基于dbt的机器学习:流畅的过程衔接
DBT 继承了我们在 SQL 上的工作,在数据工程师、数据分析工程师和任何数据角色之间构建了一个优雅、通用的、操作友好的环境。工具和工作流的统一在数据组织内为不同团队之间创建了互操作性。
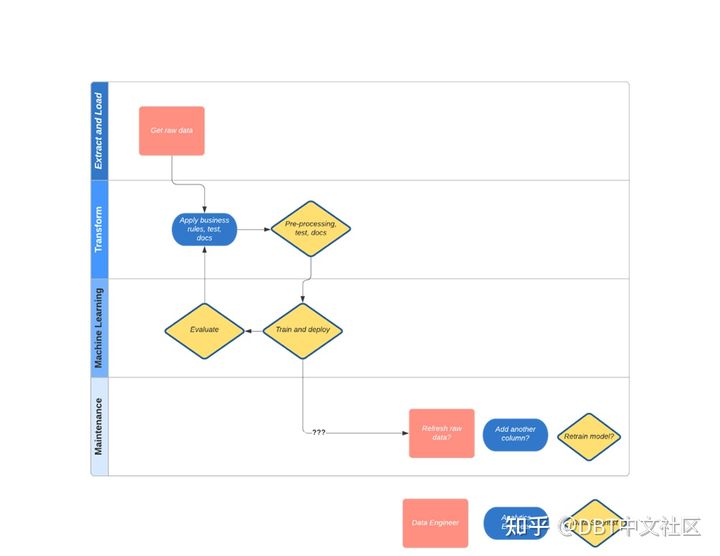
就像在接力赛中一样,在过程的各个阶段都有明确的交接点和明确的所有权。但截止目前,还有一个环节仍然痛苦且不确定:机器学习(ML)工程师和数据分析工程师之间的衔接。
根据我的经验,ML工程和数据分析工程之间的初始协作工作流程开始时很强大,但最终在维护阶段变得混乱。这最终导致项目变得无法使用和被遗忘。
在本文中,我们将探讨 ML 工程和数据分析工程之间的现实接力棒,并强调哪里容易出问题。ML工程和数据分析工程工作流程中存在所有权问题。幸运的是,现代数据堆栈MDS使接力棒传递更加顺畅。这篇文章将引导您完成最近的一个项目,在那里我能够亲眼看到这些系统如何协同工作,以提供为长期准确性和可维护性而构建的模型。
一、以前的工作衔接是什么样子的?
作为一名数据分析工程师,我与一位 ML 工程师配对,以分析确定公司客户流失趋势,以及我们可以采取哪些措施来防止这种情况。我们努力寻找一个解决方案,并向客户业务主管展示,1 个月后我们满怀希望完成了方案,但最新的数据更改导致模型漂移,因此 ML 工程师找到一些问题供数据工程师/数据分析工程师修复...循环往复,3个月后,没有人记得我们这样做了。这听起来熟悉吗?
发生这种情况是因为“正常”的做事方式缺乏长期和明确的所有权。但是这些故障是如何发生的呢?
事情是这样的
经过一些初步规划,我知道我们将这些原始数据存在于数据仓库,我们共同努力的这个起点很容易理解。我编写了 dbt 转换来调整这些原始数据并加入了几个表一起基于对重要变量的直觉:每日活跃使用情况、用户数量、支付金额、历史使用情况等。
ML工程师从这里介入。她习惯于在Python、 pandas和scikit-learn中进行统计和预处理。在她打开她的Jupyter Notebook之前,我们进行了一次对话,意识到可以通过dbt完成相同的工作。预处理可以通过这个开源dbt包dbt-ml-preprocessing来完成。
ML 工程师完成了预处理步骤(想想:one-hot encoding, feature scaling, imputation)。她使用 SQL 将 dbt 模型(表)读入 Jupyter Notebook以执行模型训练。在迭代机器学习模型和跟踪模型拟合(想想:AUC/Precision/Recall (用于分类))之后,她在 dbt 创建的表上运行模型,并将预测结果作为数据库中的表输出。为了保持文档整洁,她在 dbt 项目中配置了一个源来反映此预测结果表。它并不直观,但比将其排除在 dbt 文档之外要好。
最后,她在此表的顶部创建了一个仪表板,以向最终用户宣传模型随时间推移的准确性。为了安排这个,我们去找数据工程师,每天早上8点在Airflow中将上述内容串在一起,并完成。
过程哪里出了问题
让我们分析一下我们在故事中看到的待完成的工作。
| 要完成的工作 | 预期成果 | 角色 |
| 提取原始数据并将其加载到数据库中 | SQL 就绪数据 | 数据工程师 |
| 转换数据以供业务用户使用 | 数据是连贯的,可以从中做出决策 | 分析工程师、机器学习工程师 |
| 使用结构化的表格数据 | 统一实用的工作流程 | 分析工程师、机器学习工程师 |
| 在 SQL 中工作 | 统一实用的工作流程 | 分析工程师、机器学习工程师 |
| 为用户提供文档,以了解数据输出是如何创建的以及如何使用它们 | 数据的信任和上下文 | 分析工程师、机器学习工程师 |
| 测试转换后的数据输出 | 可信数据 | 分析工程师 |
| 测试预处理数据输出 | 可信数据 | 机器学习工程师 |
| 训练和部署机器学习模型(主要使用 python) | 做出预测性决策 | 机器学习工程师 |
| 随时间推移测试和维护机器学习表输出 | 证明预测结果与现实相符,即使数据输入随时间变化 | 数据工程师、分析工程师、机器学习工程师??? |
接力棒随着时间的推移而发展,需求分析和叙事是数据分析工程师和ML工程师引以为豪的容易达成共识的事情,但机器学习输出工作流的维护和验证是我们并不引以为豪的事情。发生这种情况是因为我们错过了一些关键的东西:从长远来看,我们没有统一谁应该做什么(想想:源数据变化通过转换>预处理>训练步骤级联>监控性能。难怪最终用户在 1 个月后对我们的结果耸了耸肩。
让我们把这个简单化:
- “当数据发生变化时,谁使数据和机器学习管道随着时间的推移可维护?”
如果我们把这个问题做好了,机器学习投入适用将变得更容易。
二、技术发展如何弥合数据分析工程和机器学习之间的差距?
让我们进一步关注这个问题:对于工作流程中的“随时间推移的维护”问题,
ML 模型漂移是由数据质量还是模型逻辑引起的?
将机器学习引入 SQL 工作流
如果。。。SQL可以做的比我们认为的更多,甚至应该做的更多?
- http://mindsdb.com:MindsDB是使用SQL语法创建预测模型的基于数据库之上的开源产品,机器学习计算发生在MindsDB层。
- Continual.ai:直接创建 dbt 模型来预测结果。根据您的 dbt 模型配置评估要使用的 ML 模型,机器学习计算发生在这一层和数据仓库中。
- fal.ai:fal使 dbt 和 python 可互操作。
这将如何改变我的故事?
数据分析工程师和ML工程师会在SQL上更加团结。无论长管道在何处破裂(ELT-ML),SQL将是我们一起找出问题的切入点。对于简单的机器学习问题(例如,线性回归,分类),在ML工程师的建议和审查下,数据分析工程师会更容易理解甚至拥有完整的管道。
除了在出现问题后解决问题之外,此工作流还将避免构建 ML 运维工作所涉及的大部分复杂性:大量额外的基础设施(想想: python 代码在哪里运行?)作为一名 ML 工程师,我希望生活在一个可以从一个控制平面管理探索、训练、版本控制和推理的世界里。在数仓内进行机器学习有可能使之成为现实。

数据分析工程师和ML工程师将在整个工作流程的同一个dbt项目中工作,而不仅仅是其中的一部分。我们会将 python 脚本与 dbt 配置对齐,以获得更好的谱系。
当事情出错时,弄清楚SQL更改如何通知python更改,反之亦然。不需要关心python代码在哪个基础设施上运行。将机器学习逻辑与 dbt 逻辑保持一致会更容易。