【RAG多模态】再看多模态RAG进行文档问答的方案
先说结论:这篇文章的方法和前面介绍的两个多模态RAG的工作非常相似,可以看看往期介绍:
-
【RAG&多模态】多模态RAG-ColPali:使用视觉语言模型实现高效的文档检索
-
【RAG&多模态】多模态RAG-VisRAG:基于视觉的检索增强生成在多模态文档上的应用
M3DOCRAG同样也指出,现有的方法要么专注于单页文档的多模态语言模型,要么依赖于基于文本的RAG方法,这些方法使用OCR等文本提取工具。然而,这些方法在实际应用中存在困难,例如问题通常需要跨不同页面或文档的信息,而MLMs无法处理长文档;并且,文档中重要的视觉元素(如图、表等)往往被文本提取工具忽略。
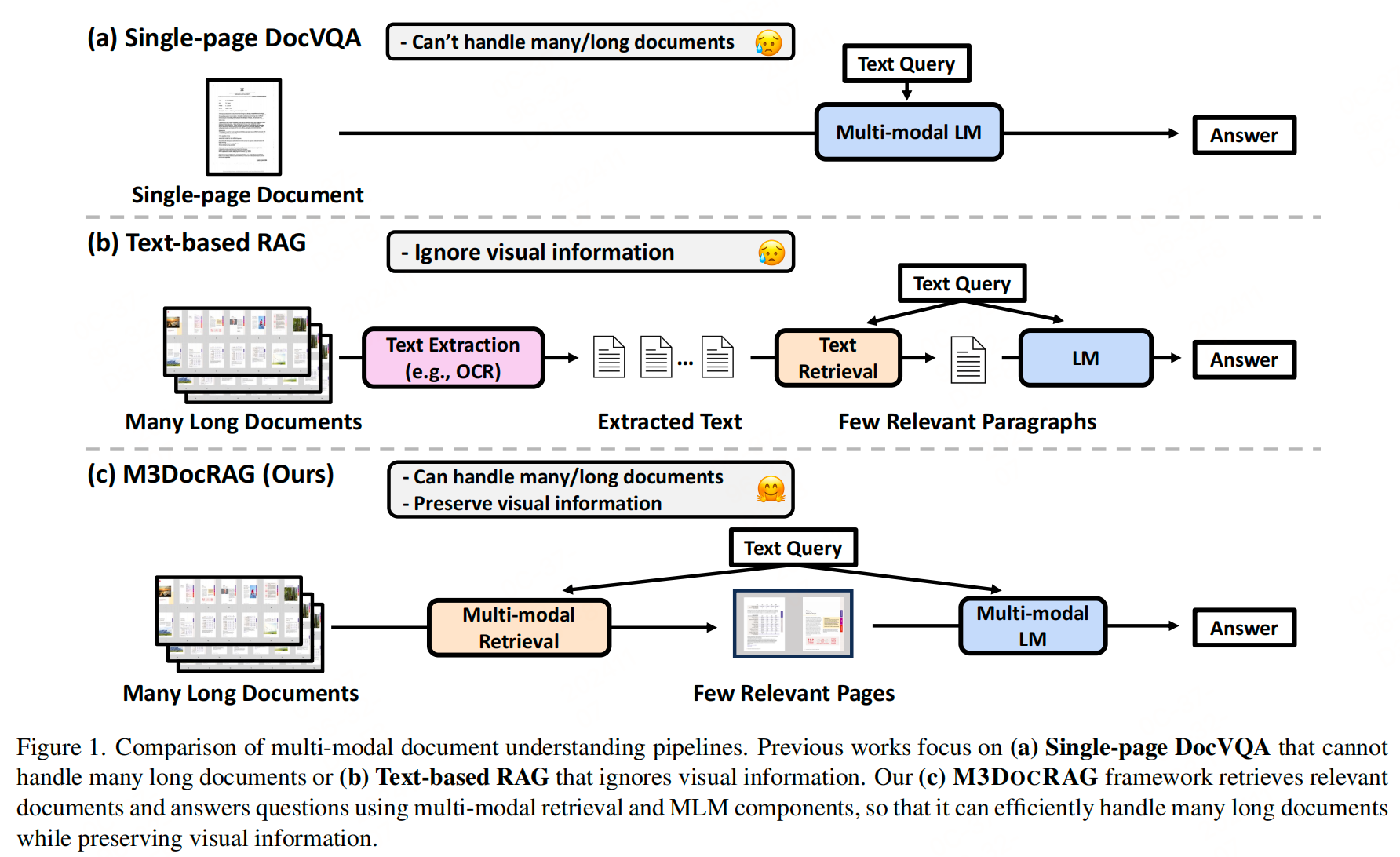
注:文章代码和数据集暂未开源,但都是使用ColPali和qwen2-vl实现,笔者在前面文档也恰好实践了一个简单的RAG-ColPali,供参考:
【多模态&RAG】多模态RAG ColPali实践
方法
-
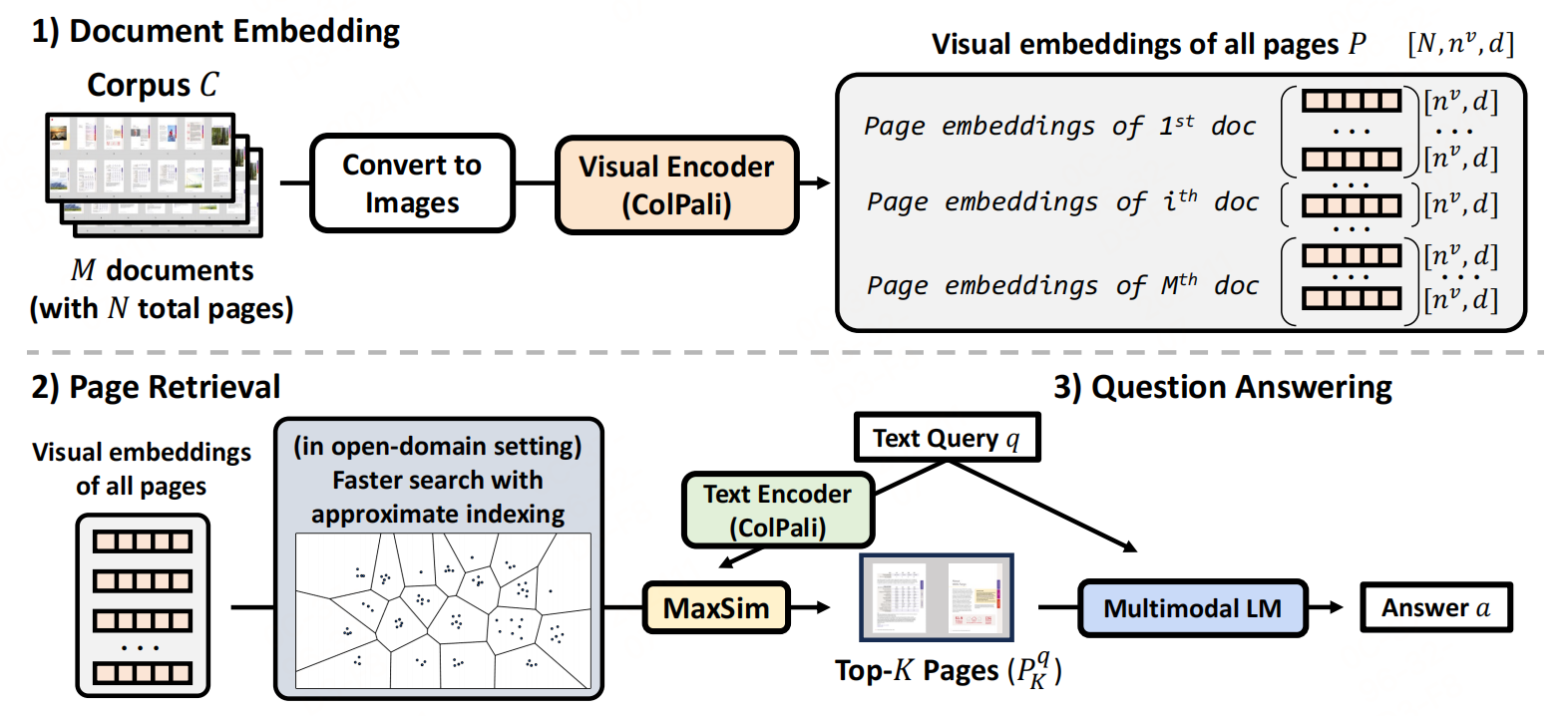
文档嵌入:和RAG-ColPali很相似,文档嵌入使用ColPali将所有文档页面转换为RGB图像,并从页面图像中提取视觉嵌入。(ColPali是一种基于后期交互机制的多模态检索模型,它将文本和图像输入编码为统一的向量表示,并检索最相关的图像。其原理可以看看往期对ColPali的介绍《ColPali》)
-
页面检索:也和RAG-ColPali使用的方法相似,也是使用MaxSim分数计算查询与页面之间的相关性,并检索与文本查询top-K个页面。
-
答案生成:使用多模态语言模型(MLM)对检索到的页面图像进行视觉问答,以获得最终答案。该方法使用的是qwen2-vl-7b
数据集
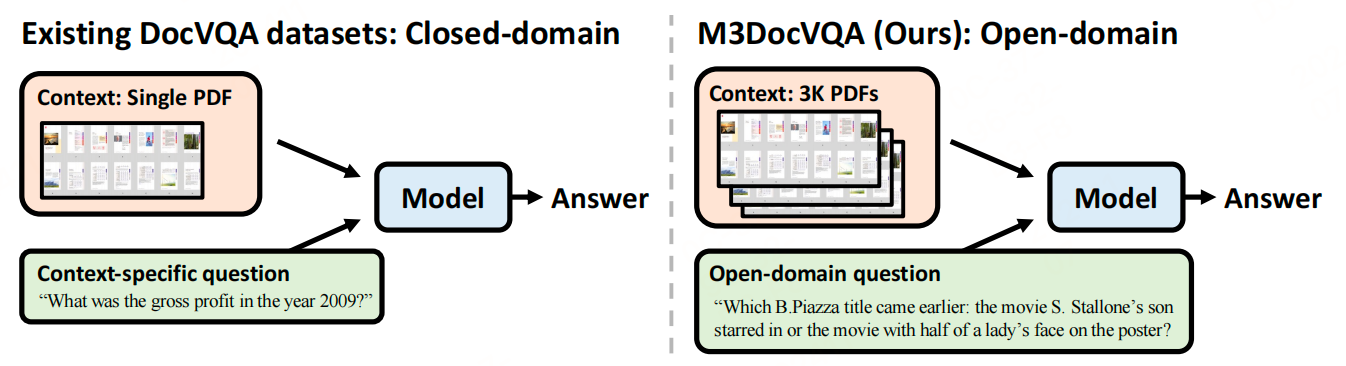
M3DocVQA包含3,368个PDF文档,总计41,005页,涵盖开放域和封闭域的DocVQA任务。

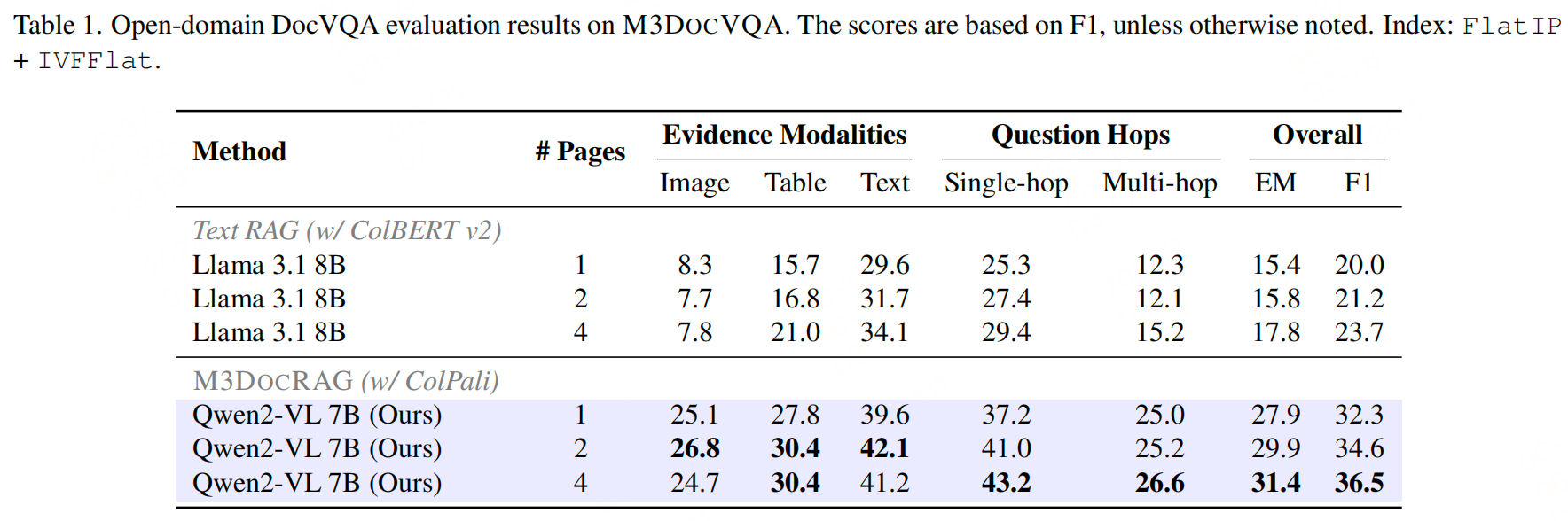
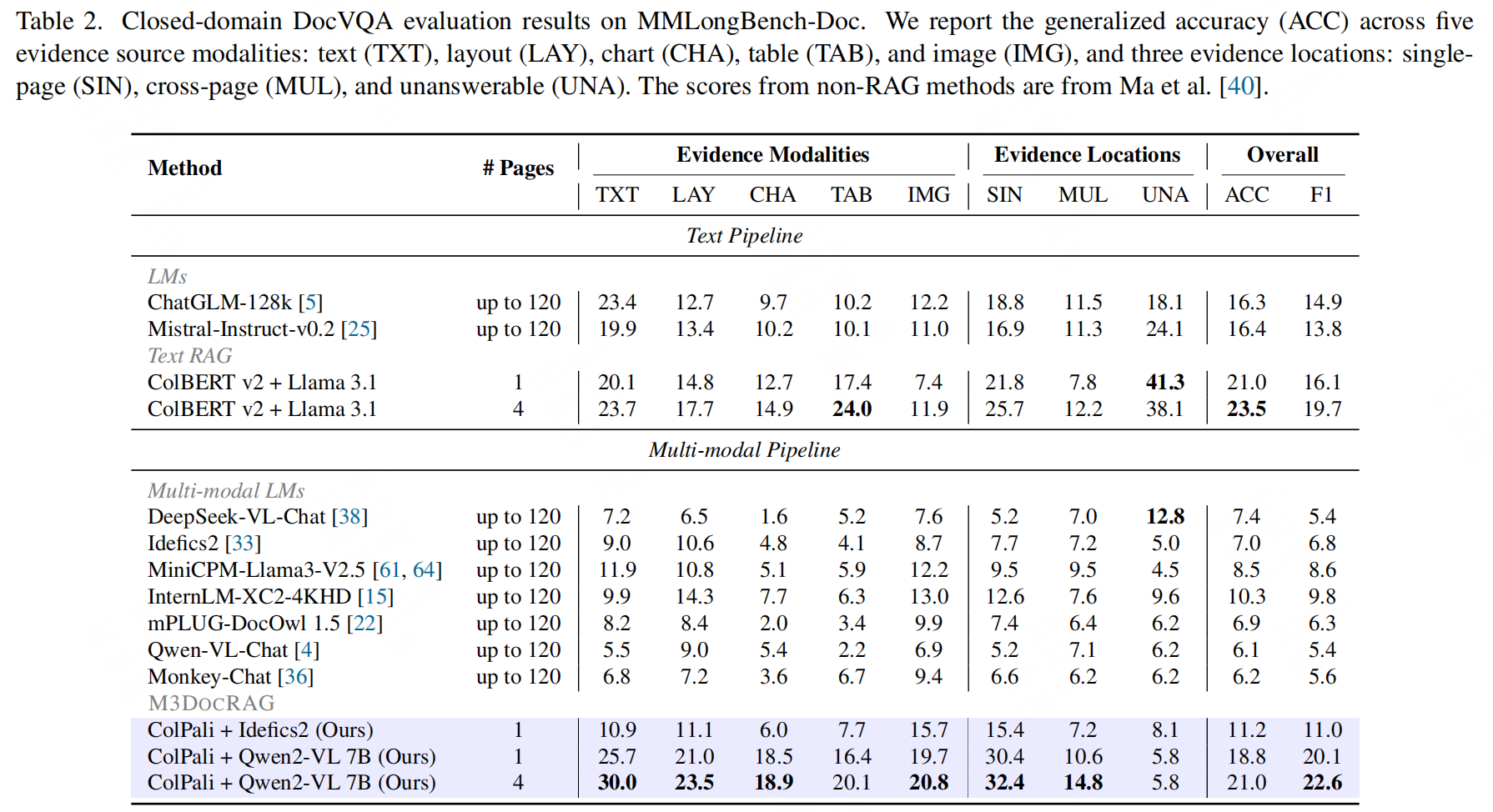
实验结果
参考文献
https://arxiv.org/pdf/2411.04952v1