电商用户画像数据可视化分析

电商用户画像数据可视化分析
作者:i阿极
作者简介:Python领域新星作者、多项比赛获奖者:博主个人首页
😊😊😊如果觉得文章不错或能帮助到你学习,可以点赞👍收藏📁评论📒+关注哦!👍👍👍
📜📜📜如果有小伙伴需要数据集和学习交流,文章下方有交流学习区!一起学习进步!💪
| 专栏案例:数据可视化分析案例 |
|---|
| 数据分析:某电商优惠卷数据分析 |
| 数据分析:旅游景点销售门票和消费情况分析 |
| 数据分析:消费者数据分析 |
| 数据分析:餐厅订单数据分析 |
| 数据分析:基于随机森林(RFC)对酒店预订分析预测 |
| 数据分析:基于K-近邻(KNN)对Pima人糖尿病预测分析 |
文章目录
- 电商用户画像数据可视化分析
- 1、前言
- 1.1什么是用户画像?
- 1.2描述电商用户画像维度
- 2、数据处理
- 3、数据可视化
- 3.1性别交易差异
- 3.2婚姻交易差异
- 3.3 文化程度
- 3.4 年龄段差异
- 4.用户画像仪表盘
- 总结
1、前言
1.1什么是用户画像?
用户画像是指根据用户的属性、行为、需求等信息而抽象出的一个标签化的用户模型。它是对用户信息进行标签化的过程,以方便计算机处理。用户画像的作用主要表现在以下几个方面:
- 精准营销:通过用户画像,企业可以了解目标用户的需求和偏好,从而制定更精准的营销策略,提高营销效果。
- 个性化推荐:基于用户画像,可以为用户提供个性化的产品和服务推荐,提升用户满意度和忠诚度。
- 产品优化:通过分析用户画像,企业可以了解用户的需求和痛点,针对性地优化产品功能和设计,提高产品的用户体验。
- 市场分析:用户画像可以帮助企业了解市场的整体趋势和用户需求变化,从而指导企业的市场决策。
因此,用户画像在电商、互联网、金融等各个领域都得到了广泛的应用。对于电商平台而言,建立准确的用户画像有助于更好地理解用户需求,提升用户体验,实现精准营销和个性化服务。
1.2描述电商用户画像维度
- 基础信息维度:包括用户的年龄、性别、地域、职业等基础信息,这些信息有助于了解用户的基本特征和背景。
- 购买行为维度:包括用户的购买频率、购买时间、购买商品种类等,这些信息可以揭示用户的购买习惯和购买力。
2、数据处理
首先,导入数据,数据包含基础信息维度,比如出生日期、性别、婚姻状况、文化程度等,以及购买行为维度,比如购买时间、购买频率、购买金额等。
import pandas as pd
data = pd.read_csv( r"D:\mydata\CSDNdata\用户画像数据.csv",encoding='gbk')
data.head()
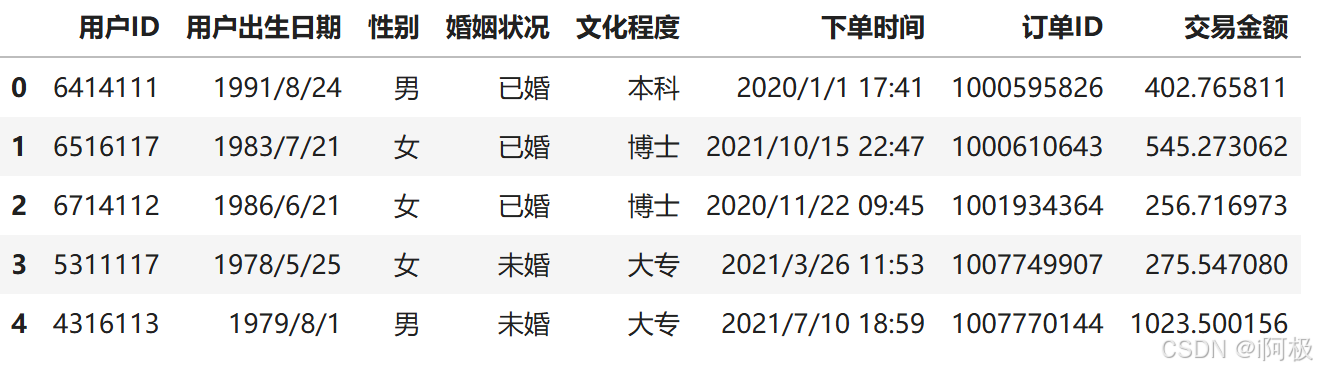
查看数据基本维度,如果有缺失值数据,可对缺失值数据做填充。
#查看是否有缺失值
data.info()
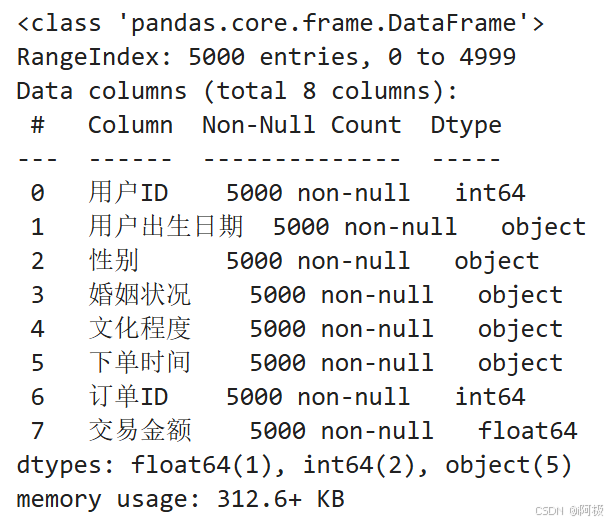
为了确保数据处理的准确性,对数据类型进行适当的检查和转换是非常重要的,如果两个不同类型的数据进行运算,可能会产生错误或不可预知的结果。比如,在算术运算中,如果一个是整数类型,另一个是字符串类型,那么这可能导致错误,因为这两种类型的数据无法进行数学运算。
#查看数据类型
data.dtypes

将用户出生日期处理为为日期数据类型
data['用户出生日期'] = pd.to_datetime(data['用户出生日期'],format='%Y/%m/%d')
将交易日期处理为日期数据类型
data['下单时间'] = pd.to_datetime(data['下单时间'],format='mixed').dt.date
将用户ID和订单ID转化为字符型数据
data['用户ID']=data['用户ID'].astype('str')
data['订单ID']=data['订单ID'].astype('str')
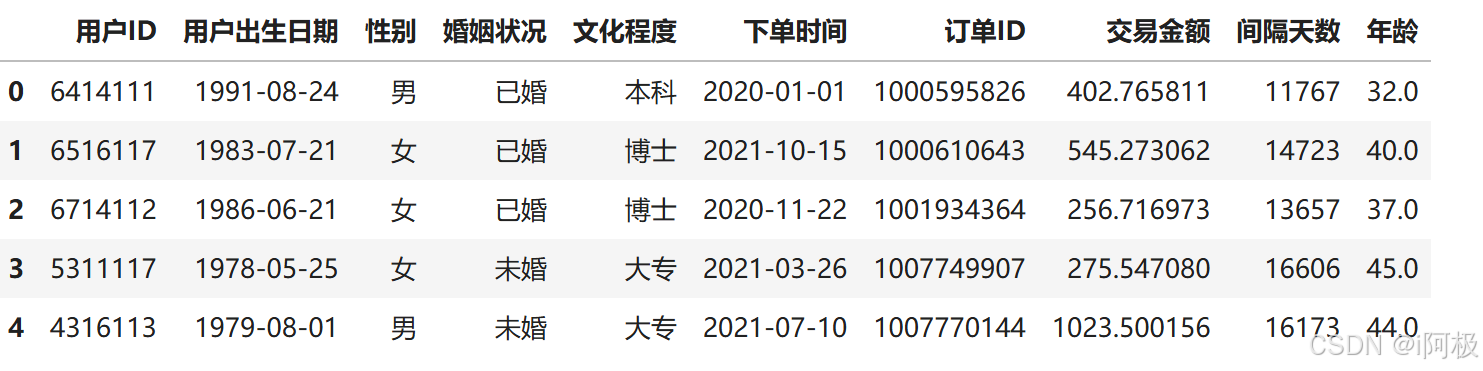
按照间隔天数近似计算用户的年龄。
# 假设2023-11-11是计算当天,求交易日期至计算当天的距离天数
data['间隔天数'] = pd.to_datetime('2023-11-11') - data['用户出生日期']
# 从时间距离中获取天数
data['间隔天数'] = data['间隔天数'].dt.days
data['年龄']=(data['间隔天数']/365).round(0)
data.head()
年龄求分位数
print('年龄最小值: {}'.format(data['年龄'].min()))
print('年龄平均值: {}'.format(data['年龄'].mean()))
print('年龄最大值: {}'.format(data['年龄'].max()))

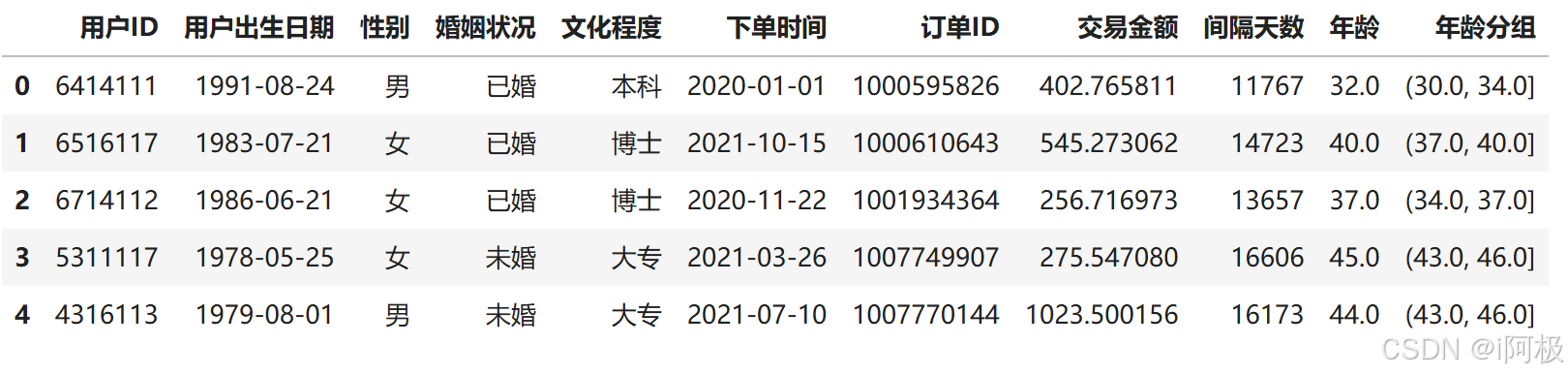
使用pd.qcut函数,将用户的年龄自动分组,按照相同的组距分为不同的年龄段
#自动分组
age_qcut=pd.qcut(data['年龄'],10)
data['年龄分组']=age_qcut
data.head()
3、数据可视化
3.1性别交易差异
性别分析作为用户画像中的重要组成部分,对于数据分析从业者来说,掌握其精髓并运用到实际工作中,无疑将为企业在激烈的市场竞争中获得更多的优势。这样的细分分析能够为企业提供更丰富的市场细分策略,帮助企业确定最有潜力的目标市场。
#不使用科学计数法,格式化为小数点后保留一位
pd.set_option('display.float_format', lambda x: '%.1f' % x)
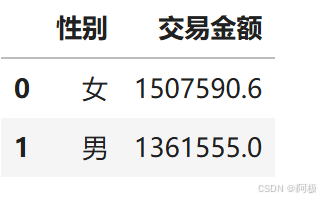
df_pay_sex=data.groupby('性别')['交易金额'].sum().reset_index()
df_pay_sex
x=df_pay_sex['交易金额'].tolist()
labels = df_pay_sex['性别'].tolist()
#饼图
plt.pie(x,#导入数据
autopct='%.1f%%',#数据标签
labels=labels,
startangle=90, #初始角度
pctdistance=0.87, # 设置百分比标签与圆心的距离
explode=[0.01,0], # 突出显示数据
textprops = {'fontsize':12, 'color':'k'}, # 设置文本标签的属性值
counterclock = False, # 是否逆时针
)
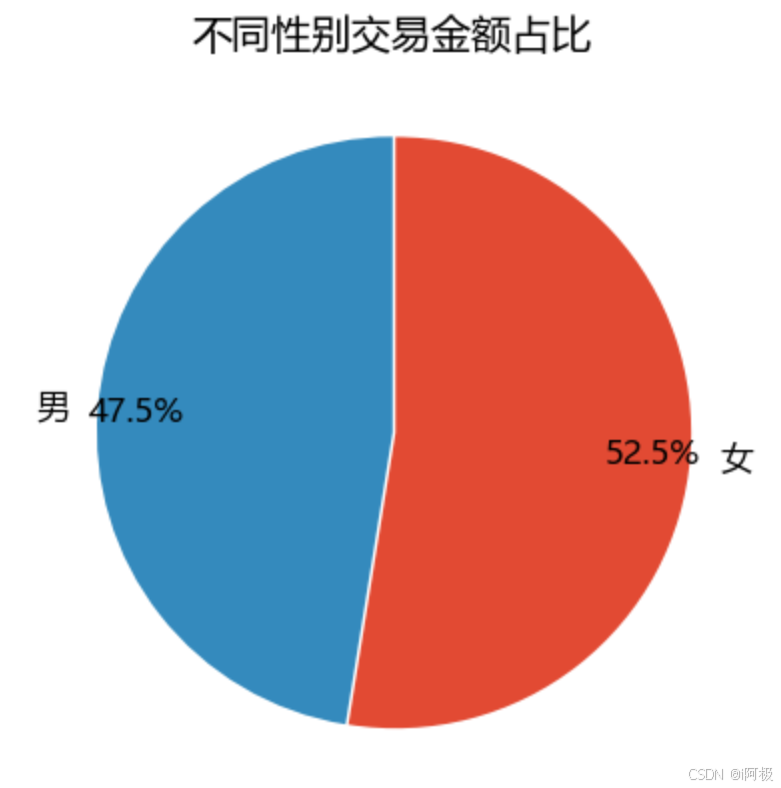
plt.title("不同性别交易金额占比")
plt.show()
3.2婚姻交易差异
婚姻状况分析对于经管专业的学习者来说是一项重要的任务。通过深入了解和分析用户的婚姻状况,企业能够更准确地把握用户需求和市场趋势,从而制定出更加精准有效的营销策略,提升市场竞争力。
#不使用科学计数法,格式化为小数点后保留一位
pd.set_option('display.float_format', lambda x: '%.1f' % x)
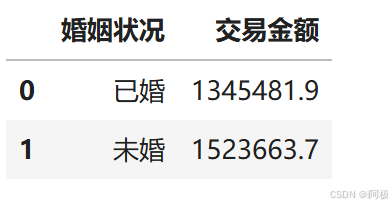
df_pay_mary=data.groupby('婚姻状况')['交易金额'].sum().reset_index()
df_pay_mary
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.style as psl
#魔法命令,用于在笔记本内联显示matplotlib图表
%matplotlib inline
#确保图表以SVG格式显示
%config InlineBackend.figure_format = 'svg'
plt.rcParams["font.sans-serif"] = 'Microsoft YaHei' #解决中文乱码问题
plt.rcParams['axes.unicode_minus'] = False #解决负号无法显示
psl.use('ggplot')
#plt.figure(figsize=(9, 6)) #设置图表画布大小
x=df_pay_mary['婚姻状况'].tolist()
y1=df_pay_mary['交易金额'].tolist()
#绘制圆环图
plt.pie(y1,#用于绘制饼图的数据,表示每个扇形的面积
labels=x,#各个扇形的标签,默认值为 None。
radius=1.0,#设置饼图的半径,默认为 1
startangle=90, #初始角度
explode=[0.01,0], # 突出显示数据
wedgeprops= dict(edgecolor = "w",width = 0.4),#指定扇形的属性,比如边框线颜色、边框线宽度等
autopct='%.1f%%',#设置饼图内各个扇形百分比显示格式,%0.1f%% 一位小数百分比
pctdistance=0.8#指定 autopct 的位置刻度
)
#设置标题
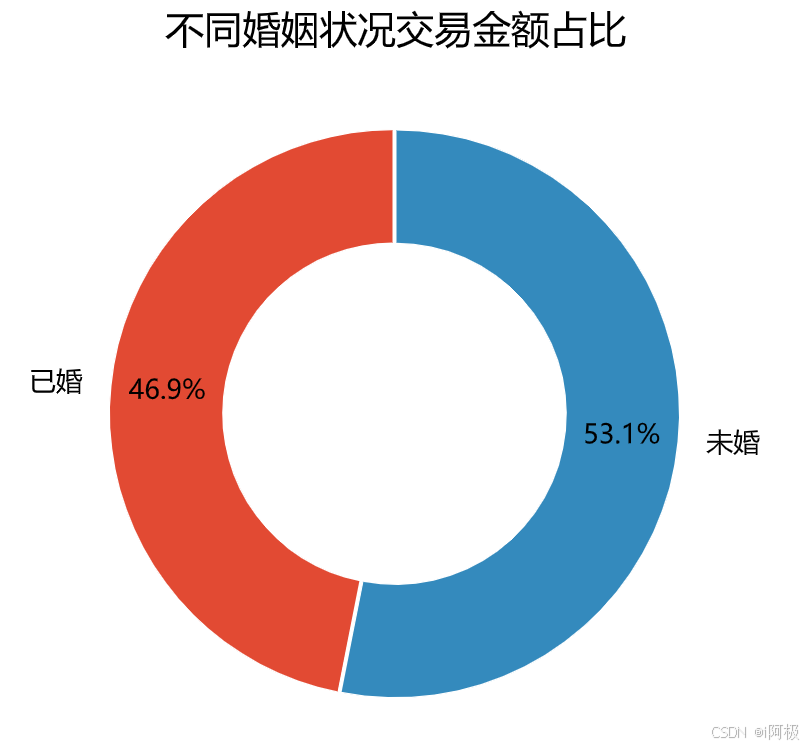
plt.title("不同婚姻状况交易金额占比", loc = "center")
#图像展示
plt.show()
3.3 文化程度
data['文化程度'].tolist()[:10]

#导入词云图包
from wordcloud import WordCloud
import matplotlib.pyplot as plt
#魔法命令,用于在笔记本内联显示matplotlib图表
%matplotlib inline
#确保图表以SVG格式显示
%config InlineBackend.figure_format = 'svg'
# 商品类别列表
product_categories = data['文化程度'].tolist()
# 使用字典统计商品类别数量
category_counts = dict()
for category in product_categories:
if category in category_counts:
category_counts[category] += 1
else:
category_counts[category] = 1
#创建词云对象
wordcloud = WordCloud(font_path='D:\\mydata\\CSDNdata\\msyh.ttf', background_color='white').generate_from_frequencies(category_counts)
# 使用matplotlib绘制词云图
plt.figure(figsize=(9, 6))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
#图像展示
plt.show()

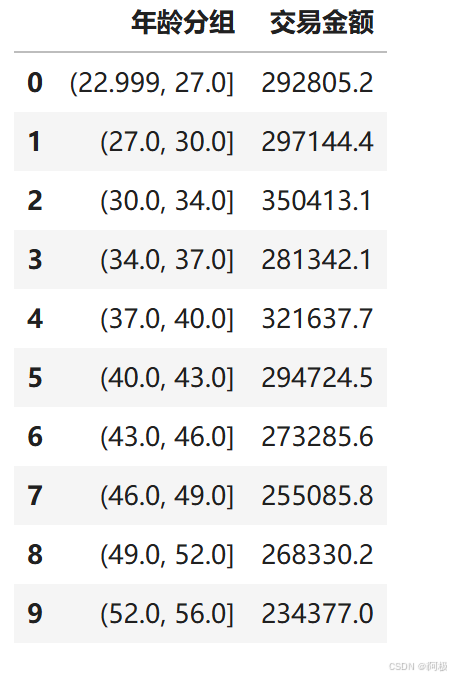
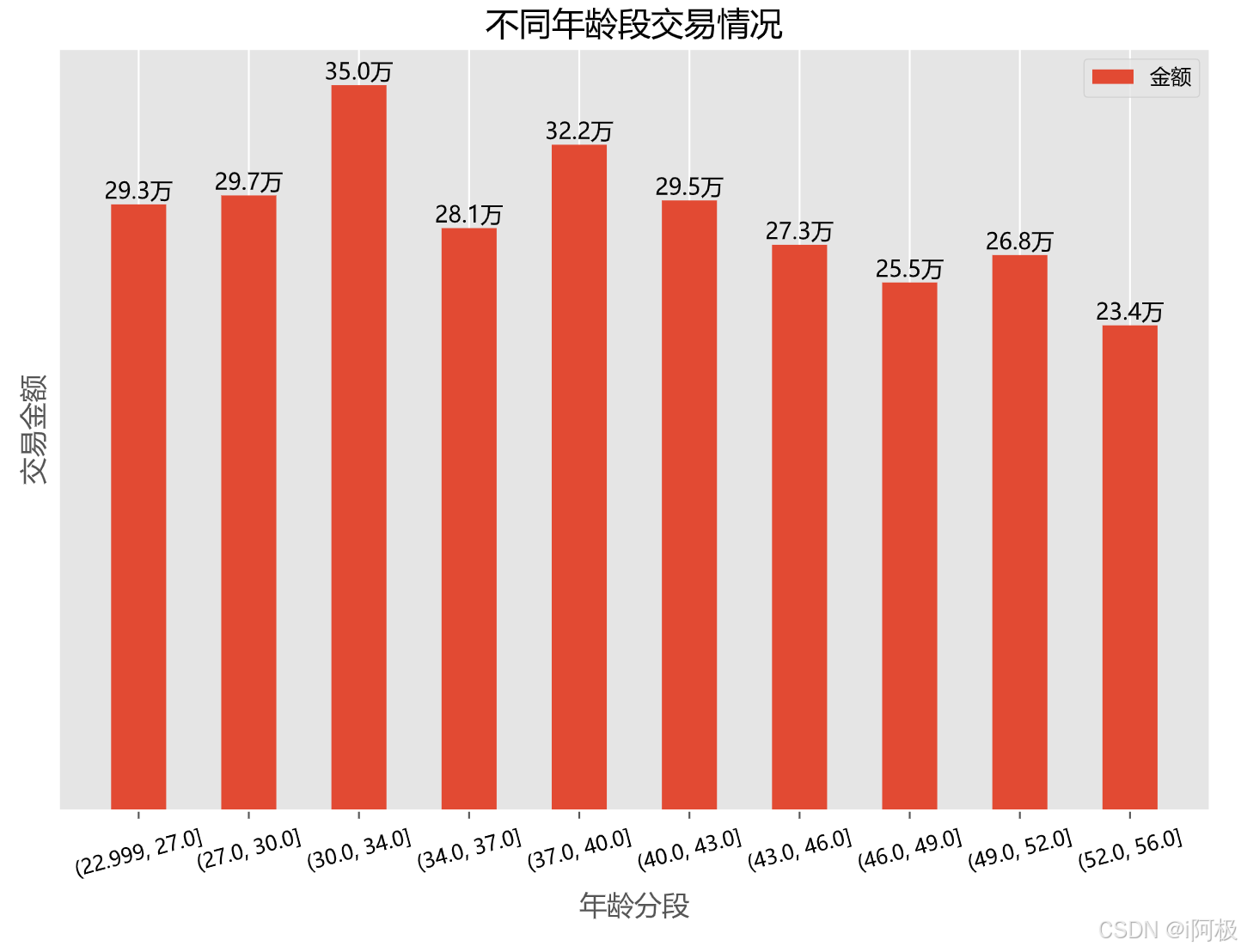
3.4 年龄段差异
df_age=data.groupby(['年龄分组'])['交易金额'].sum().reset_index()
df_age
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.style as psl
#魔法命令,用于在笔记本内联显示matplotlib图表
%matplotlib inline
#确保图表以SVG格式显示
%config InlineBackend.figure_format = 'svg'
plt.rcParams["font.sans-serif"] = 'Microsoft YaHei' #解决中文乱码问题
plt.rcParams['axes.unicode_minus'] = False #解决负号无法显示
#psl.use('ggplot')
plt.figure(figsize = (9, 6)) #设置图表画布大小
x=df_age['年龄分组'].astype('str').tolist()
y=df_age['交易金额'].tolist()
#绘制柱状图
plt.bar(x,y,width=0.5,align="center",label="金额")
plt.title("不同年龄段交易情况", loc="center")#设置标题
#添加数据标签
for a,b in zip(x, y):
plt.text(a,b,f'{b/10000:.1f}万',ha = "center", va = "bottom", fontsize = 10)
plt.xlabel("年龄分段",labelpad=5)#设置x和y轴的名称
plt.ylabel("交易金额")
plt.xticks(rotation=15,fontsize=9,color='k')#设置X坐标轴刻度
plt.yticks([])#设置不显示Y坐标轴刻度
plt.legend(fontsize=9,)#显示图例
plt.show()
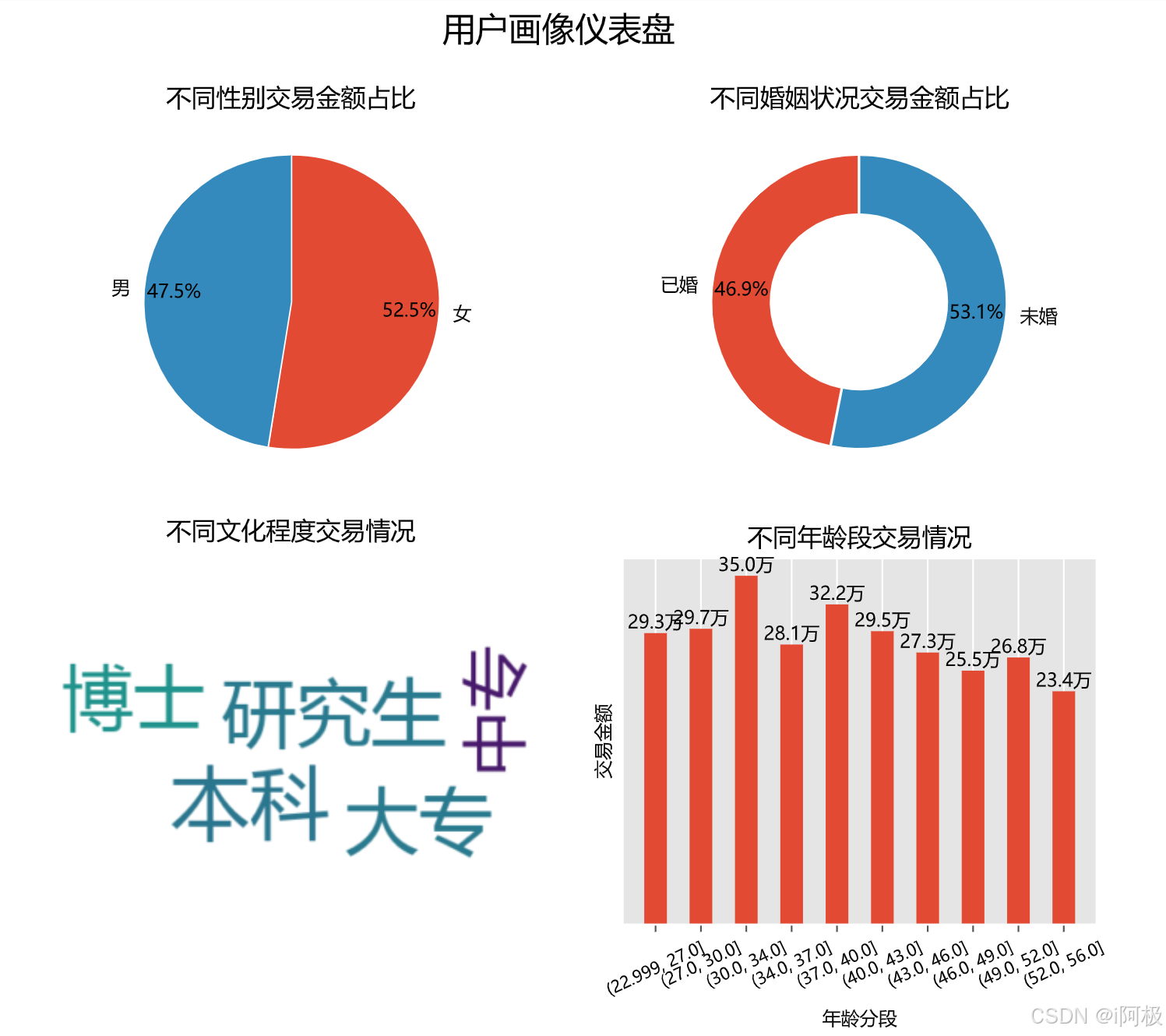
4.用户画像仪表盘
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.style as psl
#魔法命令,用于在笔记本内联显示matplotlib图表
%matplotlib inline
#确保图表以SVG格式显示
%config InlineBackend.figure_format = 'svg'
plt.rcParams["font.sans-serif"] = 'Microsoft YaHei' #解决中文乱码问题
plt.rcParams['axes.unicode_minus'] = False #解决负号无法显示
psl.use('ggplot')
plt.figure(figsize = (9, 7)) #设置图表画布大小
#饼图
plt.subplot(2,2,1)
#导入数据
x=df_pay_sex['交易金额'].tolist()
labels = df_pay_sex['性别'].tolist()
plt.pie(x,#导入数据
autopct='%.1f%%',#数据标签
labels=labels,
startangle=90, #初始角度
pctdistance=0.8, # 设置百分比标签与圆心的距离
explode=[0.01,0], # 突出显示数据
textprops = {'fontsize':9, 'color':'k'}, # 设置文本标签的属性值
counterclock = False, # 是否逆时针
)
plt.title("不同性别交易金额占比",fontsize=12,color='k')
#圆环图
plt.subplot(2,2,2)
x=df_pay_mary['婚姻状况'].tolist()
y1=df_pay_mary['交易金额'].tolist()
#绘制圆环图
plt.pie(y1,#用于绘制饼图的数据,表示每个扇形的面积
labels=x,#各个扇形的标签,默认值为 None。
radius=1.0,#设置饼图的半径,默认为 1
startangle=90, #初始角度
explode=[0.01,0], # 突出显示数据
wedgeprops= dict(edgecolor = "w",width = 0.4),#指定扇形的属性,比如边框线颜色、边框线宽度等
autopct='%.1f%%',#设置饼图内各个扇形百分比显示格式,%0.1f%% 一位小数百分比
textprops = {'fontsize':9, 'color':'k'}, # 设置文本标签的属性值
pctdistance=0.8#指定 autopct 的位置刻度
)
#设置标题
plt.title("不同婚姻状况交易金额占比",loc = "center",fontsize=12,color='k')
#词云图
plt.subplot(2,2,3)
# 商品类别列表
product_categories = data['文化程度'].tolist()
# 使用字典统计商品类别数量
category_counts = dict()
for category in product_categories:
if category in category_counts:
category_counts[category] += 1
else:
category_counts[category] = 1
#创建词云对象
wordcloud = WordCloud(font_path='D:\\mydata\\CSDNdata\\msyh.ttf', background_color='white').generate_from_frequencies(category_counts)
# 使用matplotlib绘制词云图
plt.title("不同文化程度交易情况", loc="center",fontsize=12,color='k',y=1.3)#设置标题
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
#柱形图
plt.subplot(2,2,4)
x=df_age['年龄分组'].astype('str').tolist()
y=df_age['交易金额'].tolist()
plt.bar(x,y,width=0.5,align="center",label="金额")
plt.title("不同年龄段交易情况", loc="center",fontsize=12,color='k')#设置标题
#添加数据标签
for a,b in zip(x, y):
plt.text(a,b,f'{b/10000:.1f}万',ha="center",va ="bottom",fontsize =9)
plt.xlabel("年龄分段",labelpad=5,fontsize =9,color='k')#设置x和y轴的名称
plt.ylabel("交易金额",fontsize =9,color='k')
plt.xticks(rotation=25,fontsize=8,color='k')#设置X坐标轴刻度
plt.yticks([])#设置不显示Y坐标轴刻度
plt.suptitle("用户画像仪表盘",fontsize=16,color='k')
plt.show()
#plt.savefig('my_figure1.png')
总结
此项目适合毕设和课设学习等等。如果需要数据集或源码(每个代码详解)可在博主首页的“资源”下载。
📢文章下方有交流学习区!一起学习进步!💪💪💪
📢首发CSDN博客,创作不易,如果觉得文章不错,可以点赞👍收藏📁评论📒
📢你的支持和鼓励是我创作的动力❗❗❗