【深度学习】基于Hough变化的答题卡识别(Matlab代码实现)
💥 💥 💞 💞 欢迎来到本博客 ❤️ ❤️ 💥 💥
🏆 博主优势: 🌞 🌞 🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳ 座右铭:行百里者,半于九十。
📋 📋 📋 本文目录如下: 🎁 🎁 🎁
目录
💥1 概述
📚2 运行结果
🎉3 参考文献
🌈4 Matlab代码实现
💥1 概述
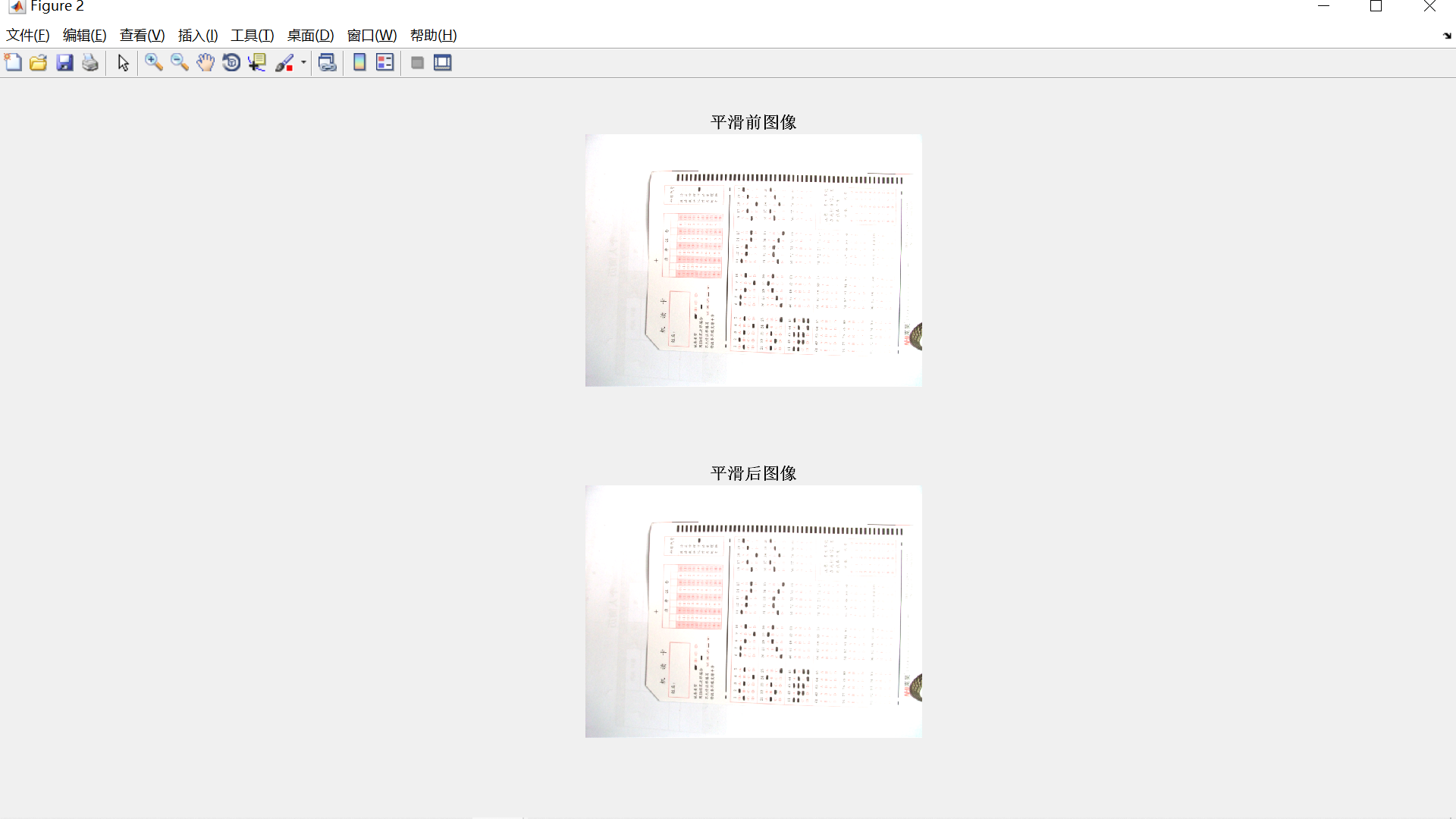
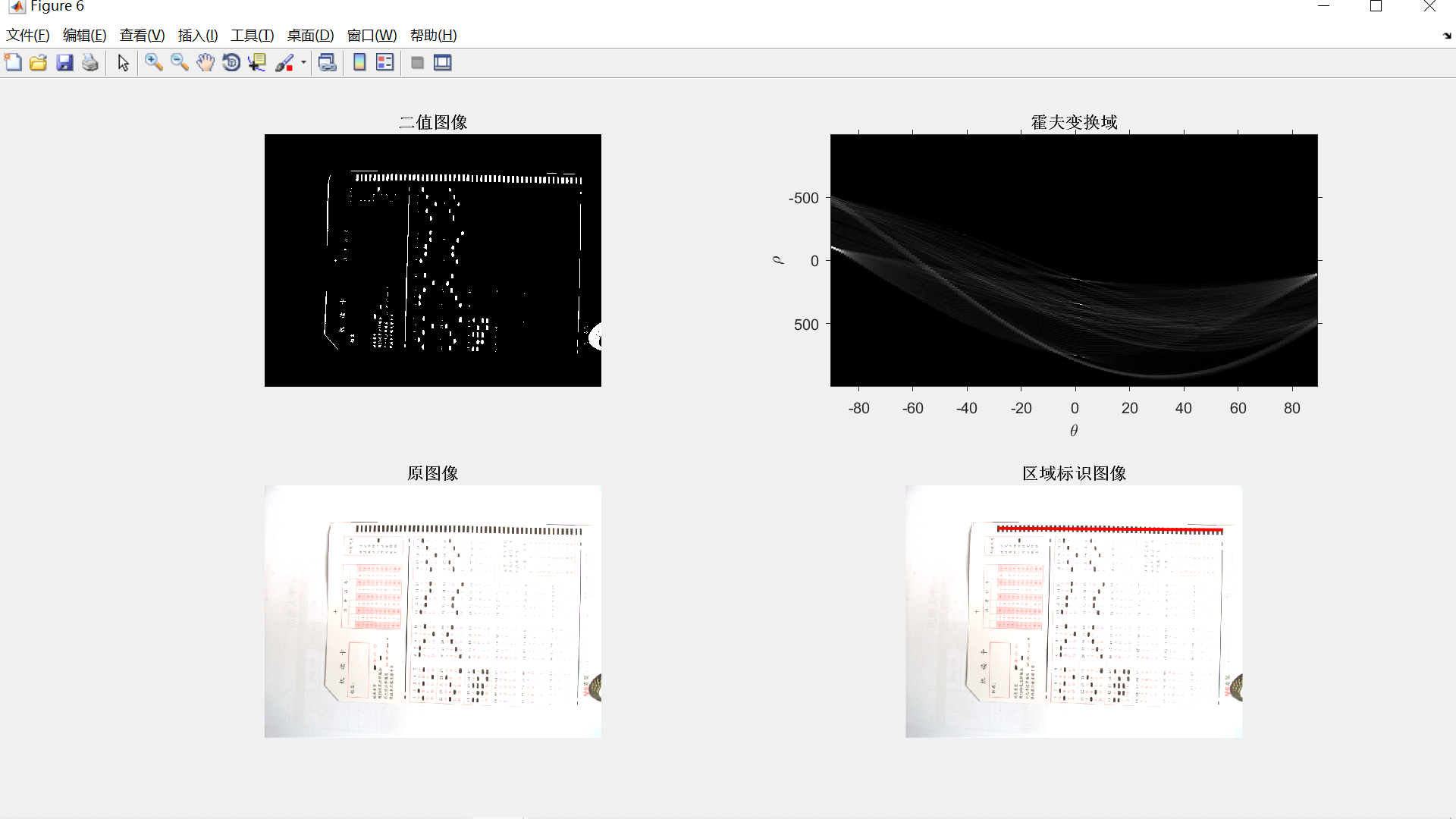
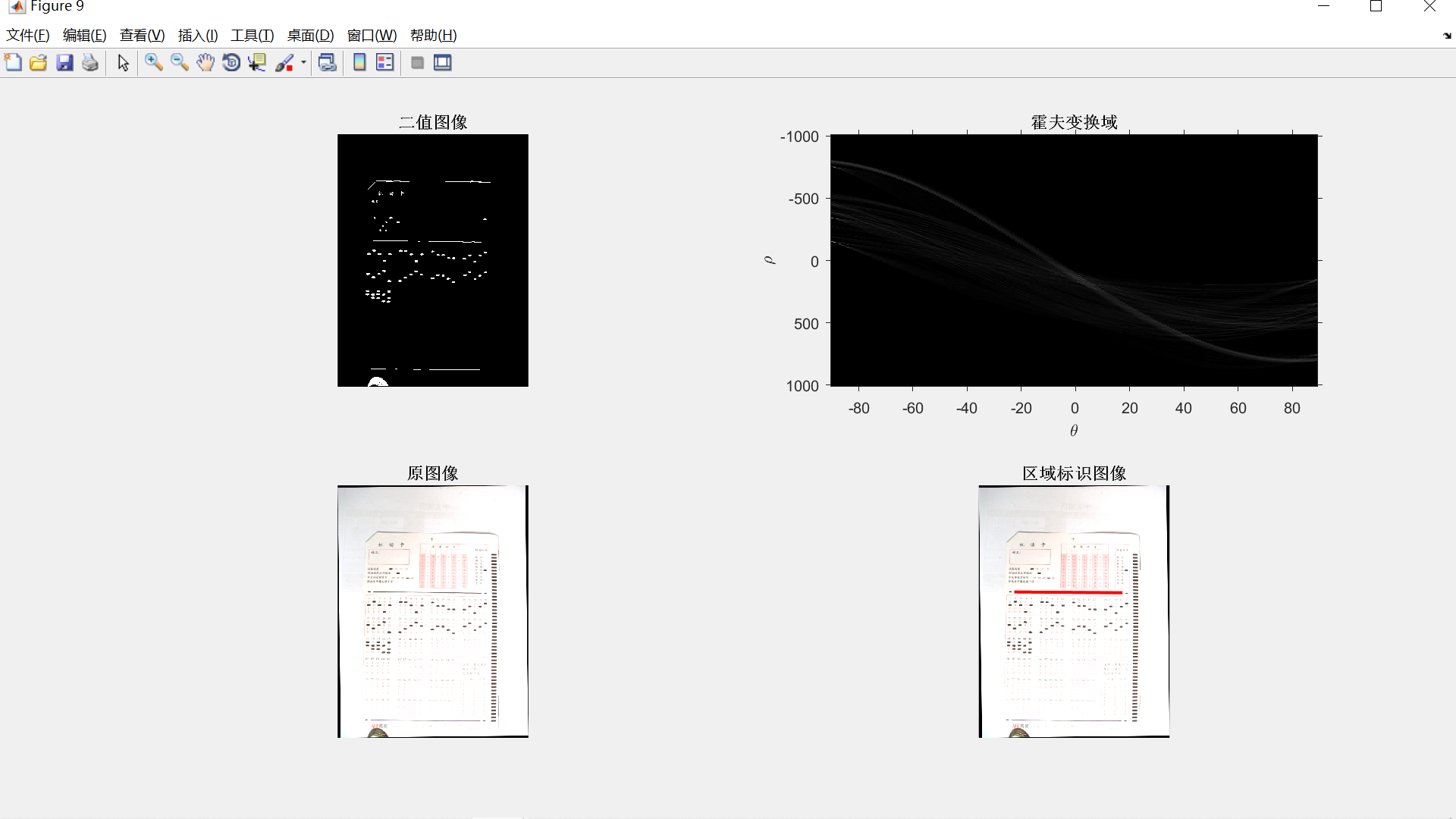
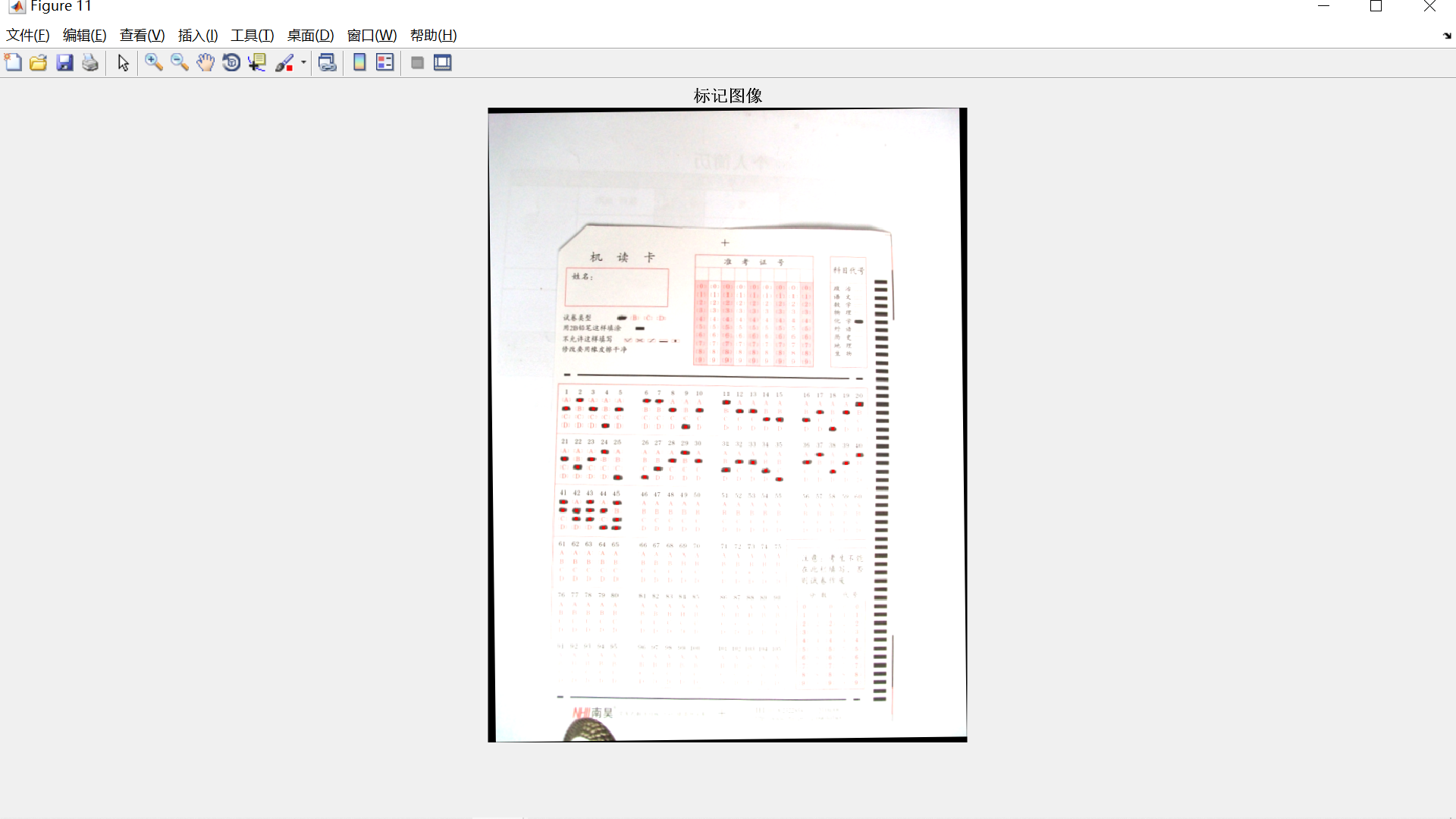
为了提高视频图像关键帧提取及修复效果,设计了一种基于计算机视觉的视频图像关键帧提取及修复方法。基于计算机视觉进行视频图像采集;采用阈值分割法建立灰度值模型,计算背景与目标的灰度差;利用视频图像中的主要特征窗口获取像素值,使用熵值法采集剩余的局部纹理图像,以完成视频图像关键帧提取。在此基础上,利用加权法还原原始矩阵,完成视频图像关键帧修复。实验结果表明,此方法提取的图像清晰度较高,能够提取到图像的颜色特征和纹理特征,提取多个视频图像关键帧的时间较少。此外,还要解决机器视觉系统对目标的识别和位置的检测计算量大、精度低的问题,本文基于提出了一种Hough变换的图像特征识别算法,利用Hough变换对边缘检测结果进行形状特征的识别,提高了目标识别的准确度,降低了计算量。客观题考试阅卷是一项烦琐重复的工作,现有的自动化阅卷设备成本较高,为降低教师的工作强度,节约成本,针对以上问题提出一种基于局部自适应阈值分割和Hough变换的答题卡识别方法。运用数字图像处理的手段,先对答题卡图像进行平滑滤波、图像灰度化、图像二值化等预处理,再依据Hough变换进行倾斜校正得到待检测识别图像,最后根据区域的分割定位进行识别判断。实验结果表明,该算法对于答题卡的识别准确率高、使用方便,具有一定的应用价值。
📚2 运行结果
























部分代码:
主函数:
clc; clear all; close all;
warning off all;
I = imread('images\\1.jpg');
I1 = Image_Normalize(I, 1);
hsize = [3 3];
sigma = 0.5;
I2 = Image_Smooth(I1, hsize, sigma, 1);
I3 = Gray_Convert(I2, 1);
bw2 = Image_Binary(I3, 1);
figure; subplot(1, 2, 1); imshow(I, []); title('原图像');
subplot(1, 2, 2); imshow(bw2, []); title('二值化图像');
[~, ~, xy_long] = Hough_Process(bw2, I1, 1);
angle = Compute_Angle(xy_long);
[I4, bw3] = Image_Rotate(I1, bw2, angle*1.8, 1);
[bw4, Loc1] = Morph_Process(bw3, 1);
[Len, XYn, xy_long] = Hough_Process(bw4, I4, 1);
[bw5, bw6] = Region_Segmation(XYn, bw4, I4, 1);
[stats1, stats2, Line] = Location_Label(bw5, bw6, I4, XYn, Loc1, 1);
[Dom, Aom, Answer, Bn] = Analysis(stats1, stats2, Line, I4);
🎉3 参考文献
部分理论来源于网络,如有侵权请联系删除。
[1]刘峰,吴文杰,刘小磊,王欣然,方亚平,李国亮,杜小勇.计算机视觉与深度学习在猪只识别中的研究进展[J/OL].华中农业大学学报:1-10[2023-03-17]
[]李一君.基于计算机视觉和深度学习的安播辅助提示系统设计与应用[J].广播与电视技术,2022,49(12):121-126.DOI:10.16171/j.cnki.rtbe.20220012025.