软件工程导论(四)总体设计(临时)
模块耦合及其分类
A:定义
耦合:是对一个软件结构内不同模块间互连程序的度量。耦合强度取决于模块接口的复杂程度、通过接口的数据等。耦合度越高,模块独立性越弱
B:分类
耦合度从低到高
- 数据耦合
- 标记耦合
- 控制耦合
- 公共耦合
- 内容耦合
-
数据耦合(Data Coupling):两个模块之间通过共享数据来通信。模块可以读取、修改和使用另一个模块的数据。这种类型的耦合是可接受的,但是应该确保共享的数据被清晰地定义和文档化,以及被严格控制和保护。
-
标记耦合(Stamp Coupling):两个模块之间通过共享数据结构或标记来通信。一个模块修改数据结构或标记,另一个模块使用修改后的数据结构或标记。这种类型的耦合可以通过使用更具体的数据类型来减少。
-
控制耦合(Control Coupling):两个模块之间共享控制关系。一个模块调用另一个模块的方法,并传递控制信息,从而影响另一个模块的执行方式。这种类型的耦合是不可避免的,但应该尽可能地减少。
-
公共耦合(Common Coupling):两个或多个模块共享全局数据或资源,例如共享文件或数据库。这种类型的耦合使得模块之间高度依赖,导致代码难以维护和调试。应该尽可能避免使用这种类型的耦合。
-
内容耦合(Content Coupling):两个或多个模块共享数据或变量,并且一个模块依赖于另一个模块内部的实现细节。这种类型的耦合非常紧密,会导致代码难以理解、调试和重构。应该尽可能避免使用这种类型的耦合。
综上所述,不同的耦合类型表示不同级别的依赖关系,其中一些耦合类型是可接受的,而其他类型的耦合应该尽可能地避免。开发人员应该尽量使用低耦合的设计,以提高代码的可维护性、可扩展性和可重用性。
耦合之间的区别
五种耦合类型之间的区别主要在于它们描述了模块之间的不同级别的依赖关系。
-
数据耦合(Data Coupling):描述了两个模块之间通过共享数据来通信的关系,其中一个模块可以读取、修改和使用另一个模块的数据。这种类型的耦合较为宽松,但需要确保共享的数据被清晰地定义和文档化,以及被严格控制和保护。
-
标记耦合(Stamp Coupling):描述了两个模块之间通过共享数据结构或标记来通信的关系,其中一个模块修改数据结构或标记,另一个模块使用修改后的数据结构或标记。这种类型的耦合需要使用更具体的数据类型来减少依赖关系。
-
控制耦合(Control Coupling):描述了两个模块之间共享控制关系的关系,其中一个模块调用另一个模块的方法,并传递控制信息,从而影响另一个模块的执行方式。这种类型的耦合是不可避免的,但应该尽可能地减少依赖关系。
-
公共耦合(Common Coupling):描述了两个或多个模块共享全局数据或资源的关系,例如共享文件或数据库。这种类型的耦合使得模块之间高度依赖,导致代码难以维护和调试。应该尽可能避免使用这种类型的耦合。
-
内容耦合(Content Coupling):描述了两个或多个模块共享数据或变量,并且一个模块依赖于另一个模块内部的实现细节的关系。这种类型的耦合非常紧密,会导致代码难以理解、调试和重构。应该尽可能避免使用这种类型的耦合。
综上所述,不同的耦合类型描述了模块之间不同级别的依赖关系,一些耦合类型较为宽松,而其他类型的耦合较为紧密,需要谨慎使用。为了提高代码的可维护性、可扩展性和可重用性,开发人员应该尽可能地使用低耦合的设计。
模块内聚及其分类
A:定义
内聚:是用来度量一个模块内部各个元素彼此结合的紧密程度。内聚度越高,紧密程度越高
B:分类
内聚度从低到高。其中1-3属于低内聚;4-5属于中内聚;6-7属于高内聚
- 偶然内聚
- 逻辑内聚
- 时间内聚
- 过程内聚
- 通信内聚
- 功能内聚
- 信息内聚
软件工程中,内聚度描述了一个模块中各个元素(如函数、变量、类等)之间彼此联系的紧密程度。以下是七种内聚类型的特征:
-
偶然内聚(Coincidental Cohesion):模块内的元素之间没有任何明显的联系或关系,它们是因为历史原因而被放在一起的。这种内聚度最低,应该尽可能避免使用。
-
逻辑内聚(Logical Cohesion):模块内的元素之间有共同的目标或执行路径,例如执行同一项任务或对同一数据结构进行操作。这种内聚度较低,但是在某些情况下是可接受的。
-
时间内聚(Temporal Cohesion):模块内的元素按照时间顺序紧密地联系在一起,例如一个函数中包含了初始化、计算和输出结果等步骤。这种内聚度较低,应该尽可能避免使用。
-
过程内聚(Procedural Cohesion):模块内的元素按照执行顺序紧密联系在一起,例如一个函数完成一个特定的任务。这种内聚度较高,但是在某些情况下可能会导致函数过于庞大,难以维护。
-
通信内聚(Communicational Cohesion):模块内的元素通过传递消息或参数来实现联系,例如一个函数处理一个数据结构的某个部分。这种内聚度较高,但是在某些情况下可能会导致函数间的依赖关系过于复杂。
-
功能内聚(Functional Cohesion):模块内的元素按照执行相似的功能紧密联系在一起,例如一个函数执行一个特定的功能。这种内聚度最高,也是最理想的设计目标。
-
信息内聚(Informational Cohesion):模块内的元素按照共享相同的数据结构或输入输出参数紧密联系在一起,例如一个函数处理某个特定的数据结构。这种内聚度较高,但是在某些情况下可能会导致模块之间的依赖关系过于紧密。
综上所述,不同的内聚类型描述了模块内元素之间不同级别的联系,一些内聚类型较为松散,而其他类型的内聚较为紧密,需要谨慎使用。为了提高代码的可维护性、可扩展性和可重用性,开发人员应该尽可能地设计高内聚度的模块。
内聚之间的区别
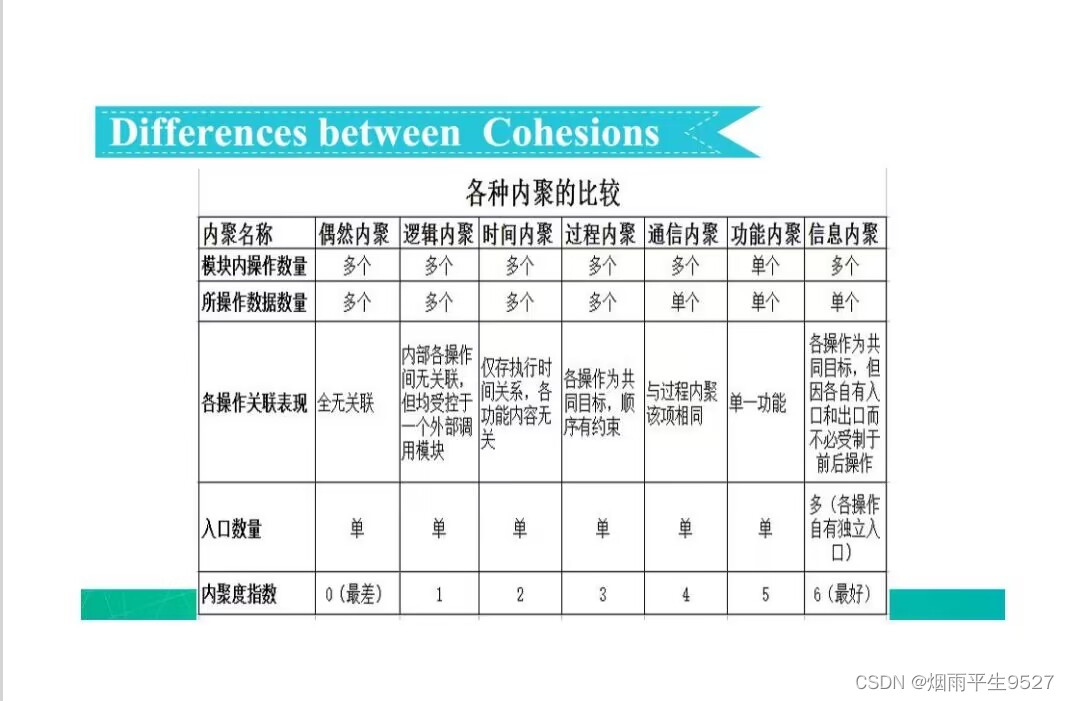
-
偶然内聚(Coincidental Cohesion):模块内的元素之间没有任何明显的联系或关系,它们是因为历史原因而被放在一起的,内聚度最低。
-
逻辑内聚(Logical Cohesion):模块内的元素之间有共同的目标或执行路径,例如执行同一项任务或对同一数据结构进行操作。它比偶然内聚高,但是较低的内聚度意味着它可能需要更多的维护。
-
时间内聚(Temporal Cohesion):模块内的元素按照时间顺序紧密地联系在一起,例如一个函数中包含了初始化、计算和输出结果等步骤。这种内聚度较低,应该尽可能避免使用。
-
过程内聚(Procedural Cohesion):模块内的元素按照执行顺序紧密联系在一起,例如一个函数完成一个特定的任务。这种内聚度较高,但是在某些情况下可能会导致函数过于庞大,难以维护。
-
通信内聚(Communicational Cohesion):模块内的元素通过传递消息或参数来实现联系,例如一个函数处理一个数据结构的某个部分。这种内聚度较高,但是在某些情况下可能会导致函数间的依赖关系过于复杂。
-
功能内聚(Functional Cohesion):模块内的元素按照执行相似的功能紧密联系在一起,例如一个函数执行一个特定的功能。这种内聚度最高,也是最理想的设计目标。
-
信息内聚(Informational Cohesion):模块内的元素按照共享相同的数据结构或输入输出参数紧密联系在一起,例如一个函数处理某个特定的数据结构。这种内聚度较高,但是在某些情况下可能会导致模块之间的依赖关系过于紧密。
综上所述,这些内聚度类型之间的差异在于它们描述了模块内部元素之间不同程度的联系和依赖关系,其中一些内聚度类型比其他类型更加紧密和理想,但需要开发人员权衡设计决策,选择最适合实际情况的内聚度类型。
耦合和内聚之间的联系
耦合和内聚都是软件设计中的重要概念,它们描述了不同模块之间的联系和模块内部元素之间的联系。耦合度和内聚度都是衡量模块设计质量的指标,它们之间是相互影响的关系。
通常来说,高内聚度和低耦合度是优秀的软件设计的目标。如果模块内部的元素紧密联系在一起,同时与其他模块之间的联系较弱,则可以更容易地进行维护和扩展。高内聚度的模块更容易进行单元测试和重构。相反,如果模块之间的联系过于紧密,则可能导致一个模块的更改需要对整个系统进行更改,因此会增加维护和扩展的复杂性。
内聚度和耦合度之间的关系可以概括为:高内聚度通常意味着低耦合度,因为元素在模块内部的联系紧密,不需要依赖其他模块。相反,低内聚度通常意味着高耦合度,因为模块之间的联系需要较多的相互依赖。
因此,软件设计中的耦合和内聚都是需要仔细权衡和平衡的因素,以获得优秀的设计。
耦合和内聚都是软件设计中非常重要的概念,它们的提高可以显著提高软件设计质量,同时也可以降低开发和维护的成本。具体来说,它们的影响有以下几点:
提高软件的可维护性:高内聚度和低耦合度的设计可以让系统的各个模块相互独立,使得维护工作更容易进行。如果设计的耦合度过高或者内聚度过低,将会增加系统的复杂度和维护难度。
提高软件的可扩展性:高内聚度和低耦合度的设计可以使系统更容易进行扩展。如果一个模块的功能需要改变,只需要更改这个模块本身,不会对其他模块产生影响,这使得系统更加灵活。
降低软件的开发成本:高内聚度和低耦合度的设计可以使得软件开发更加简单,因为模块之间的依赖关系更加清晰。这使得软件开发人员更容易理解和修改代码,同时也减少了出现错误的可能性。
提高软件的可重用性:高内聚度和低耦合度的设计可以使得系统中的代码更容易重用。如果一个模块被设计为可重用的,那么它可以被其他系统或者应用程序所使用,这样可以大大减少代码的重复编写。
总之,耦合和内聚对于软件设计的影响非常重要。通过设计高内聚度和低耦合度的系统,可以提高软件的质量、可维护性、可扩展性和可重用性,同时也可以降低开发和维护的成本。