'
browser.get(url=url)
结论
通过添加 --disable-blink-features=AutomationControlled 参数,您大大减少了被检测为自动化工具的机会。虽然这并不能保证100%绕过所有网站的防爬虫措施,但它是一个有效的工作解决方案。持续监测网站的反爬虫技术变化,并根据需要调整你的代码实现是关键。
输入和点击
对一个元素进行点击,或者向这个元素里面输入内容
-
点击元素 元素.click() 首先需要对元素定位,才能点击
-
输入内容 元素.send_keys(‘python爬虫工程师’,Keys.ENTER) 这里是向元素输入内容,然后使用Keys库,模拟键盘的操作
from selenium.webdriver.common.keys import Keys这是模拟键盘控制的头文件
import time
from numpy.f2py.rules import options
from selenium import webdriver
from selenium.webdriver.edge.service import service, Service
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys # 模拟键盘的控制,这里可以使用回车
url = 'https://www.bilibili.com/'
service = Service(fr'D:\Python\msedgedriver.exe')
opt = Options()
opt.add_argument('--disable-blink=features=AutomationControlled') # 这个参数可以隐藏机器人的痕迹,降低反爬的概率
browser = webdriver.Edge(service=service,options=opt) # opt里面就是参数,传给了机器人browser
browser.maximize_window() # 全屏打开窗口
browser.get(url) # 打开链接
time.sleep(2)
zhanghao_element = browser.find_element(By.XPATH,'//*[@id="nav-searchform"]/div[1]/input') # 定位网页的元素位置
zhanghao_element = browser.find_element(By.CSS_SELECTOR,'#nav-searchform > div.nav-search-content') # 复制元素的selector格式,这里也选择ByCSS。。。
zhanghao_element = browser.find_element(By.ID,'nav-searchform')
zhanghao_element.click() # 模拟鼠标点击一次定位的元素
zhanghao_element.send_keys('python爬虫工程师',Keys.ENTER) # 第一个参数向标签输入的内容,第二个是对文本框的操作
time.sleep(5)
1~13行的代码,基本上就是当前板块必备的内容了
19行到21行,是根据不同信息定位同一个标签的各种方式,分别是xPath,CSS,ID
25行是在B站的搜索框里面输入信息,接着一个回车,这里使用了selenium库的Keys模块,可以模拟键盘的输入
登录校园网
import time
from selenium import webdriver
from selenium.webdriver.edge.service import service, Service
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
url = 'http://10.200.0.11:9999/portal.do?wlanuserip=10.2.108.190&wlanacname=NFV-BASE&mac=2c:33:58:f6:af:d6&vlan=2720341&hostname=%C3%CE%D5%D7&rand=1bfc5c224edfe9a&url=http%3A%2F%2Fwww.msftconnecttest.com%2Fredirec'
service = Service(fr'D:\Python\msedgedriver.exe')
opt = Options()
opt.page_load_strategy = 'eager'
opt.add_argument('--disable-blink=features=AutomationControlled')
browser = webdriver.Edge(service=service,options=opt)
browser.get(url)
zhanghao_element = browser.find_element(By.XPATH,'//*[@id="userid"]')
zhanghao_element.click()
zhanghao_element.send_keys(f'2022984150305',Keys.ENTER)
mima_element = browser.find_element(By.XPATH,'//*[@id="passwd"]')
mima_element.click()
mima_element.send_keys(f'010215',Keys.ENTER)
denglu_element = browser.find_element(By.XPATH,'//*[@id="loginsubmit"]')
denglu_element.click()
time.sleep(2)
browser.close()
刚学爬虫的时候就有这个想法,感觉每次登录校园网挺麻烦的,一开始以为使用requests.get可以完成,把账户和密码填在对应的接口,
放在headers里面发送出去,但是失败了,因为网站使用了js技术,不能直接输入信息,现在学了这个selenium,暂时完成了这个需求
我的解决方法:初始化机器人,填充账户密码,这里可以直接把账户密码写上,就不需要创建别的文件夹了,这里我是为了做成一个大家
都能使用的独立程序
然后就是定位网页元素,填充信息,再模拟鼠标点击登录,就ok了
设置元素等待及加载策略
针对的问题是:打开浏览器的时候,由于网络原因或者网站自己的原因,一直在等待缓冲,我们只想获取一些信息,不需要完全加载出来,如果使用time模块,时间太短没效果,时间太长会造成浪费
所以提出了页面加载策略
页面加载策略一共分为三种:
-
normal:(默认):完整地加载。把get地址的页面及所有静态资源都下载完(如css、图片、is等)
-
eager: 等待初始HIML文档完全加载和解析,并放弃样式表、图像和子框架的加载。
-
none: 仅等待初始页面下载。从现象来看就是打开浏览器输入网址然后不管了。
使用方式:
在初始化后面再加一句
opt.page_load_strategy = 'eager'
这个也算初始化的一部分了,后面的就是加载策略,确实可以加快时间
设置webdriver等待
很多页面都使用 ajax 技术,页面的元素不是同时被加载出来的,为了防止定位这些尚在加载的元素报错,可以设置元素等来增加脚本的
稳定性。webdriver 中的等待分为 显式等待 和隐式等待。这两个等待有一个就行,不要混合使用
隐式等待
隐式等待也是指定一个超时时间,如果超出这个时间指定元素还没有被加载出来,就会抛出 NoSuchElementException 异常。除了抛出
的异常不同外,还有一点,隐式等待是全局性的,即运行过程中,如果元素可以定位到,它不会影响代码运行,但如果定位不到,则它会
以轮询的方式不断地访问元素直到元素被找到,若超过指定时间,则抛出异常。
implicitly_wait(等待时间) 以秒为单位
这个语句在机器人初始化之后使用,就可以使用none加载策略了,也就是机器人一但获取到指定的信息就立即执行下一步,也可以是退出
显式等待
设置一个超时时间,每个一段时间就去检测一次该元素是否存在,如果存在则执行后续内容,如果超过最大时间(超时时间)则抛出超时异
常(TimeoutException)。显式等待需要使用 WebDriverWait,同时配合 until 或not until
try.
element = WebDriverWait(driver, 10).until(
EC.presence of element located((By.lD, "myDynamicElement"))
finally:
driver.quit()
显示等待需要的头文件:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC # as EC是起别名
第一个就是显式等待的模块
第二行是判断元素条件的模块
使用显式等待
把两个模块导入之后,在对页面元素操作之前
使用WeDriverWait模块,第一个参数写浏览器对象,第二个参数是最大的等待时间
在上面这个模块后面还可以加一个条件,让程序等到什么元素出现(until),或者说不等到什么出现(until_not)
这个判断条件就使用EC模块里面的条件
EC模块支持的条件

比如第三个presence_of_element_located()就是判断这个元素是否被加载出来
还有第六个,text_to_be_present_in_element()。用来判断元素的文字内容是否被加载出来
还有第四个,visibility_of_element_located()判断元素是否可见
还有element_to_be_clickable()元素是否可以被点击
还可以判断当前页面的标题是不是指定的页面title_is()
visibility_of_all_element_located 判断是不是所有的元素都可见
使用EC的方法
在EC判断之前,要先以元组的形式把要判断的元素对象储存在变量里面,也就是上面的locator
储存方式:locator=(By.XPATH,‘浏览器元素地址’)
然后把这个变量放在EC判断条件里面
当程序执行到这里的时候,会先判断locator在不在,在就继续下一步,不在就等待,直到超出设定的时间抛出错误
当然我们不希望程序抛出错误,然后挂掉,所以可以使用try,except
隐式等待是全局的,只需要设置一次,而显式等待比较麻烦,但是也比较灵活
循环访问元素
因为一个元素的标签相对于网页整体的改动很小,也就是说,一个页面的功能按键基本上会保持在同一个位置
使用for循环可以循环点击一个按钮,实现翻页的效果
切换窗口
在当我们点击页面按钮时,它一般会打开一个新的标签页,但实际上代码并没有切换到最新页面中,这时你如果要定位新页面的标签就会
发现定位不到,这时就需要将实际窗口切换到最新打开的那个窗口。
我们先获取当前各个窗口的句柄,这些信息的保存顺序是按照时间来的,最新打开的窗口放在数组的末尾,这时我们就可以定位到最新打
开的那个窗口了。
driver.switch_to.window(driver.window_handles[-1]) 切换句柄到最新的窗口,想要回到最初的页面就把-1改成0
固定模板
意思是学到这里,我们已经有了一些基本的架构了
import time
from selenium import webdriver
from selenium.webdriver.edge.service import Service
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.by import By
service = Service(fr'D:\Python\msedgedriver.exe')
opt = Options()
opt.add_argument('--disable-blink-features=AutomationControlled')
browser = webdriver.Edge(service=service,options=opt)
url = 'https://www.bilibili.com/'
browser.get(url=url)
比如这个实现对网页的打开的代码
切换句柄handles(网页)
有的网站是点开下一页或者点击某个内容时会弹出新的窗口
在之前我们是再次访问新的url来进行页面爬取,现在是使用的selenium
我们使用click对网页元素进行点击,再使用switch_to.window(browser.window_handles[-1])来访问最新产生的页面
最外层的函数是切换页面函数,里面的页面的列表,浏览器页面的排列是以时间为顺序的,最开始是窗口是0,从0开始,所以最新的页面是[-1]
这时候就可以对新打开的网页进行操作了
对网页操作完之后,如果是对原网页的循环点击,还需要再切换回去!
打开新的页面/窗口
使用browser.switch_to.new_window(‘tab’)这个函数可以打开一个新页面
再使用browser.get()就可以打开一个新网页了,并且把driver自动追踪到新的页面
针对的就是使用click点击网页还需要手动切换的问题
一个browser只能操作一个页面
browser.switch_to.new_window(‘window’) 这是打开一个新窗口
切换表单—frame
很多页面也会用带 frame/iframe 表单嵌套,对于这种内嵌的页面 selenium 是无法直接定位的,需要使用 switch to.frame() 方法将当前
操作的对象切换成 frame/iframe内嵌的页面。
switch to.frame()默认可以用的id 或 name 属性直接定位,但如果iframe 没有id 或name,这时就需要使用xpath 进行定位。
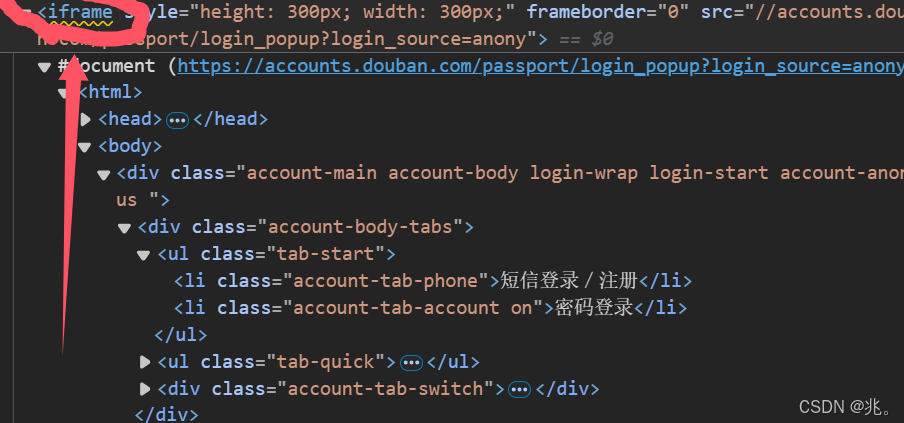
这个主要解决的就是页面的内嵌表单无法直接定位的问题
解决方法:把句柄切换到内嵌表单,才能访问元素
具体方法:使用driver.switch_to.frame(locator) 把焦点(句柄)切换到frame窗口
需要把这个网页的iframe 的路径提前储存在locator里面
import time
from selenium import webdriver
from selenium.webdriver.edge.service import Service
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.by import By
service = Service(fr'D:\Python\msedgedriver.exe')
opt = Options()
opt.add_argument('--disable-blink-features=AutomationControlled')
browser = webdriver.Edge(service=service,options=opt)
url = 'https://www.douban.com/'
browser.maximize_window()
browser.implicitly_wait(4) # 隐式等待,等待4秒
browser.get(url=url)
locator = browser.find_element(By.XPATH, '//*[@id="anony-reg-new"]/div/div[1]/iframe')
browser.switch_to.frame(locator)
browser.find_element(By.XPATH,'/html/body/div[1]/div[1]/ul[1]/li[2]').click()
time.sleep(2)
剩下的填充账号密码和之前的操作一样,先定位,再填充
在每一个对元素操作的间隔最好是写个time.sleep,毕竟真人在输入的时候肯定要有时间的啦,不能太快
退出表单回到页面
在表单里面操作完成之后,还想在原网页进行操作,可以使用下面的函数就能回去了
driver.switch_to.default_content()
动作链
什么是动作链
用selenium做爬虫,有时候会遇到需要模拟鼠标和键盘操作才能进行的情况,比如单击、双击、点击鼠标右键、拖拽、滚动等等。而
selenium给我们提供了一个类来处理这类事件–ActionChains()
- 准备的库
from selenium.webdriver.common.action_chains import ActionChains
把鼠标悬停在车票上
- 使用ActionChains类
- 使用move_to_element()方法
- 执行perform
ticket_element = browser.find_element(By.XPATH, '//*[@id="J-chepiao"]/a')
ActionChains(browser).move_to_element(ticket_element).perform()
先是定位元素ticket_element
然后执行动作链
执行一系列连续的动作
chufadi_element = browser.find_element(By.XPATH, '//*[@id="fromStationText"]')
ActionChains(browser)\
.click(chufadi_element)\
.pause(1)\
.send_keys('北京')\
.pause(1)\
.send_keys(Keys.ARROW_DOWN,Keys.ARROW_DOWN)\
.pause(1)\
.send_keys(Keys.ENTER)\
.perform()
这里对一个输入框进行了连续的多个操作,使用了‘\‘来换行,使用’.‘来说明使用的什么方法
这里面还参杂了pause(1)这是一个等待方法,就是在操作的时候停顿几秒,太快的话容易被检测出来,导致页面挂掉
勾选selsect类
在订票页面发现选择时间段的元素使用了select类,和frame一样,都是需要给selenium指定一下
对select类对象定位完成之后,有很多方法可以选择select选择
常用动作链
- move_to_element()
将鼠标移动到指定element,参数为标签。 - move_by_offset(xoffset, yoffset)
将鼠标移动到与当前鼠标位置的偏移处。参数为X轴Y轴上移动的距离。(距离单位为像素,可以通过截图的方式来把握距离。) - click()
点击一个标签。 - scrol_to_element(iframe)
鼠标滚轮滚动到某个元素 - scroll_by_amount(0, delta_y)
鼠标滚轮安装偏移量滚动 - perform()
执行所有存储的操作。因为行为链是一系列的动作,上边的命令不会写一个执行
一个,执行要通过perform(命令来全部执行。 - context_click(element)
右键点击一个标签 - click_and_hold(element)
点击且不松开鼠标 - double_click(element)
双击。 - drag_and_drop(source, target)
按住源元素上的鼠标左键,然后移动到目标元素并释放鼠标按钮 - drag_and_dropby_offset(source, xoffset, yoffset)
按住源元素上的鼠标左键,然后移动到目标偏移并释放鼠标按钮 - release(on_element=None)
在元素上释放按住的鼠标按钮 - key_down(value, element=None)
按下某个键盘上的键 - key_up(value, element=None)
松开某个键
案例 – 查询车票
import time
from selenium import webdriver
from selenium.webdriver.edge.service import Service
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.select import Select # 针对的是时间段的select类
service = Service(fr'D:\Python\msedgedriver.exe')
opt = Options()
opt.add_argument('--disable-blink-features=AutomationControlled')
opt.add_experimental_option('excludeSwitches',['enable-automation']) # 和上面的一样都是隐藏selenium的痕迹
opt.add_experimental_option("detach", True) # 防止浏览器自动退出的opt参数
browser = webdriver.Edge(service=service,options=opt)
url = 'https://www.12306.cn/index/index.html'
browser.maximize_window()
browser.implicitly_wait(4) # 隐式等待,等待4秒
browser.get(url=url)
# 把鼠标悬停在车票元素上
ticket_element = browser.find_element(By.XPATH, '//*[@id="J-chepiao"]/a')
ActionChains(browser).move_to_element(ticket_element).perform()
# 点击车票下面的单程选项
one_way_element = browser.find_element(By.XPATH, '//*[@id="megamenu-3"]/div[1]/ul/li[1]/a')
ActionChains(browser).click(one_way_element).perform()
# 向出发地的那个框输入出发地
chufadi_element = browser.find_element(By.XPATH, '//*[@id="fromStationText"]')
ActionChains(browser)\
.click(chufadi_element)\
.pause(1)\
.send_keys('石家庄')\
.pause(1)\
.send_keys(Keys.ARROW_DOWN,Keys.ARROW_DOWN)\
.pause(1)\
.send_keys(Keys.ENTER)\
.perform()
# 同理在目的地输入
mudidi_element = browser.find_element(By.XPATH, '//*[@id="toStationText"]')
ActionChains(browser)\
.click(mudidi_element)\
.pause(1)\
.send_keys('哈尔滨')\
.pause(1)\
.send_keys(Keys.ARROW_DOWN)\
.pause(1)\
.send_keys(Keys.ENTER)\
.perform()
# 勾选车次
checi_element = browser.find_element(By.XPATH, '//*[@value="G"]').click()
# 输入出发日期
chufari_element = browser.find_element(By.XPATH, '//*[@id="train_date"]')
ActionChains(browser)\
.click(chufari_element)\
.pause(1)\
.send_keys(Keys.ARROW_RIGHT,Keys.BACK_SPACE*10)\
.send_keys('2024-11-15',Keys.ENTER)\
.perform()
# 修改发车时间
start_time_element = browser.find_element(By.XPATH, '//*[@id="cc_start_time"]') # 先是定位这个select类
Select(start_time_element).select_by_visible_text('06:00--12:00')
# 查询车票
chaxun_element = browser.find_element(By.XPATH, '//*[@id="query_ticket"]').click()
这里主要涉及了三个知识点:鼠悬停,打开select类,动作链
反检测方法
stealth.min.js文件
stealth.min.js文件来源于puppeteer,有开发者给puppeteer 写了一套插件,叫做puppeteer-extra。其中,就有一个插件叫做
puppeteer-extra-plugin-stealth专门用来让puppeteer 隐藏模拟浏览器的指纹特征。
python开发者就需要把其中的隐藏特征的脚本提取出来,做成一个is 文件。然后让 Selenium 或者 Pyppeteer 在打开任意网页之前,先
运行一下这个js 文件里面的内容。puppeteer-extra-plugin-stealth的作者还写了另外一个工具,叫做extract-stealth-evasions。这个东
西就是用来生成stealth.min.is文件的。
下载地址
- https://github.com/requireCool/stealth.min.js
执行脚本
import time
from selenium import webdriver
from selenium.webdriver.edge.service import Service
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.by import By
service = Service(fr'D:\Python\msedgedriver.exe')
opt = Options()
opt.add_argument('--disable-blink-features=AutomationControlled')
opt.add_experimental_option("detach", True)
browser = webdriver.Edge(service=service,options=opt)
browser.maximize_window()
with open(fr'D:\Python\stealth.min.js',encoding='utf-8') as f:
js = f.read()
browser.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument",{"source":js})
url = 'https://bot.sannysoft.com/'
browser.get(url=url)
browser.refresh()
从14~16行,是配置stealth.min.js的方法
使用withopen打开这个js文件,我的pycharm需要指定一下编码方式也就是utf-8
在配合9行的伪装
可以应对一些反爬网站
debugging模式
就是让 selenium 连接事先配置好的浏览器。
应用场景:
爬取需要登录才能获取的内容,比如扫码登录、手机验证码登录等,通过这种方式绕过短期无法解决的验证码的识别;
也可以通过这种方式绕过一些无法自动完成的复杂操作,然后自动再执行后面的爬虫工作。
通俗来说,就是你先登录一个网站,让selenium使用你登录的账号来爬取信息
也就是手动完成复杂的登录验证操作,然后就交给selenium完成自动化任务
创建并配置浏览器
找到浏览器的安装路径:
在命令提示符输入下面命令创建配置一个浏览器:
Edge.exe–remote-debugging-port=’端口‘ --user-data-dir=“安装路径”
(允许远程控制新浏览器)
端口号不要与已有的冲突,8888,9999等等
用户数据在这个路径里面
快捷方式设置参数:
在Edge的快捷方式上右击,选择属性,快捷方式的目标栏后面加空格加上
下面命令:
“浏览器地址”–remote-debugging-port=8888 --user-data-dir="用户数据文件“
import time
from selenium import webdriver
from selenium.webdriver.edge.service import Service
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.by import By
service = Service(fr'D:\Python\msedgedriver.exe')
opt = Options()
opt.debugger_address = '127.0.0.1:8888'
browser = webdriver.Edge(service=service,options=opt)
url = 'https://www.douban.com/'
browser.get(url=url)
使用起来非常方便,只需要提前打开这个配置好的浏览器,然后让python执行自动化爬取了
详细配置步骤
首先去创建一个文件夹保存你的配置数据
然后去命令行,输入cd+浏览器文件夹地址 这一步是为了打开浏览器的配置
然后在输入Edge.exe–remote-debugging-port=’端口‘ --user-data-dir=“安装路径” 这是配置新浏览器,一般会直接打开一个浏览器
然后去桌面,对着已有的浏览器图标复制一下,再放在桌面,点击其中一个修改属性值
在属性里面有个目标框,把后面的内容替换"浏览器地址"–remote-debugging-port=8888 --user-data-dir="用户数据文件“
然后在pychram中运行上面的代码,就可以在新的浏览器里面打开豆瓣了
爬虫-反爬-反反爬
-
爬虫:采用任何技术手段,用别人开发好的程序,批量获取对方数据,都是爬虫。
-
反爬:用任何技术手段,阻止别人批量获取自己的数据
- 需要在用户体验,成本,反爬策略三者斟酌
-
反反爬:使用任何技术手段、绕过对方的反爬策略
-
误伤:因为反爬过于严格导致正常的用户体验很差
常见反爬手段
- 检测user-agent
- ip 访问频率的限制
- 必须登录(账号访问频率+ip)最有效的方式,需要维护多个账号。账号管理比爬虫本身更加重要。
- 建立账号池,让程序从账号池随机挑选
- 动态网页,is逻辑加密和混淆-加大分析难度
- 初学者使用selenium进行爬取
- 机器学习,分析爬虫行为
反反爬
user-agent
使用fake-useragent这个是请求头的池,是一个第三方库
from fake_useragent import UserAgent
ua = UserAgent()
user_agent = ua.random
print(user_agent)
使用方法特别简单,只需要从这个可以里面调用一下UserAgent类
然后实例化一个对象,就可以模拟出一个请求头了
运行这四行代码可以得到很多不同的请求头,而且分布的十分广泛,可以有效的反反爬
关于这个请求头如何使用?
正常来说,去浏览器打开一个网站,咱们复制的请求头是以字典的形式储存在程序的headers里面,这里需要把键值对的值替换一下,就ok了,也就是{‘User_Agent’:user_agent}
IP代理
就是之前,咱们都是直接向服务器发送请求,服务器可以看到本机的ip地址,对我们爬虫十分危险,所以,我们要通过一个中间人来传递信息,这个中间人就是ip代理
咱们把请求发送给ip代理,让ip代理来向服务器发送信息,服务器再把信息给ip代理,ip代理再把信息返还给咱们
ip代理和请求头池一样,都是有特别多的备用线路
有四个类型
- 开发代理 质量查,但是便宜
- 私密代理,需要手动切换ip
- 隧道代理,服务器自动分配ip
- 独享代理,不适合爬虫
这里的ip代理有很多网站
一般是收费的,具体的用法每个网站都不太一样,网站里面有教程
cookie
一个网站的cookie的有效期一般是3~7天
- 获取cookie
- 手动登录账号或者模拟登录
- 下载cookie
- 使用cookie
- 打开网址域名之后,把之前的cookie直接填充进去,再刷新
可以绕过网址的登录环节
配合selenium配置的debugging模式,使用get_cookies()就可以从网站下载cookie了
然后就是把本地的cookie填充到新的浏览器,使用add_cookie()就可以填充浏览器的cookie了,最后刷新一下就欧克了