量化注意事项和模型设计思想
量化的注意事项
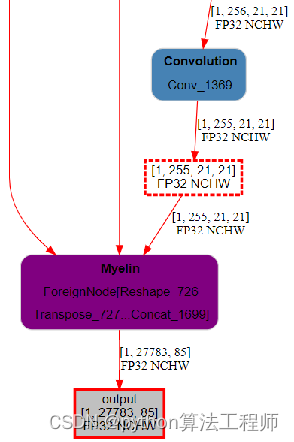
1、量化检测器时,尽量不要对Detect Head进行量化,一旦进行量化可能会引起比较大的量化误差;
2、量化模型时,模型的First&Second Layer也尽可能不进行量化(精度损失具有随机性);
3、TensorRT只支持对称量化,因此Zero-Point为0;
4、PTQ的结果一般比TensorRT的结果好,同时更具有灵活性,可以进行局部量化(因为TensorRT时性能优先);
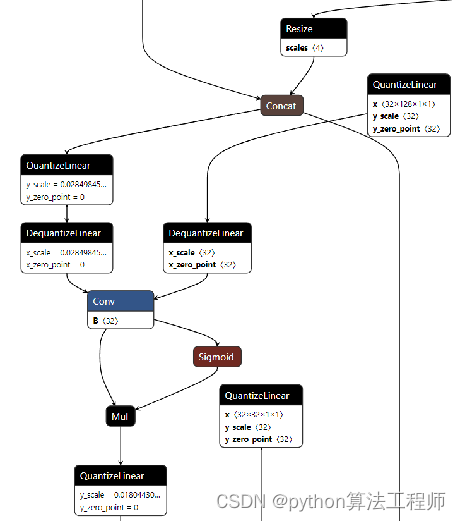
5、Resize和add操作可能会引入混合精度节点,这可能也是后面TensorRT改进和优化的点;
6、激活函数的量化对精度没有影响(ReLU/ReLU6等),因此使用per_tensor粗粒度量化即可;
7、随机量化并不能提高精度;
8、量化粒度越细精度越高,相应计算复杂度也就越高,速度越慢;一般使用per_channels即可;
9、Depth-wise Conv可能会破坏截断误差与舍入误差的平衡,进而影响精度;
10、BN层与Conv的融合可能会对per_tensor量化有所影响,但是对于per_channel没有影响;
11、MobileNet系列中的深度可分离卷积的量化误差比较大,需要进行局部量化;
12、卷积/转置卷积的量化选择per_tensor与per_channel均可。
13、参数量大的网络模型对于量化加速更加鲁棒;
14、非对称的per_channel量化能够提高精度(TensorRT不支持,其他框架支持);
15、语义分割一般PTQ即可满足量化精度的要求,因为本质是逐像素分类;
16、pytorch-quantization本身的initialize不建议使用,最好使用本次实践中的方法更为灵活;
17、多分支结构并不利于QAT的训练,QAT办法缓解PTQ的精度丢失。
模型的设计原则
1、模型涉及和改进避免多分支结构,如果项目中使用了多分支结构,建议使用结构重参思想;
2、如果使用了结构重参,同时PTQ不能满足要求,QAT也不能缓解,建议使用梯度先验的形式RepOpt;
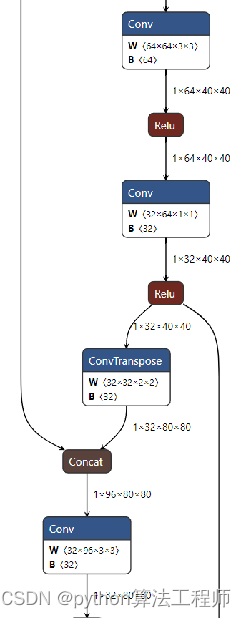
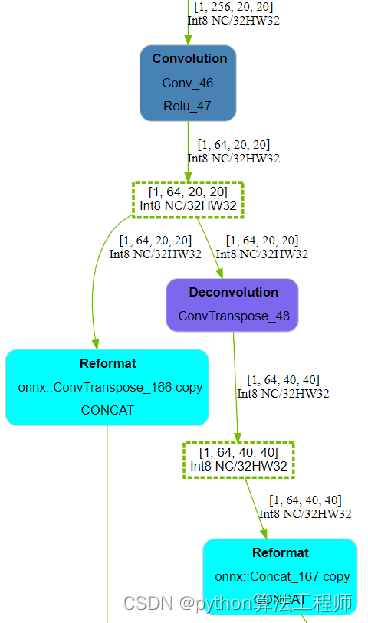
3、YOLOv6中的上采样使用TransposeConv比YOLOv5中使用的Upsample更适合进行量化,因为使用Upsample在转为Engine的时候,TensorRT会模型将其转为混合精度的Resize,影响性能;
4、在自己设计Block的时候,应该更多考虑Block中的算子尽可能进行算子融合,YOLOv6这方面就是典范,值得多多学习。
5、如果模型中涉及到Plugin,使用局部量化跳过该层即可;
检测头与ADD

nn.Upsample
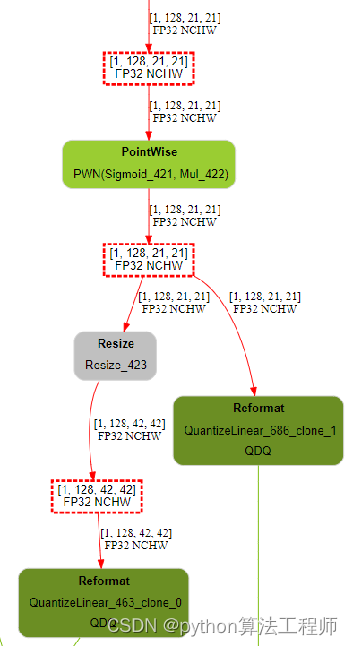
转置卷积