1500 字节 MTU | 溯源 / 技术权衡 / 应用影响
注:本文为 “MTU 字节” 相关文章合辑。
机翻,未校。
讨论部分,以提交人为分界。
单行只有阿拉伯数字的,为引文转译时对回复的点赞数。
How 1500 bytes became the MTU of the internet
1500 字节是如何成为互联网 MTU 的
Feb 19 2020

CC BY-SA 4.0 - Dmitry Nosachev_
Ethernet is everywhere, tens of thousands of hardware vendors speak and implement it. However almost every ethernet link has one number in common, the MTU:
以太网无处不在,成千上万的硬件供应商都在使用和实现它。然而,几乎每个以太网连接都有一个共同的数字,即 MTU:
$ ip l
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: enp5s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 state UP
link/ether xx:xx:xx:xx:xx:xx brd ff:ff:ff:ff:ff:ff
The MTU (Maximum Transmission Unit) states how big a single packet can be. Generally speaking, when you are talking to devices on your own LAN the MTU will be around 1500 bytes and the internet runs almost universally on 1500 as well. However, this does not mean that these link layer technologies can’t transmit bigger packets.
MTU(最大传输单元)规定了一个数据包可以有多大。一般来说,当你与自己局域网中的设备通信时,MTU 大约为 1500 字节,互联网也几乎普遍使用 1500。然而,这并不意味着这些链路层技术不能传输更大的数据包。
For example, 802.11 (better known as WiFi) has a MTU of 2304 bytes, or if your network is using FDDI_ then you have a MTU around 4352 bytes. Ethernet itself has the concept of “jumbo frames”, where the MTU can be set up to 9000 bytes (on supporting NICs, Switches and Routers).
例如,802.11(更广为人知的是 WiFi)的 MTU 为 2304 字节,或者如果你的网络使用 FDDI,那么你的 MTU 大约为 4352 字节。以太网本身有“巨型帧”的概念,MTU 可以设置到 9000 字节(在支持的网卡、交换机和路由器上)。
However, almost none of this matters on the internet. Since the backbone of the internet is now mostly made up of ethernet links, the de facto maximum size of a packet is now unofficially set to 1500 bytes to avoid packets being fragmented_ down links.
然而,在互联网上,这些几乎都不重要。由于互联网的骨干现在主要由以太网链路组成,为了避免数据包在链路上被 分片,数据包的实际最大大小现在非正式地被设置为 1500 字节。
On the face of it 1500 is a weird number, we would normally expect a lot of constants in computing to be based around mathematical constants, like powers of 2. 1500, however fits none of those.
从表面上看,1500 是一个奇怪的数字,我们通常会期望计算机中的许多常数是基于数学常数的,比如 2 的幂。然而,1500 并不符合这些。
So where did 1500 come from, and why are we still using it?
那么,1500 是从哪里来的,我们为什么还在使用它呢?
The magic number
神奇的数字
Ethernet’s first major break into the world came in the form of 10BASE-2 (cheapernet) and 10BASE-5 (thicknet), the numbers indicating roughly how many hundred meters a single network segment could span over.
以太网首次大规模进入世界的形式是 10BASE-2(廉价网)和 10BASE-5(粗缆网),这些数字大致表示一个网络段可以跨越多少百米。
The previous version of this post was wrong. Click here if you still wish to read the archived version
本文的先前版本是错误的。如果你仍然想阅读存档版本,请点击这里
Since there were many competing protocols at the time, and hardware limits existed, the original creator notes this in an email_ that the packet buffer memory requirements had some play in the magic 1500 number. (thanks to @yeled for finding this)
由于当时存在许多竞争协议和硬件限制,原始创建者在一封电子邮件中提到,数据包缓冲区内存需求对神奇的 1500 数字有一定影响。(感谢 @yeled 找到这个)
In retrospect, a longer maximum might have been better, but if it increased the cost of NICs during the early days it may have prevented the widespread acceptance of Ethernet, so I’m not really concerned.
回顾过去,最大长度更长可能更好,但如果它在早期增加了网卡的成本,可能会阻碍以太网的广泛接受,所以我不太担心。
However that is not the whole story. The “Ethernet: Distributed Packet Switching for Local Computer Networks” paper from 1980_ is a early note of the efficiency cost analysis of larger packets on a network. This being especially important to ethernet at the time, since ethernet networks would ether be sharing the same coax cable between all systems, or there would be ethernet hubs that would only allow one packet at a time to be transmitted around all members of the ethernet segment.
然而,这并不是全部。1980 年的 “以太网:局域计算机网络的分布式分组交换”论文是对网络中大数据包的效率成本分析的早期记录。这在当时对以太网尤为重要,因为以太网网络要么在所有系统之间共享同轴电缆,要么有以太网集线器,只允许一次向以太网段的所有成员传输一个数据包。
A number had to be picked that would mean that transmission latency on these shared (sometimes busy) segments would not be too high, but also that packet header overhead would not be too much. (see some of the tables on the paper linked above on page 15-16)
必须选择一个数字,使得在这些共享的(有时很忙的)段上的传输延迟不会太高,同时数据包头部开销也不会太大。(参见上述链接论文第 15-16 页的一些表格)
It would seem at best that the engineers at the time picked 1500 bytes, or around 12000 bits as the best “safe” value.
看起来,当时的工程师们选择了 1500 字节,或者大约 12000 比特,作为最“安全”的值。
Since then various other transmission systems have come and gone, but the lowest MTU value of them has still been ethernet at 1500 bytes. Going bigger than lowest MTU on a network will either result in IP fragmentation, or the need to do path MTU detection. Both of which have their own sets of problems. Even if sometimes large OS vendors dropped the default MTU to even lower at times._
自那以后,各种其他传输系统来来去去,但其中最低的 MTU 值仍然是以太网的 1500 字节。在网络中使用比最低 MTU 更大的值,要么会导致 IP 分片,要么需要进行路径 MTU 检测。这两者都有各自的问题。即使有时大型操作系统供应商有时会将默认 MTU 降低得更低。
The efficiency factor
效率因素
So now we know that the internet’s MTU is capped at 1500 mostly due to legacy latency numbers and hardware limits, how bad is this for the efficiency of the internet?
现在我们知道,互联网的 MTU 被限制在 1500,主要是由于遗留的延迟数字和硬件限制,这对互联网的效率有多大的影响呢?
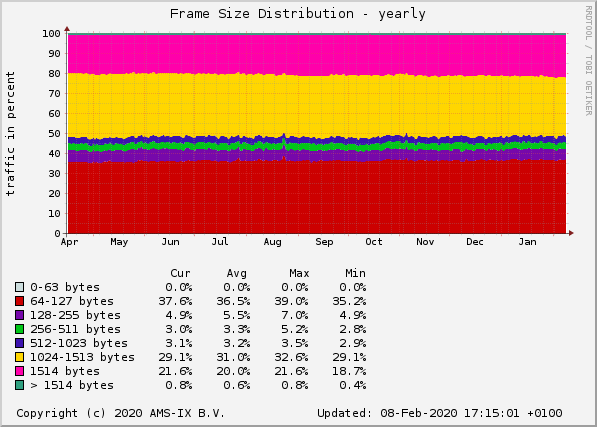
AMS-IX 以太网帧大小分布
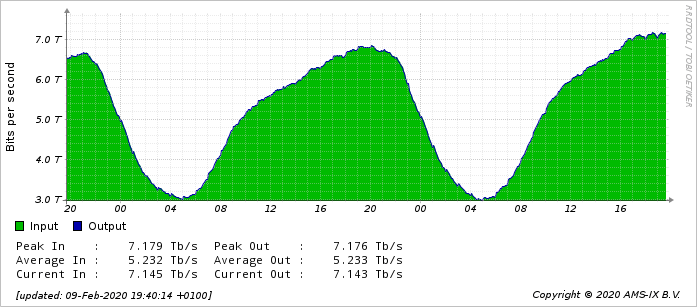
If we look at data from a major internet traffic exchange point (AMS-IX), we see that at least 20% of packets transiting the exchange are the maximum size. We can also see the total traffic of the LAN:
如果我们查看一个主要的互联网流量交换点(AMS-IX)的数据,我们会发现至少有 20% 的数据包在交换点达到了最大大小。我们还可以看到局域网的总流量:
AMS-IX 流量图
If you combine these two graphs, you get something that roughly looks like this. This is an estimation of how much traffic each packet size bucket is:
如果你将这两个图表结合起来,你会得到一个大致看起来像这样的东西。这是对每个数据包大小区间的流量的估计:
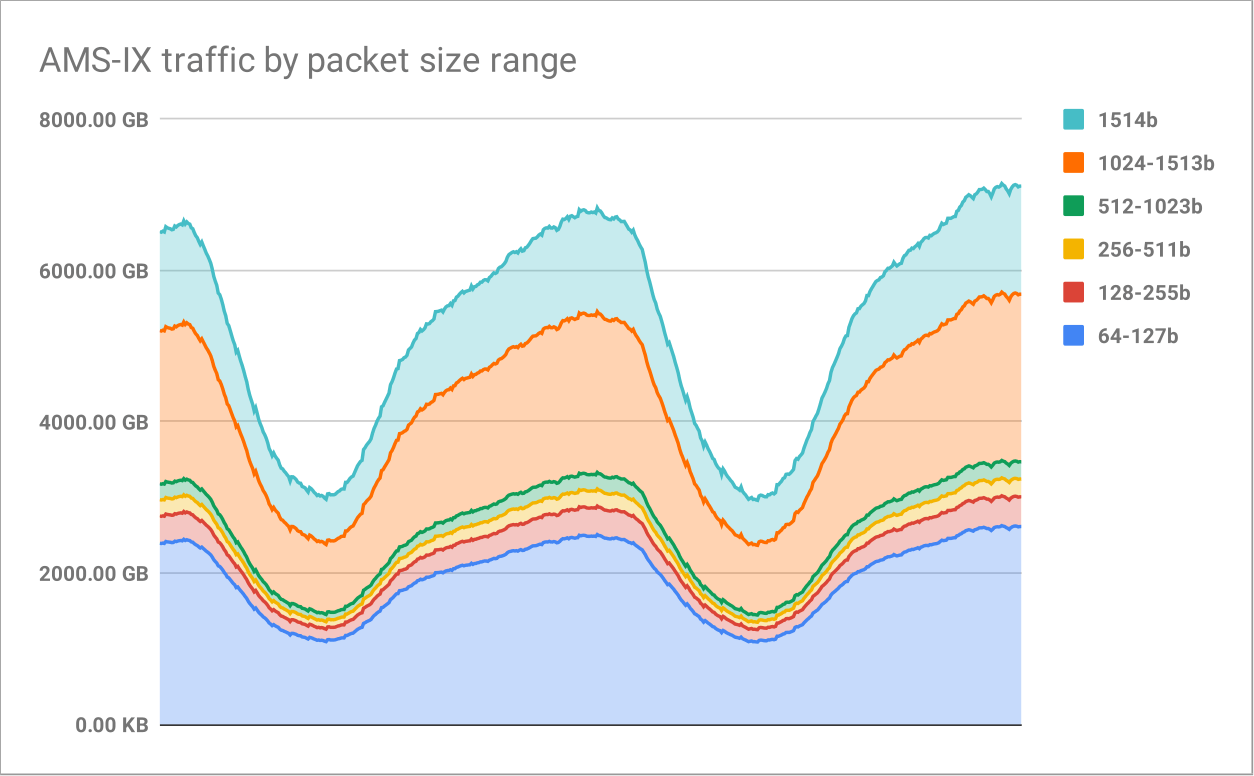
按数据包大小区间划分的 AMS-IX 流量
Or if we look at just the traffic that all of those ethernet preambles and headers cause, we get the same graph but with different scales:
或者,如果我们只看那些以太网前导码和头部引起的流量,我们会得到一个相同但比例不同的图表:

按数据包大小开销划分的 AMS-IX 流量
This shows a great deal of bandwidth being spent on headers for the largest packet class. Since the peak traffic shows the biggest packet bucket reading at around 246GBit/s of overhead we can assume that if we had all adopted jumbo frames while we had the chance to, this overhead would only be around 41GBit/s.
这表明大量的带宽被用于最大数据包类别的头部。由于峰值流量显示最大的数据包区间大约有 246Gbps 的开销,我们可以假设,如果我们有机会采用巨型帧,这个开销将只有大约 41Gbps。
But I think at this point, the ship has sailed to do this on the wider internet. While some internet transport carriers operate on 9000 MTU_, the vast majority don’t, and changing the internet’s mind collectively has been shown time and time again to be prohibitively difficult_.
但我认为,现在在更广泛的互联网上做这件事已经来不及了。尽管一些 互联网传输运营商使用 9000 MTU,但大多数都没有,而且一次又一次地证明,集体改变互联网的想法是极其困难的。
If you have more context on the history of 1500 bytes, please email them into ethernet1500@benjojo.co.uk.
Sadly the manuals, mailing list posts, and other context to this are disappearing fast without a trace.
如果你对 1500 字节的历史有更多的背景信息,请发送电子邮件至 ethernet1500@benjojo.co.uk。
遗憾的是,相关的手册、邮件列表帖子和其他背景信息正在迅速消失,不留痕迹。
How 1500 bytes became the MTU of the internet
1500 字节如何成为互联网的 MTU
by petercooper on Feb 19, 2020
433 points
162 comments
MrLeap on Feb 19, 2020
For… reasons, I found myself having to make a ‘driver’ for a PoE+ sensing device this month.
出于……原因,我发现自己本月不得不为一款 PoE + 感测设备编写一个“驱动程序”。
The manufacturer had an SDK, but compiling it requires an old version of Visual Studio - a bouquet of dependencies, and it had no OSX support.
制造商提供了 SDK,但编译它需要一个旧版本的 Visual Studio —— 一堆依赖项,而且它不支持 OSX。
None of the bundled applications would do what I needed (namely, let me forward the raw sensing data to another application… SOMEHOW).
捆绑的应用程序没有一个能满足我的需求(也就是,让我将原始感测数据转发到另一个应用程序…… somehow)。
The data isn’t encoded in the usual ways, so even 4 hours of begging FFMPEG were to no avail.
数据的编码方式并非常规方式,因此即使向 FFMPEG 求助了 4 个小时也毫无用处。
A few glances at wireshark payloads, the roughly translated documentation, and weighing my options, I embarked on a harrowing journey to synthesize the correct incantation of bytes to get the device to give me what I needed.
我看了看 wireshark 中的数据包负载,大致翻译了一下文档,并权衡了一下选项,然后踏上了一段艰难的旅程,试图合成出正确的字节组合,让设备给出我需要的东西。
I’ve never worked with RTP/RTSP prior to this – and I was disheartened to see nodejs didn’t have any nice libraries for them.
此前我从未接触过 RTP/RTSP —— 看到 nodejs 没有为它们提供任何好用的库,我感到很沮丧。
Oh well, it’s just udp when it comes down to it, right?
哦,反正归根结底它就是 UDP,对吧?
SO MY NAIVETE BEGOT A JOURNEY INTO THE DARKNESS.
所以我的天真开启了这段黑暗之旅。
Being a bit of an unknown - unknown, this project did not budget time for the effort this relatively impromptu initiative required.
由于这是一个未知的未知领域,这个项目并没有预留出时间来应对这种相对临时的行动所需的努力。
An element of sentimentality for the customer, and perhaps delusions of grandeur, I convinced myself I could just crunch it out in a few days.
出于对客户的某种情感因素,或许还有些不切实际的幻想,我说服自己可以在几天内搞定它。
A blur of coffee and 7 days straight crunch later, I built a daisy chain of crazy that achieved the goal I set out for.
在连续 7 天的咖啡和高强度工作之后,我搭建了一个疯狂的串联结构,实现了我设定的目标。
I read rfc3550 so many times I nearly have it committed to memory.
我读了那么多遍 rfc3550,几乎都能背下来了。
The final task was to figure out how to forward the stream I had ensorcelled to another application.
最后的任务是弄清楚如何将我施了魔法的数据流转发到另一个应用程序。
UDP seemed like the “right” choice, if I could preserve the heavy lifting I had accomplished to reassemble the frames of data… MTU sizes are not big enough to accommodate this (hence probably why the device uses RTP, LOL.).
如果我能保留我为重组数据帧所做的努力,UDP 似乎是一个“正确”的选择…… MTU 的大小不足以容纳这些数据(这大概也是设备使用 RTP 的原因,哈哈)。
OSX supports some hilariously massive MTU’s (It’s been a few days, but I want to say something like 13,000 bytes?)
OSX 支持一些非常巨大的 MTU(已经有些时日了,我想说大概是 13000 字节?)
Still, I’d have to chunk and reassemble each frame into quarters.
尽管如此,我仍然需要将每个数据帧分成四份并重新组装。
Having to write additional client logic to handle drops and OOO and relying on OSX’s embiggened MTU’s when I wanted this to be relatively OS independent… and the SHIP OR DIE pressure from above made me do bad.
我需要编写额外的客户端逻辑来处理丢包和乱序问题,并且依赖于 OSX 的超大 MTU,而我原本希望这个系统相对独立于操作系统……而且上面的压力让我不得不做出一些糟糕的选择。
At this point, I was so crunched out that the idea of writing reconnect logic and doing it with TCP was painful so I’m here to confess… I did bad…
到了这个时候,我已经筋疲力尽,写重连逻辑并用 TCP 来实现的想法让我痛苦不堪,所以我在这里坦白……我做错了……
The client application spawns a webserver, and the clients poll via HTTP at about 30HZ.
客户端应用程序启动了一个 Web 服务器,客户端通过 HTTP 以大约 30Hz 的频率轮询。
Ahhh it’s gross… I’m basically adrift on a misery raft of my own manufacture.
啊,这太糟糕了……我基本上是在自己制造的痛苦木筏上漂流。
Maybe protobufs would be better? I’ve slept enough nights to take a melon baller to the bad parts…
也许 protobuf 会更好?我已经睡了足够多的夜晚,用勺子挖掉那些糟糕的部分……
hinkley on Feb 19, 2020
https://en.m.wikipedia.org/wiki/Jumbo_frame The wiki page talks about getting 5 % more data through at full saturation but it doesn’t mention an important detail that I recall from when it was proposed.
https://en.m.wikipedia.org/wiki/Jumbo_frame 维基页面提到在满负荷时可以多传输 5 % 的数据,但它没有提到我从提案时就记得的一个重要细节。
It turned out with gigabit Ethernet or higher that a single TCP connection cannot saturate the channel with an MTU of 1500 bytes.
事实证明,对于千兆以太网或更高带宽的网络,单个 TCP 连接无法在 1500 字节的 MTU 下使通道达到满负荷。
The bandwidth went up but the latency did not go down, and ACKs don’t arrive fast enough to keep the sender from getting throttled by the TCP windowing algorithm.
带宽增加了,但延迟并没有降低,而且确认应答(ACK)到达的速度不够快,无法防止发送方被 TCP 窗口算法限制。
If I have a typical network with a bunch of machines on it nattering at each other, that might not sound so bad.
如果我有一个典型的网络,上面有许多机器在互相通信,这听起来可能并不太糟糕。
But when I really just need to get one big file or stream from one machine to another, it becomes a problem.
但如果我真正需要从一台机器向另一台机器传输一个大文件或数据流时,这就成了一个问题。
So they settled on a multiple of 1500 bytes to avoid uneven packet fragmentation (if you get half packets every nth packet you lose that much throughput).
因此,他们决定使用 1500 字节的倍数,以避免数据包分片不均匀(如果你每 n 个数据包就丢失一半的数据包,那么你的吞吐量就会减少这么多)。
Somehow that multiple became 6.
不知怎么的,这个倍数变成了 6。
And then other people wanted bigger or smaller and I’m not quite sure how OS X ended up with 13000.
然后其他人想要更大或更小的倍数,我不太清楚 OS X 是如何最终选择了 13000。
You’re gonna get 8 x 1500 + 1000 there. Or worse, 9000 + 4000.
你会得到 8 × 1500 + 1000。或者更糟,9000 + 4000。
hinkley on Feb 19, 2020
In college I only had one group project, which scandalized me but apparently lots of others found this normal.
在大学里,我只参加了一个小组项目,这让我感到震惊,但显然很多人都觉得这很正常。
We had to fire UDP packets over the network and feed them to an MJPeG card.
我们需要通过网络发送 UDP 数据包,并将它们传输到一个 MJPeG 卡上。
You got more points based on the quality of the video stream.
根据视频流的质量,你会得到更多的分数。
My very industrious teammate did 75 % of the work (4 man team, I did 20 %, if you are generous with the value of debugging).
我的非常勤奋的队友完成了 75 % 的工作(4 人团队,我做了 20 %,如果你对调试的价值慷慨一些的话)。
One of the things we/he tried was to just drop packets that arrived out of order rather than reorder them.
我们 / 他尝试过的一种方法是直接丢弃乱序到达的数据包,而不是对它们重新排序。
Turned out the reordering logic was reducing framerates.
结果发现,重新排序的逻辑降低了帧率。
So he ran some trials and looked at OOO traffic, and across the three or so routers between source and sink he never observed a single packet arriving out of order.
于是他进行了一些试验,观察了乱序流量,在源和目的地之间的大约三个路由器之间,他从未观察到任何一个数据包乱序到达。
So we just dropped them instead and got ourselves a few more frames per second.
于是我们直接丢弃了它们,结果每秒多得到了几帧。
pantalaimon on Feb 19, 2020
Tbh that’s what most real - time video/audio applications will do. Reordering adds latency and that is worse than the occasional dropped frame.
说真的,大多数实时视频 / 音频应用程序都会这样做。重新排序会增加延迟,这比偶尔丢弃一帧更糟糕。
MrLeap on Feb 19, 2020
I can drop a frame, I can’t casually drop misordered packets. It takes many packets to build a frame. I have to reorder interframe packets (actually I just insert - in - order). If I drop packets, I get data scrolling like a busted CRT raster.
我可以丢弃一帧,但我不能随意丢弃乱序的数据包。构建一帧需要许多数据包。我必须对帧间数据包进行重新排序(实际上我只是按顺序插入)。如果我丢弃数据包,数据就会像坏掉的阴极射线管显示器一样滚动。
I’m using a KoalaBarrel. Koalas receive envelopes full of eucalyptus leaves. Koalas have to eat their envelopes in order. First koala to get his full subscription becomes fat enough to crush all the koalas beneath him. Keep adding koalas. Disregard letters addressed to dead koalas.
我正在使用一个考拉桶。考拉收到装满桉树叶的信封。考拉必须按顺序吃掉它们的信封。第一个拿到全部订阅的考拉会变得足够胖,压碎它下面的所有考拉。继续添加考拉。忽略寄给已死考拉的信件。
shawnz on Feb 19, 2020
Not saying this is the ideal solution, but you could just drop any frame that contains any out of order packets. If an out of order packet arrives, just drop the current frame and start ignoring packets until you find the start of another frame.
我不是说这是理想的解决方案,但你可以直接丢弃任何包含乱序数据包的帧。如果一个乱序数据包到达,直接丢弃当前帧,并开始忽略数据包,直到找到另一个帧的开头。
madddiagnosis on Feb 20, 2020
This is very dependent on the frame in question, iframes are much more valuable than p/b frames. If you get unlucky with dropped frames you can end up showing a lot of distorted nonsense to the end user.
这非常依赖于所讨论的帧,I 帧比 P/B 帧更有价值。如果你不幸丢失了帧,你可能会向最终用户展示大量扭曲的无意义内容。
anticensor on Feb 19, 2020
embiggened For non - native speakers: embiggened means huge, enlarged, overgrown. I am not a native speaker of English either
embiggened 对于非母语者:embiggened 意为巨大、增大、过度生长。我也不是英语母语者
squiggleblaz on Feb 19, 2020
For non - Simpsons watchers The word was created as a joke in a Simpsons episode, a word used in Springfield only. It is described as “perfectly cromulent” by a Springfielder, which is evidently meant to mean “acceptable” or “ordinary” but is another Springfieldism. The joke may be lost on future generations who don’t realise they’re not normal words.
对于不看《辛普森一家》的人来说,这个词是在一集《辛普森一家》中作为玩笑创造的,仅在春田镇使用。一个春田镇人将其描述为“完全符合要求”,这显然意味着“可以接受”或“普通”,但这是另一个春田镇特有的词汇。这个玩笑可能会让未来的观众感到困惑,因为他们不知道这些并不是普通的单词。
skykooler on Feb 19, 2020
Actually, “embiggened” is an actual word, though archaic, it’s been around for over 130 years. The coinage of “cromulant” to describe it as such was the joke there, not “embiggen” itself.
实际上,“embiggened”是一个真正的单词,尽管它已经过时,但它已经存在了超过 130 年。将“cromulant”这个词用来描述它是玩笑,而不是“embiggen”本身。
kalleboo on Feb 19, 2020
The show writers thought they came up with the word on their own, they didn’t know about the previous usage of the word in 1884 (the episode was written in 1996, the internet wasn’t quite as full of facts back then), “embiggen” was still supposed to be a joke.
该剧的编剧以为他们是自己创造的这个词,他们不知道这个词在 1884 年就已经被使用过(这一集是在 1996 年写的,那时候互联网还没有那么多事实信息),“embiggen”仍然被认为是一个玩笑。
kahirsch on Feb 19, 2020
It was used once in 1884 and the writer there specifically said he invented it. There are no other recorded uses of the word before The Simpsons.
这个词在 1884 年被使用过一次,而且当时的作者明确表示是他创造的。在《辛普森一家》之前,没有其他记录显示这个词被使用过。
MrLeap on Feb 19, 2020
To be fair to everyone, I’ve had native English speakers tell me what I speak is barely English.
为了对每个人公平,我曾遇到过英语母语者告诉我,我说的英语勉强能算英语。
alasdair_ on Feb 20, 2020
To be fair, I have had Americans complement me on how well I have learned English when I tell them I am from the United Kingdom…
说句公道话,曾有美国人夸我英语学得很好,当我告诉他们我是来自英国的时候……
rasz on Feb 20, 2020
You cant expect too much from College education https://www.youtube.com/watch?v=kRh1zXFKC_o
你不能对大学教育期望过高 https://www.youtube.com/watch?v=kRh1zXFKC_o
jtbayly on Feb 19, 2020
This needs to be its own post. Lol.
这应该单独发一篇帖子。哈哈。
sneak on Feb 19, 2020
What does it sense that changes >= 30 times a second?
它感知的是什么,会在一秒钟内变化 >= 30 次?
ses1984 on Feb 19, 2020
I’m guessing video frames given ffmpeg was part of the story.
我猜是视频帧,因为 ffmpeg 是故事的一部分。
dahfizz on Feb 19, 2020
You only use the Real Time Protocol (RTP) when you need time sensitive data streaming (typically audio or video)
只有当你需要对时间敏感的数据流(通常是音频或视频)时,你才会使用实时协议(RTP)。
jsight on Feb 19, 2020
I was curious about that to. Lots of references to video related standards that imply its a PoE camera, but then why isn’t the data encoded in the usual ways? What does that mean?
我也很好奇。有很多关于视频相关标准的引用,暗示它是一个 PoE 摄像头,但为什么数据不是以通常的方式编码呢?这是什么意思?
MrLeap on Feb 19, 2020
What codec would you use for a camera that captures not RGB, but poetry of the soul? CONTEXTLESS, HEADERLESS, ENDLESS BYTE STREAMS OF COURSE, where the literal, idealized (remember udp) position of each byte is part of a vector in a non - euclidean coordinate system.
你会用什么编解码器来处理一个不是捕捉 RGB,而是捕捉灵魂的诗意的摄像头呢?当然是无上下文、无头部、无尽的字节流,其中每个字节的实际、理想化(记住是 UDP)位置是一个非欧几里得坐标系中的向量的一部分。
cfallin on Feb 19, 2020
What codec would you use for a camera that captures not RGB, but poetry of the soul? I would love to read a collaborative work between you and James Mickens – this genre of writing seems sadly under - present in the computing world…
你会用什么编解码器来处理一个不是捕捉 RGB,而是捕捉灵魂的诗意的摄像头呢?我很想读到你和 James Mickens 的合作作品——这种类型的写作在计算机领域似乎很遗憾地被低估了……
MrLeap on Feb 20, 2020
I appreciate the interest in listening to a simulcast of Harvard - Professor - Collaborates - With - A - Nobody - Hobo. I’ll forward this to my agent. My agent is a tin can. I think she used to hold beans. Sometimes I put a few smashed nickels in her and rattle. While I do this, I pretend she’s reading me my messages, and I’m like “oh no, I would never consent to a biopic directed by THAT charlatan.” and then we laugh and laugh. Oh how we laugh.
我很感谢你对收听哈佛教授与无名流浪汉合作广播的兴趣。我会把这转发给我的经纪人。我的经纪人是一个锡罐。我想她以前是用来装豆子的。有时我会在她里面放几枚被压扁的镍币,然后摇晃。当我这样做的时候,我会假装她在读我的信息,然后我会说:“哦,不,我绝不会同意由那个江湖骗子执导的传记电影。”然后我们大笑,大笑。我们笑得多么开心啊。
vermilingua on Feb 20, 2020
Sounds like Crestron, and if so I feel for you.
听起来像是 Crestron,如果是这样的话,我同情你。
mhandley on Feb 19, 2020
For 802.11, the biggest overhead is not packet headers but the randomized medium aquisition time so as to minimize collisions. 1500 bytes is way too small here with modern 802.11, so if you only send one packet for each medium aquisition, you end up with something upwards of 90 % overhead. The solution 802.11n and later uses here is to use Aggregate MPDUs (AMPDUs). For each medium aquisition, the sender can send multiple packets in a contiguous burst, up to 64 KBytes. This ends up adding a lot of mechanism, including a sliding window block ack, and it impacts queuing disciplines, rate adaptation and pretty much everything else. Life would be so much simpler if the MTU had simply grown over time in proportion to link speeds.
对于 802.11 来说,最大的开销不是数据包头部,而是随机的介质获取时间,以尽量减少碰撞。在现代 802.11 中,1500 字节太小了,因此如果你每次介质获取只发送一个数据包,最终会得到超过 90 % 的开销。802.11n 及以后版本的解决方案是使用聚合 MPDU(AMPDU)。对于每次介质获取,发送方可以连续发送多个数据包,最多可达 64 KB。这最终增加了很多机制,包括滑动窗口块确认,它还影响排队规则、速率适应以及几乎所有其他方面。如果 MTU 能够随着时间的推移按比例增长,生活就会简单得多。
wtallis on Feb 19, 2020
Life would be so much simpler if the MTU had simply grown over time in proportion to link speeds. The problem is that the world went wireless, so maximum link speeds grew a lot but minimum link speeds are still relatively low. A single 64kB packet tying up a link for multiple milliseconds—unconditionally delaying everything else in the queue by at least that much—is not what we want.
如果 MTU 能够随着时间的推移按比例增长,生活就会简单得多。问题是世界走向了无线化,因此最大链路速度增长了很多,但最小链路速度仍然相对较低。一个 64kB 的数据包占据链路多个毫秒——无条件地将队列中的其他所有内容延迟至少这么多——这不是我们想要的。
inetknght on Feb 19, 2020
The problem is that the world went wireless, so maximum link speeds grew a lot but minimum link speeds are still relatively low. I would argue: the problem is that the MTU isn’t negotiated at all, but especially not based on link availability.
问题是世界走向了无线化,因此最大链路速度增长了很多,但最小链路速度仍然相对较低。我会说:问题是 MTU 根本没有协商,特别是没有根据链路可用性进行协商。
snuxoll on Feb 19, 2020
IPv6 tries to solve this with path MTU discovery.
IPv6 试图通过 PMTU 发现来解决这个问题。
inetknght on Feb 19, 2020
Yes, but IPv6 is still at a higher level than Ethernet, Wifi, et al and is therefore subject to the limitations of the lower level framing.
是的,但 IPv6 仍然比以太网、WiFi 等处于更高层次,因此它受到低层帧结构的限制。
jandrese on Feb 19, 2020
Sure, I mean that’s what pMTUd is all about. One big difference with IPv6: Routers can’t fragment packets. They either send or they don’t.
当然,这就是 pMTUd 的全部内容。IPv6 的一个主要区别是:路由器不能分片数据包。它们要么发送,要么不发送。
pantalaimon on Feb 20, 2020
I thought so too, but apparently there is an IPv6 fragmentation extension and it’s implemented by several operating systems.
我也这么认为,但显然有一个 IPv6 分片扩展,它已经被几个操作系统实现了。
jandrese on Feb 20, 2020
Only the endpoints can fragment.
只有终端节点可以分片。
snuxoll on Feb 19, 2020
Sure? At this point 1500 is the standard, we can’t ever hope to increase it without a way to negotiate the acceptable value across the entire transmission path - that’s what IPv6 gives us.
是吗?目前 1500 是标准,我们无法在没有一种方法来协商整个传输路径上可接受的值的情况下增加它——这就是 IPv6 给我们的东西。
inetknght on Feb 19, 2020
I’m not sure that negotiating the acceptable value across the entire transmission path is a reasonable thing to do. I’m not sure that IPv6 should be aware of a minimum/maximum MTU of underlying transmission path particularly since that path can often change transparently and each segment is subject to different requirements.
我不确定在整个传输路径上协商可接受的值是否是一个合理的事情。我不确定 IPv6 是否应该知道底层传输路径的最小 / 最大 MTU,特别是因为该路径通常可以透明地改变,而且每个段都有不同的要求。
btown on Feb 19, 2020
Especially since there are a lot of low latency applications (games, etc.) that take advantage of being able to fit data in a single packet that will not be held up due to other applications sharing the link that might try to stuff larger packets down the link.
特别是因为有很多低延迟应用(如游戏等),它们利用能够将数据放入一个不会因为其他应用共享链路而被延迟的单个数据包中的优势——其他应用可能会试图将更大的数据包塞入链路。
mhandley on Feb 19, 2020
802.11 AMPDUs already tie up the link for ~ 4ms in normal operation. Without this, the medium acquisition overheads kill throughput. But you’re correct that a single 64KB packet sent at MCS - 0 would take a lot longer than that. 802.11 already includes a fragmentation and reassembly mechanism at the 802.11 level, distinct from any end - to - end IP fragmentation. Unlike IP fragmentation, fragments are retransmitted if lost. So you could use 802.11 fragmentation for large packets sent at slow link speeds to avoid tying up the link for a long time.
802.11 AMPDU 在正常运行时已经会占用链路大约 4ms。如果没有这个机制,介质获取开销会杀死吞吐量。但你说得对,以 MCS - 0 发送的一个 64KB 数据包会比这个时间长得多。802.11 已经在 802.11 层面上包含了分片和重组机制,这与任何端到端的 IP 分片是不同的。与 IP 分片不同的是,如果丢失了分片,会重新传输。因此,你可以使用 802.11 分片来处理在低链路速度下发送的大数据包,以避免长时间占用链路。
sjwright on Feb 19, 2020
The M in MTU stands for maximum, not mandatory.
MTU 中的 M 代表最大,而不是强制。
LeifCarrotson on Feb 19, 2020
It ends up being mandatory if you’re sharing a non - MIMO link with other systems that are using large packets.
如果你和其他使用大数据包的系统共享一个非 MIMO 链路,它最终会变成强制性的。
saber6 on Feb 19, 2020
I understand. I have architected networks for over a decade now. The real issue is serialization delay. If I have a tiny voice packet that has to wait to be physically transmitted behind a huge dump truck packet (big), it can still be a problem even with high speed links with regards to microbursts.
我明白。我已经有超过十年的网络架构经验了。真正的问题是序列化延迟。如果我有一个很小的语音数据包,它必须在一辆巨大的大卡车数据包(大数据包)后面等待物理传输,即使在高速链路中,对于微突发来说,这仍然可能是一个问题。
sjwright on Feb 20, 2020
A single gigabit link can sends something in the order of 80,000 packets per second. If packets had a 9000 byte MTU, that would still be 12,000 packets per second. Having your smaller packets wait a at most an extra 0.02 milliseconds to be serialised onto a 1 gigabit physical link seems… rather unlikely to be a problem in the real world?
一个单独的千兆链路每秒可以发送大约 80,000 个数据包。如果数据包有 9000 字节的 MTU,那仍然会是每秒 12,000 个数据包。让你的小数据包在被序列化到 1 千兆物理链路上时最多等待额外的 0.02 毫秒,似乎……在现实世界中不太可能是一个问题?
mertenVan on Feb 19, 2020 [flagged]
gugagore on Feb 19, 2020
It would be nice to corroborate this reason with another source, because my understanding is that clock synchronization was not a factor in determining the MTU, which seems really more like a OSI layer 2 / 3 consideration. I am surprised the PLLs could not maintain the correct clocking signal, since the signal encodings for early ethernet were “self - clocking” [1,2,3] (so even if you transmitted all 0s or all 1s, you’d still see plenty of transitions on the wire).
最好能从另一个来源证实这个原因,因为据我所知,时钟同步并不是决定 MTU 的因素,这更像是 OSI 第二层 / 第三层的问题。我很惊讶 PLL 无法保持正确的时钟信号,因为早期以太网的信号编码是“自时钟”的 [1,2,3](所以即使你传输的全是 0 或全是 1,你仍然会在电线上看到很多信号跳变)。
Note that this is different from, for example, the color burst at the beginning of each line in color analog TV transmission [4]. It is also used to “train” a PLL, which is used to demodulate the color signal transmission. After the color burst is over, the PLL has nothing to synchronize to. But the 10base2 / 5 / etc have a carrier throughout the entire transmission.
请注意,这与例如彩色模拟电视传输中每行开头的颜色突发信号 [4] 是不同的。它也被用来“训练”一个 PLL,这个 PLL 用于解调颜色信号传输。颜色突发信号结束后,PLL 就没有东西可以同步了。但是 10base2/5 等在整个传输过程中都有一个载波。
[1] [https://en.wikipedia.org/wiki/Ethernet_physical_layer#Early_ …]
[1] https://en.wikipedia.org/wiki/Ethernet_physical_layer#Early_implementations
[2] https://en.wikipedia.org/wiki/10BASE2#Signal_encoding
[2] https://en.wikipedia.org/wiki/10BASE2#Signal_encoding
[3] http://www.aholme.co.uk/Ethernet/EthernetRx.htm
[3] http://www.aholme.co.uk/Ethernet/EthernetRx.htm
[4] https://en.wikipedia.org/wiki/Colorburst
[4] https://en.wikipedia.org/wiki/Colorburst
stripline on Feb 19, 2020
I also don’t believe this is the reason. Early Ethernet physical standards used Manchester encoding to recover the data clock.
我也不认为这是原因。早期的以太网物理标准使用曼彻斯特编码来恢复数据时钟。
peteri on Feb 19, 2020
I would agree given I worked on an Ethernet chipset back in 1988 / 9 keeping the PLL synched was not a problem. I can’t remember what the maximum packet size we supported was (my guess is 2048) but that was more of a buffering to SRAM and needing more space for counters. The datasheet for the NS8391 has no such requirement for PLL sync.
鉴于我在 1988/9 年参与过一个以太网芯片的工作,我同意这个观点。保持 PLL 同步并不是问题。我不记得我们支持的最大数据包大小是多少了(我猜是 2048),但那更多是因为需要将数据缓冲到 SRAM 中,并且需要更多的空间来放置计数器。NS8391 的数据手册中没有任何关于 PLL 同步的要求。
https://archive.org/details/bitsavers_nationaldaDataCommunic
jleahy on Feb 19, 2020
As others have said, with Manchester encoding 10BASE2 is self - clocking, you can use the data to keep your PLL locked, just as you would on modern ethernet standards. However I imagine with these standards you may not even have needed an expensive / power - hungry PLL, probably you could just multi - sample at a higher clock rate like a UART did (I don’t actually know how this silicon was designed in practice). Futher PLLs have not got a lot better, but a lot worse. Maybe back when 10BASE2 was introduced you could train a PLL on 16 transitions and then have acquired lock but there’s no way you can do that anymore (at modern data rates). PCI express takes thousands of transitions to exit L0s - > L0, which is all to allow for PLL lock.
正如其他人所说,使用曼彻斯特编码的 10BASE2 是自时钟的,你可以用数据来保持 PLL 锁定,就像在现代以太网标准中一样。然而我猜想在这些标准中,你可能甚至不需要一个昂贵 / 耗电的 PLL,你可能只需要像 UART 那样用更高的时钟频率进行多次采样(我实际上不知道这种硅片在实践中是如何设计的)。PLL 并没有变得更好,而是变得更糟了。也许在 10BASE2 刚推出的时候,你可以用 16 次信号跳变来训练一个 PLL,然后就能锁定,但在现代数据速率下,你再也做不到这一点了。PCI Express 需要数千次信号跳变才能从 L0s 状态退出到 L0 状态,这都是为了实现 PLL 锁定。
My best guess for the 1500 number is that with a 200ppm clock difference between the sender and receiver (the maximum allowed by the spec, which says your clock must be + - 100ppm) then after 1500 bytes you have slipped 0.3 bytes. You don’t want to slip more than half a byte during a packet as it may result in duplicated or skipped byte in your system clock domain. (2001e - 6)1500 = 0.3.
我最好的猜测是,发送端和接收端的时钟差异为 200ppm(这是规范允许的最大值,规范规定你的时钟必须在 ±100ppm 以内),那么在 1500 字节之后,你会滑动 0.3 字节。你不想在一个数据包中滑动超过半个字节,因为这可能会导致在你的系统时钟域中出现重复或跳过的字节。(200 × 1e - 6)× 1500 = 0.3。
Unklejoe on Feb 19, 2020
I thought most Ethernet PHYs don’t lock actually to the clock, but instead use a FIFO that starts draining once it’s half way full. The size of this FIFO is such that it doesn’t under or overflow given the largest frame size and worst case 200 PPM difference. I figured this is what the interframe gap is for - to allow the FIFO to completely drain.
我以为大多数以太网物理层(PHY)并不是真正锁定时钟,而是使用一个 FIFO,当它半满时就开始排空。这个 FIFO 的大小是这样的,即使在最大帧大小和最坏情况下的 200ppm 差异下,它也不会下溢或上溢。我想这就是帧间间隔的作用——让 FIFO 完全排空。
saber6 on Feb 19, 2020
IFP is really more to let the receiver knows where one stream of bits stop and the next stream of bits start. How they handle the incoming spray of data is up to them on a queue / implementation level.
IFP 真正的作用是让接收端知道一个比特流在哪里结束,下一个比特流在哪里开始。他们如何处理传入的数据流取决于他们的队列 / 实现方式。
Animats on Feb 19, 2020
The original MTU was 576 bytes, enough for 512 bytes of payload plus 64 bytes for the IP and TCP header with a few options. 1500 bytes is a Berkeleyism, because their TCP was originally Ethernet - only.
最初的 MTU 是 576 字节,足够容纳 512 字节的有效载荷,以及 64 字节的 IP 和 TCP 头部(带有一些选项)。1500 字节是一个“伯克利化”的东西,因为他们的 TCP 最初只用于以太网。
wmf on Feb 19, 2020
Yeah, didn’t T1 and ISDN use 576 to limit serialization delay and jitter? The backbone probably switched to 1500 when OC - 3 was adopted.
是的,T1 和 ISDN 不是用 576 来限制序列化延迟和抖动吗?当采用 OC - 3 时,主干网可能切换到了 1500。
tssva on Feb 19, 2020
The default MTU for a T1 / E1 was usually 1500. The default for HSSI was 4470 which meant the default for DS3 circuits was 4470. This was also the usual default MTU for IP over ATM which is what most OC - 3 circuits would have been using when they were initially rolled out for backbone use. This remained the usual default MTU all the way through OC - 192 circuits running packet over sonnet. I left the lSP backbone and large enterprise WAN field around that time and can’t speak to more recent technologies.
T1/E1 的默认 MTU 通常是 1500。HSSI 的默认值是 4470,这意味着 DS3 电路的默认值也是 4470。这也是大多数 OC - 3 电路在最初用于主干网时使用的 IP over ATM 的常用默认 MTU。这种情况一直持续到运行在 SONET 上的 OC - 192 电路。我在那个时期离开了 lSP 主干网和大型企业 WAN 领域,因此无法谈论更新的技术。
willis936 on Feb 19, 2020
IEEE 802 history is disappearing without a trace? Afaik it’s pretty well documented, you just need to be a member for some of the stuff. http://www.ieee802.org/I feel like the last piece we’re missing in this story is the performance impact of fragmentation. Like why not just set all new hardware to an MTU of 9000 and wait ten years?
IEEE 802 的历史是不是在无声无息地消失?据我所知,它被记录得相当好,你只需要成为会员才能看到其中一些内容。http://www.ieee802.org/I 我觉得我们在这个故事中缺失的最后一块是分片的性能影响。比如为什么我们不把所有新硬件的 MTU 都设置为 9000,然后等十年呢?
vlan0 on Feb 19, 2020
I feel like the last piece we’re missing in this story is the performance impact of fragmentation. Like why not just set all new hardware to an MTU of 9000 and wait ten years? Because a node with a MTU of 9000 will very likely be unable to determine the MTU of every link in it’s path. At best, you’ll see fragmentation. At worst, the node’s packets will be registered as interface errors when it encounters an interface lower than 9k. Neither of those are desirable.
我觉得我们在这个故事中缺失的最后一块是分片的性能影响。比如为什么我们不把所有新硬件的 MTU 都设置为 9000,然后等十年呢?因为一个 MTU 为 9000 的节点很可能无法确定其路径中每个链路的 MTU。最好的情况是你会看到分片。最坏的情况是,当遇到小于 9k 的接口时,该节点的数据包会被记录为接口错误。这两种情况都不理想。
cesarb on Feb 19, 2020
Like why not just set all new hardware to an MTU of 9000 and wait ten years? The hardware in question is Ethernet NICs. However, for you to set the MTU on an Ethernet NIC to 9000, every device on the same Ethernet network (at least the same Ethernet VLAN), including all other NICs and switches, including ones which aren’t connected yet, must also support and be configured for that MTU. And this also means you cannot use WiFi on that Ethernet network (since, at least last time I looked, WiFi cannot use a MTU that large).
比如为什么我们不把所有新硬件的 MTU 都设置为 9000,然后等十年呢?所涉及的硬件是以太网网卡。然而,要将一个以太网网卡的 MTU 设置为 9000,同一个以太网网络(至少是同一个以太网 VLAN)上的所有设备,包括所有其他网卡和交换机,包括尚未连接的设备,也必须支持并配置该 MTU。这也意味着你不能在那个以太网网络上使用 WiFi(因为至少在我上次查看时,WiFi 无法使用那么大的 MTU)。
willis936 on Feb 19, 2020
Sending a jumbo frame down a line that has hardware that doesn’t support jumbo frames somewhere along the way does not mean the packet gets dropped. The NIC that would send the jumbo frame fragments the packet down to the lower MTU. So what’s the performance impact of that fragmentation? If it isn’t higher than the difference in bandwidth overhead from headers of 9000 MTU traffic vs. 1500 MTU traffic then why not transition to 9000 MTU?
在一个沿途某处的硬件不支持巨型帧的线路上发送一个巨型帧,并不意味着数据包会被丢弃。发送巨型帧的 NIC 会将数据包分片到较低的 MTU。那么这种分片的性能影响是什么呢?如果它并不高于 9000 MTU 流量与 1500 MTU 流量的头部带宽开销差异,那么为什么我们不切换到 9000 MTU 呢?
sathackr on Feb 19, 2020
But how does the NIC know that, 11 hops away, there is a layer 2 device, which cannot communicate with the NIC (switches do not typically have the ability to communicate directly with the devices generating the packets), that only supports a 1500 byte frame? Now you need Path MTU discovery, which as the article indicates, has its own set of issues. (Overhead from trial and error, ICMP being blocked due to security concerns, etc… )
但是 NIC 是如何知道的呢,在 11 跳之外,有一个第二层设备(交换机通常没有能力直接与生成数据包的设备通信),它只支持 1500 字节的数据帧?现在你需要路径 MTU 发现,正如文章所指出的,它有自己的问题。(尝试错误的开销,由于安全问题而阻止 ICMP 等等……)
wbl on Feb 19, 2020
If you block ICMP you deserve what you get. Don’t do this. (Edit: don’t block ICMP)
如果你阻止了 ICMP,那么你就活该得到这样的结果。不要这么做。(编辑:不要阻止 ICMP)
oarsinsync on Feb 19, 2020
So now you’re trying to communicate from your home machine to some random host on the internet (website, VPS, streaming service), and you’re configured for MTU 9000, the remote service is also configured for MTU 9000, but some transit provider in the middle is not, and they’ve disabled ICMP for $reasons. They blocked ICMP, do you deserve what you get?
所以现在你试图从你的家用电脑与互联网上的某个随机主机(网站、虚拟专用服务器、流媒体服务)进行通信,你的配置是 MTU 9000,远程服务也配置为 MTU 9000,但中间的某个传输提供商没有,而且他们出于某种原因禁用了 ICMP。他们阻止了 ICMP,那么你是不是活该得到这样的结果?
wbl on Feb 19, 2020
Transit providers should push packets and generally do. With PMTU failures it’s usually clueless network admins on firewalls nearer endpoints. And no, you don’t and I wish the admin responsible could feel your pain.
传输提供商应该推送数据包,而且通常也会这么做。在 PMTU 失败的情况下,通常是靠近终端的防火墙上的无知网络管理员。不,你没有,我希望负责的管理员能感受到你的痛苦。
oarsinsync on Feb 19, 2020
Transit providers should Agreed > and generally do Agreed. Now if you can make it ‘will always just push packets’, we’ll be golden. Unfortunately, there are enough ATM / MPLS / SONET / etc networks being run by people who no longer understand what they’re doing, that we’re never going to get there. To make matters more entertaining, IPv6 depends on icmp6 even more.
传输提供商应该同意 > 通常也会这么做 同意。现在如果你能让它“总是只推送数据包”,那我们就成功了。不幸的是,有足够多的 ATM/MPLS/SONET 等网络是由那些不再知道自己在做什么的人在运行,我们永远也到不了那里。更有趣的是,IPv6 更加依赖 icmp6。
willis936 on Feb 19, 2020
Why should it need to? Ethernet is designed to have non - deterministic paths (except in cases of automotive, industrial, and time - sensitive networks). If you get to a hop that doesn’t support jumbo frames then break it into smaller frames and send them individually. The higher layers don’t care if the data comes in one frame or ten.
为什么它需要呢?以太网被设计成具有非确定性路径(除了汽车、工业和时间敏感型网络的情况)。如果你到达了一个不支持巨型帧的跳数,那么就把它们分成更小的帧,然后分别发送。更高层并不在乎数据是一个帧还是十个帧到达。
toast0 on Feb 19, 2020
Sending a jumbo frame down a line that has hardware that doesn’t support jumbo frames somewhere along the way does not mean the packet gets dropped Almost all IP packets on the internet at large have the ‘do not fragment’ flag set. IP defragmentation performance ranges from pretty bad to an easy DDoS vector, so a lot of high traffic hosts drop fragments without processing them. If we had truncation (with a flag) instead of fragmentation, that might have been usable, because the endpoints could determine in - band the max size datagram and communicate it and use that; but that’s not what we have.
在一个沿途某处的硬件不支持巨型帧的线路上发送一个巨型帧,并不意味着数据包会被丢弃。几乎所有在互联网上的 IP 数据包都设置了“不分片”标志。IP 分片重组的性能从相当糟糕到容易成为 DDoS 攻击的载体不等,因此许多高流量的主机在不处理的情况下就丢弃了分片。如果我们有截断(带标志)而不是分片,那可能还有用,因为端点可以在带内确定最大尺寸的数据报,并进行通信和使用;但我们并没有这个。
cesarb on Feb 19, 2020
AFAIK, Ethernet has no support for fragmentation; I’ve never seen, in the Ethernet standards I’ve read (though I might have missed it), a field saying “this is a fragment of a larger frame”. There’s fragmentation in the IP layer, but it needs: (a) that the frame contains an IP packet; (b) that the IP packet can be fragmented (no “don’t fragment” on IPv4, or a special header on IPv6); © that the sending host knows the receiving host’s MTU; (d) that it’s not a broadcast or multicast packet (which have no singular “receiving host”). You can have working fragmentation if you have two separate Ethernet segments, one for 1500 and the other for 9000, connected by an IP router; the cost (assuming no broken firewalls blocking the necessary ICMP packets, which sadly is still too common) is that the initial transmission will be resent since most modern IP stacks set the “don’t fragment” bit (or don’t include the extra header for IPv6 fragmentation).
据我所知,以太网不支持分片;在我读过的以太网标准中(尽管我可能遗漏了),我从未见过一个字段写着“这是更大帧的一个分片”。IP 层有分片,但它需要:(a)该帧包含一个 IP 数据包;(b)该 IP 数据包可以被分片(IPv4 上没有“不分片”标志,或者 IPv6 上有一个特殊头部);(c)发送主机知道接收主机的 MTU;(d)它不是一个广播或组播数据包(它们没有单一的“接收主机”)。如果你有两个独立的以太网段,一个用于 1500,另一个用于 9000,通过一个 IP 路由器连接,你可以有有效的分片;代价是(假设没有损坏的防火墙阻止必要的 ICMP 数据包,这很遗憾仍然很常见)初始传输将被重新发送,因为大多数现代 IP 栈都设置了“不分片”标志(或者不包括 IPv6 分片的额外头部)。
tyingq on Feb 19, 2020
It does mean packets sent to another local, non - routed, non - jumbo - frame interface would get lost. So you could, for example, maybe talk to the internet, but you couldn’t print anything to the printer down the hall.
这意味着发送到另一个本地的、非路由的、非巨型帧接口的数据包将会丢失。例如,你可能可以与互联网通信,但你无法将任何东西打印到大厅尽头的打印机上。
zamadatix on Feb 19, 2020
Fragmentation / reassembly is an l3 concept and not guaranteed to large MTUs when it is there.
分片 / 重组是一个第三层的概念,并且当它存在时,并不能保证适用于大 MTU。
vlan0 on Feb 19, 2020
PMTU - D will save their ass in some cases. But it’s not safe to assume all routers in the path will respond to ICMP.
在某些情况下,PMTU - D 会拯救他们的屁股。但不能假设路径中的所有路由器都会对 ICMP 做出响应。
toast0 on Feb 19, 2020
It doesn’t matter that the routers respond to ICMP, it matters that they generate them, and that they’re addressed properly, and that intermediate routers don’t drop them. Some routers will generate the ICMPs, but are rate limited, and the underlying poor configuration means that the rate limits are hit continuously and most connections are effectively in a path mtu blackhole.
路由器是否对 ICMP 做出响应并不重要,重要的是它们是否生成 ICMP,它们是否被正确地寻址,以及中间路由器是否不会丢弃它们。有些路由器会生成 ICMP,但它们受到速率限制,而底层的糟糕配置意味着速率限制被持续触发,大多数连接实际上处于路径 MTU 的黑洞中。
vlan0 on Feb 19, 2020
It doesn’t matter that the routers respond to ICMP, it matters that they generate them, and that they’re addressed properly, and that intermediate routers don’t drop them. > Some routers will generate the ICMPs, but are rate limited, and the underlying poor configuration means that the rate limits are hit continuously and most connections are effectively in a path mtu blackhole. Sure. But I’m not about to sit here and name all the different reasons for folks. And since most here do not have a strong networking background running consumer grade routers at home, it seemed most applicable. I could have used a more encompassing term like PMTU - D blackhole, but I didn’t.
路由器是否对 ICMP 做出响应并不重要,重要的是它们是否生成 ICMP,它们是否被正确地寻址,以及中间路由器是否不会丢弃它们。> 有些路由器会生成 ICMP,但它们受到速率限制,而底层的糟糕配置意味着速率限制被持续触发,大多数连接实际上处于路径 MTU 的黑洞中。当然。但我不会坐在这里一一列举所有不同的原因。而且由于这里大多数人没有很强的网络背景,在家里运行的是消费级路由器,这似乎是最适用的。我本可以使用一个更全面的术语,比如 PMTU - D 黑洞,但我没有。
Avamander on Feb 19, 2020
The worst case I just recently encountered with Jumbo Frames was with NetworkManager trying to follow local DNS server’s advertised MTU but when the local interface doesn’t support Jumbo Frames it just dies and keeps looping. Even if you really want devices to use JF, some fail miserably because it’s just not well thought out.
我最近遇到的巨型帧的最坏情况是,NetworkManager 尝试遵循本地 DNS 服务器发布的 MTU,但当本地接口不支持巨型帧时,它就会崩溃并不断循环。即使你真的希望设备使用 JF,有些设备也会因为没有经过深思熟虑而惨败。
tyingq on Feb 19, 2020
“why not just set all new hardware to an MTU of 9000” Routers can fragment the packets, switches can’t. So that would be pretty chaotic for non - techie installed equipment.
“为什么不把所有新硬件的 MTU 都设置为 9000 呢?”路由器可以分片数据包,但交换机不能。所以这会让非技术人员安装的设备变得相当混乱。
brutt on Feb 19, 2020
Last time I saw hardware Ethernet switch was 20 years ago. 8 - [ ]
我最后一次看到硬件以太网交换机是在 20 年前。8 - [ ]
tyingq on Feb 19, 2020
There’s one in your house probably. It won’t frag packets between your wired PC and your wired printer. There are also certainly a shit load of them in closets and top - of - rack all over where I work.
你家里可能有一个。它不会在你的有线电脑和有线打印机之间分片数据包。在我工作的地方,机架顶部和壁橱里肯定有很多这样的设备。
kitteh on Feb 19, 2020
Plenty of routers today that can’t fragment packets. And they have rate limiters where they can only generate a small amount of ICMP 3 / 4s (maybe 50 a second).
如今有很多路由器无法分片数据包。而且它们有速率限制器,只能生成少量的 ICMP 3 / 4 数据包(可能每秒 50 个)。
teddyh on Feb 19, 2020
My favorite Ethernet resource is Charles Spurgeon’s Ethernet (IEEE 802.3) Web Site: http://www.ethermanage.com/resources/It used to have even more stuff, but I think he removed a lot when he got his book published.
我最喜欢的以太网资源是查尔斯·斯普劳根的以太网(IEEE 802.3)网站:http://www.ethermanage.com/resources/It 它以前有更多的内容,但我想他在出版他的书时删除了很多。
phicoh on Feb 19, 2020
The problem seems to be that both the IEEE and the IETF don’t want to do anything. IEEE could define a way to support larger frames. ‘just wait 10 years’ doesn’t strike me as the best solution, but at least it is a solution. In my opinion a better way be if all devices would report the max frame length they support. Bridges would just report the minimum over all ports on the same vlan. When there are legacy devices that don’t report anything, just stay at 1500. IETF can also do something today by having hosts probe the effective max. frame length. There are drafts but they don’t go anywhere because too few people care.
问题似乎在于 IEEE 和 IETF 都不想采取任何行动。IEEE 可以定义一种支持更大帧的方法。“再等 10 年”在我看来并不是最好的解决方案,但至少它是一个解决方案。在我看来,一个更好的方法是所有设备都能报告它们支持的最大帧长度。网桥只需报告同一 VLAN 上所有端口的最小值。当有不报告任何信息的旧设备时,就保持在 1500。IETF 今天也可以通过让主机探测有效的最大帧长度来采取一些行动。虽然有一些草案,但由于关心的人太少,它们并没有取得任何进展。
smoyer on Feb 19, 2020
The article talks about how the 1500 byte MTU came about but doesn’t mention that the problem of clock recovery was solved by using 4b / 5b or 8b / 10b encoding when sending Ethernet through twisted - pair wiring. This encoding technique also provides a neutral voltage bias. EDIT: As pointed out below, I failed to account for the clock - rate being 25 % faster than the bit - rate in my original assertion that Ethernet over twisted - pair was only 80 % efficient due to the encoding (see below)
这篇文章讲述了 1500 字节 MTU 的由来,但没有提到在通过双绞线发送以太网时,通过使用 4b / 5b 或 8b / 10b 编码解决了时钟恢复的问题。这种编码技术还提供了一个中性的电压偏差。编辑:正如下面指出的,我在最初的断言中没有考虑到时钟速率比比特率快 25%,我原本认为由于编码,通过双绞线的以太网只有 80% 的效率(见下文)
Unklejoe on Feb 19, 2020
Ethernet through twisted - pair wiring only provides 80 % of the listed bit - rate Actually, they already accommodated for this in the advertised speed. In other words, a 1 GbE SerDes runs at 1.250 Gbit / s, so you end up with an actual 1 Gbit / s bandwidth. The reason you don’t actually hit 1 Gbit / s in practice is due to other overheads such as the interframe gaps, preambles, FCS, etc.
通过双绞线的以太网只提供标称比特率的 80%。实际上,他们已经在宣传的速度中考虑了这一点。换句话说,一个 1 千兆以太网 SerDes 的运行速度为 1.250 千兆比特 / 秒,因此你最终得到的实际带宽是 1 千兆比特 / 秒。实际上你无法真正达到 1 千兆比特 / 秒的原因是由于其他开销,如帧间间隔、前导码、FCS 等。
smoyer on Feb 19, 2020
You’re absolutely correct … it’s been a long time since I was designing fiber transceivers but I should have remembered this. Ultimately efficiency is also affected by other layers of the protocol stack too (UDP versus TCP headers) which also explains why larger frames can be more efficient. In the early days of RTP and RTSP, there were many discussions about frame size, how it affected contention and prioritization and whether it actually helped to have super - frames if the intermediate networks were splitting and combining the frames anyway.
你说得完全正确……自从我设计光纤收发器以来已经很久了,但我应该还记得这一点。最终,效率还受到协议栈其他层的影响(UDP 与 TCP 头部),这也解释了为什么更大的帧可以更有效。在 RTP 和 RTSP 的早期,人们就帧大小进行了许多讨论,它如何影响竞争和优先级,以及如果中间网络无论如何都要拆分和组合帧,那么拥有超级帧是否真的有帮助。
blattimwind on Feb 19, 2020
The reason you don’t actually hit 1 Gbit / s in practice is due to other overheads such as the interframe gaps, preambles, FCS, etc. Actually Gigabit Ethernet is highly efficient; it can actually give you 98 - 99 % of line rate as the payload rate.
实际上你无法真正达到 1 千兆比特 / 秒的原因是由于其他开销,如帧间间隔、前导码、FCS 等。实际上千兆以太网是非常高效的;它实际上可以给你 98 - 99% 的线路速率作为有效载荷速率。
mchristen on Feb 19, 2020
There has to be something else going on here because I routinely achieve > 800mbps on my gigabit network over copper.
这里一定还有其他原因,因为我经常在我的铜缆千兆网络上达到 > 800mbps。
adrianmonk on Feb 19, 2020
I’m not a hardware engineer, but from some quick research it appears that 100 megabit ethernet (“fast ethernet”) transmits at effectively 125 MHz. So the 100 megabit number describes the usable bit rate, not the electrical pulses on the wire. Gigabit Ethernet is more complicated, and it uses multiple voltages and all four pairs of wires bidirectionally. So it is not just a single serial stream of on / off.
我不是硬件工程师,但从一些快速研究来看,100 兆以太网(“快速以太网”)的有效传输频率为 125MHz。因此,100 兆这个数字描述的是可用比特率,而不是电线上的电脉冲。千兆以太网更加复杂,它使用多种电压,并且所有四对线都双向使用。因此,它不仅仅是一个简单的开 / 关的串行流。
jws on Feb 19, 2020
Yes, the wire symbol rates are higher. For instance, 100mbit Ethernet has a 125 million symbols per second wire rate.
是的,电线的符号速率更高。例如,100mbit 以太网的电线速率是每秒 1.25 亿个符号。
rcarmo on Feb 19, 2020
I used to glue stuff together to FDDI rings and Token Ring networks back in the day (I used Xylan switches, which had ATM - 25 UTP line cards among other long - forgotten oddities), and MTU sizes always struck me as being particularly arbitrary. But I’m not really sure about the clock sync limitations being a factor here. It was way back in the deepest past. What I do remember vividly is the mess that physical layer networking evolved into over the years thanks to dial - up and DSL (ever had to set your MTU to 1492 to accommodate an extra PPP header?). And something is obviously wrong today, since we’re still using the same baseline value for our gigabit fiber to the home connections, our 3 / 4 / 5G (scratch to taste) mobile phones, etc.
我过去常常把东西粘合到 FDDI 环和令牌环网络上(我用的是 Xylan 交换机,它有 ATM - 25 UTP 线卡,还有其他一些早已被遗忘的奇特东西),MTU 大小总是让我觉得特别武断。但我真的不太确定时钟同步限制是否是这里的因素。那是在很久很久以前。我清楚记得的是,由于拨号和 DSL 的出现,物理层网络经过多年的发展变得一团糟(你有没有试过把 MTU 设置为 1492 来容纳一个额外的 PPP 头部?)。今天显然有些地方出了问题,因为我们仍然在使用相同的基准值来连接我们的千兆光纤到家、3/4/5G(按需选择)手机等。
hylaride on Feb 19, 2020
PPPoE was such an ugly mess. In its early days there were various server - side OSes (IRIX and one other I can’t remember) that had piss - poor TCP/IP MTU implementations. The result was that you ran into random websites that just took forever to load as packets that happened to not fill the full 1492 limits eventually got the data through. By around 2003 i rarely encountered it anymore, but then I moved to a place with cable and never had to deal with it again.
PPPoE 是如此丑陋的混乱。在其早期,各种服务器端操作系统(IRIX 和另一个我记不起来的)都有糟糕的 TCP/IP MTU 实现。结果就是,你会遇到一些随机的网站,它们加载起来需要很长时间,因为那些碰巧没有填满 1492 限制的数据包最终还是把数据传过来了。到了大约 2003 年,我很少再遇到这种情况了,但后来我搬到了一个有线电视的地方,再也不用处理这个问题了。
mrkstu on Feb 19, 2020
Oh, and throw IPsec and a bunch of other protocols into the mix - networking is often a fragile beast:https://www.networkworld.com/article/2224654/mtu-size-issues.html
哦,再加上 IPsec 和一大堆其他协议——网络往往是一个脆弱的野兽:https://www.networkworld.com/article/2224654/mtu-size-issues.html
kalleboo on Feb 19, 2020
ever had to set your MTU to 1492 to accommodate an extra PPP header? I had to replace my Apple AirPort Extreme when I got gigabit fiber since it didn’t have a manual MTU setting and it didn’t autodetect the MTU properly over PPPoE… In 2020 I still need to manually set the MTU on my Ubiquiti USG…
有没有试过把 MTU 设置为 1492 来容纳一个额外的 PPP 头部?当我接入千兆光纤时,我不得不更换我的苹果 AirPort Extreme,因为它没有手动 MTU 设置,而且它不能正确地通过 PPPoE 自动检测 MTU……2020 年,我仍然需要手动设置我的 Ubiquiti USG 的 MTU……
neurostimulant on Feb 19, 2020
ever had to set your MTU to 1492 to accommodate an extra PPP header? Ah, I was always wondering why my ISP configured my fiber modem’s mtu to 1492. So it’s due to using PPPoE? Is there no way to use bigger mtu when using PPPoE?
有没有试过把 MTU 设置为 1492 来容纳一个额外的 PPP 头部?啊,我一直想知道为什么我的 ISP 把我的光纤调制解调器的 mtu 设置为 1492。所以是因为使用了 PPPoE 吗?使用 PPPoE 时有没有办法使用更大的 mtu 呢?
toast0 on Feb 19, 2020
Nowadays, there’s PPPoA (over ATM) which wraps at a lower level, and allows 1500 byte ethernet payloads through. But running the ethernet over ATM at 1508 MTU so that PPPoE would be 1500 was probably out of reach — when PPPoE was introduced, the customer endpoint was often the customer PC, and some of those were using fairly old nics that might not have supported larger packets. Sadly, smaller than 1500 byte MTUs still cause issues for some people to this day. It’s all fine if everything is properly configured, or if at least everything sends and receives ICMP, but if something is silently dropping packets, you’re in for a bad day. These days, I think it’s usually problems with customers sending large packets, as opposed to early days where receiving large packets would routinely fail, but a lot of that is because large sites gave up on sending large packets.
如今,有了 PPPoA(通过 ATM),它在较低的层次上封装,并允许 1500 字节的以太网有效载荷通过。但是,将以太网通过 ATM 以 1508 MTU 运行,以便 PPPoE 可以达到 1500,可能当时是难以实现的——当 PPPoE 被引入时,客户端往往是客户的个人电脑,而其中一些使用的是相当旧的网卡,可能不支持更大的数据包。遗憾的是,小于 1500 字节的 MTU 至今仍然给一些人带来问题。如果一切都正确配置了,或者至少一切都发送和接收 ICMP,那就没问题,但如果有些东西在默默地丢弃数据包,那你就会遇到糟糕的一天。如今,我认为通常是客户发送大包的问题,而在早期,接收大包通常会失败,但很多原因是因为大站点放弃了发送大包。
rcarmo on Feb 19, 2020
Yes, PPPoA was also a thing I dealt with, and another source of irritating MTU issues.
是的,我也处理过 PPPoA,它也是令人烦恼的 MTU 问题的另一个来源。
jburgess777 on Feb 19, 2020
RFC 4638 provides a mechanism for this. It relies on the Ethernet devices supporting a ‘baby jumbo’ MTU of 1508 bytes and support for it is still a bit scarce. https://tools.ietf.org/html/rfc4638
RFC 4638 为这种情况提供了一个机制。它依赖于以太网设备支持 1508 字节的“小巨型”MTU,而目前对它的支持还比较少。https://tools.ietf.org/html/rfc4638
thehappypm on Feb 19, 2020
When networks were new, computers connected to each other using a shared trunk that you physically drilled into. It’s a non - trivial problem to send data over a shared channel; it’s very easy for two systems to clobber each other. A primitive, but somewhat effective mechanism is ALOHA (https://en.wikipedia.org/wiki/ALOHAnet ), where multiple senders randomly try to send their message to a single receiver. The single receiver then repeats back any messages it successfully receives. In that way the sender is able to confirm its message got through – an ack. After a certain amount of time with no ack, senders repeat their messages. As you can imagine, shorter packets are less likely to cause collisions. Ethernet uses something similar, but is able to detect if someone else is using the wire, called carrier sense. A short packet of 1500 bytes reduced the likelihood of collisions.
当网络还是新生事物时,计算机通过物理钻孔连接到一个共享主干上。在共享信道上发送数据是一个非平凡的问题;两个系统很容易互相干扰。一种原始但还算有效的机制是 ALOHA(https://en.wikipedia.org/wiki/ALOHAnet ),多个发送者随机地尝试向一个接收者发送他们的消息。该单一接收者随后会重复发送它成功接收到的任何消息。通过这种方式,发送者能够确认其消息已经通过——一个确认应答。在没有收到确认应答的一定时间后,发送者会重复发送他们的消息。正如你所能想象的,较短的数据包不太可能引起冲突。以太网使用了类似的机制,但能够检测到是否有人在使用这条线路,这被称为载波检测。一个 1500 字节的短数据包降低了冲突的可能性。
_8huj on Feb 19, 2020
Does multiplexing over Ethernet exist?
以太网上是否存在多路复用?
5436436347 on Feb 19, 2020
Not anymore for all practical purposes, but it once did for the very old 10Base - 2 standard for Ethernet over coaxial cable. This is practically why the old MII Ethernet PHY interface protocol had the collision - sense lines to indicate to the MAC to stop sending data if it detects incoming data, in attempts to minimize collisions. https://en.wikipedia.org/wiki/10BASE2
实际上已经不存在了,但在非常古老的 10Base - 2 标准中,曾经有过以太网通过同轴电缆的多路复用。这实际上也是为什么旧的 MII 以太网 PHY 接口协议有碰撞检测线,以指示 MAC 如果检测到传入数据就停止发送数据,试图尽量减少碰撞。https://en.wikipedia.org/wiki/10BASE2
_8huj on Feb 19, 2020
This is very cool history, and something I never would have stumbled upon myself. Thank you for sharing !
这是很酷的历史,是我自己绝对发现不了的。谢谢你的分享!
throw0101a on Feb 19, 2020
Unreliable IP fragmentation, and the brokenness of Path MTU Discovery (PMTUD), is causing the DNS folks to put a clamp on the size of (E)DNS message size: * https://dnsflagday.net/2020/
不可靠的 IP 分片,以及路径 MTU 发现(PMTUD)的缺陷,导致 DNS 专家对(E)DNS 消息大小进行了限制:* https://dnsflagday.net/2020/
2rsf on Feb 19, 2020
I remembered something different related to shared medium and CMSA / CD where 1500 ensured fairness, and the minimum of 46 related to propagation time in the longest allowable cable More at: https://networkengineering.stackexchange.com/questions/2962/ …
我记起了一件与共享介质和 CMSA / CD 相关的不同事情,其中 1500 确保了公平性,而最小值 46 与最长允许电缆中的传播时间有关。详情见:https://networkengineering.stackexchange.com/questions/2962/ ……
anonymousiam on Feb 19, 2020
Minor factoid the article does not mention. ATM is an alternative to Ethernet that’s used in many optical fiber environments. The “transfer unit” size of the ATM “cell” is 53 bytes (5 for the header and 48 for the payload). This is much smaller than 1500. Another quirky story from the past: Sometime around 20 years ago I was having a bizarre networking problem. I could telnet into a host with no trouble, and the interactive session would be going just fine until I did something that produced a large volume of output (such as ‘cat’ on a large file). At that point the session would freeze and I would eventually get disconnected. After troubleshooting for a while I identified the problem as one of the Ethernet NICs on the client host. It was a premium NIC (3Com 3C509). Nonetheless, the NIC crystal oscillator frequency had drifted sufficiently that it would lose clock synchronization to the incoming frame if the MTU was larger than about 1000.
文章中没有提到的一个小事实。ATM 是以太网的一种替代品,它被用于许多光纤环境中。ATM“信元”的“传输单元”大小为 53 字节(其中 5 字节为头部,48 字节为有效载荷)。这比 1500 小得多。另一个来自过去的小趣事:大约 20 年前,我遇到了一个奇怪的网络问题。我能够毫无困难地通过 telnet 登录到一台主机,交互式会话也会正常进行,直到我做了某件产生大量输出的事情(比如对一个大文件使用“cat”命令)。在那一刻,会话会冻结,我最终会被断开连接。经过一段时间的故障排除,我确定问题是客户主机上的一个以太网网卡。这是一个高档网卡(3Com 3C509)。尽管如此,网卡的晶体振荡器频率漂移得足够多,如果 MTU 大于大约 1000,它就会失去与传入帧的时钟同步。
TomVDB on Feb 19, 2020
Speaking about ATM: the 48 byte payload was a standardization compromise between Europe and the US. US companies had prototypes using 64 bytes, while European companies used 32 bytes. To avoid anyone giving a competitive advantage, they decided on a middle ground of 48. There were trade - offs between 32 and 64 bytes as well: a 32 byte payload had a higher overhead than a 64 byte payload, but it had a shorter transmission time which made it easier to do voice echo cancellation. Or so I was told many decades ago when I got introduced to ATM systems…
说到 ATM:48 字节的有效载荷是欧洲和美国之间的一个标准化折衷方案。美国公司的原型使用 64 字节,而欧洲公司使用 32 字节。为了避免任何一方获得竞争优势,他们决定采用中间值 48。在 32 字节和 64 字节之间也有权衡:32 字节的有效载荷比 64 字节的有效载荷有更高的开销,但它有更短的传输时间,这使得语音回声抵消更容易实现。或者至少几十年前我刚接触 ATM 系统时有人这样告诉我……
saber6 on Feb 19, 2020
ATM is mostly dead. The only places it exists now is legacy deployments. Everyone has been deploying MPLS/IP instead of ATM for the past 15 - 20 years.
ATM 基本上已经死了。现在它只存在于一些遗留部署中。过去 15 - 20 年,大家都在部署 MPLS/IP 而不是 ATM。
alexforencich on Feb 19, 2020
I think the author may have made a mistake in some of the math. The frame size distribution plots are likely based on the number of frames, not the amount of data contained in said frames. The 1500 byte and other large frames should therefore account for the lion’s share of the actual data transferred. Correcting this error will totally change the final two graphs.
我觉得作者在某些计算中可能犯了错误。帧大小分布图很可能是基于帧的数量,而不是这些帧中包含的数据量。因此,1500 字节和其他大帧应该占实际传输数据的大部分。修正这个错误将完全改变最后两张图。
labawi on Feb 19, 2020
Yes. But only the “AMS - IX traffic by packet size range” graph is wildly inaccurate. Ethernet frame overhead is per - packet and presumably right.
是的。但只有“按数据包大小范围划分的 AMS - IX 流量”这张图严重不准确。以太网帧开销是按数据包计算的,应该没错。
alexforencich on Feb 19, 2020
Ah yeah, that’s probably true. According to some back of the envelope math, it seems like the distribution should be more like 5 %, 1 %, 1 %, 3 %, 50 %, 39 %, ignoring the first and last size bins.
哦,这可能是真的。根据一些简单的估算,分布应该更像是 5 %、1 %、1 %、3 %、50 %、39 %,忽略第一个和最后一个大小区间。
tartoran on Feb 19, 2020
I find that technology cements in strata (the archaeology term) just as the layers that accumulate as the result of natural processes and human activity. The dynamics are not exactly the same but the tendency is similar. I wonder whether we’ll always be capable of digging down deeper to the beginnings as things get more and more complicated.
我觉得技术就像自然过程和人类活动产生的地层(考古学用语)一样逐渐固化。动力学原理并不完全相同,但趋势类似。我想知道,随着事物变得越来越复杂,我们是否还能一直深入挖掘到最初的起点。
IshKebab on Feb 19, 2020
I don’t think the Ethernet Frame Overhead graph is correct. Surely the overhead is proportionally higher, per amount of data, for smaller packets. That graph shows that the overhead is just proportional to the amount of data sent, irrespective of the packet size, which can’t be right.
我不认为以太网帧开销图是正确的。对于小数据包来说,开销肯定与数据量成正比更高。那张图显示开销仅与发送的数据量成正比,而与数据包大小无关,这肯定不对。
alexforencich on Feb 19, 2020
The graph above that one is totally wrong. The frame overhead graph may be correct, though.
上面那张图完全错了。帧开销图可能是正确的。
trixie_ on Feb 19, 2020
Kind of expected an article titled ‘How 1500 bytes became the MTU of the internet’ to tell us how 1500 bytes became the MTU of the internet. Even I could of told you, ‘the engineers at the time picked 1500 bytes’.
我本以为一篇名为“1500 字节如何成为互联网的 MTU”的文章会告诉我们 1500 字节是如何成为互联网的 MTU 的。即使是我也能告诉你,“当时的工程师们选择了 1500 字节”。
russfink on Feb 19, 2020
IIRC it was called “thinnet” (10B2). I loved the vampire taps on thick net.
如果我没记错的话,它被称为“细网”(10B2)。我喜欢厚网上的吸血鬼接口。
注:此处
10B2应为10BASE2笔误。
- 10BASE2(Thin Ethernet,细网):一种早期以太网标准 。它使用细同轴电缆作为传输介质,传输速率固定为 10 Mbps 。在实际应用中,每个网段的最大传输距离严格限制为 185 米,单个网段上最多能够支持 30 个工作站。。
- 10BASE5(Thick Ethernet,厚网):同样是早期以太网标准之一。采用粗同轴电缆作为传输线缆,传输速率同样为 10 Mbps 。每个网段的最大距离限制为 500 米,每个网段允许接入的最多终端数量为 100 台。
- Vampire Taps(吸血鬼接口):10BASE5 网络中特有的一种连接设备 。它通过特殊的物理方式连接到粗同轴电缆上,用于将网络设备接入网络。因其独特的连接方式类似于“吸血鬼”咬住电缆,故而得名 。
franga2000 on Feb 19, 2020
Not my field, so I might be making an obvious error here, but: If there are efficiency gains to be had from using jumbo frames, wouldn’t setting my MTU to a multiple of 1500 still be of some benefit? If my PC, my switch and my router all support it, that would still be a tiiiny improvement. If the server’s network does as well and let’s say both of our direct providers, even if none of the exchanges or backbones in between do, that would still be an efficiency gain for ~ 10 % of the link, right?
这并非我的专业领域,所以我可能在这里犯了一个明显的错误,但:如果使用巨型帧可以提高效率,那么把我的 MTU 设置为 1500 的倍数是否仍有一些好处呢?如果我的电脑、我的交换机和我的路由器都支持,那仍然会有一点点改进。如果服务器的网络也支持,假设我们双方的直接提供商也支持,即使中间的交换节点或骨干网都不支持,那仍然会在大约 10 % 的链路上提高效率,对吧?
benjojo12 on Feb 19, 2020
Locally you can set your MTU to larger than 1500, but if you (generally) try and send a packet towards the internet larger than 1500 it will be dropped without a trace, or it will be dropped and an ICMP message will be generated to tell your system to lower the MTU. Assuming you have not firewalled off ICMP ; As a handy feature on Linux at least, you can set your MTU to 9000 locally, and then set the default (internet generally) route to have a MTU of 1500 to prevent issues: ip route add 0.0.0.0 / 0 via 10.11.11.1 mtu 1500
在本地,你可以把 MTU 设置为大于 1500,但如果你(通常)试图向互联网发送一个大于 1500 的数据包,它将无声无息地被丢弃,或者它将被丢弃,并且会生成一个 ICMP 消息来告诉你的系统降低 MTU。前提是你没有屏蔽 ICMP;至少在 Linux 上有一个很方便的功能,你可以将本地 MTU 设置为 9000,然后将默认(通常是互联网)路由的 MTU 设置为 1500,以避免出现问题:
\# ip route add 0.0.0.0/0 via 10.11.11.1 mtu 1500
franga2000 on Feb 20, 2020
Huh, I wasn’t aware that dropping large frames was so commonplace. I guess they don’t want to use the CPU cycles to fragment them?
哇,我不知道丢弃大数据帧是如此常见的事情。我想他们大概是不想用 CPU 周期来分片这些帧吧?
luma on Feb 19, 2020
Over - sized packets can (and generally will) be fragmented by your router. It shouldn’t be dropped unless you’ve intentionally set DNF.
超大尺寸的数据包可以(而且通常会)被你的路由器分片。除非你故意设置了不分片(DNF),否则不应该丢弃它们。
benjojo12 on Feb 19, 2020
Fragments are very hit or miss on the internet, https://blog.cloudflare.com/ip - fragmentation - is - broken/
在互联网上,分片的效果非常不稳定,https://blog.cloudflare.com/ip - fragmentation - is - broken/
zajio1am on Feb 19, 2020
AFAIK, most OSes today set DNF by default.
据我所知,如今大多数操作系统默认设置为不分片(DNF)。
duxup on Feb 19, 2020
They will fragment them but many times you will see performance or other misc issues … eventually.
它们会分片,但很多时候你会看到性能或其他各种问题……最终。
apexalpha on Feb 19, 2020
Oh I never knew this. I wonder if I could enable Jumbo Frames to stream 4k content more efficiently on my local LAN.
哦,我以前不知道这个。我想知道我是否可以在我的局域网中启用巨型帧,以更高效地传输 4k 内容。
a_t48 on Feb 19, 2020
You could… if the software on both your server and your media pc support large frames. And you’re willing to deal with every once in a while some piece of software doing the wrong thing and sending out every packet with large MTU without doing detection on max packet size.
你可以……如果你的服务器和媒体电脑上的软件都支持大数据帧,并且你愿意偶尔处理一些软件做错事情,发送出每个数据包都使用大数据 MTU 而没有进行最大数据包大小检测的情况。
duxup on Feb 19, 2020
Potentially but troubleshooting performance issues from mismatched MTU can be brutal so most providers drop anything over 1500. Many devices can do over 1500 but anyone who has done so without careful consideration knows the outcome isn’t predictable unless everyone on the network is prepared to do so. A dedicated / controlled SAN type environment can do it just fine, beyond that it can be difficult.
理论上可以,但从不匹配的 MTU 中排查性能问题可能会很痛苦,因此大多数供应商会丢弃任何超过 1500 的数据包。许多设备可以处理超过 1500 的数据,但任何在没有仔细考虑的情况下这样做过的人都知道,除非网络中的每个人都准备好这样做,否则结果是不可预测的。一个专用的 / 受控的 SAN 类型环境可以很好地处理这种情况,除此之外可能会很困难。
afandian on Feb 19, 2020
Off - topic but looking at that old network card picture reminded me of a very vague memory of more than one card with a component that looked like a capacitor, except it looked cracked. Is my mind playing tricks? Were they faulty units or was there meant to be a crack? This picture could be the same thing:https://www.vogonswiki.com/images/3/37/Viglen_Ethergen_PnP_2000A.jpg
离题了,但看到那张旧网卡的照片让我想起了一段非常模糊的记忆,有一张以上的网卡上有一个看起来像电容器的元件,但它看起来像是裂开的。是我的脑子在作怪吗?它们是故障单元,还是本该有裂痕的?这张照片可能也是同样的东西:https://www.vogonswiki.com/images/3/37/Viglen_Ethergen_PnP_2000A.jpg
kens on Feb 20, 2020
That looks like a capacitor with a built - in spark gap. I’ve seen them in CRT circuitry. They’re probably using it in the network card so if there’s a huge over - voltage (e.g. lightning somewhere), it will jump across the spark gap, limiting damage.
那看起来像是一个带有内置火花间隙的电容器。我在 CRT 电路中见过它们。他们可能在网卡中使用它,以便在出现巨大的过电压(例如某处的闪电)时,它会跳过火花间隙,从而限制损坏。
afandian on Feb 20, 2020
Perfect! Thank you for solving something that has been lurking unresolved at the back of my mind for 20 years! More info: https://electronics.stackexchange.com/questions/381682/what-kind-component-is-this
太棒了!感谢你解决了困扰我 20 年的一个未解之谜!更多信息:https://electronics.stackexchange.com/questions/381682/what-kind-component-is-this
_bxg1 on Feb 20, 2020
So they just picked an arbitrary number that felt right? I expected the story to be more interesting than that, given the title. Still, there was some interesting trivia surrounding the core question. Reminds me of the IPv6 adoption problem: https://news.ycombinator.com/item?id=14986324
他们只是随便挑了一个感觉合适的数字?鉴于标题,我本以为这个故事会更有趣。不过,围绕核心问题还是有一些有趣的细节。这让我想起了 IPv6 的采用问题:https://news.ycombinator.com/item?id=14986324
hinkley on Feb 19, 2020
If we look at data from a major internet traffic exchange point (AMS - IX), we see that at least 20 % of packets transiting the exchange are the maximum size. He’s so optimistic. My brain heard this as “only 20 % of packets [ … ] are the maximum size” What are all of those 64 byte packets? Interactive shells, or some other low bitrate protocol?
如果我们查看一个主要的互联网流量交换点(AMS - IX)的数据,我们会发现至少有 20 % 的经过该交换点的数据包是最大尺寸的。他太乐观了。我的大脑理解成“只有 20 % 的数据包 [ … ] 是最大尺寸的”。那些 64 字节的数据包都是什么?是交互式终端,还是其他某种低比特率协议?
labawi on Feb 19, 2020
Note that maximum size is defined as >= 1514, with 50 % of packets being >= 1024. It very well may be that ~ 45 % of packets are >= 1400 bytes. The transfer graph is wrong - it shows packet count distribution, not size. Quick math says roughly 90 % of transfer size are >= 1024 byte packets.
请注意,最大尺寸被定义为 >= 1514,其中 50 % 的数据包 >= 1024。很可能约 45 % 的数据包 >= 1400 字节。传输图是错误的——它显示的是数据包数量分布,而不是大小。快速计算表明,大约 90 % 的传输大小是 >= 1024 字节的数据包。
wmf on Feb 19, 2020
Probably mostly ACKs.
很可能大多是确认应答(ACK)。
hinkley on Feb 19, 2020
Well now I feel dumb.
现在我觉得自己很傻。
zamadatix on Feb 19, 2020
I’ve always wondered how 9000 became “jumbo”. Technically anything over 1500 is consider jumbo and there is no standard. The largest I’ve seen is 16k. I think there are some crc accuracy concerns at larger sizes but 9k still seems quite arbitrary for computer land.
我一直想知道 9000 是如何成为“巨型”的。从技术上讲,任何超过 1500 的都被视为巨型,而且没有标准。我见过的最大值是 16k。我认为在更大的尺寸下有一些循环冗余校验(CRC)精度问题,但 9k 对于计算机领域来说仍然显得相当随意。
cesarb on Feb 19, 2020
The explanation according to http://sd.wareonearth.com/~phil/jumbo.html is: “First because ethernet uses a 32 bit CRC that loses its effectiveness above about 12000 bytes. And secondly, 9000 was large enough to carry an 8 KB application datagram (e.g. NFS) plus packet header overhead.” That is, 9000 is the first multiple of 1500 which can carry an 8192 - byte NFS packet (plus headers), while still being small enough that the Ethernet CRC has a good probability to detect errors.
根据 http://sd.wareonearth.com/~phil/jumbo.html 的解释是:“首先,因为以太网使用了一个 32 位的循环冗余校验(CRC),在大约 12000 字节以上时会失去其有效性。其次,9000 足够大,可以携带一个 8KB 的应用数据报(例如 NFS)加上数据包头部开销。”也就是说,9000 是 1500 的倍数中,第一个既能容纳一个 8192 字节的 NFS 数据包(加上头部),又足够小以使以太网 CRC 能够高效检测错误的值。
ajross on Feb 19, 2020
Ethernet frame size was never strictly limited. The way the packet length works with Ethernet II frames (802.3 is more explicit, but never really caught on) is that the hardware needs to read all the way to the end of the packet and detect a valid CRC and a gap at the end before it knows the thing is done. So there’s no reason beyond buffer size to put a fixed limit on it, and different hardware had different SRAM configurations. Wikipedia has this link showing that 9000 bytes was picked by one site c. 2003 simply because it was generally well - supported by their existing hardware:https://noc.net.internet2.edu/i2network/jumbo-frames/rrsum-almes-mtu.html
以太网帧大小从未被严格限制。在以太网 II 帧(802.3 更明确,但从未真正流行起来)中,数据包长度的工作方式是,硬件需要一直读取到数据包的末尾,并检测到有效的 CRC 和末尾的间隔,才能知道数据包已经结束。因此,除了缓冲区大小之外,没有理由对它设置固定限制,而不同的硬件有不同的 SRAM 配置。维基百科有这样一个链接,显示 9000 字节是在 2003 年左右被一个网站选中的,仅仅是因为它通常得到了他们现有硬件的良好支持:https://noc.net.internet2.edu/i2network/jumbo-frames/rrsum-almes-mtu.html
gargs on Feb 19, 2020
This reminds me of various Windows applications back in the day (Windows 3.1 and 95) that claimed to fine - tune your connection and one of the tricks they used was changing the MTU setting, as far as I can recall. Could anyone share how that worked?
这让我想起了当年(Windows 3.1 和 95 时代)的各种 Windows 应用程序,它们声称可以微调你的连接,其中一个技巧就是更改 MTU 设置,至少据我回忆是这样。有人能分享一下那到底是怎么工作的吗?
ndespres on Feb 19, 2020
If your computer sends a larger MTU than the next device upstream can handle, the packets will be fragmented leading to increased CPU usage, increased work by the driver, higher I/O on the network interface, higher CPU load on your router or modem, etc depending on where the bottleneck is. For example if you connect over Ethernet to a DSL modem, or to a router that has a DSL uplink, all your packets will be fragmented. This is because DSL uses 8 bytes per packet for PPPoE authentication. So if you send a 1500 byte packet to the modem, it will get broken up by the modem into 2 packets: one is 1492 + 8 bytes, and the other is 8 + 8 bytes. But your PC is still sending more packets… the modem is struggling to fragment them all and send them upstream… its memory buffer is filling up… your computer is retrying packets that it never got a response on… By lowering your computer MTU to 1492 to start with, you avoid the extra work by the modem, which can have considerable speed increase.
如果你的电脑发送的 MTU 大于上游下一个设备能够处理的大小,数据包将会被分片,从而导致 CPU 使用率增加、驱动程序工作量增加、网络接口的 I/O 增加、路由器或调制解调器的 CPU 负载增加等,具体取决于瓶颈在哪里。例如,如果你通过以太网连接到一个 DSL 调制解调器,或者连接到一个有 DSL 上行链路的路由器,你所有的数据包都会被分片。这是因为 DSL 使用每个数据包 8 字节用于 PPPoE 认证。所以如果你向调制解调器发送一个 1500 字节的数据包,它会被调制解调器分解成两个数据包:一个是 1492 + 8 字节,另一个是 8 + 8 字节。但你的电脑仍在发送更多的数据包……调制解调器正在努力分片并将它们发送到上游……它的内存缓冲区正在被填满……你的电脑正在重试那些从未收到响应的数据包……通过将你的电脑 MTU 降低到 1492,你可以避免调制解调器的额外工作,这可能会显著提高速度。
fireattack on Feb 19, 2020
Probably a dumb question, why the maximum size (and the one has most of packages) in the AMS - IX graph 1514 bytes instead of 1500 bytes that got discussed in the article?
可能是个很傻的问题,为什么在 AMS - IX 图表中,最大尺寸(以及拥有最多数据包的尺寸)是 1514 字节,而不是文章中讨论的 1500 字节?
ra1n85 on Feb 19, 2020
1500 bytes is the MTU of IP, in most cases. It often excludes the Ethernet header, which is 14 bytes excluding the FCS, preamble, IFG, and any VLANs. If have a 1500 byte MTU for IP, then we need at least a 1514 byte MTU for IP + Ethernet. We often call the > 1514B MTU the “interface MTU”. It’s unnecessarily confusing.
在大多数情况下,1500 字节是 IP 的 MTU。它通常不包括以太网头部,以太网头部为 14 字节,不包括 FCS、前导码、IFG 和任何 VLAN。如果我们有一个 1500 字节的 IP MTU,那么我们需要至少一个 1514 字节的 MTU 来容纳 IP + 以太网。我们通常把 > 1514B 的 MTU 称为“接口 MTU”。这确实令人困惑。
bjornsing on Feb 19, 2020
Actually, MTUs below 1500 bytes are pretty common, e.g. with PPP over Ethernet or other forms of encapsulation / tunneling.
实际上,低于 1500 字节的 MTU 并不少见,例如在以太网上的 PPP 或其他形式的封装 / 隧道中。
CGamesPlay on Feb 19, 2020
I think you’re saying that the smallest bucket of packets are all packets that would have been combined with a larger packet of that had been an option… but that doesn’t make sense. That class of packets includes TCP SYN, ACK, RST, and 128 bytes could fit an entire instant message on many protocols.
我想你说的是,最小的那一类数据包都是那些如果有可能的话会被合并到一个更大的数据包中的数据包……但这没有道理。这一类数据包包括 TCP SYN、ACK、RST,而且 128 字节可以在许多协议中容纳一个完整的即时消息。
leroman on Feb 19, 2020
Looks like a ripe low - hanging fruit for SpaceX Starlink to pick…
看起来像是 SpaceX Starlink 可以轻松摘取的低垂果实……
leroman on Feb 19, 2020
Why the downvote? possibly facilitating the end - to - end transport will allow them to offer jumbo packets
为什么被踩?可能是因为促进端到端传输会让他们能够提供巨型数据包
ekimekim on Feb 19, 2020
This would only be possible if you were talking from a jumbo - configured client (let’s say you’ve set up your laptop correctly), across a jumbo - configured network (Starlink, in your scenario), to a jumbo - configured server (here’s the problem). The problem is that Starlink only controls the steps from your router to “the internet”. If you’re trying to talk to spacex.com it’d be possible, but if you’re trying to talk to google.com then now you need Starlink to be peering with ISPs that have jumbo frames, and they need to peer with ISPs with jumbo frames, etc etc and then also google’s servers need to support jumbo frames. Basically, the problem is that Starlink is not actually end to end, if you’re trying to reach arbitrary servers on the internet. It just connects you to the rest of the internet, and you’re back to where you started. This is also true for any other ISP, Starlink is not special in this regard.
只有在你的客户端配置了巨型帧(假设你正确设置了你的笔记本电脑),并且通过一个配置了巨型帧的网络(在你的场景中是 Starlink),向一个配置了巨型帧的服务器(这就是问题所在)通信时,这才有可能。问题是 Starlink 只控制从你的路由器到“互联网”的部分。如果你试图与 spacex.com 通信,这是有可能的,但如果你试图与 google.com 通信,那么现在你需要 Starlink 与支持巨型帧的 ISP 互连,而这些 ISP 又需要与其他支持巨型帧的 ISP 互连,等等,而且谷歌的服务器也需要支持巨型帧。基本上,问题是 Starlink 并没有真正实现端到端的连接,如果你试图连接互联网上的任意服务器,你又回到了起点。其他任何 ISP 也是如此,Starlink 在这方面并没有什么特别之处。
Avamander on Feb 19, 2020
True, you’d expect endpoints to support Jumbo Frames as well, but why not start at least making it possible. It’s a dead loop otherwise. IPv6 was the same at start.
确实,你希望终端节点也支持巨型帧,但为什么至少不先让它成为可能呢?否则就会陷入死循环。IPv6 最初也是如此。
hylaride on Feb 19, 2020
Well, depending on the quality of the connections, a re - transmit of a jumbo frame could mean having to re - transmit a lot more data. But since the local network and the end network where the servers are located will almost certainly be 1500, the point is almost all but moot.
好吧,根据连接的质量,重新传输一个巨型帧可能意味着需要重新传输更多的数据。但由于本地网络和服务器所在的终端网络几乎肯定会是 1500,所以这一点几乎毫无意义。
dooglius on Feb 19, 2020
Most connections will not be peer - to - peer over Starlink, so you need to deal with the least common denominator.
大多数连接不会通过 Starlink 实现点对点通信,因此你需要考虑最小公倍数。
saber6 on Feb 19, 2020
Because you don’t know what you’re talking about and are engaging in “what if” - isms? There is no business case to solve with jumbo frames over the internet. I’ve been in this business for 20 years. Seen this argument a dozen times. It never changes.
因为你根本不知道你在说什么,只是在进行“如果……会怎样”的猜测?在互联网上使用巨型帧没有任何商业案例需要解决。我在这一行已经干了 20 年。我见过无数次这种争论。它从未改变。
tambourine_man on Feb 19, 2020
Nah, it’s 1492 forever!
不,1492 将永远存在!
dredmorbius on Feb 19, 2020
Found the ADSL user.
找到了一个 ADSL 用户。
尽管现代网络技术已经取得了很大的进步,但仍有一些用户可能还在使用较旧的技术,这在网络环境中是常见的现象。
Just How Did 1500 Bytes Become The MTU Of The Internet?
1500 字节是如何成为互联网的 MTU 的?
by: Donald Papp
June 29, 2021

[Benjojo] got interested in where the magic number of 1,500 bytes came from, and shared some background on just how and why it seems to have come to be. In a nutshell, the maximum transmission unit (MTU) limits the maximum amount of data that can be transmitted in a single network-layer transaction, but 1,500 is kind of a strange number in binary. For the average Internet user, this under the hood stuff doesn’t really affect one’s ability to send data, but it has an impact from a network management point of view. Just where did this number come from, and why does it matter?
[Benjojo] 对 1500 字节这个神奇数字的来源产生了兴趣,并且分享了一些关于它如何以及为何会成为现在的样子的背景。简而言之,最大传输单元(MTU)限制了单次网络层事务中可以传输的最大数据量,但在二进制中,1500 是一个比较奇怪的数字。对于普通互联网用户来说,这些底层的东西并不会真正影响他们发送数据的能力,但从网络管理的角度来看,它确实有影响。这个数字到底从何而来,又为何重要呢?
[Benjojo] looks at a year’s worth of data from a major Internet traffic exchange and shows, with the help of several graphs, that being stuck with a 1,500 byte MTU upper limit has real impact on modern network efficiency and bandwidth usage, because bandwidth spent on packet headers adds up rapidly when roughly 20% of all packets are topping out the 1,500 byte limit. Naturally, solutions exist to improve this situation, but elegant and effective solutions to the Internet’s legacy problems tend to require instant buy-in and cooperation from everyone at once, meaning they end up going in the general direction of nowhere.
[Benjojo] 查看了一年份来自一个主要互联网流量交换点的数据,并通过几张图表展示了,被限制在 1500 字节的 MTU 上限对现代网络效率和带宽使用有实际影响,因为当大约 20% 的数据包达到 1500 字节的上限时,用于数据包头部的带宽会迅速累积。当然,存在一些解决方案可以改善这种情况,但针对互联网遗留问题的优雅且有效的解决方案往往需要所有人立即接受并合作,这意味着它们最终往往会陷入僵局。
So where did 1,500 bytes come from? It appears that it is a legacy value originally derived from a combination of hardware limits and a need to choose a value that would play well on shared network segments, without causing too much transmission latency when busy and not bringing too much header overhead. But the picture is not entirely complete, and [Benjojo] asks that if you have any additional knowledge or insight about the 1,500 bytes decision, please share it because manuals, mailing list archives, and other context from that time is either disappearing fast or already entirely gone.
那么,1500 字节是从哪里来的呢?似乎它是一个遗留值,最初是从硬件限制和需要选择一个在共享网络段上表现良好的值中得来的,在繁忙时不会造成太多的传输延迟,也不会带来太多头部开销。但这个画面并不完整,[Benjojo] 请求,如果你对 1500 字节的决定有任何额外的知识或见解,请分享它,因为那时的手册、邮件列表存档和其他背景要么正在迅速消失,要么已经完全不见了。
Knowledge fading from record and memory is absolutely a thing that happens, but occasionally things get saved instead of vanishing into the shadows. That’s how we got IGNITION! An Informal History of Liquid Rocket Propellants_, which contains knowledge and history that would otherwise have simply disappeared.
知识从记录和记忆中逐渐消失绝对是一件会发生的事情,但偶尔有些东西会得以保存,而不是消失在阴影中。这就是我们得到《IGNITION! An Informal History of Liquid Rocket Propellants》的方式,它包含了本会消失的知识和历史。
59 Comments
-
Truth says:
June 29, 2021 at 1:19 am
I would try and make contact Vint Cerf or Bob Kahn, they may not know the answer, but they would definitely have more insight than most. And could probably point you in the direction of someone for a more definitive answer.
我会尝试联系 Vint Cerf 或 Bob Kahn,他们可能不知道答案,但他们肯定比大多数人更有洞察力。而且他们可能能指引你找到一个更明确的答案。 -
Alice Lalita Heald says:
June 29, 2021 at 1:23 am
Or it came from 80/20% header rule
或者它来自 80/20% 的头部规则。 -
Owen says:
June 29, 2021 at 1:30 am
That wouldn’t make a lot of sense. For that to be the case, an Ethernet header would have to be as much as 300 octets. Ethernet headers are only 18 octets.
Remember, the Ethernet Specification was independent of the header lengths in any higher layer protocols (e.g. AppleTalk, Banyan, DECNET, IPv4, IPv6, IPX, etc.).
这不太说得通。如果是这样的话,以太网头部必须多达 300 字节。以太网头部实际上只有 18 字节。
请记住,以太网规范与任何更高层协议(例如 AppleTalk、Banyan、DECNET、IPv4、IPv6、IPX 等)的头部长度无关。 -
Murray says:
June 29, 2021 at 8:01 am
I vote for 80/20. You don’t want too large packets, it increases the cost of retransmissions.
我支持 80/20。你不想让数据包太大,这会增加重传的成本。 -
Owen says:
June 29, 2021 at 1:25 am
I would suggest reaching out instead to Bob Metcalfe. To the best of my knowledge, Cerf and Kahn were involved in the development of Internet Protocol and the Internet, but not the L2 definitions of Ethernet.
Also, one could review the original IEEE 802.1/802.2/802.3 proceedings. and probably get a fairly good idea.
Bob Metcalfe was one of the principle investigators/developers of the original Ethernet specifications.
我建议联系 Bob Metcalfe。据我所知,Cerf 和 Kahn 参与了互联网协议和互联网的开发,但并没有参与以太网的 L2 定义。
此外,可以查阅原始的 IEEE 802.1/802.2/802.3 会议记录,可能会得到一个相当不错的概念。
Bob Metcalfe 是原始以太网规范的主要研究者之一。 -
Antron Argaiv says:
June 29, 2021 at 4:17 am
Second that. I once knew some of that information, but it’s lost in the cobwebs now. My memory is that the packet length is strongly tied to network efficiency and fairness. There’s a compromise between packet length (Ideally, you would transmit your entire message in one packet) and network availability (a shorter packet means the next user gets access to the network earlier). So you are trying to maximise both throughput and network utilisation, while minimizing wait time and overhead (collisions, interframe gap and header time). 1500 is probably the value that works best (for 10 mbits/s…see below)
我也同意。我以前知道一些这样的信息,但现在都遗忘了。我记得数据包长度与网络效率和公平性密切相关。数据包长度(理想情况下,你会将整个消息在一个数据包中传输)和网络可用性(较短的数据包意味着下一个用户可以更早地访问网络)之间存在折衷。因此,你试图在最大化吞吐量和网络利用率的同时,最小化等待时间和开销(碰撞、帧间间隔和头部时间)。1500 可能是最佳值(对于 10 Mbps 的网络……见下文)。 -
Owen says:
June 30, 2021 at 12:12 am
I’ll note that 4kbits is equal to 500 octets which is 1/3 of 1500 which 3mbps is a little less than 1/3rd of 10mbps, so that maps well.
OTOH, it means that leaving the MTU at 1500 octets as Ethernet scaled from 10Mbps to 100Mbps to 1,000Mbps (Gigabit), then 10Gbps and now even 100Gbps was, well, perhaps a bit silly.
我注意到 4kbits 等于 500 字节,这是 1500 的 1/3,而 3Mbps 略小于 10Mbps 的 1/3,所以这很匹配。
另一方面,这意味着当以太网从 10Mbps 升级到 100Mbps、1000Mbps(千兆)、10Gbps 甚至现在的 100Gbps 时,保持 MTU 为 1500 字节,嗯,可能有点愚蠢。 -
Barry says:
June 30, 2021 at 4:36 am
In fact all the backbone providers networks now transport jumbo frames, with 100/400G ports set to typically 9200 between P/PE routers. vSo they can carry Mpls payloads of also jumbo frame size.
Correct, its about setting mtu appropriately for the bandwidths available. indeed whilst routers can perform ip-fragmentation, not all do. so theres still some risk when going over 1500 with headers.
实际上,所有骨干网提供商的网络现在都传输巨型帧,100/400G 端口通常在 P/PE 路由器之间设置为 9200。因此它们可以携带也是巨型帧大小的 MPLS 负载。
正确,关键是根据可用带宽适当设置 MTU。确实,虽然路由器可以执行 IP 分片,但并非所有路由器都支持。因此,当带有头部的帧超过 1500 时,仍然存在一些风险。 -
Jason says:
June 30, 2021 at 11:40 pm
There is the Jumbo Frame option for internal networks:
内部网络有巨型帧选项:
https://en.m.wikipedia.org/wiki/Jumbo_frame -
Adam P says:
June 29, 2021 at 11:07 am
Second that. And I’m sure Bob Metcalfe will help. I reached out to him once to get his blessing to use the photo of the original Ethernet sketch (the one used in the illustration to this page) in my book. He agreed right away and we had a nice chat on top of that.
我也同意。我相信 Bob Metcalfe 会帮忙。我曾经联系过他,希望得到他允许在书中使用原始以太网草图(本页插图中使用的那幅)的照片。他立刻同意了,我们还愉快地聊了一会儿。 -
Antron Argaiv says:
June 29, 2021 at 12:27 pm
From Metcalfe and Boggs (referring to 3Mbit/s Ethernet):
“We limit in software the maximum length of our packets to be near 4000 bits to keep the latency of network access down and to permit efficient use of station packet buffer storage. For packets whose size is above 4000 bits, the efficiency of our experimental Ethernet stays well above 95 percent. For packets with a size approximating that of a slot, Ethernet efficiency approaches 1/e, the asymptotic efficiency of a slotted Aloha network [27].”
If you work that out, 4000 bits is 500 bytes, so for a 10Mbit/s network, the max packet size is just about 3 times that or 1500 bytes. The reasoning and math is in the paper at the link I posted above. Well worth the read and a bit of playing on Excel/Libre Calc
来自 Metcalfe 和 Boggs(关于 3Mbit/s 以太网):
“我们在软件中将数据包的最大长度限制在接近 4000 比特,以降低网络访问的延迟,并允许高效使用站点数据包缓冲区存储。对于大小超过 4000 比特的数据包,我们的实验性以太网效率保持在 95% 以上。对于大小接近时隙的数据包,以太网效率接近 1/e,这是时隙 ALOHA 网络的渐近效率 [27]。”
如果你计算一下,4000 比特是 500 字节,所以对于一个 10Mbit/s 的网络,最大数据包大小大约是它的 3 倍,即 1500 字节。我上面链接的论文中有推理和数学计算。值得一读,并且可以在 Excel/Libre Calc 上进行一些实验。 -
Lance Richardson says:
July 3, 2021 at 5:57 am
The “slotted ALOHA network” mentioned by Metcalfe is pretty interesting by itself. ALOHAnet was a packet radio network developed by the University of Hawaii in the ’70s that was a direct ancestor to both CSMA/CD Ethernet and WiFi. https://en.wikipedia.org/wiki/ALOHAnet
Metcalfe 提到的“时隙 ALOHA 网络”本身就很有趣。ALOHAnet 是夏威夷大学在 20 世纪 70 年代开发的一种分组无线网络,它是 CSMA/CD 以太网和 WiFi 的直接前身。https://en.wikipedia.org/wiki/ALOHAnet -
Juergen says:
June 29, 2021 at 1:29 am
I believe the raw MTU is 1536 including ethernet header. 1536 ist somewhat binary (1024+512)
我认为原始 MTU 是 1536,包括以太网头部。1536 有点像二进制数字(1024+512)。 -
Owen says:
June 30, 2021 at 12:18 am
Yes, that’s correct… On-wire MTU is 1536, including (IIRC, arguably obsolete) preamble and Ethernet framing/header/etc.
是的,这是正确的……线上的 MTU 是 1536,包括(据我记忆,可能已经过时)前导码和以太网帧/头部等。 -
CSMA-CD says:
June 29, 2021 at 1:37 am
A long time ago I remember reading some (paper) article about this. Dont remember the exact details. The article was from one of the inventors: Metcalf or Metcalfe.
1500 Bytes is from Ethernet.
The 1500 Bytes were a compromise.
– Fast memory (for buffers) was relatively expensive.
– the CSMA/CD access method dictated limits: If a larger size is used, the medium would be occupied too long, so the total number of allowed stations on the network would have to be limited. (Bridges/Switches did not exist then).
(- there is also a minimum size on Ethernet: 64 Bytes. It is a limit from the physical size an Ethernet network is allowed to have. If this size is reduced, the total physical Ethernet network span would have to be reduced. Otherwise Collisions could not be detected reliably.).
All these parameters of the original Ethernet were the result of simulations. There probably are some old PHD thesis about this.
All newer Ethernet technologies (10BaseT to 100GBase…) always maximized compatibility. So 1500 Bytes is still used today.
很久以前我记得读过一篇(纸质)文章,不记得具体细节了。这篇文章是一位发明者写的:Metcalf 或 Metcalfe。
1500 字节来自以太网。
1500 字节是一个折衷方案。
– 高速内存(用于缓冲区)相对昂贵。
– CSMA/CD 访问方法规定了限制:如果使用更大的尺寸,介质会被占用太久,因此网络上允许的站点总数必须受到限制。(当时还没有桥接器/交换机)。
(– 以太网还有一个最小尺寸:64 字节。这是以太网网络允许的物理尺寸的限制。如果这个尺寸减小,整个物理以太网网络跨度也必须减小。否则无法可靠地检测到碰撞。)
原始以太网的所有这些参数都是模拟的结果。可能有一些旧的博士论文涉及这个内容。
所有更新的以太网技术(从 10BaseT 到 100GBase……)始终最大化兼容性。因此,今天仍然使用 1500 字节。 -
SamT says:
June 29, 2021 at 1:43 am
If I remember correctly, it has to do with the hardware clock rates and/or buffer size on early interfaces. There’s a limit to how many packets the L1 hardware can process, divide the link speed by that number and voila, there’s the most efficient packet size. It was set very early on and as hardware has much longer life cycles back then, it just lingered on and continued to be supported until it would be WAY too hard to change it globally.
如果我记得正确,这与早期接口的硬件时钟速率和/或缓冲区大小有关。L1 硬件可以处理的数据包数量是有限的,将链路速度除以这个数字,结果就是最高效的数据包大小。这个值很早就被设定好了,由于当时的硬件生命周期更长,它一直被保留并继续得到支持,直到变得几乎不可能在全球范围内改变它。 -
Name says:
June 29, 2021 at 1:48 am
Why do my comments vanish?
为什么我的评论消失了? -
Elliot Williams says:
June 29, 2021 at 7:10 am
Because you said something mean, crazy, or political. Or replied to a comment that was one of the above, and the child comment got deleted with the parent.
Or because it got reported often enough that it was sent back to moderation, in which case if it’s fine, we’ll just re-approve it.
https://hackaday.com/policies/
因为你说了些刻薄、疯狂或政治性的话。或者回复了一条评论,而该评论属于上述情况之一,那么子评论也会被删除。
或者因为该评论被举报得太多,以至于被送回审核,如果没问题,我们会重新批准它。
https://hackaday.com/policies/ -
Wallace Owen says:
June 29, 2021 at 8:21 am
Perhaps due to the confluence of your username and not-well-adjusted input handling?
可能是因为你的用户名和不太合适的输入处理方式的结合? -
Elliot Williams says:
June 30, 2021 at 8:08 am
Nah. We’re ok with that. (Knock on wood…)
不,我们对此没问题。(希望如此……) -
Zoogara says:
June 29, 2021 at 2:11 am
I’m fairly certain from my 1980’s Ethernet training that it was a factor of the number of bits that could fit on the standard Ethernet cable combined with the minimum and maximum times that if would take to sense a collision.
CSMA/CD is the key here isn’t it? the “magic” number was all about the best chance of detecting carrier and collisions to achieve maximum throughput.
我相当确定,根据我 20 世纪 80 年代的以太网培训,它是标准以太网电缆上可以容纳的比特数的一个因素,结合了检测到碰撞所需的最小时间和最大时间。
CSMA/CD 是关键,不是吗?这个“神奇”的数字完全是为了最大化检测载波和碰撞的机会,以实现最大吞吐量。 -
Wallace Owen says:
June 29, 2021 at 8:19 am
Exactly so. If I’d read this first I’d not have made my post.
完全正确。如果我先读到这个,我就不会发表我的帖子了。 -
Antron Argaiv says:
June 29, 2021 at 11:44 am
No, that I do remember.
The length of the preamble and the inter-packet[frame] gap IFG, are related to the maximum segment length, because:
– 1. You want collisions to occur in the preamble if at all possible (preamble length)
– 2. You want the station at the opposite end of the segment to have an opportunity to see the medium is idle before anyone can transmit. (IFG)
不,我记得这个。
前导码的长度和帧间间隔 IFG 与最大段长度有关,因为:
– 1.你希望碰撞尽可能发生在前导码中(前导码长度)
– 2.你希望在任何人在段上传输之前,段的另一端的站点有机会看到介质是空闲的。(IFG) -
Owen says:
June 30, 2021 at 12:22 am
Not exactly. CSMA/CD collision detection combined with the 100 meter length limit is what dictated the size of the preamble, but not what dictated the 1500 octet MTU. The MTU was chosen based on the compromises around number of stations and high likelihood of transmit success on first try without tying up the wire too long.
不完全正确。CSMA/CD 碰撞检测结合 100 米长度限制决定了前导码的大小,但并不是决定 1500 字节 MTU 的因素。MTU 是基于站点数量和首次传输成功的高概率而选择的,而不会占用线路太久。 -
mikeselectricstuff says:
June 29, 2021 at 2:29 am
My guess would be it comes from early Ethernet hardware – 2K RAM for packet+workspace, Maybe also data recovery/synchronisation time constraints.
我猜这可能来自早期以太网硬件——2K RAM 用于数据包 + 工作空间,也许还有数据恢复/同步时间限制。 -
abjq says:
June 29, 2021 at 4:38 am
That sounds correct, just looking at the data link: “The EtherType field is two octets long and it can be used for two different purposes. Values of 1500 and below mean that it is used to indicate the size of the payload in octets, while values of 1536 and above indicate that it is used as an EtherType, to indicate which protocol is encapsulated in the payload of the frame. When used as EtherType, the length of the frame is determined by the location of the interpacket gap and valid frame check sequence (FCS).”
So if you’re running the larger frame size/MTU you’d need to hold off for the gap. If there was a collision or data error on the segment, the gap might get trashed, leading to a buffer overrun and all sorts of nasties (maybe crashing workstations etc as back in the day the s/w wasn’t that robust). So – best to keep it to 1500 or less for robustness.
这听起来是正确的,只是看看数据链路:“EtherType 字段是两个字节长,它可以用于两个不同的目的。1500 及以下的值表示它用于指示有效载荷的字节数,而 1536 及以上的值表示它用作 EtherType,以指示哪个协议封装在帧的有效载荷中。当用作 EtherType 时,帧的长度由帧间间隔和有效的帧检查序列(FCS)的位置决定。”
因此,如果你使用较大的帧大小/MTU,你需要等待间隔。如果在段上发生碰撞或数据错误,间隔可能会被破坏,导致缓冲区溢出和各种问题(因为过去的软件并不那么健壮,可能会导致工作站崩溃等)。所以——最好将它保持在 1500 或更少,以保证健壮性。 -
jonsmirl says:
June 29, 2021 at 5:03 am
MTUs came from the ARPANET IMP processor
https://en.wikipedia.org/wiki/Interface_Message_Processor
The 1500 is the maximum Ethernet packet size and it is that way due the original CDMA nature of Ethernet.
https://en.wikipedia.org/wiki/Ethernet_frame
I believe it was first specified in IEEE 802.3, but it might have been defined in DIX 1 or 2.
https://en.wikipedia.org/wiki/Carrier-sense_multiple_access_with_collision_detection
You also need to know about MAUs (Ethernet transceivers).
https://en.wikipedia.org/wiki/Medium_Attachment_Unit
MTU 来自 ARPANET IMP 处理器
https://en.wikipedia.org/wiki/Interface_Message_Processor
1500 是以太网数据包的最大大小,这是由于以太网的原始 CDMA 特性。
https://en.wikipedia.org/wiki/Ethernet_frame
我认为它最初是在 IEEE 802.3 中规定的,但也可能在 DIX 1 或 2 中定义。
https://en.wikipedia.org/wiki/Carrier-sense_multiple_access_with_collision_detection
你还需要了解 MAU(以太网收发器)。
https://en.wikipedia.org/wiki/Medium_Attachment_Unit -
Wallace Owen says:
June 29, 2021 at 8:17 am
Aah yes. The vampire tap. You would core into a foil jacketed half-in-diameter stiff cable to reveal a bare naked center conductor which you would then poke into with the MAU – a vampire tooth with insulation.
哦,是的。吸血鬼抽头。你会钻入一个半径为半英寸的硬电缆,该电缆包裹着一层铝箔护套,露出一个裸露的中心导体,然后你会用带有绝缘层的 MAU(吸血鬼牙)刺入它。 -
jonsmirl says:
June 29, 2021 at 6:08 pm
https://networkengineering.stackexchange.com/questions/2962/why-was-the-mtu-size-for-ethernet-frames-calculated-as-1500-bytes
It appears to be a function of two things.
– 1. the anti-babble feature of the MAU
– 2. The change in definition of the Ethertype from DIX to 802.3
Plus you don’t want a single node hogging the wire too long.
我认为这是一个由两件事决定的功能。
– 1.MAU 的防喋喋不休功能
– 2.Ethertype 从 DIX 到 802.3 的定义变化
此外,你不想让一个节点占用线路太久。 -
Antron Argaiv says:
June 29, 2021 at 11:46 am
…and then the AUI cable would rip itself off the transceiver because the damn slide latch didn’t retain it worth beans.
……然后 AUI 电缆会从收发器上扯下来,因为该死的滑动卡扣根本就扣不住它。 -
jonsmirl says:
June 29, 2021 at 5:06 am
Look up CDMA/CS and Ethernet transceivers. I believe it was first specified in IEEE 802.3 or maybe DIX 1/2. It is a function of the math for CDMA/CS.
查找 CDMA/CS 和以太网收发器。我认为它最初是在 IEEE 802.3 或 DIX 1/2 中规定的。这是 CDMA/CS 数学的一个功能。 -
Wallace Owen says:
June 29, 2021 at 8:14 am
s/CS/CD/ – CSMA/CD, or Carrier Sense Multiple Access/Carrier Detect.
s/CS/CD/ – CSMA/CD,即载波侦听多路访问/载波检测。 -
mkomarinski says:
June 29, 2021 at 5:25 am
I’d guess memory size plus likely a balance of latency. Transmission lines were really slow then and if you want ‘quick’ turnaround then the packets have to be small.
我猜是内存大小加上延迟的平衡。当时的传输线路真的很慢,如果你想要快速的周转,那么数据包必须小。 -
Torrente says:
June 29, 2021 at 6:16 am
Several technical parameters today are tied to past architectural decisions.
From HD limits, file systems, SQLs, network parameters.
You cannot build something without being elastic in architecture.
If something in your architecture can lead to limits, look for alternatives, or at some point a break in compatibility will be required.
1500 limit is just one among many others, look at x86/PC the size of the limitations that we follow until today.
今天许多技术参数都与过去的架构决策有关。
从硬盘限制、文件系统、SQL 到网络参数。
你不能在没有弹性架构的情况下构建东西。
如果你架构中的某些东西会导致限制,寻找替代方案,否则在某个时刻将需要打破兼容性。
1500 限制只是其中之一,看看 x86/PC,我们至今仍在遵循的限制有多大。 -
DSchultz says:
June 29, 2021 at 6:50 am
MAP might have mentioned something about it in “The Elements of Networking Style” but it has been a while since I read it.
MAP 可能在《网络风格要素》中提到过一些关于它的东西,但我已经很久没读过了。 -
Wallace Owen says:
June 29, 2021 at 8:12 am
Actual limit is 1536 octets (bytes). A consequence of the media (copper) access method used by Ethernet. The reason is that this was needed to meet limits on back-off time for CSMA-CD, the transmission method used to manage segment ownership. If it was longer than 1536, at 10mb/second (original speed), effective use of the copper was poor with all those that had attempted to transmit stepping on the packet forcing the first user to retransmit, with a specified max nodes per segment, any one of which might begin to transmit a packet, it was a compromise to meet the spec that statistically, Ethernet, and by extension CSMA, could provide a certain bandwidth without requiring tokens, or a management layer with a central node. Remember, it wasn’t the only network out there. It was a compromise at 10Mb/s.
实际限制是 1536 字节(字节)。这是以太网使用的介质(铜)访问方法的结果。原因是,为了满足 CSMA/CD 的退避时间限制,CSMA/CD 是用于管理段所有权的传输方法。如果它超过 1536,在 10mb/秒(原始速度)下,由于所有尝试传输的节点都会覆盖数据包,迫使第一个用户重新传输,而每个段都有指定的最大节点数,其中任何一个都可能开始传输一个数据包,这是一个折衷方案,以满足规范,从统计上看,以太网,以及扩展到 CSMA,可以在不需要令牌或具有中心节点的管理层的情况下提供一定的带宽。请记住,它并不是唯一的网络。这是一个在 10Mb/s 下的折衷方案。 -
Antron Argaiv says:
June 29, 2021 at 11:47 am
It was the only GOOD network out there.
它是那里唯一的好的网络。 -
Simon McNair says:
June 29, 2021 at 8:27 am
It’s a bit sad that so much background and context is being lost in this digital age. It almost feels as if books have a place in condensing this kind of information in a way that newsgroups and emails do not have lasting impact.
在这个数字时代,这么多背景和上下文正在丢失,这有点令人难过。这几乎让人感觉,书籍在压缩这类信息方面有其独特之处,而新闻组和电子邮件则没有持久的影响。 -
NoOneOfInterest says:
June 29, 2021 at 8:45 am
It’s been a few fortnights but I’ll take a stab at this one. Totally cannot produce any documentation of substance.
Three decades ago I worked for a Token Ring (802.5) firm. Not IBM but one that OEM’d Token Ring h/w to IBM. We were working on implementing big frames (16K? not sure, many tequilas ago) and discovered the obvious – a frame has a physical length when it’s on a wire. If the frame is physically longer than the wire it’s transmitted on the hardware must start processing the frame before the entire frame is received by the hardware. The alternative is storing the entire frame before processing, which slows transmit rates. It seems counter-intuitive – but bigger frames can result in slower throughput. A lot of networks don’t physically have enough wire length to support big frames.
…and that’s why small “frame”/cell tech like ATM and SONET/SDH often carry our data today – even if “Ethernet” is layered on top of it. We often share our networks today so smaller “transactions” can result in increased perception of speed – not necessarily throughput but sometimes that’s faster too.
Fun note – we had a Fluke meter back in the day. It would tell us the electrical length of the network and we would calculate the MTU from that to make sure the frame would fit on the customer network.
已经过去几周了,但我会尝试回答这个问题。完全无法提供任何实质性的文件。
三十年前,我在一家 Token Ring(802.5)公司工作。不是 IBM,而是为 IBM 提供 Token Ring 硬件的 OEM。我们正在尝试实现大帧(16K?不确定,那是很久以前的事了),并发现了显而易见的事实——当帧在电线上时,它有物理长度。如果帧的物理长度大于它所传输的电线长度,硬件必须在收到整个帧之前就开始处理帧。另一种选择是在处理之前存储整个帧,这会降低传输速率。这似乎违反直觉——但更大的帧会导致吞吐量降低。许多网络在物理上没有足够的电线长度来支持大帧。
……这就是为什么今天像 ATM 和 SONET/SDH 这样的小“帧”/单元技术经常携带我们的数据——即使“以太网”被分层在它之上。我们今天经常共享我们的网络,因此更小的“事务”可以增加速度的感知——不一定是吞吐量,但有时这也更快。
有趣的是——我们当时有一个 Fluke 测量仪。它可以告诉我们网络的电气长度,我们根据这个计算 MTU,以确保帧可以适应客户的网络。 -
Antron Argaiv says:
June 29, 2021 at 11:54 am
I also designed Token Ring boards…something I never want to do again. 4Mbit TR might have worked well, but when they tried to go to UTP and then 16Mbit TR, well…the warts started to reveal themselves.
Getting a UTP-16M TR switch through radiated emissions testing was an exercise in frustration. All the more so, when 100BASE-T was coming out at the same time. You knew it was futile, but you still had to do it. Luckily, I was able to join the Ethernet side of the business, which was much more fun.
Much later, at a different company, I was called upon to make an “in-house” fiber-based token passing network…work. The designer had left, his MAC was implemented inside a Xilinx chip with minimal comments, and the process of electing a master to initiate the token wasn’t working. Loads of fun…not…but I got it working after hacking a bit. So no matter where you are, your work on TR can come back to bite you!
我也设计过 Token Ring 板……这是我再也不想做的事情。4Mbit TR 可能效果不错,但当他们尝试转向 UTP,然后是 16Mbit TR 时,问题开始暴露出来。
让一个 UTP-16M TR 交换机通过辐射发射测试是一项令人沮丧的练习。尤其是当 100BASE-T 同时问世时。你知道这是徒劳的,但你仍然必须去做。幸运的是,我能够加入以太网业务,这要有趣得多。
很久以后,在另一家公司,我被要求让一个“内部”的光纤令牌传递网络……工作。设计者已经离开,他的 MAC 被实现在一个 Xilinx 芯片中,几乎没有注释,选举一个主节点来启动令牌的过程也不起作用。非常有趣……不是……但我在黑客攻击后让它工作了。所以无论你在哪里,你的 TR 工作都可能反过来咬你一口! -
Keith Milner says:
June 29, 2021 at 12:17 pm
As I recall, from building metro Token Ring networks for banks, the much feted “wrap” capability of Token Ring that allowed it to “heal” was actually a function of the connectors which would mechanically switch, when unplugged, to create the wrapped network.
If a cable actually broke, then the whole network would go down.
With UTP, they had to emulate that in software because RJ45 don’t have that feature and, in my experience, it didn’t work very well. When we first started building these networks for banks, we would often get a call saying “our network is down” because someone in the bank had unplugged part of the ring expecting it to wrap and, for some reason, it hadn’t. Or one of their cables had gone faulty, breaking the ring. And, of course, when their whole network went down, that was our fault.
据我回忆,我在为银行构建城域 Token Ring 网络时,Token Ring 备受赞誉的“自愈”能力实际上是由连接器实现的,这些连接器在拔出时会机械切换,从而创建一个闭环网络。
如果电缆真的断了,那么整个网络就会瘫痪。
对于 UTP,他们不得不在软件中模拟这一功能,因为 RJ45 没有这个功能,而根据我的经验,它效果不太好。当我们刚开始为银行构建这些网络时,我们经常接到电话说“我们的网络瘫痪了”,因为银行里的某个人拔掉了环的一部分,期望它能够自愈,但不知何故它没有。或者他们的某根电缆出了故障,打破了环。当然,当他们的整个网络瘫痪时,这就是我们的错。 -
Antron Argaiv says:
June 29, 2021 at 1:37 pm
Exactly. Those clunky Type I connectors were a royal PITA, even more so than the Ethernet AUI “slide latch,” which was totally ineffective against plenum insulated AUI cables. I can’t imagine their “self shorting” ability was all that reliable…nobody liked them or the inflexible cables. And, of course, the hubs were huge. The only solution was to use switches, and get away from shared media (to be fair, this was just as much of a problem with Ethernet!). But a TR MAC/PHY was 3x the cost of an Ethernet MAC/PHY, and once 100BASE-T came out, 16Meg TR just couldn’t compete, except on “low latency” and “guaranteed delivery.”
The problem with UTP TR was that, while the Ethernet UTP waveform was tailored to minimize radiated emissions, doing that with TR induced intolerable amounts of jitter…so they couldn’t do it, and it radiated like a banshee.
I designed Data General’s TR interface card for their AViiON workstations, because the contract specified a TR interface. Marketing said that if I couldn’t build it cheap, they’d go outside and buy an OEM card. So I used a bunch of GALs and massaged the Motorola bus interface on the (TI TMS380C16, IIRC) TR chip to be a VME bus interface and we had the world’s cheapest TR card!
(shortly thereafter, Motorola discontinued the 88K processor on which AViiON was based, and that was the end of THAT adventure!)
完全正确。那些笨重的 Type I 连接器真是让人头疼,甚至比以太网的 AUI“滑动卡扣”还要糟糕,后者对风管绝缘的 AUI 电缆完全无效。我无法想象它们的“自短路”能力有多可靠……没人喜欢它们或那些不灵活的电缆。当然,集线器也非常大。唯一的解决方案是使用交换机,远离共享介质(公平地说,以太网也有同样的问题!)。但 TR MAC/PHY 的成本是以太网 MAC/PHY 的三倍,一旦 100BASE-T 问世,16M TR 就无法竞争了,除了在“低延迟”和“保证交付”方面。
UTP TR 的问题是,虽然以太网的 UTP 波形被调整以最小化辐射发射,但对 TR 进行这种调整会导致无法容忍的抖动……所以他们做不到,它就像女妖一样辐射。
我为 Data General 的 AViiON 工作站设计了 TR 接口卡,因为合同规定了 TR 接口。市场部门说,如果我不能廉价地制造它,他们就会到外面去购买 OEM 卡。所以我使用了许多 GAL,并调整了(TI TMS380C16,如果我记得没错的话)TR 芯片上的 Motorola 总线接口,使其成为 VME 总线接口,于是我们有了世界上最便宜的 TR 卡!
(不久之后,Motorola 停产了 AViiON 所基于的 88K 处理器,那场冒险也就此结束!) -
Tom K says:
June 30, 2021 at 5:46 am
I love the idea that data has a physical length “a frame has a physical length when it’s on a wire”. Out of interest (because my maths is terrible), what would be the calculation to determine, say, the length of a 400 bit message sent over Ethernet?
我喜欢“数据在电线上时有物理长度”这个概念。出于兴趣(因为我的数学很差),如何计算,比如说,通过以太网发送的 400 比特消息的长度呢? -
my2c says:
July 15, 2021 at 8:57 pm
– Still comes into play today – FC storage switches negotiate buffer credits – essentially how much a sender can blast away into a wire before taking a break to confirm – since at 32Gbps you can pump a lot of data into a physical fiber before it hits the other end (LW, KM’s away) – and the less ack’s you need to wait for the better – but you also don’t want to overrun the buffer at the receiver and create retransmits or other issues. The more memory the receiver has available, the more credits can be given to a client/connection – and I believe LW connections receive more credits than SW connections, so they can queue more data up on the wire / less ACK round trips.
– 这在今天仍然起作用——FC 存储交换机协商缓冲区信用——本质上是一个发送方可以在确认之前向电线发送多少数据——因为以 32Gbps 的速度,你可以在数据到达另一端(LW,几公里之外)之前向物理光纤中传输大量数据——你等待的确认越少越好——但你也不想溢出接收方的缓冲区并导致重传或其他问题。接收方可用的内存越多,就可以向客户端/连接授予更多的信用——我认为 LW 连接比 SW 连接获得更多的信用,因此它们可以在电线上排队更多数据/减少 ACK 往返。 -
Keith Milner says:
June 29, 2021 at 9:31 am
It’s because Ethernet has become the default transport for most of the Internet.
See https://datatracker.ietf.org/doc/html/rfc894
Originally Ethernet was a fat coaxial cable bus that stations connected to. When the station needed to send data it had to wait until any other transmissions had finished and then attempt to transmit. If two stations tried to transmit at the same time, you got a “collision” and both stations had to abandon their transmit and try again after a random time. If the maximum packet size was too large then that would block other stations from using the network. 1500 was, fairly arbitrarily, chosen as a good size to support most data types at the time, whilst not causing too many delays for other stations on the bus.
Additionally, the transceivers had a safety feature built in to stop faults in a station from blocking the whole network. This was known as “anti-babble”: if a station transmission was longer than around 1.25 ms, then the transceiver would assume it was faulty and isolate it from the network.
See: http://www.pennington.net/archives/ethernet/Ethernet_Version_2.pdf
因为以太网已经成为互联网的主要传输方式。
查看 https://datatracker.ietf.org/doc/html/rfc894
最初,以太网是一个粗同轴电缆总线,各个站点连接到它上面。当站点需要发送数据时,它必须等到其他传输完成,然后尝试传输。如果两个站点同时尝试传输,就会发生“冲突”,两个站点都必须放弃传输,并在随机时间后重试。如果最大数据包大小太大,那么就会阻止其他站点使用网络。1500 被相当随意地选为一个合适的大小,既能支持当时大多数数据类型,又不会给总线上的其他站点造成太多延迟。
此外,收发器内置了一个安全功能,以防止站点的故障阻塞整个网络。这被称为“防喋喋不休”:如果站点的传输时间超过大约 1.25 毫秒,那么收发器就会认为它有故障,并将其隔离在网络之外。
查看:http://www.pennington.net/archives/ethernet/Ethernet_Version_2.pdf -
jonsmirl says:
June 29, 2021 at 10:12 am
That is the DIX 2.0 specification but I don’t see the math in it for how 1518 was calculated. If people keep digging there is a formula about the timing of packets on the original thick coax Ethernet segments. Once you find that formula it will tell you the maximum time the packet can last and from that you can figure out the maximum packet length. This is all rooted in the design of CSMA-CD protocol. 1500 seems arbitrary now that CSMA-CD is no longer in use.
BTW, before 1500 it was 576 bytes on the packet switched networks based on telephone lines.
这是 DIX 2.0 规范,但我没有看到关于如何计算 1518 的数学公式。如果人们继续挖掘,会有一个关于原始粗同轴以太网段上数据包时序的公式。一旦你找到那个公式,它就会告诉你数据包可以持续的最大时间,从那里你可以计算出最大数据包长度。这都源于 CSMA/CD 协议的设计。现在 CSMA/CD 不再使用,1500 似乎显得很随意。
顺便说一下,在 1500 之前,基于电话线的分组交换网络上的数据包大小是 576 字节。 -
Keith Milner says:
June 29, 2021 at 1:24 pm
Here’s the v1 spec. It contains a lot of the same text, and doesn’t describe much about the packet timing that I could see:
http://www.pennington.net/archives/ethernet/Ethernet_Version_1.pdf
这是 v1 规范。它包含了很多相同的文本,而且我没有看到关于数据包时序的太多描述:
http://www.pennington.net/archives/ethernet/Ethernet_Version_1.pdf -
Jack Dansen says:
June 29, 2021 at 10:37 am
I spent a lot of time trying to run this down without success. At this point, we would probably be better off creating a new protocol which is just Ethernet but with a much larger MTU default and a protocol for negotiating MTUs with upstream switches. Possibly we could co-opt an ethertype to flag an upgrade.
我花了很长时间试图弄清楚这个问题,但没有成功。在这个阶段,我们可能最好创建一个新的协议,它只是以太网,但有一个更大的 MTU 默认值,并且有一个与上游交换机协商 MTU 的协议。也许我们可以利用一个 EtherType 来标记升级。 -
Ryan Erickson says:
June 29, 2021 at 11:04 am
If you trace it back far enough, it ends up being the number of octets you can fit between the width of two horses’ rear ends.
如果你追溯得足够远,最终会发现它取决于两匹马屁股之间的宽度可以容纳多少字节。 -
Gregg Eshelman says:
June 29, 2021 at 11:11 am
In short whomever invents and introduces a technology tends to get stuck with the original while others come up with better versions. (see NTSC TV vs PAL) In the case of network technology that 1500 bytes became so widespread before hardware and protocols were developed to easily handle larger packets.
So the world is stuck with it until something comes along that can handle larger packets AND seamlessly “downshift” to 1500. To make that easiest, a larger packet size should be a multiple of what’s current so software and hardware can “thunk” between different sizes by buffering x small packets to assemble one large packet or hold one large packet and chunk it into small packets to send out sequentially.
It just needs to be done, like getting rid of all the early 7 bit hardware on the internet that trashed binary data and non-English text passing through by setting the least significant bit to zero, because in the base ASCII character set that bit is always zero.
7 bit routers are why BinHex exists. Unlike MacBinary, BinHex uses only 7 bit characters. I remember when Macintosh software sites had downloads in Stuffit, MacBinary, and BinHex, often with small test files to download and extract to see if something in the route between them and you mangled it. If you were on slow dialup, especially with a metered connection, you really wanted to be able to download Stuffit or MacBinary.
简而言之,谁发明并引入了一种技术,往往就会被原始版本困住,而其他人则会开发出更好的版本。(参见 NTSC 电视与 PAL)在网络技术的情况下,1500 字节变得如此广泛,以至于在硬件和协议开发出来之前,它们都无法轻松处理更大的数据包。
因此,世界将一直困于它,直到出现某种能够处理更大数据包并且能够无缝“降档”到 1500 的东西。为了使这最容易实现,更大的数据包大小应该是当前大小的倍数,以便软件和硬件可以通过缓冲 x 个小数据包来组装一个大数据包,或者将一个大数据包分成小数据包依次发送,从而在不同大小之间“转换”。
这只是需要做的事情,就像消除互联网上所有早期的 7 位硬件,这些硬件通过将最低有效位设置为零来破坏二进制数据和通过的非英文文本,因为在基本 ASCII 字符集中,该位始终为零。
7 位路由器是 BinHex 存在的原因。与 MacBinary 不同,BinHex 只使用 7 位字符。我记得 Macintosh 软件网站上有 Stuffit、MacBinary 和 BinHex 的下载,通常还有小测试文件可供下载和解压,以查看在他们和你之间的路由中是否有东西损坏了。如果你使用的是慢速拨号连接,尤其是按流量计费的连接,你真的希望能够下载 Stuffit 或 MacBinary。 -
IanS says:
June 30, 2021 at 2:26 am
s/least significant bit/most significant bit/
s/least significant bit/most significant bit/ -
Steven Gerber says:
June 29, 2021 at 12:47 pm
Sorry, but
CSMA/CD: Carrier Sense Multiple Access w/ Collision Detection
对不起,但
CSMA/CD:带冲突检测的载波侦听多路访问 -
Experienced Experimenter says:
June 29, 2021 at 12:53 pm
The 1500 byte limit may come from memory limitations of early store and forward packet switches, since they would store entire packets in memory before retransmitting them. If they didn’t exist at the time that number was declared, then it could have been related to limiting the memory that needed to be embedded in network adapters.
1500 字节限制可能来自早期存储和转发分组交换机的内存限制,因为它们会在转发之前将整个数据包存储在内存中。如果在宣布该数字时它们还不存在,那么它可能与限制需要嵌入网络适配器中的内存量有关。 -
Keith Milner says:
June 29, 2021 at 1:16 pm
No, it was the original frame size on the original shared-media Ethernet chosen, largely, to give all stations a reasonable chance of being able to transmit. It predated store and forward LAN switches by about 20 years.
不,这是原始共享介质以太网上选择的原始帧大小,主要是为了让所有站点都有合理的机会进行传输。它比存储和转发局域网交换机早了大约 20 年。 -
abjq says:
June 29, 2021 at 1:56 pm
Experimenter might have been thinking of x.25 packet switches, which would have been used for WANs, but they had a max packet size of 1024 Bytes.
实验者可能在想 x.25 分组交换机,这些用于广域网,但它们的最大数据包大小为 1024 字节。 -
HackJack says:
June 29, 2021 at 3:26 pm
MTU issue gets more complicated when tunnel is involved. The devices on both end of the tunnel has no idea there is a tunnel yet the tunnel still limited by the MTU. So everything has to be scaled down or be fragmented. it is a mess.
当涉及隧道时,MTU 问题变得更加复杂。隧道两端的设备都不知道存在隧道,但隧道仍然受到 MTU 的限制。因此,所有东西都必须缩小或被分片。这是一团糟。 -
Bill says:
June 29, 2021 at 4:55 pm
Back in the day, I was chairperson for organizing bi-monthly meetings of Ohio’s higher education network OARnet. It was about 1997 that higher performance connectivity with the moniker Internet2 was the Vogue. The Ohio Supercomputer Center was one of the entities involved in Internet2 research. We brought in an expert from the OSC to talk about internetworking performance. Packet length was discussed. Of course there are many competing variables. OSC research had shown that under average conditions of packet loss, segment length, application behavior, etc. that 1500 octets is a good default compromise. As it was, Bob Metcalfe and friends had made a pretty good choice. It is kind of like the fact 50 Ohm coaxial cable isn’t magic number, but it is a real world compromise between several competing factors.
最初的以太网运行速度为 3 兆比特。为什么是 3Mb?因为这比 Alto 计算机的数据路径慢,而以太网正是为 Alto 计算机发明的。这意味着最初的以太网接口在数据到达时不需要缓冲数据,它们可以直接将比特写入计算机的内存(当时的内存非常昂贵)。
当年,我是俄亥俄州高等教育网络 OARnet 双月会议的主席。大约在 1997 年,高性能连接(名为 Internet2)成为时尚。俄亥俄超级计算机中心是参与 Internet2 研究的机构之一。我们邀请了一位来自 OSC 的专家来讨论互联网性能。讨论了数据包长度。当然,有许多相互竞争的变量。OSC 的研究表明,在平均条件下的数据包丢失、段长度、应用程序行为等情况下,1500 字节是一个不错的默认折衷方案。正如鲍勃·梅特卡夫和他的朋友们做出了一个相当不错的选择一样。这有点像 50 欧姆同轴电缆并不是一个神奇的数字,但它是在几个相互竞争的因素之间的一个现实世界的折衷方案。I later worked for a business and we experimented with jumbo packets on our gigabit LAN when writing backups. The real world performance gain was only a few percent, so we decided to stick with 1500 octet packet length to keep life simple.
后来,我在一家公司工作,我们在千兆局域网上尝试使用巨型数据包进行备份写入。实际性能提升只有几个百分点,所以我们决定坚持使用 1500 字节的数据包长度,以保持简单。I still find myself on occasion going to Bill Stalling’s classic three volume set of networking books from the 1980s.
我仍然偶尔会翻阅比尔·斯托林斯 20 世纪 80 年代的经典三卷本网络书籍。 -
Richard Brodie says:
July 1, 2022 at 7:18 am
I think Bob Metcalfe was once asked what he would change if he had to reinvent Ethernet and he replied something on the lines of: ‘make the maximum packet size larger and fix the damn latch.’
我认为鲍勃·梅特卡夫曾经被问到,如果他要重新发明以太网,他会改变什么,他回答说:“把最大数据包大小弄得更大一些,把该死的卡扣修好。” -
dm says:
March 27, 2024 at 2:12 pm
Ethernet maximum frame sizes vary with the governing standards (e.g., the various 802.11 standards), but mostly, they’re around 1536 bytes (IP packets are 1500 bytes because Ethernet uses some bytes from the frame for its own addressing).
以太网的最大帧大小因标准而异(例如,各种 802.11 标准),但大多数情况下,它们大约是 1536 字节(IP 数据包是 1500 字节,因为以太网使用帧中的一些字节用于自己的寻址)。So, why 1536 bytes on the original Ethernet?
那么,为什么原始以太网是 1536 字节呢?The very original Ethernet ran at 3 megabits. Why 3Mb? Because that was slower than the data path in the Alto computer, for which Ethernet was invented. This meant that the original Ethernet interfaces did not have to buffer data as it arrived, they could just write the bits into the computer’s memory (memory was very expensive then).
An Ethernet frame of 1536 bytes is 12288 bits, which takes 4096 (2^12) microseconds to transmit at 3Mb/s.
…And, at a 3Mb rate, a bit is about 300 feet long on the cable.
…And Ethernet works by listening to see if the cable is idle before you try to transmit a frame, so you want all your Ethernet interfaces to be within a light-bit of one another. Which is okay! This is a Local Area Network built for an office.一个 1536 字节的以太网帧是 12288 比特,在 3Mb/s 的速度下传输需要 4096( 2 12 2^{12} 212)微秒。
……而且,在 3Mb 的速率下,电缆上的一个比特大约有 300 英尺长。
……而且以太网的工作方式是在你尝试传输一个帧之前,先监听电缆是否空闲,所以你希望所有以太网接口彼此之间在一个光比特的范围内。这是可以的!这是一个为办公室建造的局域网。
What is the actual size of an Ethernet MTU
以太网 MTU 的实际大小是多少
38
I think I might be getting confused with terminology surrounding MTU.
我认为我可能对 MTU 的术语有些混淆。
This definition from Wendell Odom’s CCNA book on MTU:
这是 Wendell Odom 的 CCNA 书中关于 MTU 的定义:
The IEEE 802.3 specification limits the data portion of the 802.3 frame to a minimum of 46 and a maximum of 1500 bytes. The term maximum transmission unit (MTU) defines the maximum layer 3 packet that can be sent over a medium. Because the layer 3 packet rests inside the data portion of an Ethernet frame, 1500 bytes is the largest IP MTU allowed over an Ethernet.
IEEE 802.3 规范将 802.3 帧的数据部分限制在最小 46 字节和最大 1500 字节之间。术语“最大传输单元(MTU)”定义了可以在介质上传送的最大第三层数据包。由于第三层数据包位于以太网帧的数据部分内,因此允许通过以太网传输的最大 IP MTU 为 1500 字节。
My understanding, is that an Ethernet frame is the last phase of encapsulation before it gets transmitted to the wire. When I look at a diagram of an Ethernet frame, its total size can equal a maximum of 1526 bytes.
我的理解是,以太网帧是数据在传输到线路上之前的最后一层封装。当我查看以太网帧的图表时,其总大小可以达到最大 1526 字节。
Am I right in saying that an Ethernet frame MTU is 1526 while the MTU at the IP layer is 1500? Does the MTU change at each phase of encapsulation, or is the term “MTU” only meant to define the maximum size of a packet at layer 3?
我说以太网帧的 MTU 是 1526,而 IP 层的 MTU 是 1500,这样说对吗?MTU 是否在每个封装阶段都会变化,还是术语“MTU”仅用于定义第三层数据包的最大大小?
edited Sep 11, 2021 at 22:20 S. M.
asked Nov 19, 2013 at 19:41 Josh
41
Am I right in saying that an Ethernet frame MTU is 1526 while the MTU at the IP layer is 1500?
我说以太网帧的 MTU 是 1526,而 IP 层的 MTU 是 1500,这样说对吗?
The Ethernet MTU is 1500 bytes, meaning the largest IP packet (or some other payload) an Ethernet frame can contain is 1500 bytes. Adding 26 bytes for the Ethernet header results in a maximum frame (not the same as MTU) of 1526 bytes.
以太网 MTU 是 1500 字节,这意味着以太网帧可以包含的最大 IP 数据包(或其他有效载荷)是 1500 字节。加上 26 字节的以太网头部,结果是一个 最大帧(与 MTU 不同)为 1526 字节。
Does the MTU change at each phase of encapsulation, or is the term “MTU” only meant to define the maximum size of a packet at layer 3?
MTU 是否在每个封装阶段都会变化,还是术语“MTU”仅用于定义第三层数据包的最大大小?
The MTU is often considered a property of a network link, and will generally refer to the layer 2 MTU. The limits at layer 3 are far higher (see below) and cause no issues.
MTU 通常被视为网络链路的属性,通常指的是第二层 MTU。第三层的限制要高得多(见下文),不会引起任何问题。
The length of an IP packet (layer 3) is limited by the maximum value of the 16 bit Total Length field in the IP header. For IPv4, this results in a maximum payload size of 65515 (= 2^16 - 1 - 20 bytes header). Because IPv6 has a 40 byte header, it allows for payloads up to 65495. And IIRC using the Jumbo Payload header extension, IPv6 could allow packets up to 4 GB…
IP 数据包(第三层)的长度由 IP 头部中 16 位总长度字段的最大值限制。对于 IPv4,这导致最大有效载荷大小为 65515(= 2^16 - 1 - 20 字节头部)。因为 IPv6 有 40 字节的头部,它允许有效载荷高达 65495。如果我记得没错,使用巨型有效载荷头部扩展,IPv6 可以允许高达 4 GB 的数据包……
When setting up a TCP connection, a Maximum Segment Size (MSS) is agreed upon. This could be considered an MTU at layer 4, but it is not fixed. It is often set to the largest payload that can be sent in a TCP segment without causing fragmentation, thus reflecting the lowest layer 2 MTU on the path. With an ethernet MTU of 1500, this MSS would be 1460 after subtracting 20 bytes for the IPv4 and TCP header.
在建立 TCP 连接时,会协商一个最大报文段大小(MSS)。这可以被视为第四层的 MTU,但它不是固定的。它通常被设置为可以在 TCP 报文中发送的最大有效载荷,而不会导致分片,因此反映了路径上最低的第二层 MTU。对于 1500 字节的以太网 MTU,减去 IPv4 和 TCP 头部的 20 字节后,这个 MSS 将是 1460。
edited Aug 4, 2017 at 13:19 cmbuckley
answered Nov 19, 2013 at 21:30 Gerben
13
Specifying an Ethernet “header” of 26 bytes seems to be assuming a Q-in-Q encapsulation. The standard Ethernet header is 14 bytes, with an FCS of 4 bytes at the end of the frame. So this leads to an Ethernet frame size of 1518 bytes for a 1500 byte IP packet. Each 802.1Q vlan tag adds another 4 bytes, so a single layer of vlan encapsulation will result in an ethernet overhead of 22 bytes, and it is only when 2 VLAN tags are included that the overhead is 26 bytes (technically only 22 bytes of this is header, and 4 bytes of trailer).
指定一个 26 字节的以太网“头部”似乎假设了 Q-in-Q 封装。标准以太网头部是 14 字节,帧尾部有 4 字节的 FCS。因此,对于一个 1500 字节的 IP 数据包,这导致了一个以太网帧大小为 1518 字节。每个 802.1Q vlan 标签再增加 4 字节,因此单层 vlan 封装将导致以太网开销为 22 字节,只有当包含 2 个 VLAN 标签时,开销才是 26 字节(技术上只有 22 字节是头部,4 字节是尾部)。
– Russell Heilling CommentedFeb 21, 2014 at 22:23
Why was the MTU size for ethernet frames calculated as 1500 bytes?
为什么以太网帧的 MTU 大小被计算为 1500 字节?
42
Why was ethernet MTU calculated as 1500 bytes?
为什么以太网的 MTU 被计算为 1500 字节?
What specific calculation was done to arrive at 1500 byte ethernet MTUs, and what factors were considered for that calculation?
为了得出 1500 字节的以太网 MTU,进行了哪些具体的计算,考虑了哪些因素?
edited Oct 22, 2021 at 0:41 Mike Pennington
asked Aug 24, 2013 at 16:14 Padmaraj
3
IEEE people are resisting adding 9k to the standard because mathematical guarantees FCS brings today at 1.5k would not all be true anymore at 9k.
IEEE 人员抵制将 9k 添加到标准中,因为在 1.5k 时 FCS 带来的数学保证在 9k 时将不再完全成立。
– ytti
CommentedAug 25, 2013 at 6:27
6
@ytti, that is only one of the arguments against endorsing 1500 frames. The full text of Geoff Thomson’s letter (containing the IEEE objections to standardizing jumbo frames) is in draft-ietf-isis-ext-eth-01 Appendix 1. The objections start with the word “Consideration”
@ytti,这只是反对支持大于 1500 字节帧的一个论点。Geoff Thomson 的信件全文(包含 IEEE 对标准化巨型帧的反对意见)在 draft-ietf-isis-ext-eth-01 附录 1 中。反对意见以“Consideration”一词开始。
– Mike Pennington
CommentedAug 26, 2013 at 4:57
Did any answer help you? If so, you should accept the answer so that the question doesn’t keep popping up forever, looking for an answer. Alternatively, you can post and accept your own answer.
是否有答案帮助到你?如果是,请接受答案,这样问题就不会一直弹出来寻找答案了。或者,你可以发布并接受自己的答案。
– Ron Maupin ♦
CommentedJan 3, 2021 at 1:18
padmaraj asked:
Why was ethernet MTU calculated as 1500 bytes?
为什么以太网的 MTU 被计算为 1500 字节?
What specific calculation was done to arrive at 1500 byte ethernet MTUs, and what factors were considered for that calculation?
为了得出 1500 字节的以太网 MTU,进行了哪些具体的计算,考虑了哪些因素?
Short story
简短故事
The answer to “Why is Ethernet MTU calculated as 1500 bytes?” is layered. A lot depends on the Ethernet protocols in question. Unfortunately we don’t always know in advance what Layer-2 protocol is wrapped by an Ethernet frame header.
“为什么以太网 MTU 被计算为 1500 字节?”的答案是多层次的。这在很大程度上取决于所涉及的以太网协议。遗憾的是,我们并不总是能提前知道以太网帧头所封装的第 2 层协议是什么。
Ethernet uses the two / four bytes after the source mac-address in different ways:
以太网以不同的方式使用源 MAC 地址之后的两个 / 四个字节:
-
802.1Q tagged frames use the FOUR bytes following the source mac-address as a vlan tag. 802.1Q is EtherType 0x8100
802.1Q 标记帧使用源 MAC 地址之后的四个字节作为 VLAN 标签。802.1Q 是 EtherType 0x8100 -
Untagged Ethernet II DIX frames use TWO bytes after the Ethernet source mac-address for a EtherType
未标记的以太网 II DIX 帧使用以太网源 MAC 地址之后的两个字节作为 EtherType -
802.3 frames (such as 802.2 ISIS / Spanning-Tree) use TWO bytes after the Ethernet source mac-address as a Length field.
802.3 帧(如 802.2 ISIS / 生成树)使用以太网源 MAC 地址之后的两个字节作为 Length 字段。
How do you know which Ethernet Layer-2 protocol we’re parsing off the wire? Usually, we know from the MAC-layer EtherType, but 802.3 with 802.2 LLC encap doesn’t have an EtherType.
如何知道我们正在解析的以太网第 2 层协议是什么?通常,我们从 MAC 层的 EtherType 中得知,但 802.3 与 802.2 LLC 封装没有 EtherType。
Thus, the payload of ISO 802.2 LLC frames (such as ISIS or Spanning-Tree) should not exceed 1500 bytes. Other Ethernet protocols (such as Ethernet II DIX) unofficially can exceed 1500 bytes as long as their Ethernet PHY-layer doesn’t depend on CSMA/CD.
因此,ISO 802.2 LLC 帧(如 ISIS 或生成树)的有效载荷不应超过 1500 字节。其他以太网协议(如以太网 II DIX)非正式地可以在其以太网 PHY 层不依赖于 CSMA/CD 的情况下超过 1500 字节。
Longer story
更长的故事
A lot depends on the Ethernet protocols in question. The most basic technique to read Ethernet headers is explained in draft-ietf-isis-ext-eth-01, specifically Section 3-5. Quoting from that RFC draft…
这在很大程度上取决于所涉及的以太网协议。阅读以太网头部的最基本技术在 draft-ietf-isis-ext-eth-01 中有解释,特别是 第 3-5 节。引用该 RFC 草案中的内容…
Problem with Large Length interpretation Frames in the presence of Type Interpretation Frames
在类型解释帧存在的情况下,大长度解释帧的问题
Some protocols commonly used in the Internet have no reserved EtherType. An example is the set of ISO Network layer protocols, of which ISIS is a member. Such protocols are only defined to use the IEEE 802.3/802.2 encoding, and so their packets are limited in length to 1500 bytes.
一些在互联网中常用的协议没有保留的 EtherType。一个例子是 ISO 网络层协议集,ISIS 是其中之一。这些协议仅定义为使用 IEEE 802.3/802.2 编码,因此其数据包的长度限制为 1500 字节。
Type Interpretation frames have no length field. Protocols encapsulated in Type interpretation frames, such as IP, are not limited in length to 1500 bytes by framing.
类型解释帧没有长度字段。封装在类型解释帧中的协议(如 IP)不受帧结构对 1500 字节长度的限制。
I’m including an annotated diagram below of Ethernet II DIX and 802.3 frames, these illustrate where the conflicting bytes are in the ethernet header:
我在下面附上了一个以太网 II DIX 和 802.3 帧的注释图,这些图说明了以太网头部中冲突字节的位置:
- RFC 894 Ethernet II (DIX) frames have an EtherType after the source mac-address
RFC 894 以太网 II(DIX)帧在源 MAC 地址之后有一个 EtherType
+----+----+-----------+------+-----+
| DA | SA | EtherType | Data | FCS |
+----+----+-----------+------+-----+
^^^^^^^^^^^^^
DA Destination MAC Address (6 bytes) // 目的 MAC 地址(6 字节)
SA Source MAC Address (6 bytes) // 源 MAC 地址(6 字节)
EtherType Protocol (2 bytes: >= 0x0600 or 1536 decimal) <--- // 协议(2 字节:>= 0x0600 或 1536 十进制)
Data Protocol Data (46 - 1500 bytes) // 协议数据(46 - 1500 字节)
FCS Frame Checksum (4 bytes) // 帧校验和(4 字节)
- IEEE 802.3 with ISO 802.2 LLC / SNAP (used by [Spanning-Tree], ISIS) use these same bytes for Length; 802.2 ISO ISIS doesn’t have an EtherType and Spanning-Tree doesn’t have an EtherType. Therefore 802.2 frame payloads MUST be smaller than 1500 bytes in order for the Length field to avoid conflict with reserved EtherType values.
IEEE 802.3 与 ISO 802.2 LLC / SNAP(用于 [生成树]、ISIS)使用这些相同的字节作为 Length;802.2 ISO ISIS 没有 EtherType,生成树也没有 EtherType。因此,为了使 Length 字段避免与保留的 EtherType 值冲突,802.2 帧的有效载荷必须小于 1500 字节。
+----+----+------+-------------------------+------------+
| DA | SA | Len | DSAP / SSAP / Ctl (DSC) | Data | FCS |
+----+----+------+-------------------------+------------+
^^^^^^^^
DA Destination MAC Address (6 bytes) 目的 MAC 地址(6 字节)
SA Source MAC Address (6 bytes) 源 MAC 地址(6 字节)
Len Length of Data field (2 bytes: <= 0x05DC or 1500 decimal) <--- 数据字段的长度(2 字节:<= 0x05DC 或 1500 十进制)
DSC 802.2 DSAP, SSAP, Ctl (3 bytes)
DSC 802.2 DSAP、SSAP、Ctl (3 字节)
Data Protocol Data (46 - 1500 bytes) 协议数据(46 - 1500 字节)
FCS Frame Checksum (4 bytes) 帧校验和(4 字节)
IEEE’s objections to official Jumbo frame support
IEEE 对官方支持巨型帧的反对意见
----------------------------------------------
General comments on the use of jumbo frames in Ethernet networks:
关于在以太网网络中使用巨型帧的总体评论:
Consideration #1: The expectation of no more than 15-1600 bytes between frames and an interpacket gap before the next frame is deeply ingrained throughout the design and implementation of standardized Ethernet/802.3 hardware. This shows up in buffer allocation schemes, clock skew and tolerance compensation and fifo
Consideration #1:期望不超过 15-1600 字节在帧之间以及下一个帧之前的帧间间隔深深植根于标准化以太网 / 802.3 硬件的设计和实现中。这体现在缓冲区分配方案、时钟偏差和容差补偿以及 FIFO 设计中。
Consideration #2: For some Ethernet/802.3 hardware (repeaters are one specific example) it is not possible to design compliant equipment which meets all of the requirements and will still pass extra long frames. Further, since clock frequency may vary with time and temperature, equipment may successfully pass long frames at times and corrupt them at other times. Therefore, attempts to verify the ability to send long frames over a path may produce inaccurate results.
Consideration #2:对于某些以太网 / 802.3 硬件(中继器是一个具体的例子),不可能设计出符合所有要求且仍能通过超长帧的合规设备。此外,由于时钟频率可能会随时间变化和温度变化,设备可能在某些时候能够成功通过长帧,而在其他时候可能会损坏长帧。因此,尝试验证路径上是否能够发送长帧可能会产生不准确的结果。
Consideration #3: The error checking mechanism embodied in the 4 byte checksum has not been well characterized at greater frame lengths, but is known to degrade. Therefore the data reliability of transfers in long frame transfers will have a greater rate of undetected frame errors.
Consideration #3:4 字节校验和中的错误检查机制在更长的帧长度下尚未得到很好的表征,但已知会退化。因此,在长帧传输中的数据可靠性将会有更高的未检测到帧错误的比率。
Consideration #4: The length of frames proposed by this draft can not be assured to pass through standards conformant hardware. The huge value of Ethernet/802.3 systems in the data networking universe is their standardization and the resulting assurance that systems will all interoperate. No such assurance can be provided for oversize frames with both the current broadly accepted standard and the large installed base ofstandards based equipment.
Consideration #4:本草案所提出的帧长度不能保证通过符合标准的硬件。以太网 / 802.3 系统在数据网络宇宙中的巨大价值在于其标准化以及由此带来的系统之间能够互操作的保证。对于超大帧,无法在当前广泛接受的标准和大量基于标准的设备安装基础上提供这种保证。
In summary with regard to greatly longer frames for Ethernet, much of the gear produced today would be intolerant of greatly longer frames. There is no way proposed to distinguish between frame types in the network as they arrive from the media. Bridges might and repeaters would drop or truncate frames (and cause errors doing so) right and left for uncharacterized reasons. It would be a mess. What might seem okay for small carefully characterized networks would be enormously difficult or impossible to do across the Standard.
总之,对于以太网的大幅加长帧,如今生产的许多设备将无法容忍大幅加长帧。没有提出一种方法可以在网络中区分从媒体到达的帧类型。桥接器可能会、中继器则会丢弃或截断帧(并且在不明原因的情况下造成错误)。这将是一团糟。对于小规模、经过仔细表征的网络来说可能看起来可以接受,但在整个标准范围内实施将极其困难甚至不可能。
----------------------------------------------
Summary
总结
The safest Ethernet MTU is 1500-byte payloads; IEEE refuses to endorse Ethernet payloads 1500 bytes. Depending on circumstances, we can CAUTIOUSLY increase Ethernet II payloads over the existing MTU of 1500-bytes.
最安全的以太网 MTU 是 1500 字节的有效载荷;IEEE 拒绝支持超过 1500 字节的以太网有效载荷。根据具体情况,我们可以谨慎地将以太网 II 的有效载荷增加到现有的 1500 字节 MTU 之上。
If you want to implement jumbo frames (MTU 1500), you should test your network to ensure you aren’t breaking things in subtle ways. Thoroughly read IEEE’s objections to jumbo frames (see above) before you test.
如果你想实现巨型帧(MTU 1500),你应该测试你的网络,以确保你没有以微妙的方式破坏东西。在测试之前,仔细阅读 IEEE 对巨型帧的反对意见(见上文)。
I will summarize with some simple guidance around jumbo frame support:
我将总结一些关于巨型帧支持的简单指导:
-
Ethernet 802.2 LLC ISIS / Spanning-Tree frames must NOT exceed a 1500-byte payload (to avoid EtherType / frame Length conflicts).
以太网 802.2 LLC ISIS / 生成树帧的有效载荷不得超过 1500 字节(以避免 EtherType / 帧长度冲突)。 -
Ethernet II DIX frame payloads CAN exceed 1500 bytes on full-duplex links
以太网 II DIX 帧的有效载荷可以在 全双工链路 上超过 1500 字节 -
Ethernet II DIX frame payloads must NOT exceed 1500 bytes on half-duplex links, which use CSMA/CD (and Ethernet CSMA/CD assumes the payload is <= 1500 bytes)
以太网 II DIX 帧的有效载荷在 半双工链路 上不得超过 1500 字节,这些链路使用 CSMA/CD(以太网 CSMA/CD 假设有效载荷 <= 1500 字节) -
802.1Q Frames cannot use 802.3 / 802.2 encapsulation, and 802.1Q frame payloads CAN exceed 1500 bytes on full-duplex links.
802.1Q 帧不能使用 802.3 / 802.2 封装,802.1Q 帧的有效载荷可以在 全双工链路 上超过 1500 字节。
As mentioned above, if you implement jumbo frames, test to ensure you aren’t breaking things.
如上所述,如果你实现巨型帧,请进行测试以确保你没有破坏内容。
FYI, I am including a link to pdf copies of the Ethernet Version 1 spec and Ethernet Version 2 spec, in case anyone is interested…
顺便说一下,我附上了 以太网版本 1 规范 和 以太网版本 2 规范 的 pdf 副本链接,以防有人感兴趣……
edited Nov 17, 2022 at 16:48
answered Aug 24, 2013 at 17:35
Mike Pennington
BTW, the values between maxValidFrame (1500) and “1536 decimal” are undefined in the Ethernet standard. The behavior of equipment at these values is not specified and can not be depended on
顺便说一下,在以太网标准中,maxValidFrame(1500)和“1536 十进制”之间的值是未定义的。设备在这些值下的行为没有规定,也不能依赖
– Mike Pennington
CommentedAug 24, 2013 at 17:44
3
Well, Ethernet II frames have their type field begin at 0x0600 (from the IEEE 802.3x-1997 spec) because the max max length of 802.3 was just below that. So that’s just an effect, not a cause.
以太网 II 帧的类型字段从 0x0600 开始(来自 IEEE 802.3x-1997 规范),因为 802.3 的最大长度就在该值之下。所以这只是一个结果,而不是原因。
– nos
CommentedAug 27, 2013 at 8:09
@nos, to claim that this is an effect instead of a cause presupposes that you can prove the cause… can you provide authoritative evidence for your proposed cause? The original Ethernet Version 1 spec published in 1980 already uses the Type field, and in 1984, the IP protocol was specified using Ethertype 0x0800
@nos,声称这是一个结果而不是原因,假设你可以证明原因……你能为你提出的原因提供权威证据吗?1980 年发布的原始以太网版本 1 规范已经使用了类型字段,1984 年,IP 协议被指定使用 Ethertype 0x0800
– Mike Pennington
CommentedAug 27, 2013 at 9:11
2
Indeed, the ethernet I and II spec already had a type field (which at that time had no restrictions), and already specified the max data length of 1500 - at that time there was no 802.3 frames. So one cannot conclude that the limit of 1500 was added in a later spec because of the type field.
确实,以太网 I 和 II 规范已经有一个类型字段(当时没有任何限制),并且已经指定了 1500 的最大数据长度——当时还没有 802.3 帧。因此,不能得出结论说 1500 的限制是在后来的规范中因为类型字段而增加的。
– nos
CommentedAug 27, 2013 at 10:45
2
@nos I disagree, Ethernet II had to coexist with the preexisting standard. And it also defined the use of the same field to act as both a type field in the prior standard and a length field in the new standard. Given that there MUST be NO possibility of confusion between the two standards, that must coexist in the same network, any length that could look like an existing type would not be allowed. As existing type list started at 0x600 a number less than that had to be chosen. To allow for no further expansion to the standard there had to be some band left available should it be needed.
@nos 我不同意,以太网 II 必须与现有的标准共存。它还定义了同一个字段既可以作为先前标准中的类型字段,也可以作为新标准中的长度字段。鉴于这两种标准必须共存于同一个网络中,且绝对不能混淆,任何可能看起来像现有类型的长度都不会被允许。由于现有的类型列表从 0x600 开始,必须选择一个小于该值的数字。为了允许标准不再进一步扩展,必须保留一些带宽以备不时之需。
– user3104
CommentedOct 31, 2013 at 0:12
17
At the other end of the range - 1500 bytes, there were two factors that lead to the introduction of this limit. First, if the packets are too long, they introduce extra delays to other traffic using the Ethernet cable. The other factor was a safety device built into the early shared cable transceivers. This safety device was an anti-babble system. If the device connected to a transceiver developed a fault and started transmitting continuously, then it would effectively block any other traffic from using that Ethernet cable segment. To protect from this happening, the early transceivers were designed to shut off automatically if the transmission exceeded about 1.25 milliseconds. This equates to a data content of just over 1500 bytes. However, as the transceiver used a simple analogue timer to shut off the transmission if babbling was detected, then the 1500 limit was selected as a safe approximation to the maximum data size that would not trigger the safety device.
在范围的另一端——1500 字节,有两个因素导致了这一限制的引入。首先,如果数据包太长,它们会给使用以太网电缆的其他流量带来额外的延迟。另一个因素是早期共享电缆收发器中内置的安全装置。这个安全装置是一个防“喋喋不休”系统。如果连接到收发器的设备出现故障并开始连续传输,那么它将有效地阻止其他流量使用该以太网电缆段。为了防止这种情况发生,早期的收发器被设计为如果传输时间超过大约 1.25 毫秒就会自动关闭。这相当于略多于 1500 字节的数据量。然而,由于收发器使用了一个简单的模拟计时器来检测到“喋喋不休”时关闭传输,因此 1500 字节的限制被选为一个安全的近似值,以确保不会触发安全装置。
Source: http://answers.yahoo.com/question/index?qid=20120729102755AAn89M1
edited Aug 26, 2013 at 20:03 Ricky
answered Aug 25, 2013 at 4:19 user1171
6
Hi @user1171: StackExchange preferred style is to include the answer material here, and link out as a reference. That way, when the link eventually rots, the answer is still useful.
嗨 @user1171:StackExchange 倡导的风格是将答案内容包含在此处,并将链接作为参考资料。这样,当链接最终失效时,答案仍然有用。
– Craig Constantine
CommentedAug 25, 2013 at 12:02
The jabber function required the MAU to shut down after 20 to 150 ms for 10 Mbit/s (IEEE 802.3 Clause 8.2.1.5), 40 to 75 kbit for Fast Ethernet (Clause 27.3.2.1.4) and twice that for Gigabit Ethernet, far exceeding the frame length. The Yahoo post is wrong.
“喋喋不休”功能要求 MAU 在 10 Mbit/s 下关闭时间为 20 到 150 毫秒(IEEE 802.3 第 8.2.1.5 条),快速以太网下为 40 到 75 千比特(第 27.3.2.1.4 条),千兆以太网下为 两倍时间,远远超过了帧长度。雅虎帖子是错误的。
– Zac67 ♦
CommentedJul 20, 2018 at 13:50
10
When Ethernet was originally developed as a shared medium or bus with 10Base5 and 10Base2, collisions of frames were frequent (what else you would expect in a connection where you fork the signal by drilling a tap into the cable) and expected as part of the design. Contrast this to today, when most everything is switched with separate collision domains and running full-duplex, where no one expects to see collisions.
当以太网最初被开发为一种共享介质或总线(使用 10Base5 和 10Base2)时,帧的碰撞是频繁的(在通过在电缆上打孔分叉信号的连接中,你还能期待什么呢),并且被设计为 预期中的行为。与今天相比,如今大多数设备都使用交换机,具有独立的冲突域,并且运行在全双工模式下,没有人期望看到冲突。
The mechanism to share the “ether” employed CSMA/CD (Carrier Sense Multiple Access/Collision Detection)
用于共享“以太”的机制采用了 CSMA/CD(载波监听多路访问/冲突检测)
Carrier Sense meant that a station wanting to transmit must listen to the wire – sense the carrier signal – to ensure no one else was talking since it was Multiple Access on that medium. Allowing 1500 bytes (though an arbitrary number as far as I can tell) was a compromise that meant a station could not capitalize the wire too long by talking too much at one time. The more bytes transmitted in a frame, the longer all other stations must wait until that transmission completes. In other words, shorter bursts or smaller MTU meant other stations got more opportunity to transmit and a fairer share. The slower the rate of the transmission medium (10Mb/s), stations would have longer delays to transmit as the MTU increases (if allowed to exceed 1500).
载波监听意味着想要传输的站点必须监听线路——感知载波信号——以确保没有其他站点在传输,因为这是在该介质上的多路访问。允许 1500 字节(尽管在我看来这是一个任意数字)是一个折衷方案,意味着一个站点不能通过一次传输过多数据而长时间占用线路。一个帧中传输的字节越多,其他所有站点就必须等待更长时间,直到该传输完成。换句话说,较短的突发传输或较小的 MTU 意味着其他站点有更多的机会进行传输,并且分配更加公平。传输介质的速率越慢(10Mb/s),随着 MTU 的增加(如果允许超过 1500),站点的传输延迟就会越长。
An interesting corollary question would be why the minimum frame size of 64 bytes? Frames were transmitted in “slots” that are 512 bits and took 51.2 microseconds for round-trip signal propagation in the medium. A station has to not only listen to when to start talking by sensing the IFG (interframe gap of 96 bits), but to listen for collisions with other frames. Collision Detection assumes maximum propagation delay and doubles that (to be safe) so it doesn’t miss a transmission starting about the same time from the other end of the wire or a signal reflection of its own transmission when someone forgot the terminating resistor at the ends of the cable. The station must not complete the sending of its data before sensing a collision, so waiting 512 bits or 64 bytes guarantees this.
一个有趣的相关问题是为什么最小帧大小是 64 字节?帧在“时隙”中传输,每个时隙为 512 位,介质中的往返信号传播时间为 51.2 微秒。一个站点不仅要通过感知 IFG(96 位的帧间间隔)来确定何时开始传输,还要监听与其他帧的冲突。冲突检测假设最大传播延迟,并将其加倍(为了安全),以免错过从线路另一端几乎同时开始的传输,或者当有人忘记在电缆末端安装终端电阻时,错过其自身传输的信号反射。站点必须在感知到冲突之前完成数据的发送,因此等待 512 位或 64 字节可以保证这一点。
edited Feb 19, 2020 at 21:23 Erkin Alp Güney
answered Aug 27, 2013 at 0:26 generalnetworkerror
Originally, max. payload was defined as 1500 bytes in 802.3. Ethernet v2 supports frame length of >=1536 and this is what IP implementations use. Most carrier-class vendors support around 9000 bytes (“jumbo frames”) these days. Since 1500 byte is the standard that all Ethernet implementations must support, this is what is normally set as default on all interfaces.
最初,802.3 中定义的最大有效载荷为 1500 字节。以太网 v2 支持 >=1536 的帧长度,这也是 IP 实现所使用的。如今,大多数运营商级供应商支持大约 9000 字节(“巨型帧”)。由于 1500 字节是所有以太网实现都必须支持的标准,因此这通常被设置为所有接口的默认值。
edited Aug 24, 2013 at 18:30
answered Aug 24, 2013 at 17:22
user661
You should google maxValidFrame, it was defined by IEEE; consequently, the 9KB jumbo frame implementations that are common today are not officially compliant with Ethernet, but they work quite well for Ethernet II payloads
你应该搜索一下 maxValidFrame,它是由 IEEE 定义的;因此,如今常见的 9KB 巨型帧实现并不是官方符合以太网标准的,但对于以太网 II 的有效载荷来说,它们运行得很好。
– Mike Pennington
CommentedAug 24, 2013 at 18:00
Strictly speaking, not 802.3-compliant. IP uses Ethernet v2 though, so I tend not to even think of 802.3…
严格来说,这并不符合 802.3 标准。不过 IP 使用的是以太网 v2,所以我甚至都不太考虑 802.3…
– user661
CommentedAug 24, 2013 at 18:19
5
Jumbos are not compliant with Ethernet II or 802.3 after 802.3x was ratified. 802.3x Clause 4.2.7.1 defines maxValidFrame at 1500B payloads. Thus after 1997, any payload exceeding 1500 bytes is not compliant. See the letter that the IEEE 802.3 chairman sent to IETF regarding this issue. In short, 802.3 is much more than a frame standard… it defines both framing and hardware requirements. This means the hardware implementations depend on compliance with the frame format. Half Duplex w/ CSMA-CD needs <= 1500B payloads.
巨型帧在 802.3x 获得批准后,并不符合以太网 II 或 802.3 标准。802.3x 第 4.2.7.1 条定义 maxValidFrame 为 1500B 的有效载荷。因此,自 1997 年以后,任何超过 1500 字节的有效载荷都不符合标准。请参阅 IEEE 802.3 主席就这一问题写给 IETF 的信。简而言之,802.3 不仅仅是一个帧标准……它定义了帧结构和硬件要求。这意味着硬件实现依赖于对帧格式的符合。半双工模式下的 CSMA-CD 需要 <= 1500B 的有效载荷。
– Mike Pennington
CommentedAug 24, 2013 at 18:42
OSPF Stuck in Exstart Adjacency State
According to this article two routers will get stuck in the exstart adjacency state when their configured MTU sizes do not match. Does a VLAN tag affect this as well even if the routers involved are unconcerned with which VLAN the packet is coming from or heading to?
根据这篇文章,如果两台路由器配置的最大传输单元(MTU)大小不匹配,它们将陷入 “预启动(Exstart)” 邻接状态。即使所涉及的路由器并不关心数据包来自哪个 VLAN 或发往哪个 VLAN,VLAN 标签是否也会对此产生影响呢?
I’ll try to clarify the question if it is unclear at all.
asked Jul 31, 2013 at 22:36
JDGray
Most Cisco routers and switches allow 1500 byte IP payloads by default, even when tagged with dot1q. You can verify this with show ip interface SomeIntfName…
大多数思科路由器和交换机默认允许 1500 字节的 IP 有效载荷,即使数据包带有 802.1Q(dot1q)标签。你可以使用 show ip interface SomeIntfName 命令来验证这一点……
Router1#sh ip int vlan105
Vlan105 is up, line protocol is up
Internet address is 10.15.2.19/30
Broadcast address is 255.255.255.255
Address determined by setup command
MTU is 1500 bytes <-------------
路由器 1#sh ip int vlan105
Vlan105 已启用,线路协议已启用
互联网地址是 10.15.2.19/30
广播地址是 255.255.255.255
地址由设置命令确定
MTU 是 1500 字节 <-------------
The reason dot1q on a Cisco interface works without bumping the physical interface MTU is because most Cisco routers support what Cisco calls “baby giants”… a baby giant has an Ethernet MTU above 1518 (which includes the eth header size), but not very much over 1518… usually the default values is 1522 bytes… see this MTU configuration doc for more information. Many Cisco platforms support configurable ethernet baby giant MTUs to 1532 bytes (or even higher), which is also why MPLS tag stacks (2 or 3 tags deep) can work through legacy ethernet links.
思科接口上的 802.1Q(dot1q)能够在不增加物理接口 MTU 的情况下工作,原因是大多数思科路由器支持思科所谓的 “小巨型帧(baby giants)”…… 小巨型帧的以太网 MTU 大于 1518 字节(这包括以太网报头大小),但不会比 1518 字节大很多…… 通常默认值是 1522 字节…… 有关更多信息,请参阅此 MTU 配置文档 。许多思科平台支持将以太网小巨型帧的 MTU 配置到 1532 字节(甚至更高),这也是多协议标签交换(MPLS)标签栈(2 层或 3 层标签)能够通过传统以太网链路工作的原因。
Even though Cisco ethernet interfaces support baby giants, they leave the default IP MTU at 1500 bytes. As long as the default IP MTU of 1500 is maintained, you’ll have no problems with the default settings of any other router with a 1500-byte IP MTU… quoting RFC 2328 Section 10.8:
尽管思科以太网接口支持小巨型帧,但它们将默认的 IP MTU 保留为 1500 字节。只要保持 1500 字节的默认 IP MTU,对于任何其他具有 1500 字节 IP MTU 的路由器的默认设置,你都不会遇到问题…… 引用 RFC 2328 第 10.8 节 的内容:
10.8. Sending Database Description Packets
This section describes how Database Description Packets are sent to a neighbor. The Database Description packet’s Interface MTU field is set to the size of the largest IP datagram that can be sent out the sending interface, without fragmentation.
10.8. 发送数据库描述包
本节描述如何向邻居发送数据库描述包。数据库描述包的接口 MTU 字段设置为可以从发送接口发出的最大 IP 数据报的大小,且不会发生分片。
edited Oct 7, 2021 at 6:47
answered Jul 31, 2013 at 22:52
Mike Pennington
What if I am using Cisco router and another router from a different vendor? The Cisco router’s interface is configured for a 1500 byte MTU, but it is actually transmitting an IP packet that is 1522 bytes the other router will still accept it as long as the interface is configured with a 1500 byte MTU? That would be because of what @Puglet mentioned below and OSPF assigns the Interface MTU part of the DB Description packet with the MTU size explicitly configured on the interface and not what the actual size of the packet is?
如果我使用的是思科路由器和来自其他厂商的路由器会怎样呢?思科路由器的接口配置的 MTU 为 1500 字节,但实际上它正在传输的 IP 数据包是 1522 字节,只要另一台路由器的接口配置的 MTU 为 1500 字节,它仍然会接受该数据包吗?这是不是因为 @Puglet 下面提到的内容,即开放最短路径优先(OSPF)协议会将数据库描述包中的接口 MTU 部分设置为接口上明确配置的 MTU 大小,而不是数据包的实际大小呢?
– JDGray
Commented Jul 31, 2013 at 23:18
Correct, Cisco IOS uses the IP MTU of the local interface… the IP MTU of your Cisco and the other vendor’s box must match. Sadly, I can’t speak for the behavior of other vendor equipment. Is there a way you can conduct a ping test (using the DF option) before you deploy?
正确,思科互联网操作系统(IOS)使用本地接口的 IP MTU…… 你的思科设备和其他厂商设备的 IP MTU 必须匹配。遗憾的是,我不能代表其他厂商设备的行为。在部署之前,你有没有办法进行一次 ping 测试(使用不分片选项,即 DF 选项)呢?
– Mike Pennington
Commented Jul 31, 2013 at 23:22
I’m not actually experiencing this issue. I saw a similar question on link in a discussion about good interview questions. I figured it would be discussion for this Stack Exchange.
实际上我并没有遇到这个问题。我在一个关于优秀面试问题的讨论链接中看到了一个类似的问题。我觉得这会是在这个技术问答网站(Stack Exchange)上值得讨论的话题。
– JDGray
Commented Jul 31, 2013 at 23:25
6
So the VLAN tag affects the amount you can transfer through the interface below the Ethernet header, but it doesn’t change the actual MTU.
所以,VLAN 标签会影响在以太网报头以下通过接口传输的数据量,但它不会改变实际的 MTU。
OSPF starts by sending out Hello packets on the broadcast medium (multicast 224.0.0.5) to find neighbours, then performs the DR and BDR election.
OSPF 协议首先在广播介质上(多播地址 224.0.0.5)发送 Hello 包以发现邻居,然后进行指定路由器(DR)和备份指定路由器(BDR)的选举。
After the election has completed, each hosts sends out a DB description packet. Within this packet there is a field [IP -> OSPF -> OSPF DB-Description -> Interface MTU] that OSPF sets to the outgoing interface’s MTU.
选举完成后,每个主机都会发送一个数据库描述包。在这个包中有一个字段 [IP -> OSPF -> OSPF DB-Description -> Interface MTU],OSPF 协议会将其设置为出站接口的 MTU。
If peers’ MTUs don’t match, they won’t move past the ExStart phase.
如果对等体的 MTU 不匹配,它们将无法进入到 “预启动(Exstart)” 阶段之后的状态。
I would take a packet capture (if possible) and drill down into this field to see what’s happening, or perform a debug ip ospf adj just to make sure this is the case…
如果可能的话,我会进行一次数据包捕获,并深入查看这个字段以了解发生了什么,或者执行 debug ip ospf adj 命令来确认是否是这种情况。
A show interface <int> | MTU will give you the MTU of an interface.
show interface <int> | MTU 命令将为你显示一个接口的 MTU。
edited Jul 31, 2013 at 23:07
answered Jul 31, 2013 at 22:58
Puglet
So, even if you are adding VLAN tags to a packet it won’t affect the size of the OSPF packets negotiating neighbor adjacency because it wouldn’t include a VLAN in the first place?
那么,即使你在数据包中添加 VLAN 标签,它也不会影响用于协商邻居邻接关系的 OSPF 数据包的大小,因为一开始它就不包含 VLAN 吗?
– JDGray
Commented Jul 31, 2013 at 23:21
It won’t affect the outgoing interface’s MTU, which is what OSPF places in its DBD packets.
它不会影响出站接口的 MTU,而这正是 OSPF 协议在其数据库描述(DBD)包中设置的内容。
– Puglet
Commented Aug 1, 2013 at 2:51
The IEEE 802.3ac standard increased the maximum Ethernet frame size from 1518 bytes to 1522 bytes to accommodate the four-byte VLAN tag. Some network devices that do not support the larger frame size will process the frame successfully but may report them as a “baby giant” anomalies.
IEEE 802.3ac 标准将最大以太网帧大小从 1518 字节增加到了 1522 字节,以容纳 4 字节的 VLAN 标签。一些不支持更大帧大小的网络设备将成功处理该帧,但可能会将其报告为 “小巨型帧” 异常。
So, if you device’s support “IEEE 802.3ac”, IP MTU will not change.
所以,如果你的设备支持 “IEEE 802.3ac” 标准,IP MTU 将不会改变。
answered Nov 25, 2013 at 22:17
Arguments about MTU
This is a list of arguments and counter arguments about raising the Internet MTU. The central position is that MTU should scale with data rate. See the main page on raising the Internet MTU.
这是一个关于提高互联网 MTU 的论点和反论点的列表。核心观点是 MTU 应该随着数据速率的增加而增加。请查看关于 提高互联网 MTU 的主页。
Moore’s Law and TCP
TCP worked really well on the 1988 Internet. After all, Van Jacobson tested his landmark TCP congestion control algorithms at this time. When the NSFnet backbone was T1 (1.5 Mbit/s) and the default Maximum Segment Size (MSS) was 512 bytes, typical packet transmission times were about 3 ms. With the lower data rate the coast-to-coast Round-Trip-Time was about 120ms, so it only took 40 packets in flight to “fill the pipe”.
TCP 在 1988 年的互联网上运行得非常好。毕竟,Van Jacobson 在这个时候测试了他的标志性 TCP 拥塞控制算法。当时 NSFnet 主干网是 T1(1.5 Mbit/s),默认的最大报文段长度(MSS)是 512 字节,典型的报文传输时间约为 3 毫秒。由于数据速率较低,横跨大陆的往返时间约为 120 毫秒,因此只需要 40 个在飞报文就可以“填满管道”。
Imagine a “jumbo TCP” that uses “blocks” (1 kByte) instead of “bytes” for its basic data unit (and links with an appropriate MTU). Then, a jumbo TCP packet using an MSS of 1000 Blocks (1 MByte) on 10 Gb/s Ethernet would have a packet time of 800 microseconds and would only take about 100 packets in flight to fill a coast-to-coast pipe.
想象一个使用“块”(1 kByte)而不是“字节”作为基本数据单元的“巨无霸 TCP”(并且有适当 MTU 的链路)。那么,在 10 Gb/s 以太网中,使用 1000 个块(1 MByte)作为 MSS 的巨无霸 TCP 报文的报文时间为 800 微秒,并且只需要大约 100 个在飞报文就可以填满横跨大陆的管道。
Jumbo TCP with 100 packets in flight would have roughly the same protocol behavior and dynamics as plain old TCP had in 1988 with 40 512 Byte packets in flight. Clearly much of the network overhead, CPU, I/O, and memory processing, is proportional to packet rate (or the number of packets in flight). However there are a couple of overhead terms that scale as the square of the pipe size in packets. In particular the gain (and noise immunity) of the TCP congestion control system go as the square of the window size in packets. On this path, these terms would be (1000 / 1.5)^2 or about 400,000 times more expensive with 1500 Byte packets than with 1 MB packets.
100 个在飞报文的巨无霸 TCP 将具有与 1988 年具有 40 个 512 字节报文的普通 TCP 大致相同的协议行为和动态。显然,网络开销、CPU、I/O 和内存处理中的大部分与报文速率(或在飞报文的数量)成正比。然而,有一些开销项是按报文管道大小的平方来增长的。特别是 TCP 拥塞控制系统的增益(和抗噪声能力)与报文窗口大小的平方成正比。在这个路径上,这些项的值将是 (1000 / 1.5)^2,大约是使用 1500 字节报文时的 400,000 倍,而使用 1 MB 报文时则不是。
Put another way: With constant size packets each order of magnitude rise in link rate lowers TCP’s tolerance to other problems in the network by two orders of magnitude. If industry had scaled up packet sizes rather than scaling down packet times, the network throughput of individual data flows would be very different today.
换句话说:如果链路速率增加一个数量级,而报文大小保持不变,TCP 对网络中其他问题的容忍度会降低两个数量级。如果行业当初选择增加报文大小,而不是减少报文时间,那么今天单个数据流的网络吞吐量将会大不相同。
While larger MTU sizes do exist within the Internet, they have not been widely deployed and used since the MTU path discovery algorithm [RFC1191, RFC1981] is not effective.
尽管互联网中确实存在更大的 MTU 尺寸,但由于 MTU 路径发现算法 [RFC1191, RFC1981] 并不有效,因此它们尚未得到广泛部署和使用。
Path MTU discovery doesn’t work
Unfortunately, this is correct. We are just going have to fix it.
不幸的是,这是事实。我们只能去修复它。
The problems with path MTU discovery are documented in RFC2923. It is fragile because it depends on ICMP “Can’t Fragment” messages from the network. When there is an “ICMP black hole” the messages don’t get delivered, causing path MTU discovery to fail and the TCP connection to hang.
路径 MTU 发现的问题在 RFC2923 中有记录。它很脆弱,因为它依赖于网络中的 ICMP“无法分片”消息。当出现“ICMP 黑洞”时,消息无法送达,导致路径 MTU 发现失败,TCP 连接也会挂起。
Since path MTU discovery is fragile, vendors ship computer systems with it turned off. They instead pick a safe MTU for a system wide default, typically 1500 bytes.
由于路径 MTU 发现很脆弱,厂商在发货时会将其关闭。他们会为系统选择一个安全的 MTU 作为默认值,通常是 1500 字节。
Since computer systems are shipped not to use path MTU discovery, almost nobody notices the paths on the Internet that do support larger MTUs.
由于计算机系统在发货时不使用路径 MTU 发现,几乎没有人注意到互联网上那些确实支持更大 MTU 的路径。
The first step to mitigating this large and legitimate market disincentive to deploying larger MTUs is to fix path MTU discovery.
缓解这种对部署更大 MTU 的巨大且合理的市场阻碍的第一步是修复路径 MTU 发现。
Check out the new path MSS discovery rough draft Internet-Draft.
查看新的路径 MSS 发现初步草案。
The Ethernet CRC limits packets to about 12 kBytes. (NOT)
It has been reported in several places, such as Phil Dykstra’s page on Jumbo frames that the CRC-32 used by Ethernet is limited to about 12 kBytes.
在多个地方都有报道,例如 Phil Dykstra 的巨帧页面,以太网使用的 CRC-32 限制了大约 12 kBytes 的报文。
This statement is based on an engineering requirement that the maximum allowed probability that the CRC fails to detect a corrupted packet is below some threshold. (I would greatly appreciate it if somebody can provide a specific reference on this calculation.)
这一说法是基于一个工程要求,即 CRC 未能检测到损坏报文的最大允许概率低于某个阈值。(如果有人能提供关于这个计算的具体参考文献,我将不胜感激。)
I believe the logic behind the calculation is flawed in the following sense: If you have a large quantity of data to move (say a Peta Byte, 1 × 1 0 15 1 \times 10^{15} 1×1015 Bytes) then the total undetected error rate is independent of the packet size across a huge range of sizes. This is because changes in per-packet exposure to undetected errors are exactly offset by the change in the number of packets.
我认为这个计算背后的逻辑存在以下缺陷:如果你要传输大量的数据(比如 1 PB, 1 × 1 0 15 1 \times 10^{15} 1×1015 字节),那么在很大的报文尺寸范围内,总的未检测到的错误率与报文大小无关。这是因为每个报文暴露于未检测到的错误的变化,正好被报文数量的变化所抵消。
For example if I send 1 × 1 0 15 1 \times 10^{15} 1×1015 bytes over a link that has a raw bit error rate of 1 × 1 0 − 12 1 \times 10^{-12} 1×10−12 then I compute:
例如,如果我在一个原始比特错误率为 1 × 1 0 − 12 1 \times 10^{-12} 1×10−12 的链路上发送 1 × 1 0 15 1 \times 10^{15} 1×1015 字节,那么我计算如下:
| Using 1000 byte packets | 使用 1000 字节报文 |
|---|---|
| Raw bit error rate: 1.0 × 1 0 − 12 1.0 \times 10^{-12} 1.0×10−12 | 原始比特错误率: 1.0 × 1 0 − 12 1.0 \times 10^{-12} 1.0×10−12 |
| Per packet error rate: 8.0 × 1 0 − 9 8.0 \times 10^{-9} 8.0×10−9 | 每个报文的错误率: 8.0 × 1 0 − 9 8.0 \times 10^{-9} 8.0×10−9 |
| Undetected packet errors: 2.0 × 1 0 − 18 2.0 \times 10^{-18} 2.0×10−18 | 未检测到的报文错误: 2.0 × 1 0 − 18 2.0 \times 10^{-18} 2.0×10−18 |
| Packets per data set: 1.0 × 1 0 12 1.0 \times 10^{12} 1.0×1012 | 每个数据集的报文数量: 1.0 × 1 0 12 1.0 \times 10^{12} 1.0×1012 |
| Total undetected errors per data set: 2.0 × 1 0 − 6 2.0 \times 10^{-6} 2.0×10−6 | 每个数据集的总未检测到的错误: 2.0 × 1 0 − 6 2.0 \times 10^{-6} 2.0×10−6 |
| Using 10000000 byte packets | 使用 10000000 字节报文 |
|---|---|
| Raw bit error rate: 1.0 × 1 0 − 12 1.0 \times 10^{-12} 1.0×10−12 | 原始比特错误率: 1.0 × 1 0 − 12 1.0 \times 10^{-12} 1.0×10−12 |
| Per packet error rate: 8.0 × 1 0 − 5 8.0 \times 10^{-5} 8.0×10−5 | 每个报文的错误率: 8.0 × 1 0 − 5 8.0 \times 10^{-5} 8.0×10−5 |
| Undetected packet errors: 2.0 × 1 0 − 14 2.0 \times 10^{-14} 2.0×10−14 | 未检测到的报文错误: 2.0 × 1 0 − 14 2.0 \times 10^{-14} 2.0×10−14 |
| Packets per data set: 1.0 × 1 0 8 1.0 \times 10^{8} 1.0×108 | 每个数据集的报文数量: 1.0 × 1 0 8 1.0 \times 10^{8} 1.0×108 |
| Total undetected errors per data set: 2.0 × 1 0 − 6 2.0 \times 10^{-6} 2.0×10−6 | 每个数据集的总未检测到的错误: 2.0 × 1 0 − 6 2.0 \times 10^{-6} 2.0×10−6 |
(If you object to my numbers, please send better ones).
(如果你对我的数字有异议,请提供更好的数字)。
The undetected packet error rate was calculated using the following assumptions:
未检测到的报文错误率是基于以下假设计算的:
-
The “raw strength” of the CRC is 1 part in 2 32 2^{32} 232. I.e. a single arbitrary burst error will yield a “random” CRC, which will be a false pass once per 4 × 1 0 9 4 \times 10^{9} 4×109 packets. Actual CRCs are stronger than this because all errors patterns in some of the more common cases (e.g. single bit errors) can be proven to never cause a false pass.
CRC 的“原始强度”是 2 32 2^{32} 232 分之一。也就是说,一个任意的突发错误会产生一个“随机”的 CRC,每 4 × 1 0 9 4 \times 10^{9} 4×109 个报文会出现一次误判。实际上,CRC 比这更强,因为在一些更常见的情况下(例如单比特错误),所有错误模式都可以证明不会导致误判。
-
The ability of the CRC to detect a given burst error is not affected by the amount of correct data in the same packet.
CRC 检测特定突发错误的能力不受同一报文中正确数据量的影响。
-
The probability of there being 2 burst errors in the same packet is low. If this is not the case, you introduce second order terms on both sides of the calculation.
同一报文中出现 2 个突发错误的概率很低。如果不是这样,你将在计算的两边引入二阶项。
I am in complete agreement that CRC-32 is not strong enough for large data sets. It probably does need to be improved.
我完全同意 CRC-32 对于大型数据集来说不够强大。它可能确实需要改进。
The CRC issue does not provide an argument for limiting MTU, only that current Ethernet may not be suitable for large data sets.
CRC 问题并不是限制 MTU 的理由,只是表明当前的以太网可能不适合大型数据集。
Larger packets will cause too much jitter
The packet times shown on the MTU main page are monotonically decreasing as the date rates get higher, so newer networks will never break existing applications. If a mission oriented network needs substantially smaller jitter there is always the option of artificially limiting the MTU on selected subnets, and relying path MTU discovery to inform the bulk transport users.
在 MTU 主页 上显示的报文时间随着数据速率的提高而单调下降,因此新的网络永远不会破坏现有的应用程序。如果一个面向任务的网络需要显著更小的抖动,那么总是可以选择在选定的子网上人为地限制 MTU,并依靠路径 MTU 发现来通知大量传输用户。
Not enough people want larger MTU to justify the expense
We predict that raising the MTU will effectively be a larger performance gain for the end user than it was to replace 10 Mb/s Ethernet with 100 Mb/s Ethernet. If true, once the users are educated, there will be the opportunity to re-sell the entire current installed base of 100 Mb/s gear with big packet gear at either 100 Mb/s or 1 Gb/s.
我们预测,提高 MTU 将有效地为最终用户带来比将 10 Mb/s 以太网替换为 100 Mb/s 以太网更大的性能提升。如果这是真的,一旦用户得到教育,就有机会将现有的 100 Mb/s 设备全部重新销售为 100 Mb/s 或 1 Gb/s 的大报文设备。
Today, there are several different bottlenecks that limit performance of wide area connections to less than 10 Mb/s - the hypothetical bandwidth available more than a decade ago. The primary bottleneck today is actually end-system TCP buffer tuning, which is being addressed by the web100 project. However the primary deliverable for the project is an extended performance MIB for TCP, which has enabled us to examine other bottlenecks in the system.
如今,有多个不同的瓶颈限制了广域连接的性能,使其低于十年前假设可用的 10 Mb/s 带宽。如今的主要瓶颈实际上是终端系统的 TCP 缓冲区调整,这正在通过 web100 项目来解决。然而,该项目的主要成果是一个 TCP 扩展性能 MIB,它使我们能够检查系统中的其他瓶颈。
From this information we have come to believe that for the vast majority of university users, raising the MTU would be more valuable than migration to faster Ethernets using 1500 Byte packets. In particular, raising the MTU (together with fixing pMTU discovery and TCP tuning) would mean that most users would get their full fair share of the bottleneck line rate (i.e. fill some link in the network).
从这些信息中,我们相信对于大多数大学用户来说,提高 MTU 将比迁移到使用 1500 字节报文的更快的以太网更有价值。特别是,提高 MTU(同时修复 pMTU 发现和 TCP 调整)将意味着大多数用户将获得瓶颈链路速率的全部公平份额(即填满网络中的某个链路)。
On the other hand, since the vast majority of todays end systems can only use a small fraction of the available NIC data rate, raising the NIC date rate does little to help actual performance, and therefore there is no general demand for host interfaces faster than 100 Mb/s.
另一方面,由于当今大多数终端系统只能使用可用 NIC 数据速率的一小部分,提高 NIC 数据速率对实际性能帮助不大,因此没有普遍需求要求主机接口速度超过 100 Mb/s。
Therefore, we believe that a deployed R&E core that supports big packets, plus deployed fixes to path MTU discovery and end-system TCP tuning (or user educations about manual workarounds) has the potential to cause wide spread demand for larger packets, perhaps on faster NICs, everywhere.
因此,我们相信,部署一个支持大报文的 R&E 核心,加上部署对路径 MTU 发现和终端系统 TCP 调整的修复(或对用户进行手动解决方法的教育),有可能引发对更大报文的广泛需求,也许在更快的 NIC 上,无处不在。
A Letter from IEEE 302.3
The letter below is the IEEE response to draft-kaplan-isis-ext-eth-02.txt. That draft evolved to draft-ietf-isis-ext-eth-01.txt, which includes the letter below as appendix 1 with a rebuttal by the draft’s authors as appendix 2. Note that these documents were “Works in progress” and have already expired - They have no current standing in the IETF.
下面的信件是 IEEE 对 draft-kaplan-isis-ext-eth-02.txt 的回复。该草案演变为 draft-ietf-isis-ext-eth-01.txt,其中将下面的信件作为附录 1,草案作者的反驳作为附录 2。请注意,这些文件是“进行中的工作”,并且已经过期 - 它们在 IETF 中没有现行地位。
From: Geoff Thompson, Chair, IEEE 802.3
To: Scott O. Bradner, IETF
Re: 802.3 Position on Extended Ethernet Frame Size SupportScott-
This is in response to your query for a position regarding the publication of Extended Ethernet Frame Size Support - draft-kaplan-isis-ext-eth-02.txt - as an informational RFC. This response was approved in concept and draft by 802.3 during its closing plenary at Hilton Head on March 15. The final form was drafted by myself and reviewed by an ad hoc that was formed during our closing plenary. It should be considered the position of the 802.3 Working Group.
收件人:Geoff Thompson,IEEE 802.3 主席
发件人:Scott O. Bradner,IETF
主题:关于扩展以太网帧大小支持的 802.3 立场Scott -
这是对您关于发布扩展以太网帧大小支持 - draft-kaplan-isis-ext-eth-02.txt - 作为信息性 RFC 的立场查询的回复。该回复在 3 月 15 日于希尔顿黑德举行的最后一次全体会议上,以概念和草稿形式获得了 802.3 的批准。最终形式由我起草,并由我们在最后一次全体会议上成立的临时小组审阅。它应被视为 802.3 工作组的立场。
The response is composed of two parts, specific comments on the draft and general comments on the use of jumbo frames in Ethernet networks. However, virtually all traffic uses the type/length field as a type field. It seems unlikely that the implementations using the length format would take advantage of longer packets. Therefore, the draft conveys a very limited value.
回复分为两部分,对草案的具体评论以及对以太网网络中巨帧使用的总体评论。然而,几乎所有流量都将类型/长度字段用作类型字段。似乎不太可能使用长度格式的实现会利用更长的报文。因此,该草案传达的价值非常有限。
Specific comments on: Extended Ethernet Frame Size Support - draft-kaplan-isis-ext-eth-02.txt
对《扩展以太网帧大小支持 - draft-kaplan-isis-ext-eth-02.txt》的具体评论:
The draft makes no mention that extended frames are not likely to be successfully handled by Ethernet equipment unless the network is composed entirely of equipment that is specifically designed, beyond the specifications of the Ethernet Standard, to relay extended size frames.
草案中没有提到,除非网络完全由超出以太网标准规范专门设计以转发扩展大小帧的设备组成,否则扩展帧不太可能被以太网设备成功处理。
In section 2, Abstract, the document asserts that it presents an extension to the “current Ethernet Frame Standards to support payloads greater than 1500 bytes…” Neither the original Ethernet specification (it was not a “Standard”) nor IEEE Std. 802.3 is a “frame standard”. They are, rather, complete specifications for hardware and frame format with the expectation that parameters from one portion of the standard can be taken as a given in other portions of the Standard. Moreover, this draft is not an “extension” to those documents but rather a proposal to violate specific provisions of those documents.
在第 2 节“摘要”中,文档声称它提出了对“当前以太网帧标准”的扩展,以支持超过 1500 字节的有效载荷……无论是原始的以太网规范(它并不是一个“标准”),还是 IEEE Std. 802.3 都不是“帧标准”。它们是硬件和帧格式的完整规范,期望标准的一个部分的参数可以在标准的其他部分被当作已知条件。此外,本草案并不是对这些文件的“扩展”,而是一个提议,违反这些文件的特定条款。
In section 3, the draft refers to “Ethernet II [ETH]” and points to the reference [ETH]. The reference, as cited, is incorrect or incomplete.
在第 3 节中,草案提到了 “Ethernet II [ETH]”,并引用了参考文献 [ETH]。所引用的参考文献是错误的或不完整的。
Ethernet II would seem to point to Ethernet Version 2.0. That would specifically not be “version 1.0…September 1980”. The citation in fact points to 2 different documents and fails to note that the November 1982 edition is in fact Version 2.0. Further, both of these are obsolete references and have been superseded by IEEE Std. 802.3 and ISO/IEC 8802-3. The current version of these Standards is IEEE Std. 802.3 [2000 Edition] and ISO/IEC 8802-3 : 2000.
Ethernet II 似乎指的是以太网 2.0 版本。这肯定不是 “1.0 版本……1980 年 9 月”。实际上,该引用指向了两份不同的文件,却没有指出 1982 年 11 月版实际上是 2.0 版本。此外,这两个引用都已过时,已被 IEEE Std. 802.3 和 ISO/IEC 8802-3 替代。这些标准的现行版本是 IEEE Std. 802.3 [2000 版本] 和 ISO/IEC 8802-3 : 2000。
The details of section 4 are badly out of date. IEEE Std. 802.3 has included both Type and Length encoded packets ever since the adoption of IEEE Std. 802.3x on March 20, 1997. The current text of the 802.3 text covering this reads:
第 4 节的细节严重过时。自 1997 年 3 月 20 日采用 IEEE Std. 802.3x 以来,IEEE Std. 802.3 一直包含类型和长度编码的报文。覆盖这一内容的 802.3 文本的当前内容如下:
3.2.6 Length/Type Field
3.2.6 长度/类型字段
This two-octet field takes one of two meanings, depending on its numeric value. For numerical evaluation, the first octet is the most significant octet of this field.
这个两字节字段有两种含义,取决于它的数值。对于数值评估,该字段的第一个字节是最高有效字节。
a) If the value of this field is less than or equal to the value of maxValidFrame (as specified in 4.2.7.1), then the Length/Type field indicates the number of MAC client data octets contained in the subsequent data field of the frame (Length interpretation).
a) 如果该字段的值小于或等于 maxValidFrame 的值(如 4.2.7.1 中所指定),则长度/类型字段表示帧的后续数据字段中包含的 MAC 客户端数据字节数(长度解释)。
b) If the value of this field is greater than or equal to 1536 decimal (equal to 0600 hexadecimal), then the Length/Type field indicates the nature of the MAC client protocol (Type interpretation). The Length and Type interpretations of this field are mutually exclusive.
b) 如果该字段的值大于或等于 1536 十进制(等于 0600 十六进制),则长度/类型字段表示 MAC 客户端协议的性质(类型解释)。该字段的长度和类型解释是互斥的。
Please note that any value over “the value of maxValidFrame” is NOT a valid value for encoding length. Additionally, the values between maxValidFrame and “1536 decimal” are undefined in the Ethernet standard. The behavior of equipment at these values is not specified and cannot be depended on. The draft implies that these values are valid type fields. This is not true. These values are not valid for either Type or Length.
请注意,任何超过 “maxValidFrame 的值” 的值都不是编码长度的有效值。此外,在 maxValidFrame 和 “1536 十进制” 之间的值在以太网标准中是未定义的。设备在这些值下的行为没有规定,不能依赖。草案暗示这些值是有效的类型字段。这不是真的。这些值对于类型或长度都不是有效的。
Section 4 Re: “…are not limited in length to 1500 bytes by framing.” While this seems to be true, it is not necessarily true for a number of sometimes subtle reasons, some of which are noted in the “General” section below.
第 4 节关于 “……报文长度不受 1500 字节的限制” 的问题。虽然这看起来是真的,但由于一些有时很微妙的原因,这并不一定总是成立,其中一些原因在下面的 “总体” 部分中有所提及。
Section 5: Regarding the statement “Although the 802.3 length field is missing, the frame length is known by virtue of the frame being accepted by the network interface.” This statement is not correct. Many Ethernet interfaces, particularly those of relay equipment, accept frames without regard for packet type or content. There is no reasonable expectation that standards-based Ethernet/802.3 equipment will reject the proposed frames. They may very well accept the frame and corrupt it before passing it on. This corruption may consist of truncation or alteration of the data within the packet.
第 5 节:关于 “尽管缺少 802.3 长度字段,但由于网络接口接受了该帧,因此已知帧的长度” 这一说法。这一说法是不正确的。许多以太网接口,特别是中继设备的接口,接受报文而不考虑报文类型或内容。没有合理的理由期望基于标准的以太网 / 802.3 设备会拒绝所提出的帧。它们很可能接受该帧并在传递之前将其损坏。这种损坏可能包括截断或更改报文内的数据。
General comments on the use of jumbo frames in Ethernet networks:
关于在以太网网络中使用巨帧的总体评论:
Consideration #1: The expectation of no more than 15-1600 bytes between frames and an interpacket gap before the next frame is deeply ingrained throughout the design and implementation of standardized Ethernet/802.3 hardware. This shows up in buffer allocation schemes, clock skew and tolerance compensation and FIFO design.
考虑因素 #1:在标准化的以太网 / 802.3 硬件的设计和实现中,帧之间不超过 15-1600 字节以及下一个帧之前的帧间间隔的期望已经根深蒂固。这体现在缓冲区分配方案、时钟偏斜和容差补偿以及 FIFO 设计中。
Consideration #2: For some Ethernet/802.3 hardware (repeaters are one specific example) it is not possible to design compliant equipment which meets all of the requirements and will still pass extra long frames. Further, since clock frequency may vary with time and temperature, equipment may successfully pass long frames at times and corrupt them at other times. Therefore, attempts to verify the ability to send long frames over a path may produce inaccurate results.
考虑因素 #2:对于某些以太网 / 802.3 硬件(中继器是一个具体例子),不可能设计出符合所有要求并且仍然可以传递超长帧的合规设备。此外,由于时钟频率可能随时间和温度变化,设备有时可以成功传递长帧,而在其他时候可能会损坏它们。因此,尝试验证路径发送长帧的能力可能会产生不准确的结果。
Consideration #3: The error checking mechanism embodied in the 4-byte checksum has not been well characterized at greater frame lengths, but is known to degrade. Therefore the data reliability of transfers in long frame transfers will have a greater rate of undetected frame errors.
考虑因素 #3:4 字节校验和所体现的错误检查机制在更长的帧长度下尚未得到很好的描述,但已知其会退化。因此,在长帧传输中的数据可靠性将会有更高的未检测到的帧错误率。
Consideration #4: The length of frames proposed by this draft cannot be assured to pass through standards-conformant hardware. The huge value of Ethernet/802.3 systems in the data networking universe is their standardization and the resulting assurance that systems will all interoperate. No such assurance can be provided for oversize frames with both the current broadly accepted standard and the large installed base of standards-based equipment.
考虑因素 #4:本草案所提出的帧长度不能保证通过符合标准的硬件。以太网 / 802.3 系统在数据网络世界中的巨大价值在于其标准化以及由此带来的系统之间能够互操作的保证。对于超大尺寸的帧,无论是当前广泛接受的标准,还是大量的基于标准的设备安装基础,都无法提供这样的保证。
In summary with regard to greatly longer frames for Ethernet, much of the gear produced today would be intolerant of greatly longer frames. There is no way proposed to distinguish between frame types in the network as they arrive from the media. Bridges might and repeaters would drop or truncate frames (and cause errors doing so) right and left for uncharacterized reasons. It would be a mess. What might seem okay for small carefully characterized networks would be enormously difficult or impossible to do across the Standard.
总之,对于以太网的大幅增长的帧长度,当今生产的许多设备都无法容忍大幅增长的帧长度。没有提出任何方法来在网络中区分从介质到达的帧类型。桥接器可能会,中继器会丢弃或截断帧(并因此产生错误),原因不明。这将是一团糟。对于小的、经过精心描述的网络来说,看似可行的事情,在整个标准范围内实施将会极其困难,甚至不可能。
The choice of frame size for Ethernet packets is really the domain of 802.3 (CSMA/CD) and 802.1 (Bridging, VLANs). The only time the frame size has been modified over the history of the Standard was in order to increase maximum length by four bytes in order to accommodate VLANs, 802.1 initiated this work and 802.3 also modified the Ethernet standard to include these few extra bytes. The people with the experience dealing with this sort of thing attend IEEE 802. It’s easy to define a new ethertype, but it’s not too easy to figure out what happens when these non-standard frames are given to standardized transmission equipment e.g. bridges. We would expect discussions of this type to take place in both 802.3 & 802.1.
以太网报文的帧大小选择实际上是 802.3(CSMA/CD)和 802.1(桥接,VLAN)的领域。在标准的历史上,帧大小唯一一次被修改是为了增加最大长度,以容纳 VLAN 的四个字节,802.1 发起了这项工作,802.3 也修改了以太网标准以包含这些额外的几个字节。处理这类事情的经验丰富的人都在 IEEE 802。定义一个新的以太网类型很容易,但当这些非标准帧被交给标准化的传输设备(例如桥接器)时,很难弄清楚会发生什么。我们期望这类讨论在 802.3 和 802.1 中都会进行。
The giant frame issue has been mentioned several times over the years in 802.3, discussed in the back halls and considered each time we move to a higher speed. It has never had consensus support in that context. It has never been brought forward as a separate proposal. Backward compatibility has always been more important than ease of performance improvement. The problem is that the change is very easy to do in the standard and hard to do in the world. It is just like changing the gauge on railroad tracks. All you have to do is change one line in the standard, never mind all of the rails you have to move.
这些年来,巨帧问题在 802.3 中被多次提及,在幕后进行了讨论,并且每次我们转向更高的速度时都会被考虑。它从未在那种情况下获得共识支持。它从未被作为一个单独的提案提出来。向后兼容性一直比性能改进的便利性更重要。问题是,这种改变在标准中很容易实现,但在现实世界中却很难做到。这就像是改变铁路轨道的轨距一样。你只需要在标准中改变一行,别管你得移动多少根铁轨。
The Kaplan draft is just meant for carrying IS-IS routing protocol frames (the IS-IS working group is the intended sponsor of this draft). We expect those vendors supporting the larger frame will support this will show up and support this proposal. Those vendors not supporting the larger frame as well as those protecting the installed base will not support this activity nor having this sort of item standardized outside IEEE 802.3. [emphasis added - MM]
Kaplan 草案只是为了携带 IS-IS 路由协议帧(IS-IS 工作组是该草案的预期赞助者)。我们预计支持较大帧的供应商将会出现并支持这一提议。不支持较大帧的供应商以及保护现有安装基础的供应商将不会支持这一活动,也不会支持在 IEEE 802.3 之外对这类项目进行标准化。 [强调部分 - MM]
With best regards,
Geoff Thompson, Chair, IEEE 802.3
敬上,
Geoff Thompson,IEEE 802.3 主席
Raising the Internet MTU
The “Internet Cell size” is effectively 1500 bytes - the Maximum Transmission Unit (MTU) for Ethernet. This is orders of magnitude smaller than the optimal MTU for many high performance applications running over todays high speed Internet. Note that although traditional “jumbograms” (9 kB) are a huge improvement, they are not really large enough for networks that are faster than 1 Gb/s.
我们不是提议标准化任何特定的大 MTU。我们提议互联网需要支持多样化的 MTU(路径 MTU 发现必须完全健壮),以便不同的社区可以在互联网的不同部分使用不同的 MTU。支持数据密集型用户的骨干网(例如 NLR、ETF/DTF、Internet2、DoE、NASA 等)及其连接的校园很可能会倾向于使用更大的 MTU。其他社区,例如为数百万低速率客户提供服务的 ISP,可能会发现 1500 字节已经足够。
This material is divided into four main areas:
本材料分为四个主要部分:
Just remember: The glass is neither half full nor half empty, it is merely the wrong size.
General Resources and Background:
- Phil Dykstra’s white paper on “Gigabit Ethernet Jumbo Frames” presents a good introduction to MTU and related issues.
- The marketing paper “Maximum Transmission Unit: Hidden Restrictions on High Bandwidth Networks” also presents a good introduction, but with a slightly different spin.
- My presentation “Pushing up the Internet MTU” from the March 2003 Joint - Techs meeting is a good introduction to our rationale, goals and plans.
- Join the MTU mailing list (mailman).
- We have preliminary measurement data, showing how MTU affects performance for TCP over one particular path. Bill Rutherford, et al, has shown that 64 kB MTU substantially out performs 16 kB and smaller MTUs [RJSVL07]. As you might expect, performance is roughly proportional MTU in many operating regimes.
- This bibliography covers MTU related documents and publications.
- This page ( http://www.psc.edu/~mathis/MTU/index.html ) will be used as a clearinghouse for information and resources about Internet MTU issues. If you have comments, ideas or suggestions, please send them to me at mathis@psc.edu, or join the mailing list above and contribute directly.
Deploying Robust Path MTU Discovery (RFC 4821):
Traditional path MTU discovery, as specified in RFC 1191 and RFC 1981, is fragile when ICMP Packet - To - Big or Can’t Fragment messages are not reliably generated or delivered. So called “ICMP black holes” can cause very hard - to - diagnose connection and application hangs or other problems as documented in RFC 2401 and RFC 4458, etc. These problems arise whether the differing MTUs are due to jumbogram support or tunnels with MTU’s slightly smaller than the native infrastructure (e.g. PPPOE, VPNs, IPsec, etc.)
传统的路径 MTU 发现机制,如 RFC 1191 和 RFC 1981 中所规定的,当 ICMP 数据包过大或无法分片消息不能可靠生成或传输时,会变得很脆弱。所谓的“ICMP 黑洞”可能会导致难以诊断的连接和应用程序挂起或其他问题,这些问题在 RFC 2401 和 RFC 4458 等文档中有所记录。这些问题无论是因为支持巨帧还是因为隧道的 MTU 略小于本地基础设施(例如 PPPOE、VPN、IPsec 等)而产生的不同 MTU 都会出现。
RFC 4821 describes a robust new method for Packetization Layer Path MTU Discovery (PLPMTUD) where TCP or some other protocol can determine that the path MTU without relying on ICMP or other messages from the network. In this algorithm, the packetization layer, which is the protocol responsible for choosing packet boundaries (e.g., segment sizes) probes the path by using progressively larger packets. If a probe packet is successfully delivered, then the effective Path MTU is raised to the probe size. The isolated loss of a probe packet (with or without an ICMP message) is treated as an indication of an MTU limit, and not as a congestion indicator. In this case alone, the Packetization Protocol is permitted to retransmit one segment of missing data without adjusting the congestion window. Read the RFC itself for a full description of the algorithm.
RFC 4821 描述了一种新的健壮的分组层路径 MTU 发现(PLPMTUD)方法,TCP 或其他协议可以在不依赖网络中的 ICMP 或其他消息的情况下确定路径 MTU。在这种算法中,分组层(负责选择数据包边界的协议,例如分段大小)通过使用逐渐增大的数据包来探测路径。如果探测数据包成功传输,则有效的路径 MTU 将提高到探测大小。单独丢失一个探测数据包(无论是否带有 ICMP 消息)被视为 MTU 限制的指示,而不是拥塞指示器。在这种情况下,分组协议被允许重新传输一个丢失数据段,而无需调整拥塞窗口。请阅读 RFC 本身以获取算法的完整描述。
Traditional path MTU discovery requires that all nearby routers know a host’s MTU and that they send the proper ICMP messages to the remote hosts, essentially by proxy. Since PLPMTUD does not require messages from the network, routers do not need to know the host’s MTU. The end - to - end path MTU is deduced by observing which packet sizes are delivered and which are discarded (e.g. in a black hole). The very situation that causes classical path MTU discovery to fail becomes the primary signal for PLPMTUD.
传统的路径 MTU 发现机制要求所有附近的路由器都知道主机的 MTU,并且它们需要向远程主机发送适当的 ICMP 消息,实际上相当于代理。由于 PLPMTUD 不需要来自网络的消息,因此路由器不需要知道主机的 MTU。端到端路径 MTU 是通过观察哪些数据包大小被传输以及哪些被丢弃(例如在黑洞中)来推断的。正是这种导致传统路径 MTU 发现失败的情况,成为了 PLPMTUD 的主要信号。
RFC 4821 can be configured in a number of different ways. The natural first step is as an ICMP black hole recovery algorithm. In this configuration it is only invoked when a connection might be hung due to an ICMP black hole. It raises the robustness of RFC 1191 and RFC 1981 path MTU discovery with no significant downside. We recommend deploying it in all operating systems as soon as reasonably feasible. We are aware of at least 3 vendors who participated in the IETF pmtud WG and have experimental implementations.
RFC 4821 可以以多种不同的方式配置。最自然的第一步是将其作为 ICMP 黑洞恢复算法。在这种配置中,只有当连接可能由于 ICMP 黑洞而挂起时,才会调用它。它提高了 RFC 1191 和 RFC 1981 路径 MTU 发现的健壮性,而没有任何显著的缺点。**我们建议尽快在所有操作系统中部署它。**我们了解到至少有 3 家参与了 IETF pmtud WG 的供应商,并且有实验性实现。
In a slightly more aggressive configuration it can implement “opportunistic jumbo MTU discovery”. Some high performance host interfaces can be pre - configured to use the largest MTU efficiently supported by the memory subsystem and NIC chipset, without prior knowledge of the MTU actually supported on the local network. The per connection initial MTU is selected by a heuristic based on the history of discovered path MTUs (typically initialized to 1500 B). PLPMTUD can then probe up from 1500 bytes, to detect if the full path can support larger MTUs. In this manner an end system can opportunistically discover if the full path supports larger MTUs without any additional protocol support or site specific configuration.
在稍微激进一点的配置中,它可以实现“机会主义的巨帧 MTU 发现”。一些高性能主机接口可以预先配置为使用内存子系统和 NIC 芯片集高效支持的最大 MTU,而无需事先了解本地网络实际支持的 MTU。每个连接的初始 MTU 是根据发现的路径 MTU 的历史记录(通常初始化为 1500 字节)选择的。然后 PLPMTUD 可以从 1500 字节开始探测,以检测整个路径是否支持更大的 MTU。通过这种方式,终端系统可以在没有任何额外的协议支持或特定站点配置的情况下,机会主义地发现整个路径是否支持更大的 MTU。
Opportunistic jumbo MTU discovery has the potential to greatly ease jumbogram deployment since it relaxes some of the requirements on mixed MTU networks. With pure RFC 1191 path MTU discovery, every subnet is required to have a unique MTU, and any one device that can not be upgraded, vetoes the entire upgrade. Opportunistic path MTU discovery supports deployment strategies with mixed MTUs per subnet.
机会主义的巨帧 MTU 发现有可能极大地简化巨帧的部署,因为它放宽了混合 MTU 网络的一些要求。使用纯 RFC 1191 路径 MTU 发现,每个子网都需要有一个唯一的 MTU,任何一个无法升级的设备都会否决整个升级。机会主义路径 MTU 发现支持每个子网具有混合 MTU 的部署策略。
Implementations:
实现:
Linux 2.6.17: ICMP black hole recovery only, off by default
Linux 2.6.17:仅支持 ICMP 黑洞恢复,默认关闭
As we gain field experience with wide deployment of RFC 4821 in the above two configurations, we will document any additional recommendations for implementors. Watch this page for future information.
随着我们在上述两种配置中广泛部署 RFC 4821 并积累现场经验,我们将为实现者记录任何额外的建议。请关注此页面以获取未来信息。
Enabling 9K “Jumbograms” in the Internet today:
在当今的互联网中启用 9K“巨帧”:
We are pushing the wide deployment of 9 kB jumbograms, even though we would prefer to go to larger sizes. Just getting the Internet to the point where it fully supports mixed MTUs will break the current strong local optima at a 1500 B MTU. It is interesting to note that that a huge fraction of the deployed 1 Gb/s and faster gear already supports 9 kB Jumbograms, but it is not enabled all the way to the end systems due to the problems with RFC 1191 listed above.
我们正在推动 9 kB 巨帧的广泛部署,尽管我们更倾向于使用更大的尺寸。只要能让互联网完全支持混合 MTU,就能打破当前在 1500 字节 MTU 处的强烈局部最优状态。有趣的是,大量已部署的 1 Gb/s 及更高速率的设备已经支持 9 kB 巨帧,但由于上述与 RFC 1191 相关的问题,它尚未完全启用到终端系统。
Jumbogram Resources:
巨帧资源:
-
Rational and position papers:
理由和立场文件:
-
Internet 2 statement on Jumbogram deployment by Almes and Summerhill. Internet 2 is in the process of collecting resource pages, location TBD.
Internet 2 的 巨帧部署声明,由 Almes 和 Summerhill 提出。Internet 2 正在收集资源页面,具体位置待定。
-
The Joint Engineering Team (JET) proposed a parallel statement on Jumbogram deployment. The JET represents a collaboration of leading United States federal and academic wide area networks, including: Abilene (Internet2), DREN (DOD), ESnet (DOE), NREN (NASA), vBNS, etc.
联合工程团队(JET) 提出了一个平行的 巨帧部署声明。JET 代表了美国联邦和学术广域网的领先合作,包括:Abilene(Internet2)、DREN(国防部)、ESnet(能源部)、NREN(NASA)、vBNS 等。
-
Diagnostics and tools:
诊断和工具:
Note that as of this writing most stacks do not permit applications to send packets that are larger than the current ICMP learned path MTU. This makes it nearly impossible to to implement diagnostics to detect problems with path MTU discovery. The workaround it to use a raw interface for sending packets without interference from the stack.
需要注意的是,截至本文撰写之时,大多数堆栈不允许应用程序发送大于当前 ICMP 学习到的路径 MTU 的数据包。这使得实现用于检测路径 MTU 发现问题的诊断工具几乎不可能。解决方法是使用原始接口发送数据包,而不受堆栈的干扰。
-
RFC 4821 requires that operating systems support MTU probing from applications. As this is deployed, updated versions of traceroute and tracepath should be able to diagnose MTU discovery problems from all state - of - the - art operating systems. Watch this space for updates.
RFC 4821 要求操作系统支持应用程序的 MTU 探测。随着这一要求的实施,更新版本的 traceroute 和 tracepath 应该能够诊断所有最先进的操作系统中的 MTU 发现问题。请关注此空间以获取更新。
-
PSC maintains a path MTU discovery server that uses a hybrid MTU probing traceroute to diagnose MTU discovery problems, including ICMP black holes. It is 9 k clean from Pittsburgh via Internet2 to most US R & E networks.
PSC 维护了一个 路径 MTU 发现服务器,它使用混合 MTU 探测 traceroute 来诊断 MTU 发现问题,包括 ICMP 黑洞。它通过 Internet2 从匹兹堡到大多数美国研究与教育网络是 9k 清洁的。
-
University of Waikato scamper uses the datalink interface to implement MTU discovery in user mode. This tool can be built for most operating systems that support BPF, so you can do your own testing.
惠灵顿维多利亚大学的 scamper 使用数据链路接口在用户模式下实现 MTU 发现。这个工具可以构建在大多数支持 BPF 的操作系统上,因此你可以进行自己的测试。
-
Other collections of Jumbo resources:
其他巨帧资源集合:
-
The Internet2 network NOC has collected useful resources for network operators, including configuration examples for a couple of common routers and a list of known MTU limits for Internet2 peer and connecting networks.
Internet2 网络 NOC 收集了 网络运营商的有用资源,包括一些常见路由器的配置示例以及 Internet2 同行和连接网络的已知 MTU 限制列表。
-
Phil Dykstra has also collected jumbogram resources.
Phil Dykstra 也收集了巨帧资源。
-
NLANR/NCNE has collected tools and advice for network operators deploying and debugging Jumbograms.
NLANR/NCNE 收集了工具和建议,供部署和调试巨帧的网络运营商使用。
-
Joe St Sauver is collecting a list of Jumbo Frame Clean Networking Gear, to help you select network gear. This is especially useful for educating sales droids about the competition.
Joe St Sauver 正在收集一份 巨帧清洁网络设备清单,以帮助你选择网络设备。这特别有助于向销售人员介绍竞争情况。
Pushing up the Internet MTU
提升互联网 MTU
We are pushing for the deployment of really large MTUs in the high performance parts of the Internet. The standard MTU, 1500 Bytes, is about 3 orders of magnitude too small for for the fastest links in use today. At 10 Gb/s (standard trunks for most mid - sized ISPs), a 1500 Byte packet takes only 1.2 uS (microseconds), which is much smaller than ATM cells at the peak ATM deployment. A 9 kB “jumbogram” takes only 7.3 uS which is not much better. Since current packet times are so short, many of the problems that dogged ATM are hurting the Internet as well. In particular filling a long fast paths (e.g. 60 ms) with 1.2 uS packets requires the transport protocol to manage 50,000 packets in flight concurrently. Not too surprisingly TCP, and all other protocols, have a lot of difficulty managing this many outstanding packets.
我们正在推动在互联网的高性能部分部署真正大的 MTU。标准 MTU 为 1500 字节,对于当今使用的最快链路来说,它大约 小了 3 个数量级。在 10 Gb/s(大多数中型 ISP 的标准干线)下,一个 1500 字节的数据包仅需 1.2 微秒(μS),这比 ATM 在其部署高峰期的 ATM 单元要小得多。一个 9 kB 的“巨帧”也仅需 7.3 微秒,这并没有好太多。由于当前的数据包时间如此之短,许多曾经困扰 ATM 的问题也在对互联网造成伤害。特别是用 1.2 微秒的数据包填充长而快速的路径(例如 60 毫秒),需要传输协议同时管理 50,000 个在途数据包。毫不奇怪,TCP 以及其他所有协议在管理如此多的未确认数据包时都遇到了很大的困难。
If packets were 100 times larger (150 kBytes), the wire time would be 120 uS, the same flow would only require 500 packets in flight. Modern protocols have no difficulty at all managing this number of packets in flight.
如果数据包的大小增加 100 倍(达到 150 kBytes),那么线路上的时间将是 120 微秒,相同的流量只需要 500 个在途数据包。现代协议在管理这么多在途数据包时毫无困难。
How large do we want? Our initial vision was that the factor of ten bandwidth steps should have been allocated to a factor of 8 increase in payload size and a 20% reduction in packet time. Further considerations suggest that other models might be more practical. We show two here: constant time (125 uS, the voice/SONET frame time) and capping at 64kB, which is the natural limit for a number of protocols, including IPv4, due to the number of bits the length field (This limit does not apply to IPv6).
我们想要多大的 MTU?我们最初的设想是,每增加 10 倍的带宽,应该将有效载荷大小增加 8 倍,并将数据包时间减少 20%。进一步的考虑表明,其他模型可能更具实用性。这里我们展示了两种:恒定时间(125 微秒,即语音/SONET 帧时间)和限制在 64kB,这是许多协议(包括 IPv4)的自然极限,因为长度字段的位数限制(此限制不适用于 IPv6)。
Note that there is no specific reason to require any particular MTU at any particular rate. As a general principle, we prefer declining packet times (and declining worst case jitter) as you go to higher rates.
请注意,没有任何特定理由要求在任何特定速率下使用任何特定的 MTU。一般来说,我们更倾向于在提高速率时减少数据包时间(以及减少最坏情况下的抖动)。
| Actual | Vision | Alternate 1 | Alternate 2 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Rate | Year | MTU | Wire Time | MTU | Wire Time | MTU | Wire Time | MTU | Wire Time |
| 10 Mb/s | 1982 | 1.5 kB | 1200 uS | ||||||
| 100 Mb/s | 1995 | 1.5 kB | 120 uS | 12 kB | 960 uS | 9 kB | 720 uS | 4.3 kB | 433 uS |
| 1 Gb/s | 1998 | 1.5 kB | 12 uS | 96 kB | 768 uS | 64 kB | 512 uS | 9 kB | 72 uS |
| 10 Gb/s | 2002 | 1.5 kB | 1.2 uS | 750 kB | 600 uS | 150 kB | 120 uS | 64 kB | 51.2 uS |
| 100 Gb/s | 6 MB | 480 uS | 1.5 MB | 120 uS | 64 kB | 5.12 uS | |||
| 1 Tb/s | 50 MB | 400 uS | 15 MB | 120 uS | 64 kB | 0.512 uS |
| 实际 | 愿景 | 替代方案 1 | 替代方案 2 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 速率 | 年份 | MTU | 线上时间 | MTU | 线上时间 | MTU | 线上时间 | MTU | 线上时间 |
| 10 Mb/s | 1982 | 1.5 kB | 1200 微秒 | ||||||
| 100 Mb/s | 1995 | 1.5 kB | 120 微秒 | 12 kB | 960 微秒 | 9 kB | 720 微秒 | 4.3 kB | 433 微秒 |
| 1 Gb/s | 1998 | 1.5 kB | 12 微秒 | 96 kB | 768 微秒 | 64 kB | 512 微秒 | 9 kB | 72 微秒 |
| 10 Gb/s | 2002 | 1.5 kB | 1.2 微秒 | 750 kB | 600 微秒 | 150 kB | 120 微秒 | 64 kB | 51.2 微秒 |
| 100 Gb/s | 6 MB | 480 微秒 | 1.5 MB | 120 微秒 | 64 kB | 5.12 微秒 | |||
| 1 Tb/s | 50 MB | 400 微秒 | 15 MB | 120 微秒 | 64 kB | 0.512 微秒 |
The above numbers are very speculative about what MTUs might make sense in the market. We keep updating them as we learn more about how MTU affects the balance between switching costs and end - system costs vs end - to - end performance. The Internet as a whole will be seeking to optimize total cost vs performance for across several different communities.
上述数字关于市场上可能合理的 MTU 非常具有推测性。随着我们对 MTU 如何影响交换成本与终端系统成本与端到端性能之间的平衡的了解不断加深,我们一直在更新这些数字。整个互联网将努力为多个不同群体优化总成本与性能。
-
Collected arguments (pro and con) about raising the Internet MTU to truly large sizes.
收集了关于将互联网 MTU 提升到真正大尺寸的论点(正反两方面)。
-
Collected MTU limits present in various technologies. These are features of existing protocols, standards or implementations that limit MTU in some way.
收集了各种技术中存在的 MTU 限制。这些是现有协议、标准或实现中以某种方式限制 MTU 的特性。
-
Sample RFQ language…(FUTURE)
示例 RFQ 语言……(未来)
-
The SDSC 10 Gigabit Ethernet Workshop has been instrumental in properly focusing my attention on the real issues. The slides from my first presentation (Oct 2001) outline some of the basic arguments about MTU.
SDSC 10 千兆以太网研讨会 对于让我正确关注真正的问题起到了关键作用。我在第一次演讲(2001 年 10 月)中使用的 幻灯片 概述了一些关于 MTU 的基本论点。
Why is the maximum MTU size 1472 bytes when using ping?
Jul 8, 2020 11:37 -0500
On most systems the default interface MTU size is set to 1500 bytes:
在大多数系统上,默认接口 MTU 大小设置为 1500 字节:
ens160: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.86.5 netmask 255.255.255.0 broadcast 192.168.86.255
inet6 fe80::20c:29ff:fe9f:7062 prefixlen 64 scopeid 0x20<link>
inet6 2600:6c40:7e80:2515:20c:29ff:fe9f:7062 prefixlen 64 scopeid 0x0<global>
ether 00:0c:29:9f:70:62 txqueuelen 1000 (Ethernet)
RX packets 69 bytes 6460 (6.4 KB)
RX errors 0 dropped 4842873 overruns 0 frame 0
TX packets 52 bytes 5902 (5.9 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
By using the ping command we can validate our network path is capable of transferring 1500 byte packets. But why does the command fail when the packet size is set to 1500 bytes?
通过使用 ping 命令,我们可以验证我们的网络路径是否能够传输 1500 字节的数据包。 但是,当数据包大小设置为 1500 字节时,为什么命令会失败呢?
jemurray@home-server:~$ ping -M do -c 1 -s 1500 128.252.5.113
PING 128.252.5.113 (128.252.5.113) 1500(1528) bytes of data.
ping: local error: Message too long, mtu=1500
--- 128.252.5.113 ping statistics ---
1 packets transmitted, 0 received, +1 errors, 100% packet loss, time 0ms
If the ICMP packet size is reduced to 1472 bytes the transfer is successful:
如果 ICMP 数据包大小减小到 1472 字节,则传输成功:
jemurray@home-server:~$ ping -M do -c 1 -s 1472 128.252.5.113
PING 128.252.5.113 (128.252.5.113) 1472(1500) bytes of data.
1480 bytes from 128.252.5.113: icmp_seq=1 ttl=55 time=12.7 ms
--- 128.252.5.113 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 12.796/12.796/12.796/0.000 ms
Using tshark, we can capture and decode what is going on. In this case nothing. When the MTU on the interface is 1500 bytes, the operating system is dropping the packet before it hits the wire.
使用 tshark,我们可以捕获和解码正在发生的事情。 在这种情况下,什么都没有。 当接口上的 MTU 为 1500 字节时,作系统会在数据包到达线路之前丢弃数据包。
Note: The error message: ping: local error: Message too long, mtu=1500 helps to validate this is a OS rejection, and not a network rejection.
注意:错误消息 ping: local error: Message too long, mtu=1500 有助于验证这是作系统拒绝,而不是网络拒绝。
jemurray@home-server:~$ sudo tshark -i ens160 -n -V icmp
Capturing on 'ens160'
....nothing captured.....
Increasing the MTU size on the interface to 9000 bytes changes the results:
将接口上的 MTU 大小增加到 9000 字节会更改结果:
jemurray@home-server:~$ sudo ifconfig ens160 mtu 9000
jemurray@home-server:~$ ifconfig
ens160: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 9000
inet 192.168.86.5 netmask 255.255.255.0 broadcast 192.168.86.255
inet6 fe80::20c:29ff:fe9f:7062 prefixlen 64 scopeid 0x20<link>
inet6 2600:6c40:7e80:2515:20c:29ff:fe9f:7062 prefixlen 64 scopeid 0x0<global>
ether 00:0c:29:9f:70:62 txqueuelen 1000 (Ethernet)
RX packets 185 bytes 51601 (51.6 KB)
RX errors 0 dropped 4843390 overruns 0 frame 0
TX packets 28 bytes 4273 (4.2 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
The local error goes away, but the ping still fails:
local 错误消失,但 ping 仍然失败:
jemurray@home-server:~$ ping -M do -c 1 -s 1500 128.252.5.113
PING 128.252.5.113 (128.252.5.113) 1500(1528) bytes of data.
--- 128.252.5.113 ping statistics ---
1 packets transmitted, 0 received, 100% packet loss, time 0ms
Now we can see the results from tshark, since the OS is no longer dropping the packets before they hit the wire:
现在我们可以看到 tshark 的结果,因为作系统不再在数据包到达线路之前丢弃数据包:
Internet Protocol Version 4, Src: 192.168.86.5, Dst: 128.252.5.113
0100 .... = Version: 4
.... 0101 = Header Length: 20 bytes (5)
Differentiated Services Field: 0x00 (DSCP: CS0, ECN: Not-ECT)
0000 00.. = Differentiated Services Codepoint: Default (0)
.... ..00 = Explicit Congestion Notification: Not ECN-Capable Transport (0)
Total Length: 1528
Identification: 0x0000 (0)
Flags: 0x4000, Don't fragment
0... .... .... .... = Reserved bit: Not set
.1.. .... .... .... = Don't fragment: Set
..0. .... .... .... = More fragments: Not set
...0 0000 0000 0000 = Fragment offset: 0
Time to live: 64
Protocol: ICMP (1)
Header checksum: 0x97ea [validation disabled]
[Header checksum status: Unverified]
Source: 192.168.86.5
Destination: 128.252.5.113
Internet Control Message Protocol
Type: 8 (Echo (ping) request)
Code: 0
Checksum: 0x710e [correct]
[Checksum Status: Good]
Identifier (BE): 10184 (0x27c8)
Identifier (LE): 51239 (0xc827)
Sequence number (BE): 1 (0x0001)
Sequence number (LE): 256 (0x0100)
Timestamp from icmp data: Jul 8, 2020 12:18:15.000000000 CDT
[Timestamp from icmp data (relative): 0.350233474 seconds]
Data (1492 bytes)
0000 ee 57 05 00 00 00 00 00 10 11 12 13 14 15 16 17 .W..............
0010 18 19 1a 1b 1c 1d 1e 1f 20 21 22 23 24 25 26 27 ........ !"#$%&'
0020 28 29 2a 2b 2c 2d 2e 2f 30 31 32 33 34 35 36 37 ()*+,-./01234567
0030 38 39 3a 3b 3c 3d 3e 3f 40 41 42 43 44 45 46 47 89:;<=>?@ABCDEFG
0040 48 49 4a 4b 4c 4d 4e 4f 50 51 52 53 54 55 56 57 HIJKLMNOPQRSTUVW
0050 58 59 5a 5b 5c 5d 5e 5f 60 61 62 63 64 65 66 67 XYZ[\]^_`abcdefg
0060 68 69 6a 6b 6c 6d 6e 6f 70 71 72 73 74 75 76 77 hijklmnopqrstuvw
0070 78 79 7a 7b 7c 7d 7e 7f 80 81 82 83 84 85 86 87 xyz{|}~.........
0080 88 89 8a 8b 8c 8d 8e 8f 90 91 92 93 94 95 96 97 ................
0090 98 99 9a 9b 9c 9d 9e 9f a0 a1 a2 a3 a4 a5 a6 a7 ................
00a0 a8 a9 aa ab ac ad ae af b0 b1 b2 b3 b4 b5 b6 b7 ................
00b0 b8 b9 ba bb bc bd be bf c0 c1 c2 c3 c4 c5 c6 c7 ................
00c0 c8 c9 ca cb cc cd ce cf d0 d1 d2 d3 d4 d5 d6 d7 ................
00d0 d8 d9 da db dc dd de df e0 e1 e2 e3 e4 e5 e6 e7 ................
00e0 e8 e9 ea eb ec ed ee ef f0 f1 f2 f3 f4 f5 f6 f7 ................
00f0 f8 f9 fa fb fc fd fe ff 00 01 02 03 04 05 06 07 ................
0100 08 09 0a 0b 0c 0d 0e 0f 10 11 12 13 14 15 16 17 ................
0110 18 19 1a 1b 1c 1d 1e 1f 20 21 22 23 24 25 26 27 ........ !"#$%&'
0120 28 29 2a 2b 2c 2d 2e 2f 30 31 32 33 34 35 36 37 ()*+,-./01234567
0130 38 39 3a 3b 3c 3d 3e 3f 40 41 42 43 44 45 46 47 89:;<=>?@ABCDEFG
0140 48 49 4a 4b 4c 4d 4e 4f 50 51 52 53 54 55 56 57 HIJKLMNOPQRSTUVW
0150 58 59 5a 5b 5c 5d 5e 5f 60 61 62 63 64 65 66 67 XYZ[\]^_`abcdefg
0160 68 69 6a 6b 6c 6d 6e 6f 70 71 72 73 74 75 76 77 hijklmnopqrstuvw
0170 78 79 7a 7b 7c 7d 7e 7f 80 81 82 83 84 85 86 87 xyz{|}~.........
0180 88 89 8a 8b 8c 8d 8e 8f 90 91 92 93 94 95 96 97 ................
0190 98 99 9a 9b 9c 9d 9e 9f a0 a1 a2 a3 a4 a5 a6 a7 ................
01a0 a8 a9 aa ab ac ad ae af b0 b1 b2 b3 b4 b5 b6 b7 ................
01b0 b8 b9 ba bb bc bd be bf c0 c1 c2 c3 c4 c5 c6 c7 ................
01c0 c8 c9 ca cb cc cd ce cf d0 d1 d2 d3 d4 d5 d6 d7 ................
01d0 d8 d9 da db dc dd de df e0 e1 e2 e3 e4 e5 e6 e7 ................
01e0 e8 e9 ea eb ec ed ee ef f0 f1 f2 f3 f4 f5 f6 f7 ................
01f0 f8 f9 fa fb fc fd fe ff 00 01 02 03 04 05 06 07 ................
0200 08 09 0a 0b 0c 0d 0e 0f 10 11 12 13 14 15 16 17 ................
0210 18 19 1a 1b 1c 1d 1e 1f 20 21 22 23 24 25 26 27 ........ !"#$%&'
0220 28 29 2a 2b 2c 2d 2e 2f 30 31 32 33 34 35 36 37 ()*+,-./01234567
0230 38 39 3a 3b 3c 3d 3e 3f 40 41 42 43 44 45 46 47 89:;<=>?@ABCDEFG
0240 48 49 4a 4b 4c 4d 4e 4f 50 51 52 53 54 55 56 57 HIJKLMNOPQRSTUVW
0250 58 59 5a 5b 5c 5d 5e 5f 60 61 62 63 64 65 66 67 XYZ[\]^_`abcdefg
0260 68 69 6a 6b 6c 6d 6e 6f 70 71 72 73 74 75 76 77 hijklmnopqrstuvw
0270 78 79 7a 7b 7c 7d 7e 7f 80 81 82 83 84 85 86 87 xyz{|}~.........
0280 88 89 8a 8b 8c 8d 8e 8f 90 91 92 93 94 95 96 97 ................
0290 98 99 9a 9b 9c 9d 9e 9f a0 a1 a2 a3 a4 a5 a6 a7 ................
02a0 a8 a9 aa ab ac ad ae af b0 b1 b2 b3 b4 b5 b6 b7 ................
02b0 b8 b9 ba bb bc bd be bf c0 c1 c2 c3 c4 c5 c6 c7 ................
02c0 c8 c9 ca cb cc cd ce cf d0 d1 d2 d3 d4 d5 d6 d7 ................
02d0 d8 d9 da db dc dd de df e0 e1 e2 e3 e4 e5 e6 e7 ................
02e0 e8 e9 ea eb ec ed ee ef f0 f1 f2 f3 f4 f5 f6 f7 ................
02f0 f8 f9 fa fb fc fd fe ff 00 01 02 03 04 05 06 07 ................
0300 08 09 0a 0b 0c 0d 0e 0f 10 11 12 13 14 15 16 17 ................
0310 18 19 1a 1b 1c 1d 1e 1f 20 21 22 23 24 25 26 27 ........ !"#$%&'
0320 28 29 2a 2b 2c 2d 2e 2f 30 31 32 33 34 35 36 37 ()*+,-./01234567
0330 38 39 3a 3b 3c 3d 3e 3f 40 41 42 43 44 45 46 47 89:;<=>?@ABCDEFG
0340 48 49 4a 4b 4c 4d 4e 4f 50 51 52 53 54 55 56 57 HIJKLMNOPQRSTUVW
0350 58 59 5a 5b 5c 5d 5e 5f 60 61 62 63 64 65 66 67 XYZ[\]^_`abcdefg
0360 68 69 6a 6b 6c 6d 6e 6f 70 71 72 73 74 75 76 77 hijklmnopqrstuvw
0370 78 79 7a 7b 7c 7d 7e 7f 80 81 82 83 84 85 86 87 xyz{|}~.........
0380 88 89 8a 8b 8c 8d 8e 8f 90 91 92 93 94 95 96 97 ................
0390 98 99 9a 9b 9c 9d 9e 9f a0 a1 a2 a3 a4 a5 a6 a7 ................
03a0 a8 a9 aa ab ac ad ae af b0 b1 b2 b3 b4 b5 b6 b7 ................
03b0 b8 b9 ba bb bc bd be bf c0 c1 c2 c3 c4 c5 c6 c7 ................
03c0 c8 c9 ca cb cc cd ce cf d0 d1 d2 d3 d4 d5 d6 d7 ................
03d0 d8 d9 da db dc dd de df e0 e1 e2 e3 e4 e5 e6 e7 ................
03e0 e8 e9 ea eb ec ed ee ef f0 f1 f2 f3 f4 f5 f6 f7 ................
03f0 f8 f9 fa fb fc fd fe ff 00 01 02 03 04 05 06 07 ................
0400 08 09 0a 0b 0c 0d 0e 0f 10 11 12 13 14 15 16 17 ................
0410 18 19 1a 1b 1c 1d 1e 1f 20 21 22 23 24 25 26 27 ........ !"#$%&'
0420 28 29 2a 2b 2c 2d 2e 2f 30 31 32 33 34 35 36 37 ()*+,-./01234567
0430 38 39 3a 3b 3c 3d 3e 3f 40 41 42 43 44 45 46 47 89:;<=>?@ABCDEFG
0440 48 49 4a 4b 4c 4d 4e 4f 50 51 52 53 54 55 56 57 HIJKLMNOPQRSTUVW
0450 58 59 5a 5b 5c 5d 5e 5f 60 61 62 63 64 65 66 67 XYZ[\]^_`abcdefg
0460 68 69 6a 6b 6c 6d 6e 6f 70 71 72 73 74 75 76 77 hijklmnopqrstuvw
0470 78 79 7a 7b 7c 7d 7e 7f 80 81 82 83 84 85 86 87 xyz{|}~.........
0480 88 89 8a 8b 8c 8d 8e 8f 90 91 92 93 94 95 96 97 ................
0490 98 99 9a 9b 9c 9d 9e 9f a0 a1 a2 a3 a4 a5 a6 a7 ................
04a0 a8 a9 aa ab ac ad ae af b0 b1 b2 b3 b4 b5 b6 b7 ................
04b0 b8 b9 ba bb bc bd be bf c0 c1 c2 c3 c4 c5 c6 c7 ................
04c0 c8 c9 ca cb cc cd ce cf d0 d1 d2 d3 d4 d5 d6 d7 ................
04d0 d8 d9 da db dc dd de df e0 e1 e2 e3 e4 e5 e6 e7 ................
04e0 e8 e9 ea eb ec ed ee ef f0 f1 f2 f3 f4 f5 f6 f7 ................
04f0 f8 f9 fa fb fc fd fe ff 00 01 02 03 04 05 06 07 ................
0500 08 09 0a 0b 0c 0d 0e 0f 10 11 12 13 14 15 16 17 ................
0510 18 19 1a 1b 1c 1d 1e 1f 20 21 22 23 24 25 26 27 ........ !"#$%&'
0520 28 29 2a 2b 2c 2d 2e 2f 30 31 32 33 34 35 36 37 ()*+,-./01234567
0530 38 39 3a 3b 3c 3d 3e 3f 40 41 42 43 44 45 46 47 89:;<=>?@ABCDEFG
0540 48 49 4a 4b 4c 4d 4e 4f 50 51 52 53 54 55 56 57 HIJKLMNOPQRSTUVW
0550 58 59 5a 5b 5c 5d 5e 5f 60 61 62 63 64 65 66 67 XYZ[\]^_`abcdefg
0560 68 69 6a 6b 6c 6d 6e 6f 70 71 72 73 74 75 76 77 hijklmnopqrstuvw
0570 78 79 7a 7b 7c 7d 7e 7f 80 81 82 83 84 85 86 87 xyz{|}~.........
0580 88 89 8a 8b 8c 8d 8e 8f 90 91 92 93 94 95 96 97 ................
0590 98 99 9a 9b 9c 9d 9e 9f a0 a1 a2 a3 a4 a5 a6 a7 ................
05a0 a8 a9 aa ab ac ad ae af b0 b1 b2 b3 b4 b5 b6 b7 ................
05b0 b8 b9 ba bb bc bd be bf c0 c1 c2 c3 c4 c5 c6 c7 ................
05c0 c8 c9 ca cb cc cd ce cf d0 d1 d2 d3 d4 d5 d6 d7 ................
05d0 d8 d9 da db ....
Data: ee57050000000000101112131415161718191a1b1c1d1e1f...
[Length: 1492]
Let’s focus on the ICMP part of the packet. Notice the data block is 1492 bytes. Adding an additional 8 bytes for the ICMP header totals 1500 bytes for the ICMP portion of this packet. We still need to add the IP header, this additional information will cause the packet to exceed 1500 bytes.
让我们关注数据包的 ICMP 部分。 请注意,data 块是 1492 字节。 为 ICMP 报头添加额外的 8 个字节,则此数据包的 ICMP 部分总共为 1500 个字节。 我们仍然需要添加 IP 标头,这个额外的信息会导致数据包超过 1500 字节。
Internet Control Message Protocol
Type: 8 (Echo (ping) request)
Code: 0
Checksum: 0x710e [correct]
[Checksum Status: Good]
Identifier (BE): 10184 (0x27c8)
Identifier (LE): 51239 (0xc827)
Sequence number (BE): 1 (0x0001)
Sequence number (LE): 256 (0x0100)
Timestamp from icmp data: Jul 8, 2020 12:18:15.000000000 CDT
[Timestamp from icmp data (relative): 0.350233474 seconds]
Data (1492 bytes)
Looking at the full packet, we see the total length is 1528 bytes. This is beyond what our 1500 byte interface is capable of handling:
查看完整数据包,我们看到总长度为 1528 字节。这超出了我们的 1500 字节接口所能处理的范围:
Total Length: 1528
When the size of the ICMP packet is set to 1500 bytes, that is not taking into account the overhead of the IP header. For the command to succeed, the payload of the ICMP packet PLUS all other headers must not exceed 1500 bytes.
当 ICMP 数据包的大小设置为 1500 字节时,这不考虑 IP 报头的开销。 要使命令成功,ICMP 数据包的 payload 加上所有其他报头不得超过 1500 字节。
Looking at tshark again with a ICMP packet length of 1472 shows that the ICMP data payload is set to 1464, this combined with the ICMP headers = 1472 bytes. Adding on the overhead of the IP header and the packet stays within the 1500 byte limit:
再次查看 ICMP 数据包长度为 1472 的 tshark 显示 ICMP 数据负载设置为 1464,这与 ICMP 报头 = 1472 字节相结合。 加上 IP 报头的开销,数据包保持在 1500 字节限制内:
Internet Protocol Version 4, Src: 192.168.86.5, Dst: 128.252.5.113
0100 .... = Version: 4
.... 0101 = Header Length: 20 bytes (5)
Differentiated Services Field: 0x00 (DSCP: CS0, ECN: Not-ECT)
0000 00.. = Differentiated Services Codepoint: Default (0)
.... ..00 = Explicit Congestion Notification: Not ECN-Capable Transport (0)
Total Length: 1500
Identification: 0x0000 (0)
Flags: 0x4000, Don't fragment
0... .... .... .... = Reserved bit: Not set
.1.. .... .... .... = Don't fragment: Set
..0. .... .... .... = More fragments: Not set
...0 0000 0000 0000 = Fragment offset: 0
Time to live: 64
Protocol: ICMP (1)
Header checksum: 0x9806 [validation disabled]
[Header checksum status: Unverified]
Source: 192.168.86.5
Destination: 128.252.5.113
Internet Control Message Protocol
Type: 8 (Echo (ping) request)
Code: 0
Checksum: 0x24fd [correct]
[Checksum Status: Good]
Identifier (BE): 10864 (0x2a70)
Identifier (LE): 28714 (0x702a)
Sequence number (BE): 1 (0x0001)
Sequence number (LE): 256 (0x0100)
Timestamp from icmp data: Jul 8, 2020 12:38:45.000000000 CDT
[Timestamp from icmp data (relative): 0.658390228 seconds]
Data (1464 bytes)
0000 a6 0b 0a 00 00 00 00 00 10 11 12 13 14 15 16 17 ................
0010 18 19 1a 1b 1c 1d 1e 1f 20 21 22 23 24 25 26 27 ........ !"#$%&'
0020 28 29 2a 2b 2c 2d 2e 2f 30 31 32 33 34 35 36 37 ()*+,-./01234567
0030 38 39 3a 3b 3c 3d 3e 3f 40 41 42 43 44 45 46 47 89:;<=>?@ABCDEFG
0040 48 49 4a 4b 4c 4d 4e 4f 50 51 52 53 54 55 56 57 HIJKLMNOPQRSTUVW
0050 58 59 5a 5b 5c 5d 5e 5f 60 61 62 63 64 65 66 67 XYZ[\]^_`abcdefg
0060 68 69 6a 6b 6c 6d 6e 6f 70 71 72 73 74 75 76 77 hijklmnopqrstuvw
0070 78 79 7a 7b 7c 7d 7e 7f 80 81 82 83 84 85 86 87 xyz{|}~.........
0080 88 89 8a 8b 8c 8d 8e 8f 90 91 92 93 94 95 96 97 ................
0090 98 99 9a 9b 9c 9d 9e 9f a0 a1 a2 a3 a4 a5 a6 a7 ................
00a0 a8 a9 aa ab ac ad ae af b0 b1 b2 b3 b4 b5 b6 b7 ................
00b0 b8 b9 ba bb bc bd be bf c0 c1 c2 c3 c4 c5 c6 c7 ................
00c0 c8 c9 ca cb cc cd ce cf d0 d1 d2 d3 d4 d5 d6 d7 ................
00d0 d8 d9 da db dc dd de df e0 e1 e2 e3 e4 e5 e6 e7 ................
00e0 e8 e9 ea eb ec ed ee ef f0 f1 f2 f3 f4 f5 f6 f7 ................
00f0 f8 f9 fa fb fc fd fe ff 00 01 02 03 04 05 06 07 ................
0100 08 09 0a 0b 0c 0d 0e 0f 10 11 12 13 14 15 16 17 ................
0110 18 19 1a 1b 1c 1d 1e 1f 20 21 22 23 24 25 26 27 ........ !"#$%&'
0120 28 29 2a 2b 2c 2d 2e 2f 30 31 32 33 34 35 36 37 ()*+,-./01234567
0130 38 39 3a 3b 3c 3d 3e 3f 40 41 42 43 44 45 46 47 89:;<=>?@ABCDEFG
0140 48 49 4a 4b 4c 4d 4e 4f 50 51 52 53 54 55 56 57 HIJKLMNOPQRSTUVW
0150 58 59 5a 5b 5c 5d 5e 5f 60 61 62 63 64 65 66 67 XYZ[\]^_`abcdefg
0160 68 69 6a 6b 6c 6d 6e 6f 70 71 72 73 74 75 76 77 hijklmnopqrstuvw
0170 78 79 7a 7b 7c 7d 7e 7f 80 81 82 83 84 85 86 87 xyz{|}~.........
0180 88 89 8a 8b 8c 8d 8e 8f 90 91 92 93 94 95 96 97 ................
0190 98 99 9a 9b 9c 9d 9e 9f a0 a1 a2 a3 a4 a5 a6 a7 ................
01a0 a8 a9 aa ab ac ad ae af b0 b1 b2 b3 b4 b5 b6 b7 ................
01b0 b8 b9 ba bb bc bd be bf c0 c1 c2 c3 c4 c5 c6 c7 ................
01c0 c8 c9 ca cb cc cd ce cf d0 d1 d2 d3 d4 d5 d6 d7 ................
01d0 d8 d9 da db dc dd de df e0 e1 e2 e3 e4 e5 e6 e7 ................
01e0 e8 e9 ea eb ec ed ee ef f0 f1 f2 f3 f4 f5 f6 f7 ................
01f0 f8 f9 fa fb fc fd fe ff 00 01 02 03 04 05 06 07 ................
0200 08 09 0a 0b 0c 0d 0e 0f 10 11 12 13 14 15 16 17 ................
0210 18 19 1a 1b 1c 1d 1e 1f 20 21 22 23 24 25 26 27 ........ !"#$%&'
0220 28 29 2a 2b 2c 2d 2e 2f 30 31 32 33 34 35 36 37 ()*+,-./01234567
0230 38 39 3a 3b 3c 3d 3e 3f 40 41 42 43 44 45 46 47 89:;<=>?@ABCDEFG
0240 48 49 4a 4b 4c 4d 4e 4f 50 51 52 53 54 55 56 57 HIJKLMNOPQRSTUVW
0250 58 59 5a 5b 5c 5d 5e 5f 60 61 62 63 64 65 66 67 XYZ[\]^_`abcdefg
0260 68 69 6a 6b 6c 6d 6e 6f 70 71 72 73 74 75 76 77 hijklmnopqrstuvw
0270 78 79 7a 7b 7c 7d 7e 7f 80 81 82 83 84 85 86 87 xyz{|}~.........
0280 88 89 8a 8b 8c 8d 8e 8f 90 91 92 93 94 95 96 97 ................
0290 98 99 9a 9b 9c 9d 9e 9f a0 a1 a2 a3 a4 a5 a6 a7 ................
02a0 a8 a9 aa ab ac ad ae af b0 b1 b2 b3 b4 b5 b6 b7 ................
02b0 b8 b9 ba bb bc bd be bf c0 c1 c2 c3 c4 c5 c6 c7 ................
02c0 c8 c9 ca cb cc cd ce cf d0 d1 d2 d3 d4 d5 d6 d7 ................
02d0 d8 d9 da db dc dd de df e0 e1 e2 e3 e4 e5 e6 e7 ................
02e0 e8 e9 ea eb ec ed ee ef f0 f1 f2 f3 f4 f5 f6 f7 ................
02f0 f8 f9 fa fb fc fd fe ff 00 01 02 03 04 05 06 07 ................
0300 08 09 0a 0b 0c 0d 0e 0f 10 11 12 13 14 15 16 17 ................
0310 18 19 1a 1b 1c 1d 1e 1f 20 21 22 23 24 25 26 27 ........ !"#$%&'
0320 28 29 2a 2b 2c 2d 2e 2f 30 31 32 33 34 35 36 37 ()*+,-./01234567
0330 38 39 3a 3b 3c 3d 3e 3f 40 41 42 43 44 45 46 47 89:;<=>?@ABCDEFG
0340 48 49 4a 4b 4c 4d 4e 4f 50 51 52 53 54 55 56 57 HIJKLMNOPQRSTUVW
0350 58 59 5a 5b 5c 5d 5e 5f 60 61 62 63 64 65 66 67 XYZ[\]^_`abcdefg
0360 68 69 6a 6b 6c 6d 6e 6f 70 71 72 73 74 75 76 77 hijklmnopqrstuvw
0370 78 79 7a 7b 7c 7d 7e 7f 80 81 82 83 84 85 86 87 xyz{|}~.........
0380 88 89 8a 8b 8c 8d 8e 8f 90 91 92 93 94 95 96 97 ................
0390 98 99 9a 9b 9c 9d 9e 9f a0 a1 a2 a3 a4 a5 a6 a7 ................
03a0 a8 a9 aa ab ac ad ae af b0 b1 b2 b3 b4 b5 b6 b7 ................
03b0 b8 b9 ba bb bc bd be bf c0 c1 c2 c3 c4 c5 c6 c7 ................
03c0 c8 c9 ca cb cc cd ce cf d0 d1 d2 d3 d4 d5 d6 d7 ................
03d0 d8 d9 da db dc dd de df e0 e1 e2 e3 e4 e5 e6 e7 ................
03e0 e8 e9 ea eb ec ed ee ef f0 f1 f2 f3 f4 f5 f6 f7 ................
03f0 f8 f9 fa fb fc fd fe ff 00 01 02 03 04 05 06 07 ................
0400 08 09 0a 0b 0c 0d 0e 0f 10 11 12 13 14 15 16 17 ................
0410 18 19 1a 1b 1c 1d 1e 1f 20 21 22 23 24 25 26 27 ........ !"#$%&'
0420 28 29 2a 2b 2c 2d 2e 2f 30 31 32 33 34 35 36 37 ()*+,-./01234567
0430 38 39 3a 3b 3c 3d 3e 3f 40 41 42 43 44 45 46 47 89:;<=>?@ABCDEFG
0440 48 49 4a 4b 4c 4d 4e 4f 50 51 52 53 54 55 56 57 HIJKLMNOPQRSTUVW
0450 58 59 5a 5b 5c 5d 5e 5f 60 61 62 63 64 65 66 67 XYZ[\]^_`abcdefg
0460 68 69 6a 6b 6c 6d 6e 6f 70 71 72 73 74 75 76 77 hijklmnopqrstuvw
0470 78 79 7a 7b 7c 7d 7e 7f 80 81 82 83 84 85 86 87 xyz{|}~.........
0480 88 89 8a 8b 8c 8d 8e 8f 90 91 92 93 94 95 96 97 ................
0490 98 99 9a 9b 9c 9d 9e 9f a0 a1 a2 a3 a4 a5 a6 a7 ................
04a0 a8 a9 aa ab ac ad ae af b0 b1 b2 b3 b4 b5 b6 b7 ................
04b0 b8 b9 ba bb bc bd be bf c0 c1 c2 c3 c4 c5 c6 c7 ................
04c0 c8 c9 ca cb cc cd ce cf d0 d1 d2 d3 d4 d5 d6 d7 ................
04d0 d8 d9 da db dc dd de df e0 e1 e2 e3 e4 e5 e6 e7 ................
04e0 e8 e9 ea eb ec ed ee ef f0 f1 f2 f3 f4 f5 f6 f7 ................
04f0 f8 f9 fa fb fc fd fe ff 00 01 02 03 04 05 06 07 ................
0500 08 09 0a 0b 0c 0d 0e 0f 10 11 12 13 14 15 16 17 ................
0510 18 19 1a 1b 1c 1d 1e 1f 20 21 22 23 24 25 26 27 ........ !"#$%&'
0520 28 29 2a 2b 2c 2d 2e 2f 30 31 32 33 34 35 36 37 ()*+,-./01234567
0530 38 39 3a 3b 3c 3d 3e 3f 40 41 42 43 44 45 46 47 89:;<=>?@ABCDEFG
0540 48 49 4a 4b 4c 4d 4e 4f 50 51 52 53 54 55 56 57 HIJKLMNOPQRSTUVW
0550 58 59 5a 5b 5c 5d 5e 5f 60 61 62 63 64 65 66 67 XYZ[\]^_`abcdefg
0560 68 69 6a 6b 6c 6d 6e 6f 70 71 72 73 74 75 76 77 hijklmnopqrstuvw
0570 78 79 7a 7b 7c 7d 7e 7f 80 81 82 83 84 85 86 87 xyz{|}~.........
0580 88 89 8a 8b 8c 8d 8e 8f 90 91 92 93 94 95 96 97 ................
0590 98 99 9a 9b 9c 9d 9e 9f a0 a1 a2 a3 a4 a5 a6 a7 ................
05a0 a8 a9 aa ab ac ad ae af b0 b1 b2 b3 b4 b5 b6 b7 ................
05b0 b8 b9 ba bb bc bd be bf ........
Data: a60b0a0000000000101112131415161718191a1b1c1d1e1f...
[Length: 1464]
via:
-
How 1500 bytes became the MTU of the internet
https://news.ycombinator.com/item?id=22364830 -
How 1500 bytes became the MTU of the internet
https://blog.benjojo.co.uk/post/why-is-ethernet-mtu-1500 -
Just How Did 1500 Bytes Become The MTU Of The Internet?
https://hackaday.com/2021/06/29/just-how-did-1500-bytes-become-the-mtu-of-the-internet/ -
protocol theory - What is the actual size of an Ethernet MTU
https://networkengineering.stackexchange.com/questions/5057/what-is-the-actual-size-of-an-ethernet-mtu -
Why was the MTU size for ethernet frames calculated as 1500 bytes?
https://networkengineering.stackexchange.com/questions/2962/why-was-the-mtu-size-for-ethernet-frames-calculated-as-1500-bytes -
router - OSPF Stuck in Exstart Adjacency State
https://networkengineering.stackexchange.com/questions/2598/ospf-stuck-in-exstart-adjacency-state/2599 -
Troubleshoot OSPF Neighbors Stuck in Exstart/Exchange State - Cisco
https://www.cisco.com/c/en/us/support/docs/ip/open-shortest-path-first-ospf/13684-12.html -
Arguments about Internet MTU
http://staff.psc.edu/mathis/MTU/arguments.html -
Raising the Internet MTU
http://staff.psc.edu/mathis/MTU/index.html -
Why is the maximum MTU size 1472 bytes when using ping?
https://jasonmurray.org/posts/2020/icmpmtu/