GMP底层
GMP
GMP是Go语言运行时(runtime)层面的实现,是go语言自己实现的一套调度系统。区别于操作系统调度OS线程。
-
G:goroutine
G很好理解,就是个goroutine的,里面除了存放本goroutine信息外 还有与所在P的绑定等信息。
-
M:machine
M(machine)是Go运行时(runtime)对操作系统内核线程的虚拟,M与内核线程一般是一一映射的关系, 一个groutine最终是要放到M上执行的。
-
P:processor
P管理着一组goroutine队列,P里面会存储当前goroutine运行的上下文环境(函数指针,堆栈地址及地址边界),P会对自己管理的goroutine队列做一些调度(比如把占用CPU时间较长的goroutine暂停、运行后续的goroutine等等)当自己的队列消费完了就去全局队列里取,如果全局队列里也消费完了会去其他P的队列里抢任务。
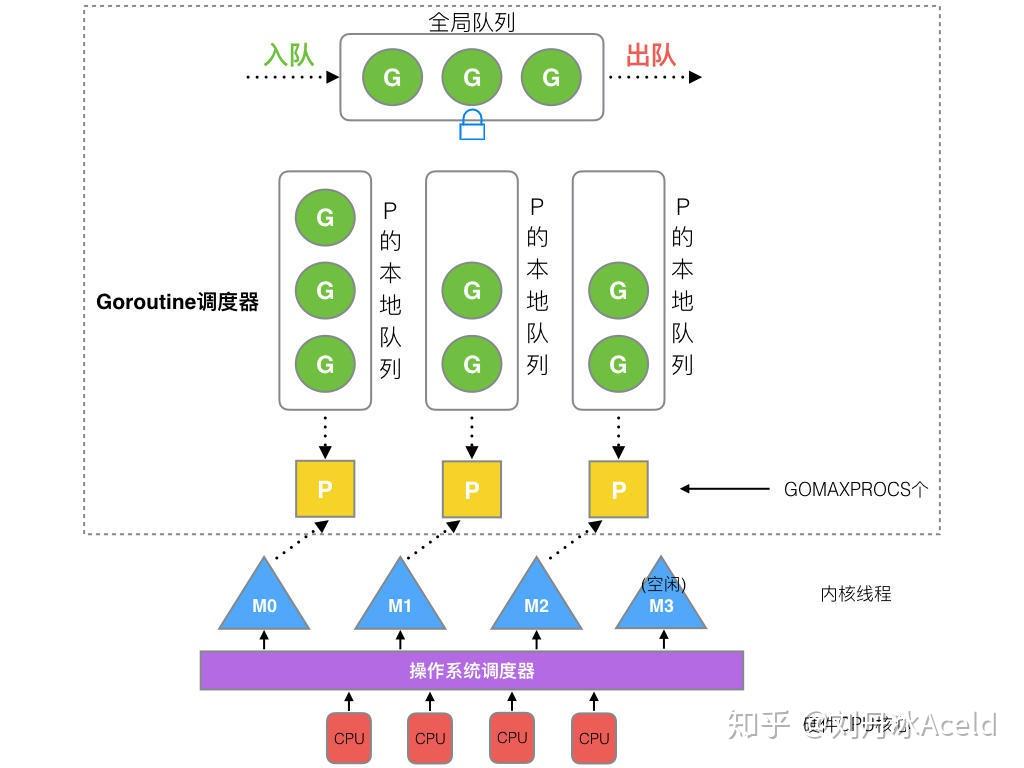
-
P 和 M 的数量没有固定的搭配关系(默认M>P),当一个 M 阻塞了,P 会发生 hand off,与其他空闲的 M 结合,或者产生新的 M
-
当 P 的局部队列里面的 G 运行完毕之后,会用全局队列获取 G,在获取的过程中,会加锁。如果全局队列为空,则从其他 P 的局部队列中 偷一半的 G 过来运行,这个叫 work stealing 机制
-
如果G进行了系统调用syscall,M也会跟着进入系统调用状态,那么这个P留在这里就浪费了,P不会等待G和M系统调用完成,而是P与GM立刻断开,找其他比较闲的M执行其他的G
Go的协程调度与操作系统线程调度区别主要存在四个方面:
- 调度发生地点:Go中协程的调度发生在runtime,属于用户态,不涉及与内核态的切换;一个协程可以被切换到多个线程执行
- 上下文切换速度:协程的切换速度远快于线程,不需要经过内核与用户态切换,同时需要保存的状态和寄存器非常少;线程切换速度为1-2微秒,协程切换速度为0.2微秒左右
- 栈大小:线程栈一般是2MB,而且运行时不能更改大小;Go的协程栈只有2kb,而且可以动态扩容(64位机最大为1G)
- 调度策略:线程调度大部分都是抢占式调度,操作系统通过发出中断信号强制线程切换上下文;Go的协程基本是主动和被动式调度,调度时机可预期
GMP概览
1 +-------------------- sysmon ---------------//------+
2 | |
3 | |
4 +---+ +---+-------+ +--------+ +---+---+
5 go func() ---> | G | ---> | P | local | <=== balance ===> | global | <--//--- | P | M |
6 +---+ +---+-------+ +--------+ +---+---+
7 | | |
8 | +---+ | |
9 +----> | M | <--- findrunnable ---+--- steal <--//--+
10 +---+
11 |
12 mstart
13 |
14 +--- execute <----- schedule
15 | |
16 | |
17 +--> G.fn --> goexit --+
G分类:
- 主协程,用来执行用户main函数的协程,主协程创建的协程,也是P调度的主要成员
- G0,每个M都有一个G0协程,他是runtime的一部分,G0是跟M绑定的,主要用来执行调度逻辑的代码,所以不能被抢占也不会被调度(普通G也可以执行runtime_procPin禁止抢占),G0的栈是系统分配的,比普通的G栈(2KB)要大,不能扩容也不能缩容
- sysmon协程,sysmon协程也是runtime的一部分,sysmon协程直接运行在M不需要P,主要做一些检查工作如:检查死锁、检查计时器获取下一个要被触发的计时任务、检查是否有ready的网络调用以恢复用户G的工作、检查一个G是否运行时间太长进行抢占式调度。
M分类:
- 普通M,用来与P绑定执行G中任务
- m0:Go程序是一个进程,进程都有一个主线程,m0就是Go程序的主线程,通过一个与其绑定的G0来执行runtime启动加载代码;一个Go程序只有一个m0
- 运行sysmon的M,主要用来运行sysmon协程。
P调度:
P是用来调度G的执行,所以每个P都有自己的一个G的队列,当G队列都执行完毕后,会从global队列中获取一批G放到自己的本地队列中,如果全局队列也没有待运行的G,则P会再从其他P中窃取一部分G放到自己的队列中。而调度的时机一般有三种:
- 主动调度,协程通过调用
runtime.Goshed方法主动让渡自己的执行权利,之后这个协程会被放到全局队列中,等待后续被执行- 被动调度,协程在休眠、channel通道阻塞、网络I/O堵塞、执行垃圾回收时被暂停,被动式让渡自己的执行权利。大部分场景都是被动调度,这是Go高性能的一个原因,让M永远不停歇,不处于等待的协程让出CPU资源执行其他任务。
- 抢占式调度,这个主要是sysmon协程上的调度,当发现G处于系统调用(如调用网络io)超过20微秒或者G运行时间过长(超过10ms),会抢占G的执行CPU资源,让渡给其他协程;防止其他协程没有执行的机会;(系统调用会进入内核态,由内核线程完成,可以把当前CPU资源让渡给其他用户协程)
sysmon
特点:
- 不需要 P(处理器)即可独立运行。
- 每 20 微秒到 10 毫秒 被唤醒一次,频率动态调整,执行系统级的维护任务。
主要职责:
- 垃圾回收
执行垃圾回收相关的辅助任务,释放不再使用的内存资源。- 回收长时间阻塞的 P
当某个 P 长时间(10ms)处于系统调用或其他阻塞状态时,sysmon 会将其从 M 中解绑,使资源得到重新利用。- 发起抢占调度
- 监控长时间运行的 G(goroutine),如果某个 G 运行时间过长,sysmon 会发出抢占信号,强制切换到其他 G。
- 确保调度的公平性,防止某个 goroutine 独占资源。+
GMP源码
G源码
// runtime/runtime2.go
type g struct {
// 记录协程栈的栈顶和栈底位置
stack stack // offset known to runtime/cgo
// 主要作用是参与一些比较计算,当发现容量要超过栈分配空间后,可以进行扩容或者收缩
stackguard0 uintptr // offset known to liblink
stackguard1 uintptr // offset known to liblink
// 当前与g绑定的m
m *m // current m; offset known to arm liblink
// 这是一个比较重要的字段,里面保存的一些与goroutine运行位置相关的寄存器和指针,如rsp、rbp、rpc等寄存器
sched gobuf
syscallsp uintptr // if status==Gsyscall, syscallsp = sched.sp to use during gc
syscallpc uintptr // if status==Gsyscall, syscallpc = sched.pc to use during gc
stktopsp uintptr // expected sp at top of stack, to check in traceback
// 用于做参数传递,睡眠时其他goroutine可以设置param,唤醒时该g可以读取这些param
param unsafe.Pointer
// 记录当前goroutine的状态
atomicstatus uint32
stackLock uint32 // sigprof/scang lock; TODO: fold in to atomicstatus
// goroutine的唯一id
goid int64
schedlink guintptr
// 标记是否可以被抢占
preempt bool // preemption signal, duplicates stackguard0 = stackpreempt
preemptStop bool // transition to _Gpreempted on preemption; otherwise, just deschedule
preemptShrink bool // shrink stack at synchronous safe point
// 如果调用了LockOsThread方法,则g会绑定到某个m上,只在这个m上运行
lockedm muintptr
sig uint32
writebuf []byte
sigcode0 uintptr
sigcode1 uintptr
sigpc uintptr
// 创建该goroutine的语句的指令地址
gopc uintptr // pc of go statement that created this goroutine
ancestors *[]ancestorInfo // ancestor information goroutine(s) that created this goroutine (only used if debug.tracebackancestors)
// goroutine函数的指令地址
startpc uintptr // pc of goroutine function
racectx uintptr
waiting *sudog // sudog structures this g is waiting on (that have a valid elem ptr); in lock order
cgoCtxt []uintptr // cgo traceback context
labels unsafe.Pointer // profiler labels
timer *timer // cached timer for time.Sleep
selectDone uint32 // are we participating in a select and did someone win the race?
}
stack结构体
stack结构体主要用来记录goroutine所使用的栈的信息,包括栈顶和栈底位置:
// Stack describes a Go execution stack.
// The bounds of the stack are exactly [lo, hi),
// with no implicit data structures on either side.
//用于记录goroutine使用的栈的起始和结束位置
type stack struct {
lo uintptr // 栈顶,指向内存低地址
hi uintptr // 栈底,指向内存高地址
}
gobuf结构体
gobuf结构体用于保存goroutine的调度信息,主要包括CPU的几个寄存器的值:
type gobuf struct {
// The offsets of sp, pc, and g are known to (hard-coded in) libmach.
//
// ctxt is unusual with respect to GC: it may be a
// heap-allocated funcval, so GC needs to track it, but it
// needs to be set and cleared from assembly, where it's
// difficult to have write barriers. However, ctxt is really a
// saved, live register, and we only ever exchange it between
// the real register and the gobuf. Hence, we treat it as a
// root during stack scanning, which means assembly that saves
// and restores it doesn't need write barriers. It's still
// typed as a pointer so that any other writes from Go get
// write barriers.
sp uintptr // 保存CPU的rsp寄存器的值
pc uintptr // 保存CPU的rip寄存器的值
g guintptr // 记录当前这个gobuf对象属于哪个goroutine
ctxt unsafe.Pointer
// 保存系统调用的返回值,因为从系统调用返回之后如果p被其它工作线程抢占,
// 则这个goroutine会被放入全局运行队列被其它工作线程调度,其它线程需要知道系统调用的返回值。
ret sys.Uintreg
lr uintptr
// 保存CPU的rip寄存器的值
bp uintptr // for GOEXPERIMENT=framepointer
}
schedt结构体
schedt结构体用来保存调度器的状态信息和goroutine的全局运行队列:
type schedt struct {
// accessed atomically. keep at top to ensure alignment on 32-bit systems.
goidgen uint64
lastpoll uint64
lock mutex
// When increasing nmidle, nmidlelocked, nmsys, or nmfreed, be
// sure to call checkdead().
// 由空闲的工作线程组成链表
midle muintptr // idle m's waiting for work
// 空闲的工作线程的数量
nmidle int32 // number of idle m's waiting for work
nmidlelocked int32 // number of locked m's waiting for work
mnext int64 // number of m's that have been created and next M ID
// 最多只能创建maxmcount个工作线程
maxmcount int32 // maximum number of m's allowed (or die)
nmsys int32 // number of system m's not counted for deadlock
nmfreed int64 // cumulative number of freed m's
ngsys uint32 // number of system goroutines; updated atomically
// 由空闲的p结构体对象组成的链表
pidle puintptr // idle p's
// 空闲的p结构体对象的数量
npidle uint32
nmspinning uint32 // See "Worker thread parking/unparking" comment in proc.go.
// Global runnable queue.
// goroutine全局运行队列
runq gQueue
runqsize int32
......
// Global cache of dead G's.
// gFree是所有已经退出的goroutine对应的g结构体对象组成的链表
// 用于缓存g结构体对象,避免每次创建goroutine时都重新分配内存
gFree struct {
lock mutex
stack gList // Gs with stacks
noStack gList // Gs without stacks
n int32
}
......
}
M源码
type m struct {
// 每个m都有一个对应的g0线程,用来执行调度代码,
// 当需要执行用户代码的时候,g0会与用户goroutine发生协程栈切换
g0 *g // goroutine with scheduling stack
morebuf gobuf // gobuf arg to morestack
........................
// tls作为线程的本地存储
// 其中可以在任意时刻获取绑定到当前线程上的协程g、结构体m、逻辑处理器p、特殊协程g0等信息
tls [tlsSlots]uintptr // thread-local storage (for x86 extern register)
mstartfn func()
// 指向正在运行的goroutine对象
curg *g // current running goroutine
caughtsig guintptr // goroutine running during fatal signal
// 与当前工作线程绑定的p
p puintptr // attached p for executing go code (nil if not executing go code)
nextp puintptr
oldp puintptr // the p that was attached before executing a syscall
id int64
mallocing int32
throwing int32
// 与禁止抢占相关的字段,如果该字段不等于空字符串,要保持curg一直在这个m上运行
preemptoff string // if != "", keep curg running on this m
// locks也是判断g能否被抢占的一个标识
locks int32
dying int32
profilehz int32
// spining为true标识当前m正在处于自己找工作的自旋状态,
// 首先检查全局队列看是否有工作,然后检查network poller,尝试执行GC任务
//或者偷一部分工作,如果都没有则会进入休眠状态
spinning bool // m is out of work and is actively looking for work
// 表示m正阻塞在note上
blocked bool // m is blocked on a note
.........................
doesPark bool // non-P running threads: sysmon and newmHandoff never use .park
// 没有goroutine需要运行时,工作线程睡眠在这个park成员上
park note
// 记录所有工作线程的一个链表
alllink *m // on allm
schedlink muintptr
lockedg guintptr
createstack [32]uintptr // stack that created this thread.
.............................
}
P源码
// runtime/runtime2.go
type p struct {
// 全局变量allp中的索引位置
id int32
// p的状态标识
status uint32 // one of pidle/prunning/...
link puintptr
// 调用schedule的次数,每次调用schedule这个值会加1
schedtick uint32 // incremented on every scheduler call
// 系统调用的次数,每次进行系统调用加1
syscalltick uint32 // incremented on every system call
// 用于sysmon协程记录被监控的p的系统调用时间和运行时间
sysmontick sysmontick // last tick observed by sysmon
// 指向绑定的m,p如果是idle状态这个值为nil
m muintptr // back-link to associated m (nil if idle)
// 用于分配微小对象和小对象的一个块的缓存空间,里面有各种不同等级的span
mcache *mcache
// 一个chunk大小(512kb)的内存空间,用来对堆上内存分配的缓存优化达到无锁访问的目的
pcache pageCache
raceprocctx uintptr
deferpool [5][]*_defer // pool of available defer structs of different sizes (see panic.go)
deferpoolbuf [5][32]*_defer
// Cache of goroutine ids, amortizes accesses to runtime·sched.goidgen.
// 可以分配给g的id的缓存,每次会一次性申请16个
goidcache uint64
goidcacheend uint64
// Queue of runnable goroutines. Accessed without lock.
// 本地可运行的G队列的头部和尾部,达到无锁访问
runqhead uint32
runqtail uint32
// 本地可运行的g队列,是一个使用数组实现的循环队列
runq [256]guintptr
// 下一个待运行的g,这个g的优先级最高
// 如果当前g运行完后还有剩余可用时间,那么就应该运行这个runnext的g
runnext guintptr
// Available G's (status == Gdead)
// p上的空闲队列列表
gFree struct {
gList
n int32
}
.......................
// 用于内存对齐
_ uint32 // Alignment for atomic fields below
.......................
// 是否被抢占
preempt bool
// Padding is no longer needed. False sharing is now not a worry because p is large enough
// that its size class is an integer multiple of the cache line size (for any of our architectures).
}