人工智能|计算机视觉——微表情识别(Micro expression recognition)的研究现状
一、简述
微表情是一种特殊的面部表情,与普通的表情相比,微表情主要有以下特点:
- 持续时间短,通常只有1/25s~1/3s;
- 动作强度低,难以察觉;
- 在无意识状态下产生,通常难以掩饰或伪装;
- 对微表情的分析通常需要在视频中,而普通表情在图像中就可以分析。
由于微表情在无意识状态下自发产生,难以掩饰或伪装,通常与真实情感直接相关,所以微表情在情感分析中较为可靠,应用前景广阔;另一方面,由于人为识别微表情比较困难,训练难度大且成功率不高,因此需要计算机进行微表情自动识别。
目前微表情识别的工作难点主要有两方面:
- 微表情的持续时间短、动作强度低,特征难以提取,因此需要进行合适的数据预处理与特征提取;
- 由于微表情的数据采集与鉴定存在困难,现有的微表情数据集较少,这使得深度学习在微表情识别中的应用存在困难。
现有的的微表情识别方法通常基于传统机器学习,设计一种手工特征(Handcrafted Feature)来提取微表情片段中的特征,依照数据预处理——特征提取——特征分类的框架进行微表情分类。随着近年来深度学习在计算机视觉中的发展,使用深度学习方法进行微表情识别的尝试也逐渐增多。
下面我将从数据集、数据预处理、传统方法、深度方法四个角度来简单介绍微表情识别工作。
二、数据集
CASME II数据集包含247条微表情视频片段(在我实际使用的版本中包含255条),使用200FPS的高速摄像机进行拍摄,视频片段的面部分辨率可以达到约280*340像素。CASME II数据集将微表情分为5类进行标注,分别是快乐(Happiness)、恶心(Disgust)、惊讶(Surprise)、压抑(Repression)、其他(Others);除此之外,CASME II数据集中还标注了微表情活动的起点(Onset)、峰值点(Apex)与结束(Offset),其中Apex对于微表情识别有所帮助;除了对情感进行标注外,CASME II数据集还标注了每个微表情的AU(面部活动单元),AU可以作为对微表情进行分类的依据。
- 对于CASME II数据集的详细介绍可以参照下文:
CASME II: An Improved Spontaneous Micro-Expression Database and the Baseline Evaluationjournals.plos.org/plosone/article?id=10.1371/journal.pone.0086041编辑
除此之外,目前比较常用的微表情数据集还有SMIC与比较新的SAMM等。对于不同的微表情数据集,主要的区别在于帧率、分辨率与标注方式。
三、数据预处理
在提取微表情的特征前,通常要对微表情视频片段进行数据预处理,首先就是人脸预处理,包括裁剪人脸等;随后,还要进行其他数据预处理,以便于特征的提取。
- 常使用的数据预处理包括使用TIM算法进行时域图像插值、使用EVM算法进行动作放大。
1.人脸预处理
在裁剪人脸时,比较经典的方法是使用ASM或其他算法提取人脸特征点,以左眼的位置以及双眼间的距离作为基准,控制人脸裁剪的位置与范围;
由于微表情数据集中的数据采集自多名受试者,而不同受试者的面部特征分布有所不同,因此为了减少不同受试者之间面部的差异,可以基于面部特征点对所有片段进行面部配准(face register),效果如下图所示:
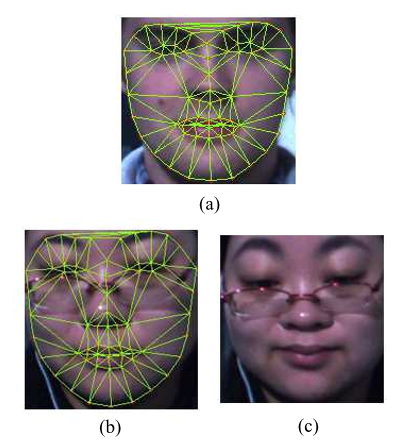
(a)标准面部 (b)面部配准前的图像 (c)面部配准后的图像
简单来说,face register首先选择一张脸作为标准人脸图像,提取其特征点;对于每个视频片段,提取视频片段中第一帧的面部特征点,并计算一个映射函数(此处使用LWM算法),将这帧图像的特征点映射到标准图像的特征点上;最后,将此映射作用在视频中的所有帧上。这种方法可以使所有视频片段中的人脸特征点位置相同,从而减少不同人脸的差异。
- 使用python的dlib库识别人脸特征点,进行face register,经过实验发现register可以提高模型在10-fold验证时的效果,但降低了模型在LOSO验证时的效果。由于dlib对于人脸特征点的识别并不是那么准,因此上述现象也可能是由dlib的误差导致。
2.时域图像插值(TIM算法)
由于微表情持续时间较短,我们希望有一种方法能在保持微表情特征的同时,延长微表情的持续时间,这样有利于特征的稳定提取,因此我们需要对视频片段进行时域上的插值,增加微表情片段所包含的图像数,相当于变相延长了微表情的持续时间。
由于在现实世界中,人的表情是连续变化的,但是在摄像机拍摄的视频中所包含的图像帧是不连续的。我们可以将现实世界中的连续表情变化视为图像空间上的一条连续曲线,曲线的每一个点都代表着人脸在一个瞬间时的表情,而摄像机拍摄的视频则可以视为在这条连续曲线上进行采样。只要能找到这条曲线,并在曲线上重新进行更加密集的采样,便能用更多的图像表示同一段表情。
时域插值模型(Temporal Interpolation Model,TIM)算法是一种时域上的图像插值算法。该方法首先将视频片段视为一个图(graph),并用图中的节点代表一帧图像,视频中相邻的帧在图中也是相邻的节点,视频中不相邻的帧在图中也不相邻;随后,使用图嵌入(graph embedding)算法将该图嵌入到一个低维的流形中,最后代入图像向量,计算出这条高维的连续曲线。在曲线上重新进行采样,便可以得到插值后的图像序列。
- TIM算法的细节可以参考下文: