Spark SQL支持DataFrame操作的数据源
DataFrame提供统一接口加载和保存数据源中的数据,包括:结构化数据、Parquet文件、JSON文件、Hive表,以及通过JDBC连接外部数据源。一个DataFrame可以作为普通的RDD操作,也可以通过(registerTempTable)注册成一个临时表,支持在临时表的数据上运行SQL查询操作。
一、数据源加载保存操作
DataFrame数据源默认文件为Parquet格式,可以通过spark.sql.sources.default参数进行重新修改。
不论何种格式的数据源均采取统一API、read和write进行操作,代码如下:
// 读取parquet格式数据
val df =sqlContext.read.load("file:///$SPARK_HOME/examples/src/main/resources/users.parquet")
// 从DataFrame写数据并保存成Parquet格式
df.write.save("saveusers.parquet")
1,指定选项
Spark支持通过完全限定名称(如org.apache.spark.sql.parquet)指定数据源的附加选项,内置数据源可以使用短名称(json、parquet、jdbc),Spark SQL支持通过format将任何类型的DataFrames转换成其他类型。
val df = sqlContext.read.format("json").load("file:///$SPARK_HOME examples/src/main/resources/people.json")
df.select("name", "age").write.format("parquet").save("namesAndAges.parquet")
2,保存模式
可以通过配置SaveMode指定如何处理现有数据,实现保存模式不使用任何锁定,而且不是原子操作;因此,多路数据写入相同位置是不安全的。当执行overwrite时,写入新数据之前原来数据将被删除。

3,保存持久表
当使用HiveContext时,DataFrames通过saveAsTable命令保存为持久表使用,与registerTempTable命令不同,saveAsTable实现Dataframe的内容,并创建一个指向Hive Metastore中数据的指针。即使Spark程序重新启动,连接相同Metastore的数据不会发生变化。
默认情况下saveAsTable将创建一个“管理表”,这意味着数据的位置将由Metastore控制,当表被删除时,管理表将表数据自动删除。
二、Parquet文件
Parquet是一种支持多种数据处理系统的存储格式,Spark SQL提供了读写Parquet文件,并且自动保存原始数据的模式。
1,Parquet文件优点
(1)高效,Parquet采取列式存储避免读入不需要的数据,具有极好的性能和GC。
(2)方便的压缩和解压缩,并具有极好的压缩比例。
(3)可以直接固化为Parquet文件,也可以直接读取Parquet文件,具有比磁盘更好的缓存效果。
Spark SQL对读写Parquet文件提供支持,方便加载Parquet文件数据到DataFrame,供Spark SQL操作,也可以将DataFrame写入Parquet文件,并自动保留原始Scheme架构。
在外部数据源方面,Spark对Parquet的支持有了很大的加强,更快的metadata discovery和schema merging;同时能够读取其他工具或者库生成的非标准合法的Parquet文件;以及更快、更鲁棒的动态分区插入。
2,加载数据编程
通过sqlContext.implicits._隐式转换一个RDD为DataFrame,并将DataFrame保存为Parquet文件;加载保存的Parquet文件,重新构建一个DataFrame,注册成临时表,供SQL查询使用。
// 创建sqlContextval
sqlContext = new org.apache.spark.sql.SQLContext(sc)
// 隐式转换为一个DataFrame
import sqlContext.implicits._
// 使用case定义schema,实现Person接口
case class Person(name: String, age: Int)
// 读取文件创建一个MappedRDD,并将数据写入Person模式类,隐式转换为DataFrame
val peopleDF = sc.textFile("file:///$SPARK_HOME/examples/src/main/resources/people.txt").map(_.split(",")).map(p => Person(p(0), p(1).trim.toInt)).toDF()
// 保存DataFrame,保存为Parquet格式
peopleDF.write.parquet("people.parquet")
// 加载Parquet文件作为DataFrame
val parquetFile = sqlContext.read.parquet("people.parquet")
// 将DataFrame注册为临时表,供SQL查询使用
parquetFile.registerTempTable("parquetTable")
val result = sqlContext.sql("SELECT name FROM parquetTable WHERE age >= 13 AND age <= 19")
result.map(t => "Name: " + t(0)).collect().foreach(println)
3,分区发现(partition discovery)
表分区(table partitioning)是一种常见的优化方法,用于像Hive一样的系统。对于分区表,数据通常存储在不同的目录中,在每个分区目录路径中对分区列的值进行编码。
Parquet数据源能够自动发现和推断分区信息,使用以下目录结构存储以前使用的人口数据到一个分区表,以gender和country作为分区列:
path└──table
├── gender=male
│ ├── ...
│ ├── country=US
│ │ └── data.parquet
│ ├── country=CN
│ │ └── data.parquet
│ └── ...
└── gender=female
├── ...
├── country=US
│ └── data.parquet
├── country=CN
│ └── data.parquet
└── ...
通过路径path/table,使用SQLContext.read的parquet或load命令,Spark SQL自动提取分区信息,返回的DataFrame模式如下:
root
|-- name: string (nullable = true)
|-- age: long (nullable = true)
|-- gender: string (nullable = true)
|-- country: string (nullable = true)
分区列的数据类型是自动映射,支持numeric数据类型和string类型自动推断。
4,模式合并(schema merging)
如同ProtocolBuffer、Avro、Thrift,Parquet也支持模式演进,用户可以从一个简单的模式开始,逐步根据需要添加更多的列。通过这种方式,用户最终得到多个不同但是能相互兼容模式的Parquet文件,Parquet数据源能够自动检测这种情况,进而合并这些文件。
由于模式合并是相对昂贵的操作,在很多情况下并非必须,为了提升性能,在1.5.0版本中默认关闭。
// 隐式转换一个RDD为DataFrame
import sqlContext.implicits._
// 创建一个DataFrame,存储数据到一个分区目录
val df1 = sc.makeRDD(1 to 5).map(i => (i, i * 2)).toDF("single", "double")
df1.write.parquet("data/test_table/key=1")
// 创建一个新DataFrame,存储在一个新的分区目录
val df2 = sc.makeRDD(6 to 10).map(i => (i, i * 3)).toDF("single", "triple")
df2.write.parquet("data/test_table/key=2")
// 读取分区表
val df3 = sqlContext.read.option("mergeSchema", "true").parquet("data/test_table")
df3.printSchema()
// 通过基础DataFrame函数,以树格式打印Schema,包含分区目录下全部的分区列
df3.printSchema()
// root
// |-- single: int (nullable = true)
// |-- double: int (nullable = true)
// |-- triple: int (nullable = true)
// |-- key: int (nullable = true)
Parquet数据源自动从文件路径中发现了key这个分区列,并且正确合并了两个不相同但相容的Schema。值得注意的是,如果最后的查询中查询条件跳过了key=1这个分区,Spark SQL的查询优化器会根据这个查询条件将该分区目录剪掉,完全不扫描该目录中的数据,从而提升查询性能。
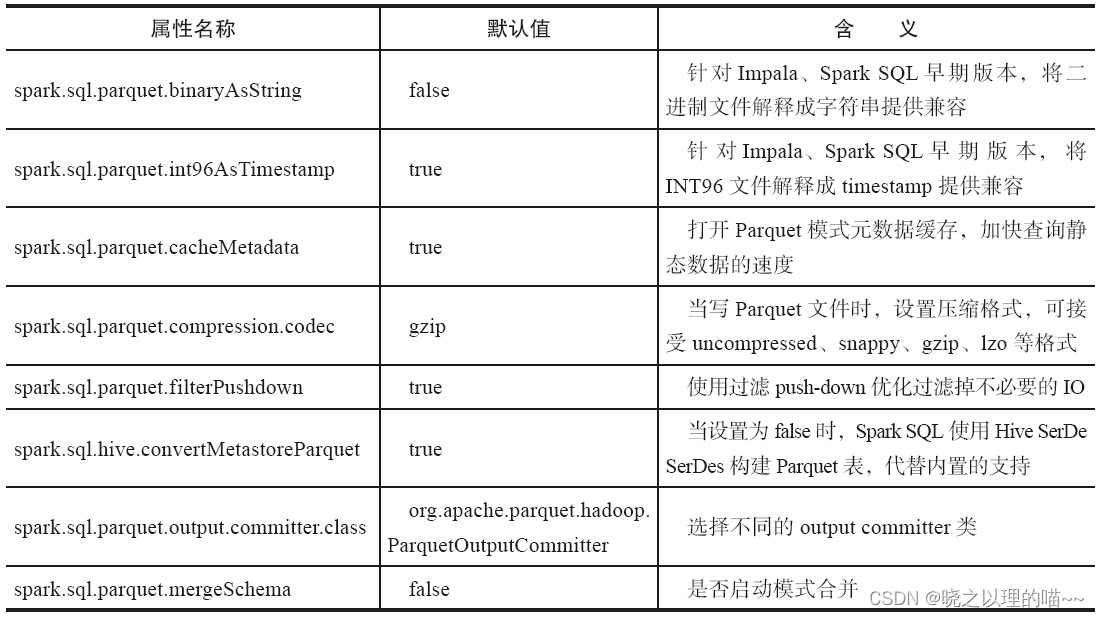
5,配置
在SQLContext中使用setConf方法,或在运行时使用SQL命令SET key=value,实现对Parquet文件的配置
三、JSON数据集
Spark SQL可以自动推断出一个JSON数据集的Schema并作为一个DataFrame加载,通过SQLContext.read.json()方法使用JSON文件创建DataFrame。
// 创建sqlContextval
sqlContext = new org.apache.spark.sql.SQLContext(sc)
// 设置JSON数据集的路径,可以是单个文件或者一个目录
val path= file:///Spark_Home/examples/src/main/resources/people.json"
val people = sqlContext.read.json(path)
// 打印schema,并显示推断的schema
people.printSchema()
// root
// |-- age: integer (nullable = true)
// |-- name: string (nullable = true)
// 注册DataFrame作为一个临时表
people.registerTempTable("jsonTable")
// 使用sql运行SQL表达式
val teenagers = sqlContext.sql("SELECT name FROM jsonTable WHERE age >= 13 AND age <= 19")
或者通过转换一个JSON对象的RDD[String]创建DataFrame。
val anotherRDD = sc.parallelize("""{"name":"Yin","address":{"city":"Columbus","state":"Ohio"}}""" :: Nil)
val anotherPeople = sqlContext.read.json(anotherRDD)
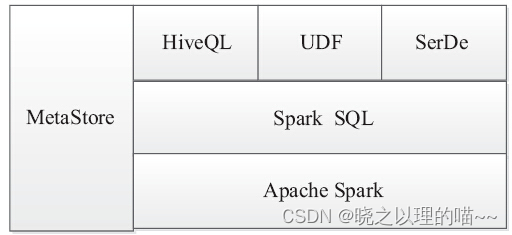
四、Hive表
Spark SQL支持从Hive表中读写数据,然而默认版本Spark组件并不包括Hive大量的依赖关系。Hive支持通过添加-Phive和-Phive-thriftserver标志对Spark重新构建一个包括Hive的新组件,Hive的新组件必须分发到所有的Worker节点上,因为Worker节点需要访问Hive的serialization和deserialization库(SerDes),以便于访问存储在Hive中的数据,所以该Hive集合Jar包必须拷贝到所有的Worker节点。
除了基本的SQLContext,Spark SQL还可以创建一个HiveContext,该HiveContext通过基本的SQLContext提供了一系列的方法集,可以使用更完整的HiveQL解析器查询,访问Hive的UDF,并从Hive表读取数据,以及SerDe支持。
1,示例数据
新建一个kv1.txt文件,数据如下:
238 val_238
86 val_86
311 val_311
27 val_27
165 val_165
409 val_409
255 val_255
278 val_278
98 val_98
2,创建HiveContext
使用Hive,必须先构建一个继承SQLContext的HiveContext对象,并加入在MetaStore中查找表和使用HiveQL写查询功能的支持;可以在conf目录hive-site.xml文件中添加Hive的配置文件,当运行一个YARN集群时,datanucleus jars和hive-site.xml必须在Driver和全部的Executors启动。
一个简单的方法如下:在spark-submit命令行通过–jars参数和–file参数加载,即使hive-site.xml文件没有配置,仍然可以创建一个HiveContext,并会在当前目录下自动地创建metastore_db和warehouse。
使用Scala语言说明HiveContext创建方式:
// SparkContext实例
val sc: SparkContext = ...
// 通过sc创建HiveContext的实例hiveContext
val hiveContext = new org.apache.spark.sql.hive.HiveContext(sc)
3,使用Hive操作数据
使用HiveContext无需单独安装Hive,可以使用spark.sql.dialect选项选择解析查询语句的SQL的特定转化,这个参数可以使用SQLContext上的setConf方法,也可以使用SQL上的SETkey=value命令进行修改。
// 通过HiveContext的sql命令创建表
hiveContext.sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING)")
// 加载数据, $SPARK_HOME指Spark文件安装目录,使用“file:// ...”标识的本地文件,使用“hdfs:// ...”标识的HDFS存储系统的文件
hiveContext.sql("LOAD DATA LOCAL INPATH 'file:///$Spark_Home/examples/src/main/resources/kv1.txt' INTO TABLE src")
// HiveQL的查询表达
hiveContext.sql("FROM src SELECT key,value").collect().foreach(println)
// 使用HiveContext创建表命令
CREATE [EXTERNAL] TABLE[IF NOT EXISTS] table_name
(col_name data_type,…)
[PARTITIONED BY(col_name data_type,…)]
[[ROW FORMAT row_format]]
[STORED AS file_format]
[LOCATION hdfs_path]
4,Spark支持的Hive特性
(1)Hive查询语句,包括:SELECT、GROUP BY、ORDER BY、CLUSTER BY、SORT BY;
(2)Hive运算符,包括:关系运算符(=、<>、、<>、<、>、>=、<=等)、算术运算符(+、-、*、/、%等)、逻辑运算符(AND、&&、OR、||等)、复杂类型构造函数、数据函数(sign、ln、cos等)、字符串函数(instr、length、printf等);
(3)用户自定义函数(UDF);
(4)用户自定义聚合函数(UDAF);
(5)用户定义的序列化格式(SerDes);
(6)连接操作,包括:JOIN、{LEFT|RIGHT|FULL}OUTER JOIN、LEFT SEMI JOIN、CROSS JOIN;
(7)联合操作(Unions);
(8)子查询:SELECT col FROM(SELECT a+b AS col from t1)t2;
(9)抽样(Sampling);
(10)解释(Explain);
(11)分区表(Partitioned tables);
(12)所有的HiveDDL操作函数,包括:CREATE TABLE、CREATE TABLE AS SELECT、ALTER TABLE;
(13)大多数Hive数据类型TINYINT、SMALLINT、INT、BIGINT、BOOLEAN、FLOAT、DOUBLE、STRING、BINARY、TIMESTAMP、DATE、ARRAY<>、MAP<>、STRUCT<>。
五、通过JDBC连接数据库
Spark SQL还包括一个可以通过JDBC从其他数据库读取数据的数据源,并返回一个DataFrame,在Spark SQL很容易处理,或者Join其他的数据源。除了Scala语言,Java或Python语言也很容易操作而不需要提供一个Class Tag。(不同于Spark SQL JDBC server允许其他应用程序使用Spark SQL运行查询。)
在Spark类路径中包含特定数据库的JDBC驱动程序,如通过Spark Shell连接postgresql命令:
SPARK_CLASSPATH=postgresql-9.3-1102-jdbc41.jar bin/spark-shell
val jdbcDF = sqlContext.load("jdbc", Map(
"url" -> "jdbc:postgresql:dbserver",
"dbtable" -> "schema.tablename"))
使用数据源API,加载远程数据库的表作为一个DataFrame和Spark SQL临时表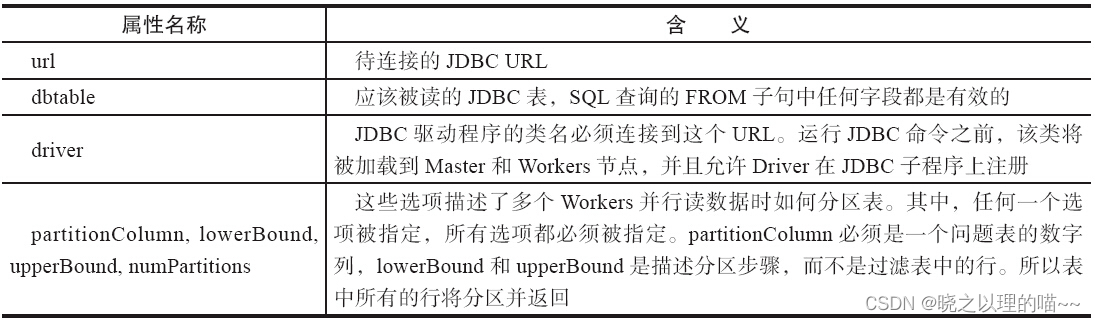
文章来源:《Spark核心技术与高级应用》 作者:于俊;向海;代其锋;马海平
文章内容仅供学习交流,如有侵犯,联系删除哦!