每日学术速递3.27
CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CV
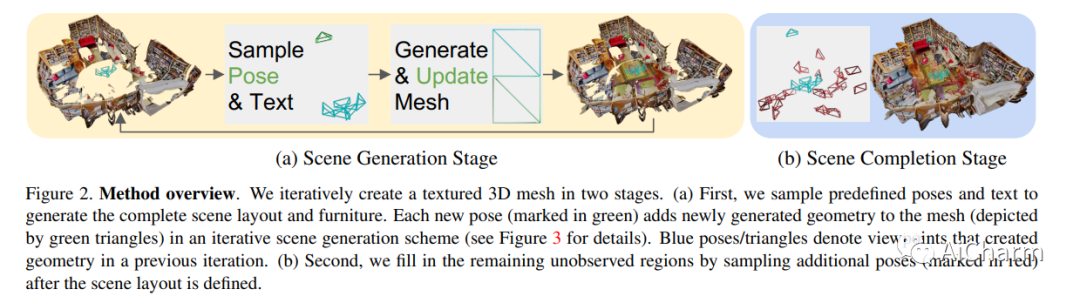
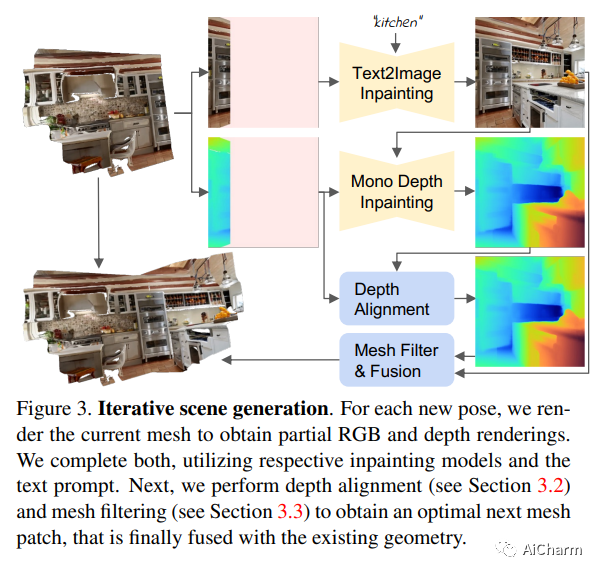
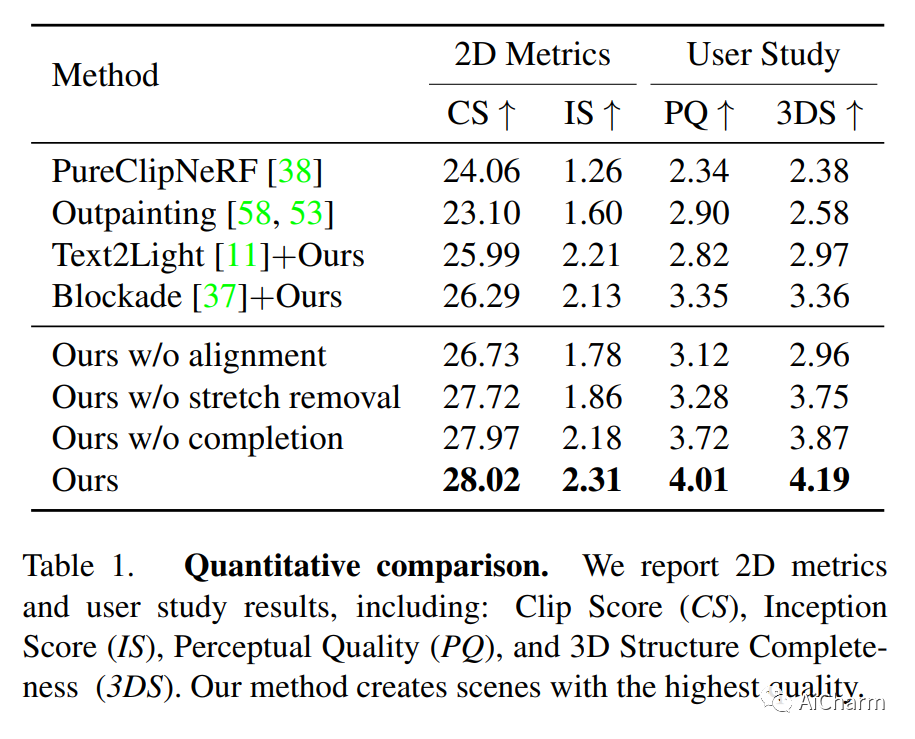
1.Text2Room: Extracting Textured 3D Meshes from 2D Text-to-Image Models

标题:Text2Room:从 2D 文本到图像模型中提取带纹理的 3D 网格
作者:Lukas Höllein, Ang Cao, Andrew Owens, Justin Johnson, Matthias Nießner
文章链接:https://arxiv.org/abs/2303.11989
项目代码:https://github.com/lukashoel/text2room
摘要:
我们介绍了 Text2Room,这是一种从给定文本提示作为输入生成房间尺度纹理 3D 网格的方法。为此,我们利用预训练的 2D 文本到图像模型来合成一系列来自不同姿势的图像。为了将这些输出提升为一致的 3D 场景表示,我们将单眼深度估计与文本条件修复模型相结合。我们方法的核心思想是量身定制的视点选择,这样每张图像的内容都可以融合到一个无缝的、有纹理的 3D 网格中。更具体地说,我们提出了一种连续对齐策略,该策略将场景帧与现有几何体迭代融合以创建无缝网格。与专注于从文本生成单个对象或缩小轨迹的现有作品不同,我们的方法生成具有多个对象和显式 3D 几何的完整 3D 场景。我们使用定性和定量指标评估我们的方法,证明它是第一种仅从文本作为输入生成具有引人注目的纹理的房间尺度 3D 几何图形的方法。
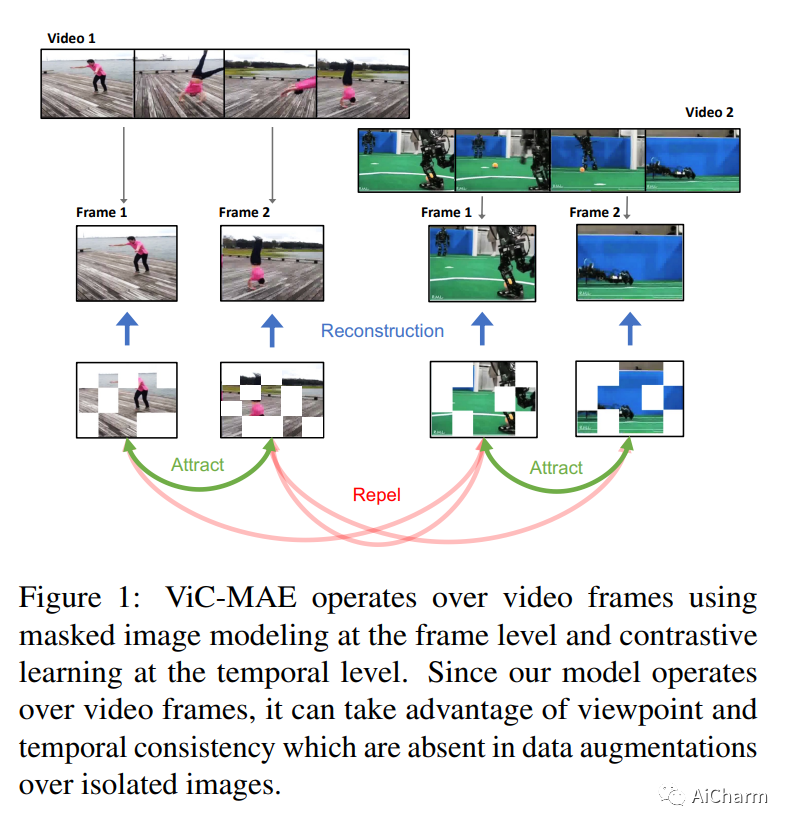
2.Visual Representation Learning from Unlabeled Video using Contrastive Masked Autoencoders

标题:使用对比掩码自动编码器从未标记视频中学习视觉表示
作者:Jefferson Hernandez, Ruben Villegas, Vicente Ordonez
文章链接:https://arxiv.org/abs/2303.12001
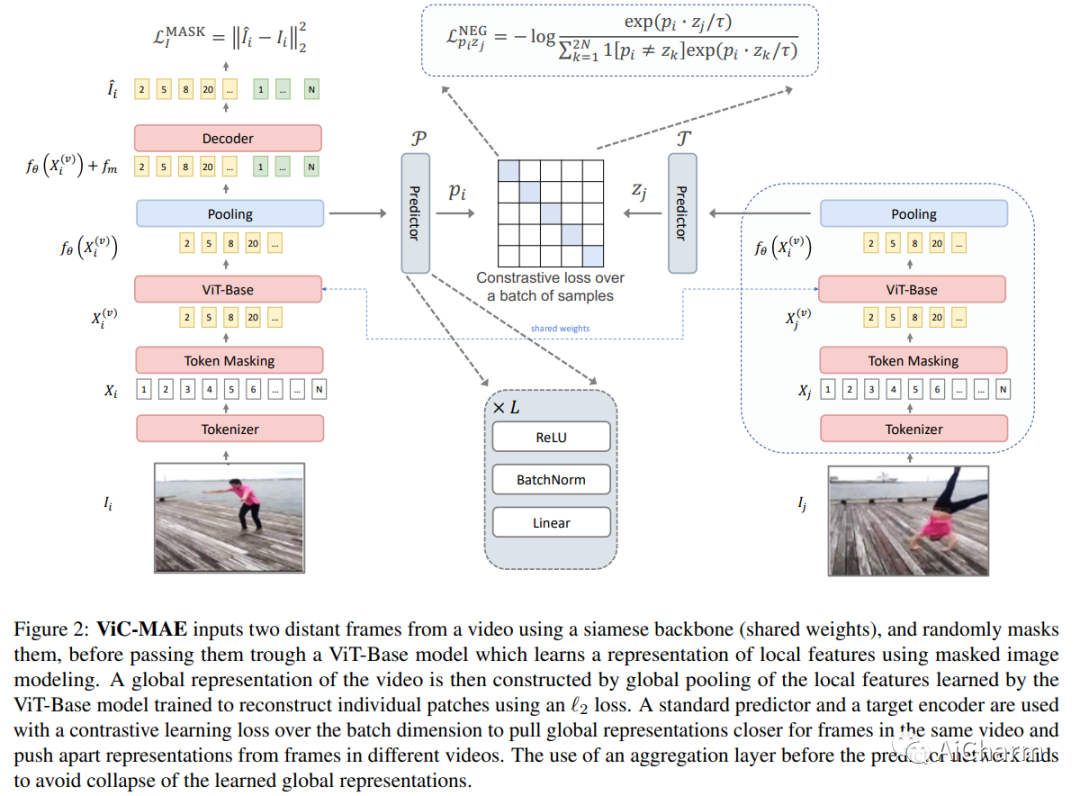
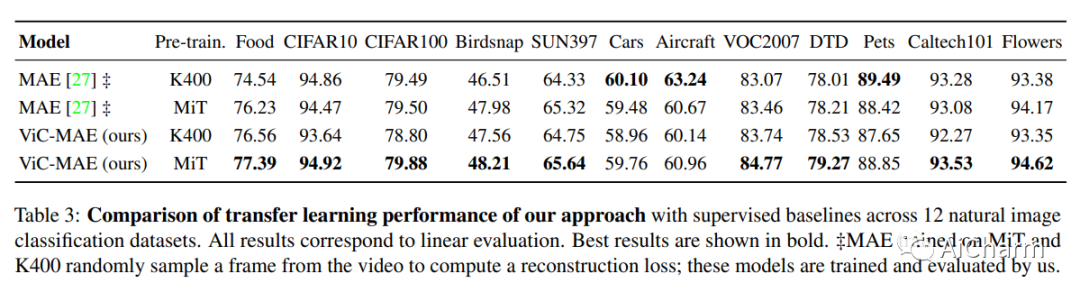
摘要:
掩码自动编码器 (MAE) 通过随机屏蔽输入图像块和重建损失来学习自我监督表示。或者,对比学习自监督方法鼓励相同输入的两个版本具有相似的表示,同时将不同输入的表示分开。我们提出了 ViC-MAE,这是一种结合 MAE 和对比学习的通用方法,它通过汇集在 MAE 重建目标下学习的局部特征表示,并在跨视频帧的对比目标下利用这种全局表示。我们表明,在 ViC-MAE 下学习的视觉表示可以很好地泛化到视频分类和图像分类任务。使用在 Moments in Time (MiT) 数据集上预训练的骨干 ViT-B/16 网络,我们在 Imagenet-1k 上通过提高 1.58% 的绝对 top-1 获得了从视频到图像的最先进的迁移学习最近一项工作的准确性。此外,我们的方法在 Kinetics-400 视频分类基准上保持了 81.50% top-1 准确率的竞争性迁移学习性能。此外,我们表明,尽管 ViC-MAE 很简单,但与将 MAE 预训练与之前提出的对比目标(如 VicReg 和 SiamSiam)相结合相比,ViC-MAE 产生了更好的结果。
3.Dexterity from Touch: Self-Supervised Pre-Training of Tactile Representations with Robotic Play

标题:触觉的灵巧性:通过机器人游戏进行触觉表征的自我监督预训练
作者:Irmak Guzey, Ben Evans, Soumith Chintala, Lerrel Pinto
文章链接:https://arxiv.org/abs/2303.12076
项目代码:https://tactile-dexterity.github.io/
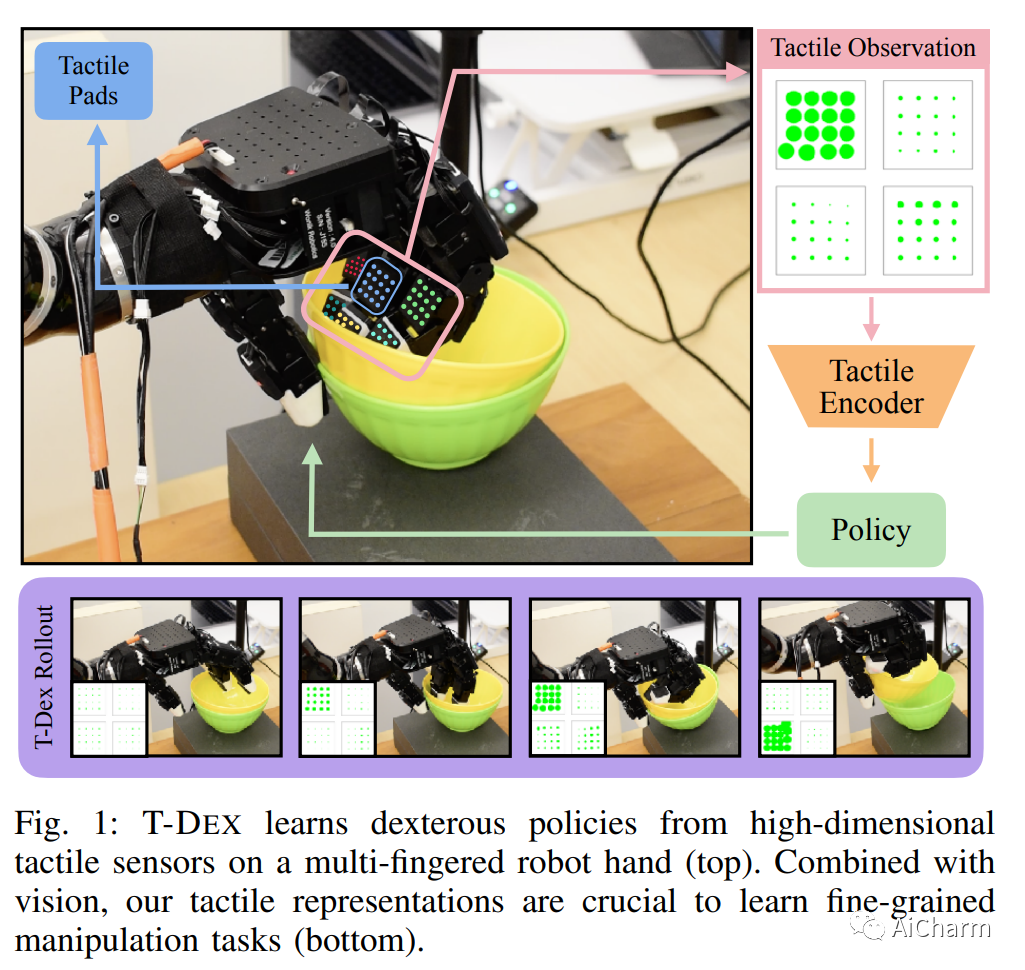
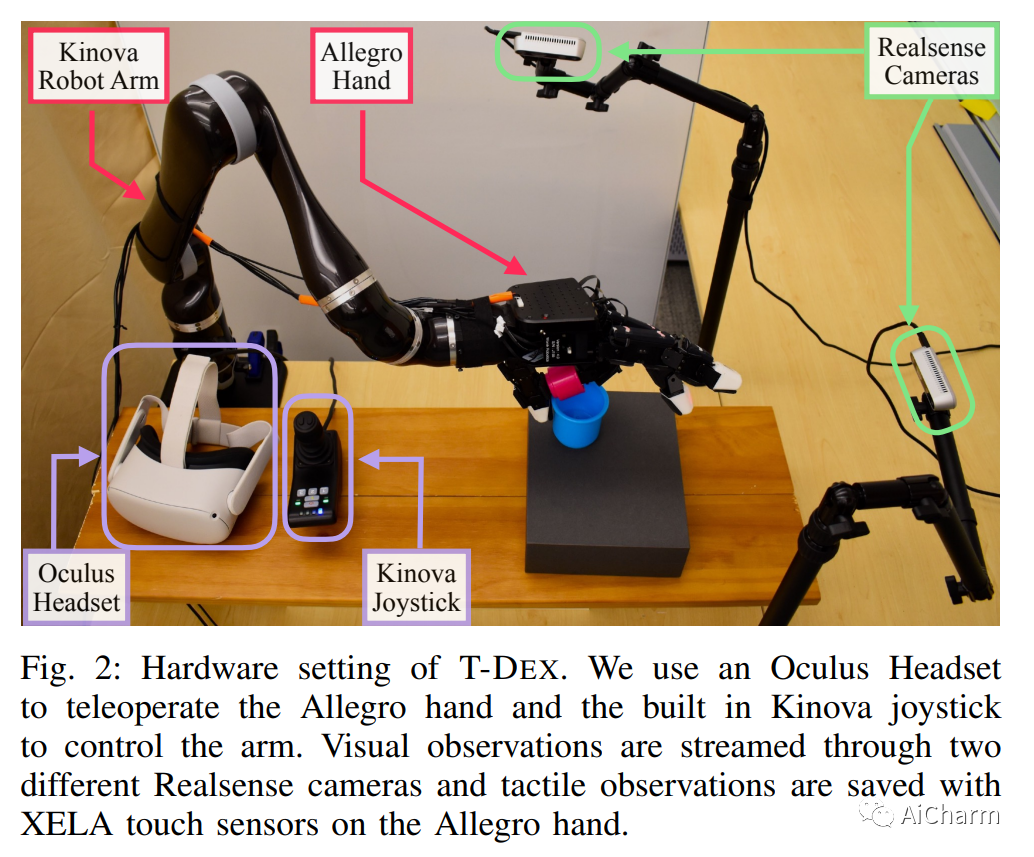
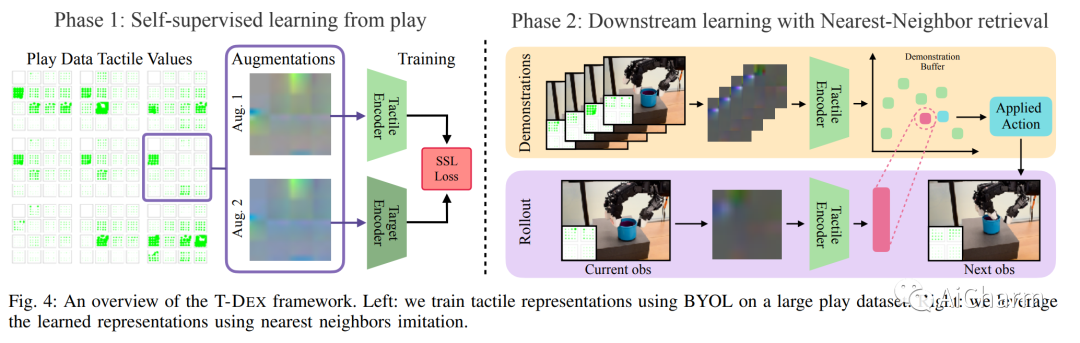
摘要:
向多指机器人教授灵巧性一直是机器人学领域的一项长期挑战。该领域最突出的工作集中在学习控制器或策略,这些控制器或策略对视觉观察或从视觉得出的状态估计进行操作。然而,这种方法在需要对接触力或手本身遮挡的物体进行推理的细粒度操作任务上表现不佳。在这项工作中,我们介绍了 T-Dex,这是一种基于触觉的灵巧性的新方法,分两个阶段运行。在第一阶段,我们收集了 2.5 小时的播放数据,用于训练自监督触觉编码器。这对于将高维触觉读数带入低维嵌入是必要的。在第二阶段,给出了一些灵巧任务的演示,我们学习了将触觉观察与视觉观察相结合的非参数策略。在五项具有挑战性的灵巧任务中,我们证明了我们基于触觉的灵巧性模型比纯视觉和基于扭矩的模型平均高出 1.7 倍。最后,我们对 T-Dex 的关键因素进行了详细分析,包括播放数据、架构和表征学习的重要性。
更多Ai资讯:公主号AiCharm