【Python】爬虫实战:高效爬取电影网站信息指南(涵盖了诸多学习内容)
本期目录
1 爬取思路
2 爬虫过程
2.1 网址
2.2 查看网页代码
3 爬取数据
3.1 导入包
3.2 爬取代码
01
爬取思路
\*- 第一步,获取页面内容
\*- 第二步:解析并获取单个项目链接
\*- 第三步:获取子页面内容
\*- 第四步:解析子页面相关信息
\*- 第五步:保存json格式数据
02
爬虫过程
2.1 网址
*- 网址``url = 'https://ssr1.scrape.center'`` ``*- 目标` `爬取电影详情内容
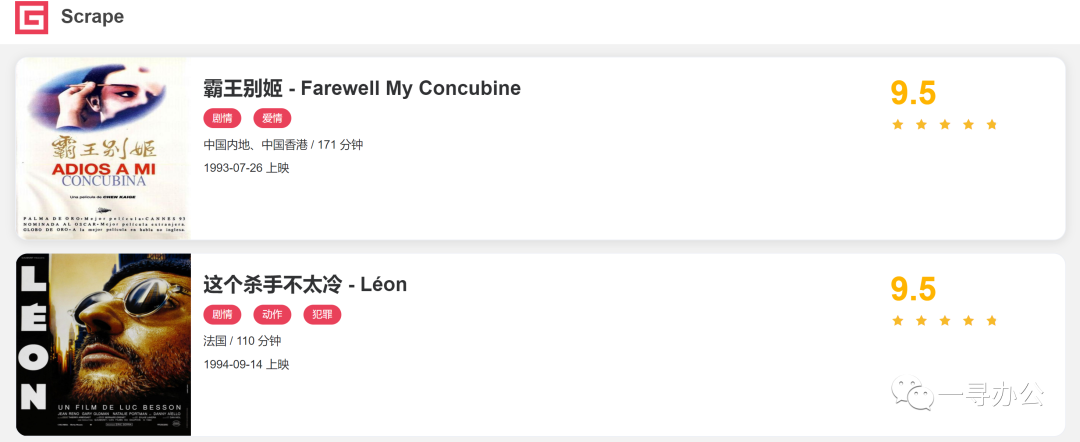

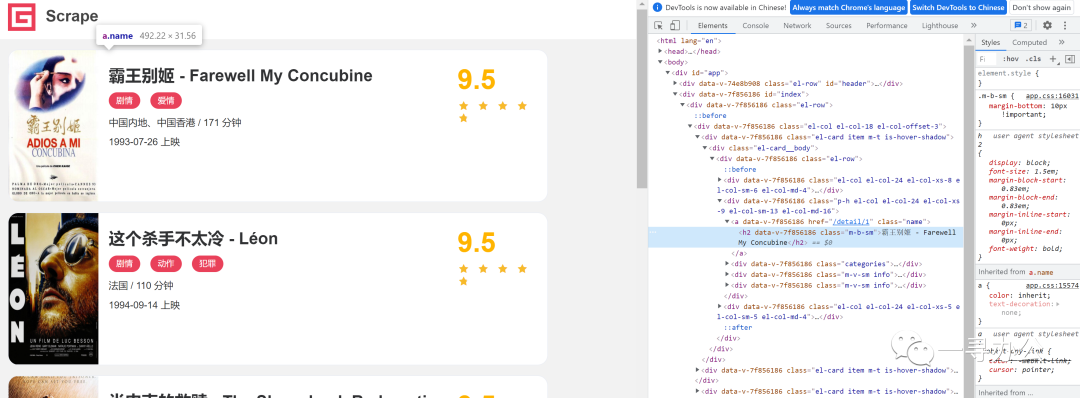
2.2 查看网页代码
*- 网页源代码没有数据``*- 采取正常requests爬取
03
爬取数据
3.1 导入包
import requests``import re``import logging``from lxml import etree``import json``import multiprocessing
3.2 爬取代码
url = 'https://ssr1.scrape.center'``page = 10
*- 爬取函数
def scrape_page(url):` `try:` `response = requests.get(url)` `if response.status_code ==200:` `return response.text` `logging.error(f'get invalid status_code{status_code} while scrape {url}')` `except requests.RequestException:` `logging.error(f'error occurred: {url}',exc_info = True)
*- 获取页面列表
def get_index_url(page):` `index_url = f'{url}/page/{page}'` `return scrape_page(index_url)
*- 解析列表页面获取单个网址:re
`def parse_index(html):` `pattern = re.compile('<a.*?href="(.*?)".*?class="name">')` `items = re.findall(pattern,html)` `for item in items:`` detail_url = url+item` `yield detail_url`
*- 爬取子页面
def scrape_detail(url):` `return scrape_page(url)
*- 解析子页面:xpath
def parse_detail(html):` `tree = etree.HTML(html)` `cover = ''.join(tree.xpath('//*[@id="detail"]/div[1]/div/div/div[1]/div/div[1]/a/img/@src')).replace('\n','').replace(' ','')` `name = ''.join(tree.xpath('//*[@id="detail"]/div[1]/div/div/div[1]/div/div[2]/a/h2//text()')).replace('\n','').replace(' ','')` `categories = ''.join(tree.xpath('//*[@id="detail"]/div[1]/div/div/div[1]/div/div[2]/div[1]//text()')).replace('\n','').replace(' ','')` `published = ''.join(tree.xpath('//*[@id="detail"]/div[1]/div/div/div[1]/div/div[2]/div[2]//text()')).replace('\n','').replace(' ','')` `drama = ''.join(tree.xpath('//*[@id="detail"]/div[1]/div/div/div[1]/div/div[2]/div[4]/p//text()')).replace('\n','').replace(' ','')` `score = ''.join(tree.xpath('//*[@id="detail"]/div[1]/div/div/div[1]/div/div[3]/p[1]//text()')).replace('\n','').replace(' ','')` `return {` `'cover':cover,` `'name':name,` `'categories':categories,` `'published':published,` `'drama':drama,` `'score':score` `}
*- 数据保存
def save_data(data):` `name = data.get('name')` `data_path = f'ResultData/{name}.json'` `json.dump(data,open(data_path,'w',encoding='utf-8'),ensure_ascii=False,indent=2)` `print(f'{data_path}处理完成')
*- 主函数
def main():` `for i in range(1,page+1):` `index_html = get_index_url(i)` `detail_urls = parse_index(index_html)` `for detail_url in detail_urls:` `detail_html = scrape_detail(detail_url)`` data = parse_detail(detail_html)` `save_data(data)`` ``if __name__ == '__main__':` `main()


最后学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。


四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

五、100道Python练习题
检查学习结果。


最后,如果你也想自学Python,可以关注我。我会把踩过的坑分享给你,让你不要踩坑,提高学习速度,这套资料涵盖了诸多学习内容:开发工具,基础视频教程,项目实战源码,51本电子书籍,100道练习题等。相信可以帮助大家在最短的时间内,能达到事半功倍效果,用来复习也是非常不错的。
