Hadoop基础介绍
Hadoop基础介绍
- 一、总体介绍
- 二、HDFS架构
- 三、MapReduce结构
- 四、YARN架构
一、总体介绍
1、定义:
是一个开源的、可靠的、可扩展的分布式计算框架。
2、用途:
(1)数据仓库
(2)PB级别数据的存储与处理。
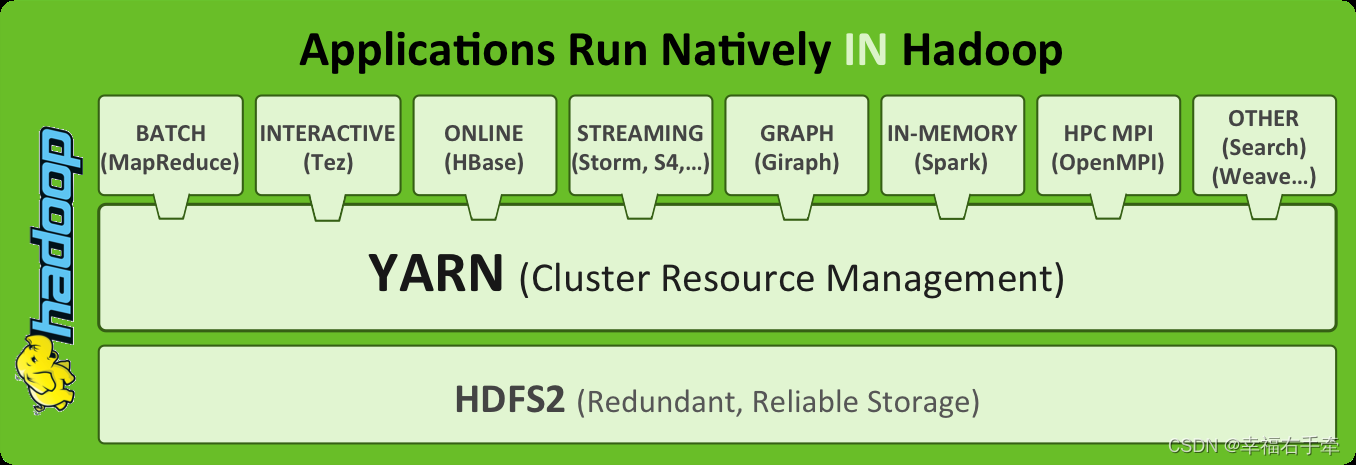
3、核心组件
(1)HDFS:解决分布式存储,包括数据切分和多副本两部分。
(2)Map Reduce:解决分布式计算,Map:分,Reduce:合。既是分布式框架,又是编程模型。
(3)YARN:通用资源管理系统,实现资源管理、调度。
二、HDFS架构
1、结构:
Master-slave结构,NameNode带DataNode。
2、NameNode:
负责客户端请求的相应;负责元数据(数据的属性描述信息)的管理;监控DataNode健康状况。使用zookeeper实现高可用。
3、DataNode:
存储数据存储;要定期发送信息,汇报自身健康状况。
4、client:
负责数据拆分,默认为128MB,冗余3份。
5、优缺点:
优点:数据冗余;适合大文件存储;处理流式数据;可在廉价机器上构建。
缺点:无法实时运算;不适合小文件存储。
6、HDFS的高可用:
数据存储故障容错、磁盘故障容错、DataNode故障容错、NameNode故障容错。
三、MapReduce结构
1、优缺点:
优点:海量数据的离线处理;易开发。
缺点:无法进行实时的流式计算,比较慢。
2、结构:
分为Map和Reduce两个阶段,通过Hadoop streaming编程,编程时需要分别实现mapper和reducer脚本,可以通过mrjob包编辑python脚本实现MapReduce操作。
3、流程:
准备MapReduce的输入数据;准备Mapper数据,实现map接口,进行Map操作,将数据下发到节点;Shuffle;Reduce处理,实现reduce接口,汇总map阶段的结果;结果输出。
4、MapReduce慢的原因:
数据会频繁的在磁盘和内存中进行IO操作。
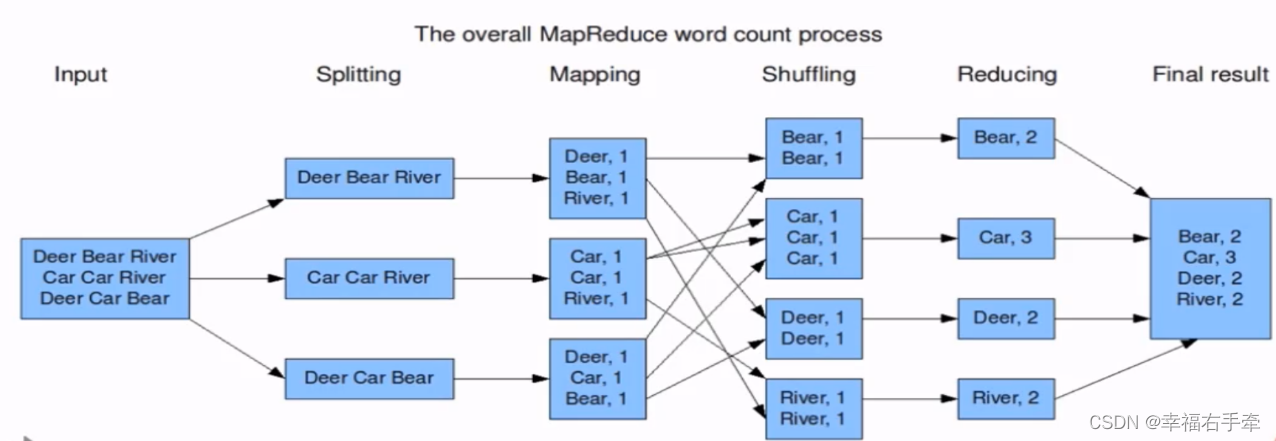
MapReduce的执行流程
四、YARN架构
1、作用:
资源管理工具,协调多个框架共同访问HDFS集群资源。
2、架构:
(1)ResourceManager:RM资源管理器,整个集群同一时间提供服务的RM只有一个。负责集群资源的统一管理和调度;处理客户端请求,submit和kill;监控NM;响应AM请求。
(2)NodeManager:NM节点管理器,整个集群中有多个,负责本身节点资源的管理;定时向RM汇报本节点资源使用情况;接收并处理RM的命令,启动Container运行task ;处理AM命令。
(3)ApplicationMaster:AM,每个应用程序对应一个MR、Spark,负责应用程序的管理;向RM申请资源;与NM通信,分发task,启动/停止task,task运行在container中,AM也运行在container中。
(4)Container:容器,是一个任务运行环境的抽象,封装CPU、内存等资源。
(5)Client:提交、查询、杀死task。
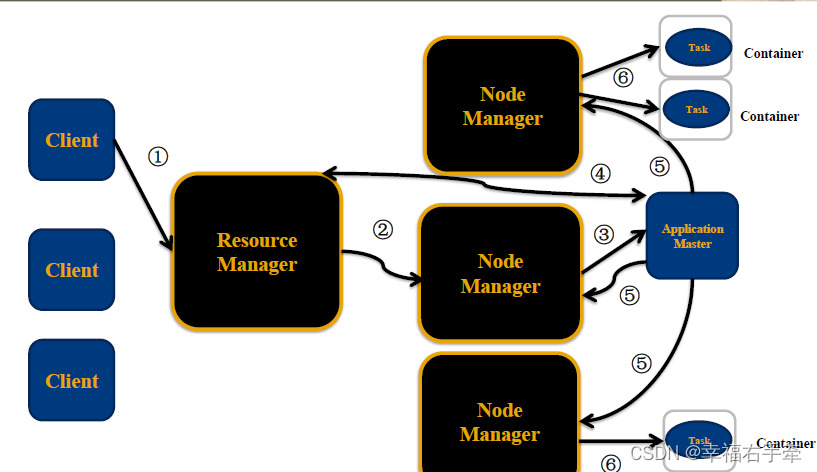
YARN管理调度示意
3、步骤:
(1)Client提交作业请求。
(2)ResourceManager进程和NodeManager进程通信,根据集群资源,为用户程序分配第一个Container(容器),并将 ApplicationMaster分发到这个容器上面。
(3)在启动的Container中创建ApplicationMaster。
(4)ApplicationMaster启动后向ResourceManager注册进程,申请资源。
(5)ApplicationMaster申请到资源后,向对应的NodeManager申请启动Container,将要执行的程序分发到NodeManager上。
(6)Container启动后,执行对应的任务。
(7)Tast执行完毕之后,向ApplicationMaster返回结果。
(8)ApplicationMaster向ResourceManager汇报任务结束,请求kill。