一文看懂多模态大型语言模型GPT-4
文章目录
- 前言
- 什么是GPT-4
- GPT-4 VS GPT-3.5
- GPT-4与其他模型对比
- GPT-4视觉输入
- GPT-4局限性
- 写在最后
前言
近日,OpenAI发布了最新版的生成预训练模型GPT-4。据官方介绍,最新一代的模型是一个大模型,性能比CPT-3.5强悍很多,不仅仅是接受图像、文本、代码等的输入输出,更多的是在很多专业领域表现出人类的水准水;与上一代不同的是它的核心技术是基于Transformer的自回归语言模型,使用了大量的无标注数据进行预训练,学习了自然语言和其他模态之间的通用表示和关系。那么,今天我们就要一探究竟。
什么是GPT-4
GPT-4是OpenAI公司3月推出的新一代人工智能预训练AI模型,是一个多模态大型语言模型,使用了1.5万亿个参数,是GPT-3.5的10倍之多,当然它也是世界上最大的人工智能模型。

据官方所述GPT-4是OpenAI在扩大深度学习方面的最新里程碑,是一个大型多模态模型(接受图像和文本输入,发出文本输出),虽然在许多现实世界场景中的能力不如人类,但在各种专业和学术基准上表现出人类水平的性能。例如,它通过了模拟律师考试,分数在前10%左右;相比之下,GPT-3.5的得分在10%左右。我们花了6个月的时间,利用我们对抗性测试计划和ChatGPT的经验教训,反复调整GPT-4,在真实性、可操纵性和拒绝走出护栏方面取得了有史以来最好的结果。足以证明GPT-4简直就是人工智能预训练模型中的劳斯奈斯,简直牛得不要不要的。
GPT-4 VS GPT-3.5
官方文档说GPT-3.5和GPT-4之间的区别可能很小,但是当任务的复杂性达到足够的阈值时,差异就会显现出来——GPT-4比GPT-3.5更可靠、更具创造力,并且能够处理更细微的指令。
官方为了比较这两个模型之间的差异,在各种基准上进行了测试,包括最初为人类设计的模拟考试,以及最新的公开考试(在奥运会和AP免费回答问题的情况下),或者购买了2022年至2023年的练习考试。在测试过程中并没有对这些考试进行专门的培训,如下图所示,在这些偏向人类独立思考的考试中,GPT-4比GPT-3.5更加的可靠和更欧创造力。
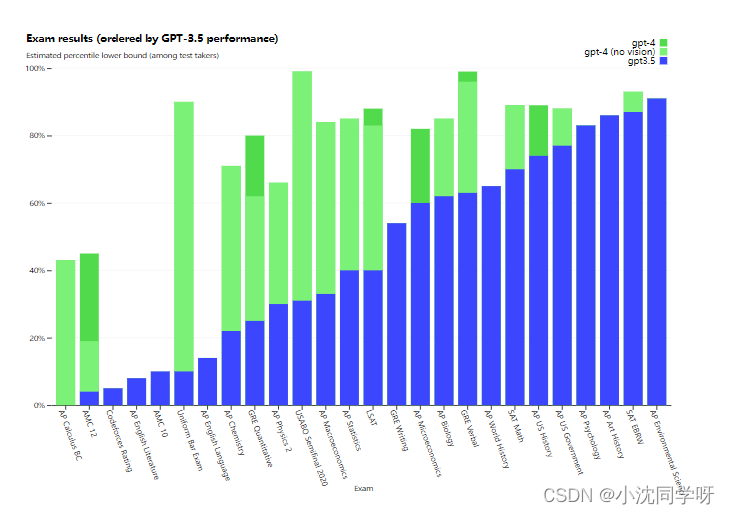
GPT-4与其他模型对比
OpenAI为机器学习模型设计的传统基准上评估了GPT-4,GPT-4大大优于现有的大型语言模型,以及大多数最先进的(SOTA)模型,这些模型可能包括特定于基准的手工制作或额外的训练协议。

在测试的26种语言中的24种中,GPT-4的英语性能优于GPT-3.5和其他LLM(Chinchilla、PaLM),包括拉脱维亚语、威尔士语和斯瓦希里语等低资源语言。

GPT-4视觉输入
GPT-4可以接受文本和图像的提示,这与纯文本设置平行,允许用户指定任何视觉或语言任务。具体来说,它生成由穿插的文本和图像组成的给定输入的文本输出(自然语言、代码等)。在一系列领域,包括带有文本和照片的文档、图表或屏幕截图,GPT-4表现出与纯文本输入类似的功能。此外,它可以通过为纯文本语言模型开发的测试时技术进行扩展,包括少量镜头和思维链提示。图像输入仍然是一个研究预览,暂时并未对公众公开。

GPT-4局限性
尽管GPT-4具有功能,但它与早期的GPT模型具有类似的局限性。最重要的是,它仍然不是完全可靠的(它会“幻觉”事实并犯推理错误)。在使用语言模型输出时,特别是在高风险的上下文中,应该非常小心,因为确切的协议(如人工审查、以额外的上下文为基础或完全避免高风险的使用)与特定用例的需求相匹配。
虽然GPT-4仍然存在问题,但与之前的模型相比,它显著减少了幻觉。在官方的内部对抗性事实评估中,GPT-4的得分比最新的GPT-3.5高40%:
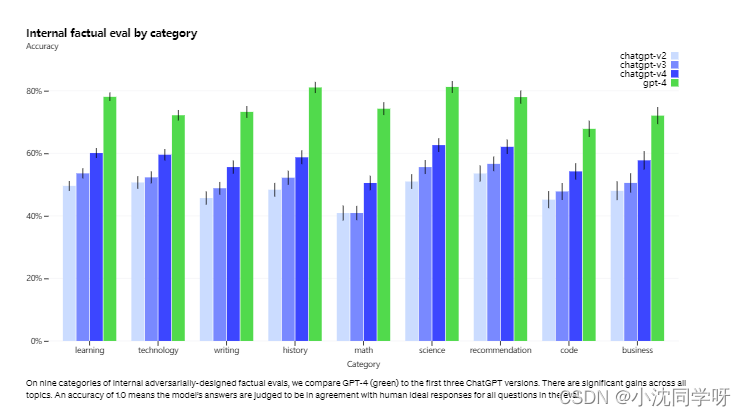
写在最后
GPT-4应该算得上是至今为止最为强大的人工智能预训练模型,无论是性能上、可靠性以及创造力都较GPT-3.5有较大提升。特别是最新的视觉输入功能,模型可以根据图片视觉分析并给出自己独立的答案,这可以算得上人工智能方向的一个新里程碑。虽然很强悍,但GPT-4还是有早期模型类似的局限性。所以,GPT-4之后的路还很长呀!
路漫漫其修远兮,吾将上下而求索
有兴趣的小伙伴也可以加我:
订阅号 ‘架构集结号’
知识星球 ‘Coding社区’