ccc-pytorch-LSTM(8)
文章目录
- 一、LSTM简介
- 二、LSTM中的核心结构
- 三、如何解决RNN中的梯度消失/爆炸问题
- 四、情感分类实战(google colab)
一、LSTM简介
LSTM(long short-term memory)长短期记忆网络,RNN的改进,克服了RNN中“记忆低下”的问题。通过“门”结构实现信息的添加和移除,通过记忆元将序列处理过程中的相关信息一直传递下去,经典结构如下:
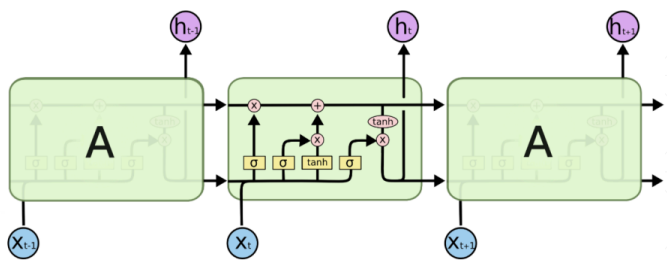

二、LSTM中的核心结构
记忆元(memory cell)-长期记忆:
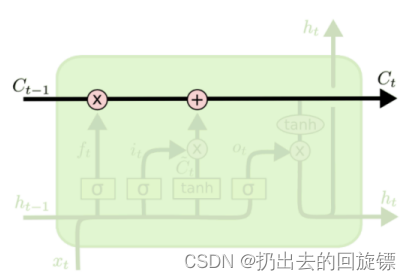
就像一个cell一样,信息通过这条只有少量线性交互的线传递。传递过程中有3种“门”结构可以告诉它该学习或者保存哪些信息
三个门结构-短期记忆
遗忘门:用来决定当前状态哪些信息被移除
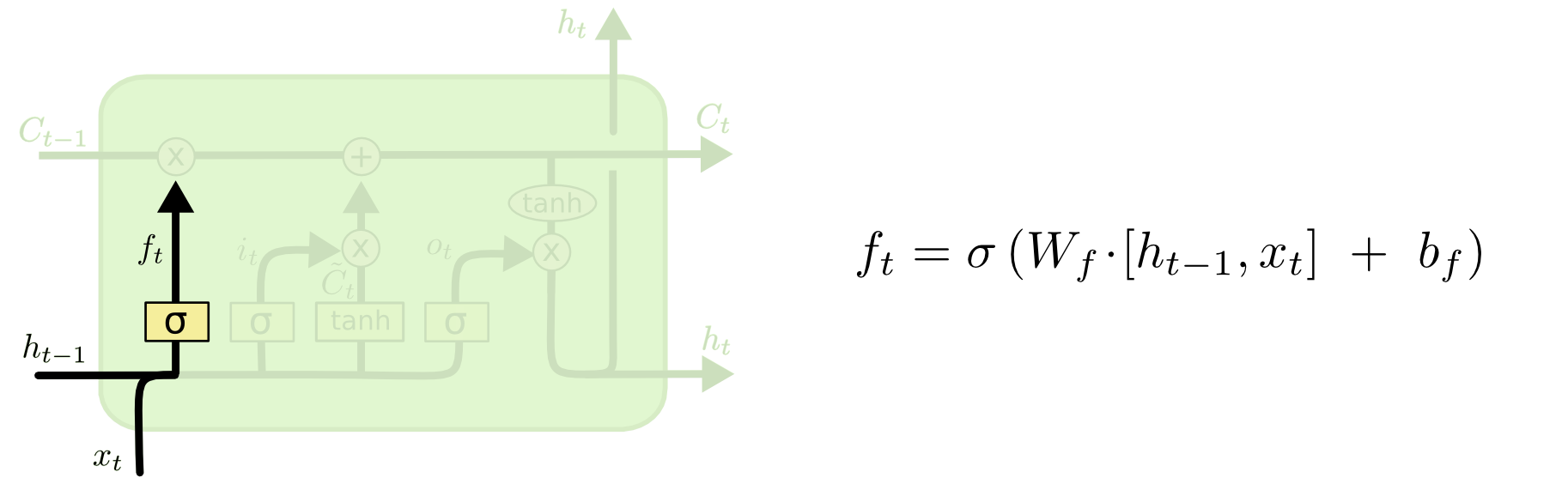
输入门:决定放入哪些信息到细胞状态
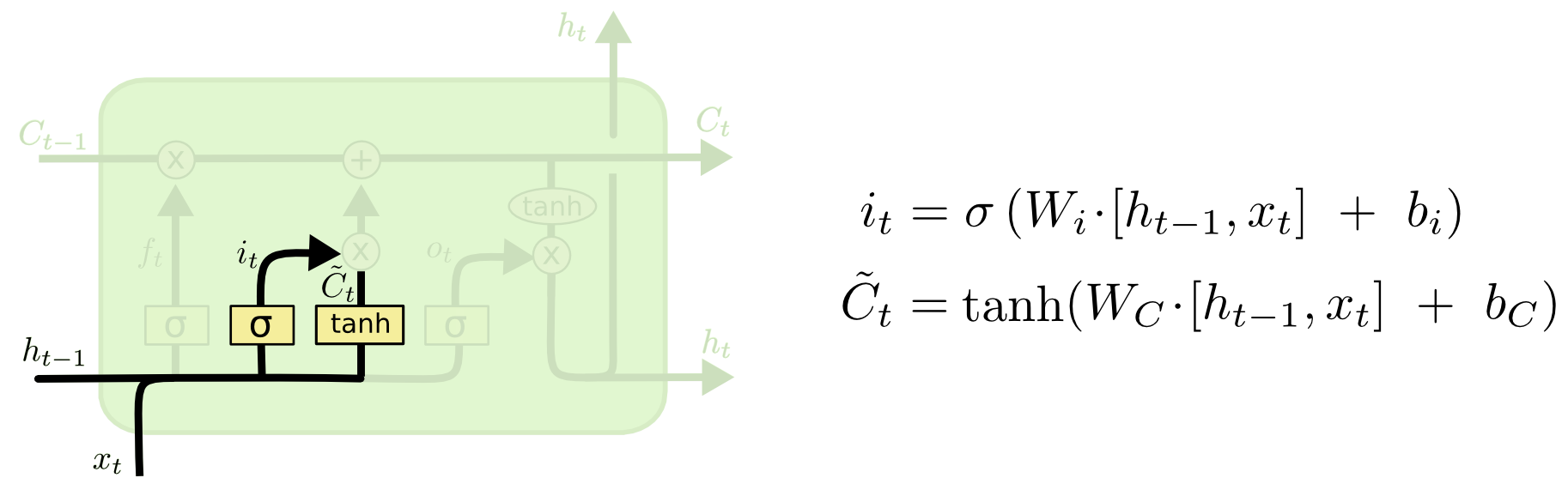
输出门:决定哪些信息用于输出
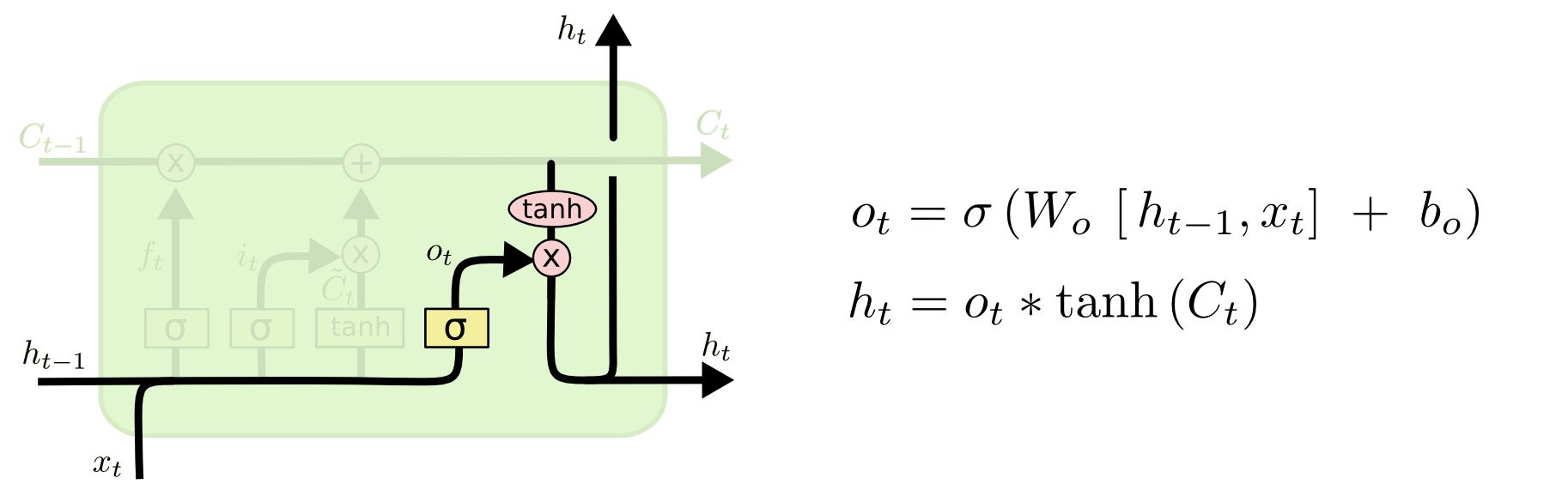
细节注意:
- 新的细胞状态只需要遗忘门和输入门就可以更新,公式为: C t = f t ∗ C t − 1 + i t ∗ C t ~ C_t=f_t*C_{t-1}+i_t* \tilde{C_t} Ct=ft∗Ct−1+it∗Ct~(注意所有的 ∗ * ∗都表示Hadamard 乘积)
- 只有隐状态h_t会传递到输出层,记忆元完全属于内部信息,不可手动修改
三、如何解决RNN中的梯度消失/爆炸问题
解决是指很大程度上缓解,不是让它彻底消失。先解释RNN为什么会有这些问题:
∂
L
t
∂
U
=
∑
k
=
0
t
∂
L
t
∂
O
t
∂
O
t
∂
S
t
(
∏
j
=
k
+
1
t
∂
S
j
∂
S
j
−
1
)
∂
S
k
∂
U
∂
L
t
∂
W
=
∑
k
=
0
t
∂
L
t
∂
O
t
∂
O
t
∂
S
t
(
∏
j
=
k
+
1
t
∂
S
j
∂
S
j
−
1
)
∂
S
k
∂
W
\begin{aligned} &\frac{\partial L_t}{\partial U}= \sum_{k=0}^{t}\frac{\partial L_t}{\partial O_t}\frac{\partial O_t}{\partial S_t}(\prod_{j=k+1}^{t}\frac{\partial S_j}{\partial S_{j-1}})\frac{\partial S_k}{\partial U}\\&\frac{\partial L_t}{\partial W}= \sum_{k=0}^{t}\frac{\partial L_t}{\partial O_t}\frac{\partial O_t}{\partial S_t}(\prod_{j=k+1}^{t}\frac{\partial S_j}{\partial S_{j-1}})\frac{\partial S_k}{\partial W} \end{aligned}
∂U∂Lt=k=0∑t∂Ot∂Lt∂St∂Ot(j=k+1∏t∂Sj−1∂Sj)∂U∂Sk∂W∂Lt=k=0∑t∂Ot∂Lt∂St∂Ot(j=k+1∏t∂Sj−1∂Sj)∂W∂Sk(具体过程可以看这里)
上面是训练过程任意时刻更新W、U需要用到的求偏导的结果。实际使用会加上激活函数,通常为tanh、sigmoid等
tanh和其导数图像如下

sigmoid和其导数如下
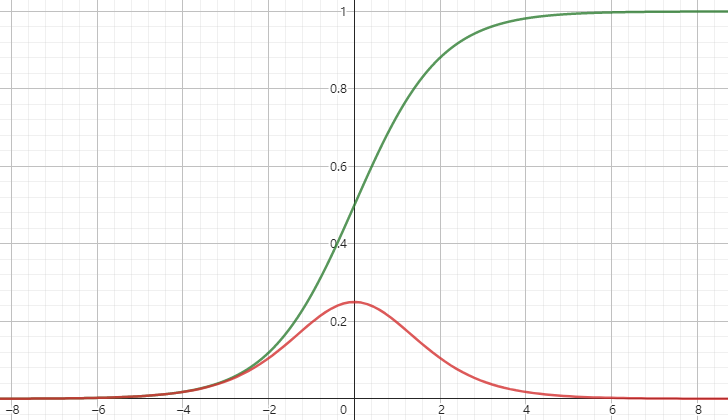
这些激活函数的导数都比1要小,又因为
∏
j
=
k
+
1
t
∂
S
j
∂
S
j
−
1
=
∏
j
=
k
+
1
t
t
a
n
h
′
(
W
s
)
\prod_{j=k+1}^{t}\frac{\partial S_j}{\partial S_{j-1}}=\prod_{j=k+1}^{t}tanh'(W_s)
∏j=k+1t∂Sj−1∂Sj=∏j=k+1ttanh′(Ws),所以当
W
s
W_s
Ws过小过大就会分别造成梯度消失和爆炸的问题,特别是过小。
LSTM如何缓解
由链式法则和三个门的公式可以得到:
∂
C
t
∂
C
t
−
1
=
∂
C
t
∂
f
t
∂
f
t
∂
h
t
−
1
∂
h
t
−
1
∂
C
t
−
1
+
∂
C
t
∂
i
t
∂
i
t
∂
h
t
−
1
∂
h
t
−
1
∂
C
t
−
1
+
∂
C
t
∂
C
t
~
∂
C
t
~
∂
h
t
−
1
∂
h
t
−
1
∂
C
t
−
1
+
∂
C
t
∂
C
t
−
1
=
C
t
−
1
σ
′
(
⋅
)
W
f
∗
o
t
−
1
t
a
n
h
′
(
C
t
−
1
)
+
C
t
~
σ
′
(
⋅
)
W
i
∗
o
t
−
1
t
a
n
h
′
(
C
t
−
1
)
+
i
t
t
a
n
h
′
(
⋅
)
W
c
∗
o
t
−
1
t
a
n
h
′
(
C
t
−
1
)
+
f
t
\begin{aligned} &\frac{\partial C_t}{\partial C_{t-1}}\\&=\frac{\partial C_t}{\partial f_t}\frac{\partial f_t}{\partial h_{t-1}}\frac{\partial h_{t-1}}{\partial C_{t-1}}+\frac{\partial C_t}{\partial i_t}\frac{\partial i_t}{\partial h_{t-1}}\frac{\partial h_{t-1}}{\partial C_{t-1}}+\frac{\partial C_t}{\partial \tilde{C_t}}\frac{\partial \tilde{C_t}}{\partial h_{t-1}}\frac{\partial h_{t-1}}{\partial C_{t-1}}+\frac{\partial C_t}{\partial C_{t-1}}\\ &=C_{t-1}\sigma '(\cdot)W_f*o_{t-1}tanh'(C_{t-1})+\tilde{C_t}\sigma '(\cdot)W_i*o_{t-1}tanh'(C_{t-1})\\&+i_ttanh'(\cdot)W_c*o_{t-1}tanh'(C_{t-1})+f_t \end{aligned}
∂Ct−1∂Ct=∂ft∂Ct∂ht−1∂ft∂Ct−1∂ht−1+∂it∂Ct∂ht−1∂it∂Ct−1∂ht−1+∂Ct~∂Ct∂ht−1∂Ct~∂Ct−1∂ht−1+∂Ct−1∂Ct=Ct−1σ′(⋅)Wf∗ot−1tanh′(Ct−1)+Ct~σ′(⋅)Wi∗ot−1tanh′(Ct−1)+ittanh′(⋅)Wc∗ot−1tanh′(Ct−1)+ft
- 由相乘变成了相加,不容易叠加
- sigmoid函数使单元间传递结果非常接近0或者1,使模型变成非线性,并且可以在学习过程中内部调整
四、情感分类实战(google colab)
环境和库:
!pip install torch
!pip install torchtext
!python -m spacy download en
# K80 gpu for 12 hours
import torch
from torch import nn, optim
from torchtext import data, datasets
print('GPU:', torch.cuda.is_available())
torch.manual_seed(123)
加载数据集:
TEXT = data.Field(tokenize='spacy')
LABEL = data.LabelField(dtype=torch.float)
train_data, test_data = datasets.IMDB.splits(TEXT, LABEL)
print(train_data.examples[15].text)
print(train_data.examples[15].label)
网络结构:
class RNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim):
"""
"""
super(RNN, self).__init__()
# [0-10001] => [100]
self.embedding = nn.Embedding(vocab_size, embedding_dim)
# [100] => [256]
self.rnn = nn.LSTM(embedding_dim, hidden_dim, num_layers=2,
bidirectional=True, dropout=0.5)
# [256*2] => [1]
self.fc = nn.Linear(hidden_dim*2, 1)
self.dropout = nn.Dropout(0.5)
def forward(self, x):
"""
x: [seq_len, b] vs [b, 3, 28, 28]
"""
# [seq, b, 1] => [seq, b, 100]
embedding = self.dropout(self.embedding(x))
# output: [seq, b, hid_dim*2]
# hidden/h: [num_layers*2, b, hid_dim]
# cell/c: [num_layers*2, b, hid_di]
output, (hidden, cell) = self.rnn(embedding)
# [num_layers*2, b, hid_dim] => 2 of [b, hid_dim] => [b, hid_dim*2]
hidden = torch.cat([hidden[-2], hidden[-1]], dim=1)
# [b, hid_dim*2] => [b, 1]
hidden = self.dropout(hidden)
out = self.fc(hidden)
return out
Embedding
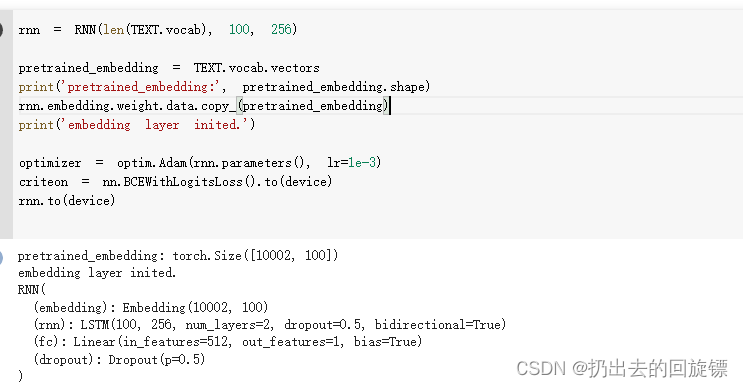
rnn = RNN(len(TEXT.vocab), 100, 256)
pretrained_embedding = TEXT.vocab.vectors
print('pretrained_embedding:', pretrained_embedding.shape)
rnn.embedding.weight.data.copy_(pretrained_embedding)
print('embedding layer inited.')
optimizer = optim.Adam(rnn.parameters(), lr=1e-3)
criteon = nn.BCEWithLogitsLoss().to(device)
rnn.to(device)
训练并测试
import numpy as np
def binary_acc(preds, y):
"""
get accuracy
"""
preds = torch.round(torch.sigmoid(preds))
correct = torch.eq(preds, y).float()
acc = correct.sum() / len(correct)
return acc
def train(rnn, iterator, optimizer, criteon):
avg_acc = []
rnn.train()
for i, batch in enumerate(iterator):
# [seq, b] => [b, 1] => [b]
pred = rnn(batch.text).squeeze(1)
#
loss = criteon(pred, batch.label)
acc = binary_acc(pred, batch.label).item()
avg_acc.append(acc)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i%10 == 0:
print(i, acc)
avg_acc = np.array(avg_acc).mean()
print('avg acc:', avg_acc)
def eval(rnn, iterator, criteon):
avg_acc = []
rnn.eval()
with torch.no_grad():
for batch in iterator:
# [b, 1] => [b]
pred = rnn(batch.text).squeeze(1)
#
loss = criteon(pred, batch.label)
acc = binary_acc(pred, batch.label).item()
avg_acc.append(acc)
avg_acc = np.array(avg_acc).mean()
print('>>test:', avg_acc)
for epoch in range(10):
eval(rnn, test_iterator, criteon)
train(rnn, train_iterator, optimizer, criteon)
最后得到的准确率结果如下:

完整colab链接:lstm
完整代码:
# -*- coding: utf-8 -*-
"""lstm
Automatically generated by Colaboratory.
Original file is located at
https://colab.research.google.com/drive/1GX0Rqur8T45MSYhLU9MYWAbycfLH4-Fu
"""
!pip install torch
!pip install torchtext
!python -m spacy download en
# K80 gpu for 12 hours
import torch
from torch import nn, optim
from torchtext import data, datasets
print('GPU:', torch.cuda.is_available())
torch.manual_seed(123)
TEXT = data.Field(tokenize='spacy')
LABEL = data.LabelField(dtype=torch.float)
train_data, test_data = datasets.IMDB.splits(TEXT, LABEL)
print('len of train data:', len(train_data))
print('len of test data:', len(test_data))
print(train_data.examples[15].text)
print(train_data.examples[15].label)
# word2vec, glove
TEXT.build_vocab(train_data, max_size=10000, vectors='glove.6B.100d')
LABEL.build_vocab(train_data)
batchsz = 30
device = torch.device('cuda')
train_iterator, test_iterator = data.BucketIterator.splits(
(train_data, test_data),
batch_size = batchsz,
device=device
)
class RNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim):
"""
"""
super(RNN, self).__init__()
# [0-10001] => [100]
self.embedding = nn.Embedding(vocab_size, embedding_dim)
# [100] => [256]
self.rnn = nn.LSTM(embedding_dim, hidden_dim, num_layers=2,
bidirectional=True, dropout=0.5)
# [256*2] => [1]
self.fc = nn.Linear(hidden_dim*2, 1)
self.dropout = nn.Dropout(0.5)
def forward(self, x):
"""
x: [seq_len, b] vs [b, 3, 28, 28]
"""
# [seq, b, 1] => [seq, b, 100]
embedding = self.dropout(self.embedding(x))
# output: [seq, b, hid_dim*2]
# hidden/h: [num_layers*2, b, hid_dim]
# cell/c: [num_layers*2, b, hid_di]
output, (hidden, cell) = self.rnn(embedding)
# [num_layers*2, b, hid_dim] => 2 of [b, hid_dim] => [b, hid_dim*2]
hidden = torch.cat([hidden[-2], hidden[-1]], dim=1)
# [b, hid_dim*2] => [b, 1]
hidden = self.dropout(hidden)
out = self.fc(hidden)
return out
rnn = RNN(len(TEXT.vocab), 100, 256)
pretrained_embedding = TEXT.vocab.vectors
print('pretrained_embedding:', pretrained_embedding.shape)
rnn.embedding.weight.data.copy_(pretrained_embedding)
print('embedding layer inited.')
optimizer = optim.Adam(rnn.parameters(), lr=1e-3)
criteon = nn.BCEWithLogitsLoss().to(device)
rnn.to(device)
import numpy as np
def binary_acc(preds, y):
"""
get accuracy
"""
preds = torch.round(torch.sigmoid(preds))
correct = torch.eq(preds, y).float()
acc = correct.sum() / len(correct)
return acc
def train(rnn, iterator, optimizer, criteon):
avg_acc = []
rnn.train()
for i, batch in enumerate(iterator):
# [seq, b] => [b, 1] => [b]
pred = rnn(batch.text).squeeze(1)
#
loss = criteon(pred, batch.label)
acc = binary_acc(pred, batch.label).item()
avg_acc.append(acc)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i%10 == 0:
print(i, acc)
avg_acc = np.array(avg_acc).mean()
print('avg acc:', avg_acc)
def eval(rnn, iterator, criteon):
avg_acc = []
rnn.eval()
with torch.no_grad():
for batch in iterator:
# [b, 1] => [b]
pred = rnn(batch.text).squeeze(1)
#
loss = criteon(pred, batch.label)
acc = binary_acc(pred, batch.label).item()
avg_acc.append(acc)
avg_acc = np.array(avg_acc).mean()
print('>>test:', avg_acc)
for epoch in range(10):
eval(rnn, test_iterator, criteon)
train(rnn, train_iterator, optimizer, criteon)