数据库基础语法
sql(Structured Query Language 结构化查询语言)
SQL语法
- use DataTableName; 命令用于选择数据库。
- set names utf8; 命令用于设置使用的字符集。
- SELECT * FROM Websites; 读取数据表的信息。
- 上面的表包含五条记录(每一条对应一个网站信息)和5个列(id、name、url、alexa 和country)。
重要的SQL命令
- SELECT - 从数据库中提取数据
- UPDATE - 更新数据库中的数据
- DELETE - 从数据库中删除数据
- INSERT INTO - 向数据库中插入新数据
- CREATE DATABASE - 创建新数据库
- ALTER DATABASE - 修改数据库
- CREATE TABLE - 创建新表
- ALTER TABLE - 变更(改变)数据库表
- DROP TABLE - 删除表
- CREATE INDEX - 创建索引(搜索键)
- DROP INDEX - 删除索引
- select xx,xx from table 从表中查找xx,xx
- select distinct xx ,xx from table 从表中查找xx,xx(不同的值,去掉重复值)
- select xx,xx from table where xxxxxs(某个条件) 限定条件
| 运算符 | 描述 |
|---|---|
| = | 等于 |
| <> | 不等于。**注释:**在 SQL 的一些版本中,该操作符可被写成 != |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
| BETWEEN | 在某个范围内 |
| LIKE | 搜索某种模式 |
| IN | 指定针对某个列的多个可能值 |
-
and or 运算符、
- 如果第一个条件和第二个条件都成立,则 AND 运算符显示一条记录。
- 如果第一个条件和第二个条件中只要有一个成立,则 OR 运算符显示一条记录。
- where country=‘CN’ and alexa>50(两个条件成立)
- where country=‘CN’ or alexa>50 (一个符合就可以)
- WHERE alexa > 15 AND (country=‘CN’ OR country=‘USA’);(双条件)
-
SELECT xxxx, xxx, ... FROM table_name ORDER BY xxxx, xxx, ... ASC|DESC;- asc 升序排序
- desc 降序排序
- order by 根据xxx进行排序,用,分开可以用多个来排序
-
insert into 向表中插入新纪录
-
INSERT INTO table_name (column1,column2,column3,...) VALUES (value1,value2,value3,...); INSERT INTO Websites (name, url, alexa, country) VALUES ('百度','https://www.baidu.com/','4','CN'); 空会自动补0/null table_name:需要插入新记录的表名。 column1, column2, ...:需要插入的字段名。 value1, value2, ...:需要插入的字段值。
-
-
updata
-
UPDATE Websites SET alexa='5000', country='USA' WHERE name='菜鸟教程';//where很重要 把 "菜鸟教程" 的 alexa 排名更新为 5000,country 改为 USA。
-
-
delete
-
DELETE FROM table_name WHERE condition; 从某表删除 where条件下的值
-
-
top、limit、rownum(**注意:**并非所有的数据库系统都支持 SELECT TOP 语句。 MySQL 支持 LIMIT 语句来选取指定的条数数据, Oracle 可以使用 ROWNUM 来选取。)
- select top num from table
- select * from table limit num
- select * from table where rownum<=num
-
like(指定模式)、
-
SELECT * FROM Websites
WHERE name LIKE ‘G%’;//%通配符,以G开头的 -
通配符 描述 % 替代 0 个或多个字符 _ 替代一个字符 [charlist] 字符列中的任何单一字符 [^charlist] 或 [!charlist] 不在字符列中的任何单一字符
-
-
in(where 子句中规定多个值)
- SELECT * FROM Websites
WHERE name IN (‘Google’,‘菜鸟教程’);
- SELECT * FROM Websites
-
between(取两个值之间的数)
- not between WHERE alexa NOT BETWEEN 1 AND 20;
- not in
- WHERE (alexa BETWEEN 1 AND 20)
AND country NOT IN (‘USA’, ‘IND’);
- WHERE (alexa BETWEEN 1 AND 20)
- 文本 WHERE name BETWEEN ‘A’ AND ‘H’;
SELECT column1, column2, ... FROM table_name WHERE column BETWEEN value1 AND value2;- column1, column2, …:要选择的字段名称,可以为多个字段。如果不指定字段名称,则会选择所有字段。
- table_name:要查询的表名称。
- column:要查询的字段名称。
- value1:范围的起始值。
- value2:范围的结束值。
高级sql
别名
xx,xx AS xx
链接 (join)
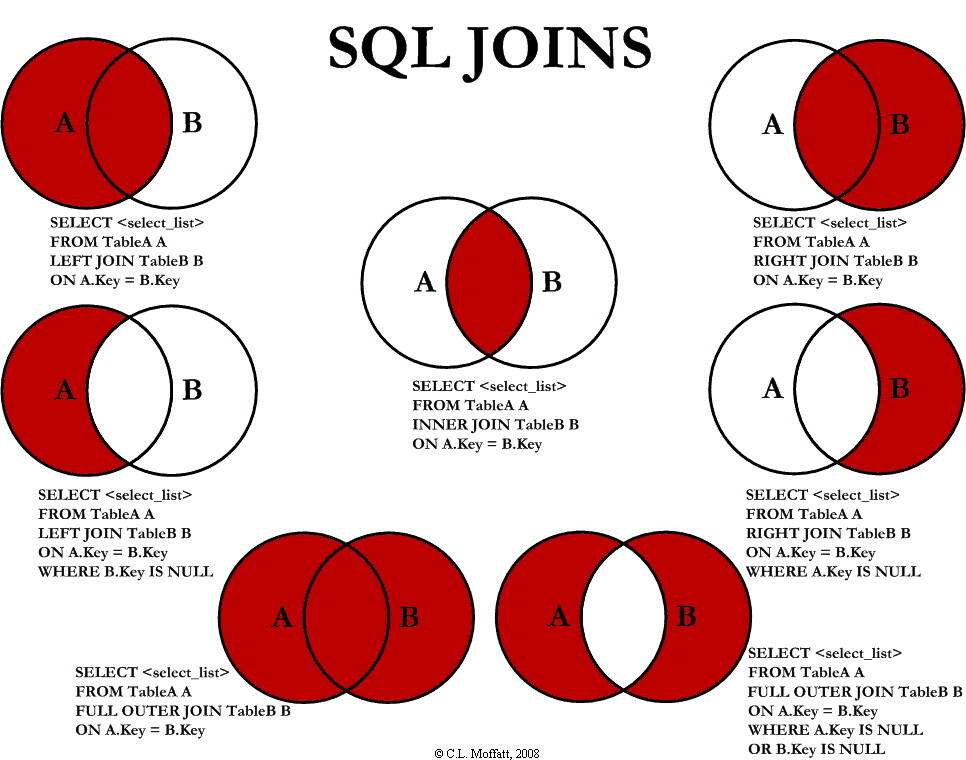
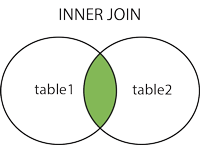
inner join 交集
SELECT column_name(s)
FROM table1
INNER JOIN table2
ON table1.column_name=table2.column_name;
- columns:要显示的列名。
- table1:表1的名称。
- table2:表2的名称。
- column_name:表中用于连接的列名。
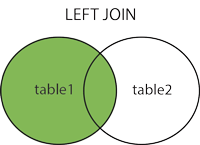
left jion(右表没有也会记录) A全部 B没有对应null
SELECT column_name(s)
FROM table1
LEFT JOIN table2
ON table1.column_name=table2.column_name;
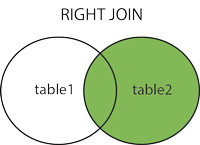
right join 右连 B全部,A没有的对应null
SELECT column_name(s)
FROM table1
RIGHT OUTER JOIN table2
ON table1.column_name=table2.column_name;
full outer join 并集
SELECT column_name(s)
FROM table1
FULL OUTER JOIN table2
ON table1.column_name=table2.column_name;
union
默认不允许重复
union all(可重复)
合并两个或多个select每个select语句需要拥有相同数量的列,列也必须拥有相同数据类型
select into
从一个表复制数据,然后把数据插入另一个新表中
用于拷贝表结构和数据
CREATE TABLE 新表
AS
SELECT * FROM 旧表
SELECT * 或某一列
INTO newtable [IN externaldb]
FROM table1;
insert into select
从一个表复制数据,然后把数据插入到一个已存在的表中。目标表中任何已存在的行都不会受影响。
else
- create database
- create table
constraints (约束)
-
添加 add 撤销 drop/alter
-
column_name3 data_type(size) constraint_name,
NOT NULL
- 指示某列不能存储 NULL 值。
- 添加 modify xx int not null
- 删除 modify xx int null
UNIQUE
- 保证某列的每行必须有唯一的值。
- 添加 add
- 撤销 drop
PRIMARY KEY
- NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。
- 添加add 撤销 drop
FOREIGN KEY
- 保证一个表中的数据匹配另一个表中的值的参照完整性。
- 添加 add 撤销 drop
CHECK
- 保证列中的值符合指定的条件。check(a>0 and/or b=‘a’)
- 添加 add 撤销 drop
DEFAULT
- 规定没有给列赋值时的默认值。
- 每个添加方式不同
- mysql alter
- sql/ms add
- oracle modify
- 撤销
- mysql alter
- sql alter
index
在不读取整表时,可快速查找数据,常用的加索引就好
-
CREATE INDEX index_name
ON table_name (column_name) -
CREATE UNIQUE INDEX index_name
ON table_name (column_name) -
drop撤销
alter table
在已有表中添加或删除修改列v(语法与环境有关)
auto increment
在新记录插入表中时生成唯一的数字(语法与环境有关)
视图 views
可视化表格
Date 函数SQL Server 和 MySQL 中的 Date 函数 | 菜鸟教程 (runoob.com)
mysql
| 函数 | 描述 |
|---|---|
| NOW() | 返回当前的日期和时间 |
| CURDATE() | 返回当前的日期 |
| CURTIME() | 返回当前的时间 |
| DATE() | 提取日期或日期/时间表达式的日期部分 |
| EXTRACT() | 返回日期/时间的单独部分 |
| DATE_ADD() | 向日期添加指定的时间间隔 |
| DATE_SUB() | 从日期减去指定的时间间隔 |
| DATEDIFF() | 返回两个日期之间的天数 |
| DATE_FORMAT() | 用不同的格式显示日期/时间 |
sql
| 函数 | 描述 |
|---|---|
| GETDATE() | 返回当前的日期和时间 |
| DATEPART() | 返回日期/时间的单独部分 |
| DATEADD() | 在日期中添加或减去指定的时间间隔 |
| DATEDIFF() | 返回两个日期之间的时间 |
| CONVERT() | 用不同的格式显示日期/时间 |
null 函数
- is null null值
- is not null 非null值
- null ≠ 0
- SQL ISNULL()、NVL()、IFNULL() 和 COALESCE() 函数 | 菜鸟教程 (runoob.com)
sql通用数据类型
| 数据类型 | 描述 |
|---|---|
| CHARACTER(n) | 字符/字符串。固定长度 n。 |
| VARCHAR(n) 或 CHARACTER VARYING(n) | 字符/字符串。可变长度。最大长度 n。 |
| BINARY(n) | 二进制串。固定长度 n。 |
| BOOLEAN | 存储 TRUE 或 FALSE 值 |
| VARBINARY(n) 或 BINARY VARYING(n) | 二进制串。可变长度。最大长度 n。 |
| INTEGER§ | 整数值(没有小数点)。精度 p。 |
| SMALLINT | 整数值(没有小数点)。精度 5。 |
| INTEGER | 整数值(没有小数点)。精度 10。 |
| BIGINT | 整数值(没有小数点)。精度 19。 |
| DECIMAL(p,s) | 精确数值,精度 p,小数点后位数 s。例如:decimal(5,2) 是一个小数点前有 3 位数,小数点后有 2 位数的数字。 |
| NUMERIC(p,s) | 精确数值,精度 p,小数点后位数 s。(与 DECIMAL 相同) |
| FLOAT§ | 近似数值,尾数精度 p。一个采用以 10 为基数的指数计数法的浮点数。该类型的 size 参数由一个指定最小精度的单一数字组成。 |
| REAL | 近似数值,尾数精度 7。 |
| FLOAT | 近似数值,尾数精度 16。 |
| DOUBLE PRECISION | 近似数值,尾数精度 16。 |
| DATE | 存储年、月、日的值。 |
| TIME | 存储小时、分、秒的值。 |
| TIMESTAMP | 存储年、月、日、小时、分、秒的值。 |
| INTERVAL | 由一些整数字段组成,代表一段时间,取决于区间的类型。 |
| ARRAY | 元素的固定长度的有序集合 |
| MULTISET | 元素的可变长度的无序集合 |
| XML | 存储 XML 数据 |
| 数据类型 | Access | SQLServer | Oracle | MySQL | PostgreSQL |
|---|---|---|---|---|---|
| boolean | Yes/No | Bit | Byte | N/A | Boolean |
| integer | Number (integer) | Int | Number | Int Integer | Int Integer |
| float | Number (single) | Float Real | Number | Float | Numeric |
| currency | Currency | Money | N/A | N/A | Money |
| string (fixed) | N/A | Char | Char | Char | Char |
| string (variable) | Text (<256) Memo (65k+) | Varchar | Varchar Varchar2 | Varchar | Varchar |
| binary object | OLE Object Memo | Binary (fixed up to 8K) Varbinary (<8K) Image (<2GB) | Long Raw | Blob Text | Binary Varbinary |
sql函数
Aggregate 函数
从列中取得的值,返回一个单一的值
- AVG() - 返回平均值
- COUNT() - 返回这一列中符合count(内容)内容的行数
- FIRST() - 返回第一个记录的值(仅ms可用)
- sql top1 order by asc
- mysql order by asc limit1
- oraclr order by asc where xx<=1
- LAST() - 返回最后一个记录的值(仅ms可用)
- sql top1 order by decs
- mysql order by desc limit1
- oraclr order by desc where xx<=1
- MAX() - 返回指定列最大值
- MIN() - 返回指定列最小值
- SUM() - 返回指定列总和
group by
可结合聚合函数使用,根据一个或多个列对结果集进行分组
having
where 无法和聚合一起使用,HAVING 子句可以让我们筛选分组后的各组数据。
exists运算符
判断查询子句是否有记录,如果有一条或多条记录存在返回 True,否则返回 False。
SELECT Websites.name, Websites.url
FROM Websites
WHERE EXISTS (SELECT count FROM access_log WHERE Websites.id = access_log.site_id AND count > 200);
Scalar函数
基于输入的值,返回一个单一的值
-
UCASE() - 将某个字段转换为大写
-
LCASE() - 将某个字段转换为小写
-
MID() - 从某个文本字段提取字符,MySql 中使用
-
SELECT MID(column_name,start[,length]) FROM table_name;
-
参数 描述 column_name 必需。要提取字符的字段。 start 必需。规定开始位置(起始值是 1)。 length 可选。要返回的字符数。如果省略,则 MID() 函数返回剩余文本。
-
-
SubString(字段,1,end) - 从某个文本字段提取字符
-
LEN() - 返回某个文本字段的长度
-
mysql SELECT LENGTH(column_name) FROM table_name; -
sql SELECT LEN(column_name) FROM table_name;
-
-
ROUND() - 对某个数值字段进行指定小数位数的四舍五入
- mysql> SELECT ROUND(1.298, 1);
-> 1.3 - mysql> SELECT ROUND(1.298, 0);
-> 1
- mysql> SELECT ROUND(1.298, 1);
-
NOW() - 返回当前的系统日期和时间
-
FORMAT() - 格式化某个字段的显示方式
| SQL 语句 | 语法 |
|---|---|
| AND / OR | SELECT column_name(s) FROM table_name WHERE condition AND|OR condition |
| ALTER TABLE | ALTER TABLE table_name ADD column_name datatypeorALTER TABLE table_name DROP COLUMN column_name |
| AS (alias) | SELECT column_name AS column_alias FROM table_nameorSELECT column_name FROM table_name AS table_alias |
| BETWEEN | SELECT column_name(s) FROM table_name WHERE column_name BETWEEN value1 AND value2 |
| CREATE DATABASE | CREATE DATABASE database_name |
| CREATE TABLE | CREATE TABLE table_name ( column_name1 data_type, column_name2 data_type, column_name2 data_type, … ) |
| CREATE INDEX | CREATE INDEX index_name ON table_name (column_name)orCREATE UNIQUE INDEX index_name ON table_name (column_name) |
| CREATE VIEW | CREATE VIEW view_name AS SELECT column_name(s) FROM table_name WHERE condition |
| DELETE | DELETE FROM table_name WHERE some_column=some_valueorDELETE FROM table_name (Note: Deletes the entire table!!)DELETE * FROM table_name (Note: Deletes the entire table!!) |
| DROP DATABASE | DROP DATABASE database_name |
| DROP INDEX | DROP INDEX table_name.index_name (SQL Server) DROP INDEX index_name ON table_name (MS Access) DROP INDEX index_name (DB2/Oracle) ALTER TABLE table_name DROP INDEX index_name (MySQL) |
| DROP TABLE | DROP TABLE table_name |
| GROUP BY | SELECT column_name, aggregate_function(column_name) FROM table_name WHERE column_name operator value GROUP BY column_name |
| HAVING | SELECT column_name, aggregate_function(column_name) FROM table_name WHERE column_name operator value GROUP BY column_name HAVING aggregate_function(column_name) operator value |
| IN | SELECT column_name(s) FROM table_name WHERE column_name IN (value1,value2,…) |
| INSERT INTO | INSERT INTO table_name VALUES (value1, value2, value3,…)orINSERT INTO table_name (column1, column2, column3,…) VALUES (value1, value2, value3,…) |
| INNER JOIN | SELECT column_name(s) FROM table_name1 INNER JOIN table_name2 ON table_name1.column_name=table_name2.column_name |
| LEFT JOIN | SELECT column_name(s) FROM table_name1 LEFT JOIN table_name2 ON table_name1.column_name=table_name2.column_name |
| RIGHT JOIN | SELECT column_name(s) FROM table_name1 RIGHT JOIN table_name2 ON table_name1.column_name=table_name2.column_name |
| FULL JOIN | SELECT column_name(s) FROM table_name1 FULL JOIN table_name2 ON table_name1.column_name=table_name2.column_name |
| LIKE | SELECT column_name(s) FROM table_name WHERE column_name LIKE pattern |
| ORDER BY | SELECT column_name(s) FROM table_name ORDER BY column_name [ASC|DESC] |
| SELECT | SELECT column_name(s) FROM table_name |
| SELECT * | SELECT * FROM table_name |
| SELECT DISTINCT | SELECT DISTINCT column_name(s) FROM table_name |
| SELECT INTO | SELECT * INTO new_table_name [IN externaldatabase] FROM old_table_nameorSELECT column_name(s) INTO new_table_name [IN externaldatabase] FROM old_table_name |
| SELECT TOP | SELECT TOP number|percent column_name(s) FROM table_name |
| TRUNCATE TABLE | TRUNCATE TABLE table_name |
| UNION | SELECT column_name(s) FROM table_name1 UNION SELECT column_name(s) FROM table_name2 |
| UNION ALL | SELECT column_name(s) FROM table_name1 UNION ALL SELECT column_name(s) FROM table_name2 |
| UPDATE | UPDATE table_name SET column1=value, column2=value,… WHERE some_column=some_value |
| WHERE | SELECT column_name(s) FROM table_name WHERE column_name operator value |