Linux小黑板(14):基于环形队列的生成消费者模型

"多少人都,生来纯洁完美,心底从不染漆黑。"
我们先来瞅瞅我们之前基于阻塞队列的生产消费者模型代码。
void Push(const T& in)
{
// 生产任务
pthread_mutex_lock(&_mutex);
while(is_full()){
pthread_cond_wait(&_pcond,&_mutex);
}
// 走到这里说明 正常生产
_q.push(in);
// 生成后 唤醒消费者 可以来消费了
pthread_cond_signal(&_ccond);
pthread_mutex_unlock(&_mutex);
}这有什么问题嘛? 唔,也许没什么问题。难道是存在并发安全? 当然不是!

每一个线程进入在操作临界资源的时候,这个临界资源必须是满足一定条件的。可是,公共资源是否 满足生产、消费条件。
即我们观察该阻塞队列是否为满或者是否为空?我们事先(线程加锁前)是无法得知的。 反而,当我们要进行条件检测时,需要先加锁,再检测(本质也是在访问临界资源),再操作,再解锁。
由此,如果有一种变量或者方法,能够支持我们事先就知道临界资源的使用情况(即条件是否满足),而不是加锁,检测,等待释放锁……,免去这些对性能造成影响的不必要步骤,那就太好了。
本篇的主题,就是为了来谈谈一个维护同步机制的技术——信号量。
---前言
一、信号量
什么是信号量呢?这个就很模糊了。
信号量(Semaphore),是在多线程环境下使用的一种设施,是可以用来保证两个或多个关键代码段不被并发调用。在进入一个关键代码段之前,线程必须获取一个信号量;一旦该关键代码段完成了,那么该线程必须释放信号量。其它想进入该关键代码段的线程必须等待直到第一个线程释放信号量。
取自这里
以下是我的操作系统教材的解释:
信号量是一种特殊的变量,它用来表示系统中资源的使用情况。
似乎第二段的描述更简化,于是乎有那么一丢丢得理解了,但是这太宏观了。在Llinux中有两套信号量标准,分别是SystemV信号量 与 POSIX信号量。它们之间的区别很大部分在于:
System V信号量 通常在于进程间通信,维护进程同步。
POSIX 信号量常常用作维护线程同步。
(1)POSIX信号量是什么?
这里也就先不卖关子了。
①信号量的本质是一个计数器; ---> 表示系统资源的使用情况,衡量临界资源数量的多少
②对于信号量的操作叫 P() V()操作。
如何理解信号量?
只要拥有信号量,那就决定了,你在未来一定拥有临界资源的一部分。申请信号量的本质,就是对临界资源小块中的 "预定" 机制。就像我们线上购买影院票,不是我到线下坐到影院坐凳上,才表示我在一段时间内,拥有对该凳子的使用权,而是向售票app预定 "座位号" ,一旦成功,就表名你一定能在未来,拥有对该临界资源的使用权。
如何理解信号量P、V操作?
线程需要访问临界资源中的某一个区域,首先需要先 申请信号量 !要先申请信号量,那么所有人都需要看到这个信号量!那么这个信号量本身一定是一个共享资源。
我们又说,信号量的本质就是一个计数器。那么它必然伴随着 递减(--) 或者 递增(++)的操作。
sem--: 说明该临界资源变少,说明已经被申请拿走一部份了 ---> "申请资源" ---> P
sem++: 说明该临界资源增多了,说明一部分资源已经被归还了 ---> "释放资源" ---> V
它是共享资源,它需不需要被保护呢?当然需要,因此 对信号量的++、--的操作一定是原子的。 信号量操作核心又称作是: PV原语。
(2)POSIX信号量相关操作
初始化和销毁:
#include <semaphore.h>
int sem_init(sem_t *sem, int pshared, unsigned int value);
#include <semaphore.h>
int sem_destroy(sem_t *sem);
//Return Val
sem_init() returns 0 on success; on error, -1 is returned, and errno is set to indicate the error.
sem_destroy() returns 0 on success; on error, -1 is returned, and errno is set to indicate the error.pshared:0表示线程间共享,非零表示进程间共享
value:信号量初始值
P(申请)V(释放)信号量:
#include <semaphore.h>
int sem_wait(sem_t *sem);
#include <semaphore.h>
int sem_post(sem_t *sem);
//Return Val
sem_wait() functions return 0 on success; on error, the value of the semaphore is left
unchanged, -1 is returned, and errno is set to indicate the error.
sem_post() returns 0 on success; on error, the value of the semaphore is left unchanged, -1 is returned, and errno is set to indicate the error.
函数的使用没啥可讲的。我们借此,可以来实现基于环形队列的生产消费者模型了。
二、环形队列的生产消费者模型
什么是环形队列呢?这是一种常用的数据结构。在物理结构上,环形队列和我们平常所见的vector 、数组相差无几,都是一段连续开辟的数组。但是,在逻辑结构上,通过控制队列的下标,实现一种环形的插入结构,就叫做环形队列。
而对于实现环形队列很重要的设计就在于,判空和判满的条件。多说无益,我们来看看。
(1)为什么会选择使用环形队列呢?
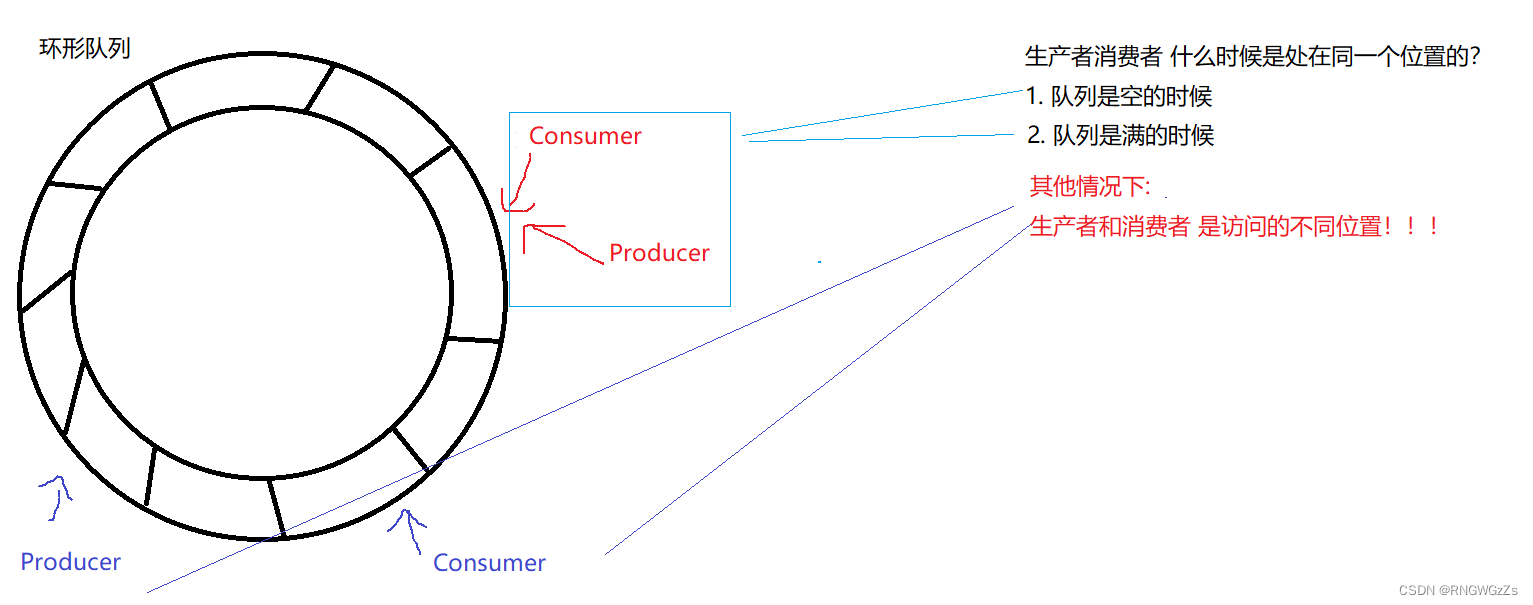
同样,使用环形队列实现生产者消费者模型,仍然需要遵守"321"原则。而怎样维护这个原则呢?无非只需要我们遵守以下的原则。
1. Consumer不能超过Producer (不可能我都没生产你跑到我前面进行消费)
2. Producer 不能超过 Consumer一圈 (数据将会被覆盖,这是不能容忍的事情)
3. 当我们站在一起的时候,谁才能访问到该临界资源。

这就完了吗?你可只是说了这个环形队列是用来干嘛的,怎么使用的,可是,你还没有说为什么要选择环形队列,为什么之前的阻塞队列实现的生产者消费者模型不行~

(2)基于环形队列的生产消费者模型实现
环形队列:
template<class T>
class RunQueue
{
public:
RunQueue(int cap = default_cap) : _queue(cap), _cap(cap)
{
// 生产者而言 当没有生成资源是 剩余空间为 _cap
int n = sem_init(&_SpaceNum, 0, _cap);
assert(n == 0);
(void)n;
// 对于消费者而言 首次入队列是 没有可消费的资源
n = sem_init(&_DataNum, 0, 0);
assert(n == 0);
(void)n;
}
~RunQueue()
{
sem_destroy(&_SpaceNum);
sem_destroy(&_DataNum);
}
private:
std::vector<T> _queue;
size_t _cap;
// 生产者: 剩余空间资源 消费者: 空间内容
sem_t _SpaceNum;
sem_t _DataNum;
// 生产者生成位置处 消费者消费位置处
size_t _ProducerStep;
size_t _ConsumerStep;
}
队列的P、V操作:
template <class T>
class RunQueue
{
// ....
void P(sem_t &sem)
{
// 申请资源
// 如果信号量--到0 那么就会阻塞
int n = sem_wait(&sem);
assert(n == 0);
(void)n;
}
void V(sem_t &sem)
{
// 释放资源
// 信号量++ 如果该信号量>0 则会唤醒处在sem_wait中的一个线程
int n = sem_post(&sem);
assert(n == 0);
(void)n;
}
// ....
}Push\Pop:
void Push(const T &in)
{
// 生产者进来申请信号量
P(_SpaceNum);
// 走到这里说明 申请成功
_queue[_ProducerStep++] = in;
_ProducerStep %= _cap;
// 这里应该释放什么资源呢?
// 你生产者生产了资源,在队列中用了嘛? 当然没有!
// 反而你生产资源 在消费者看来 说明可以进行消费了
V(_DataNum);
}
void Pop(T &out)
{
P(_DataNum);
out = _queue[_ConsumerStep++];
_ConsumerStep %= _cap;
// 同上
V(_SpaceNum);
}
(3)优化改进
但其实,上述的实现只是针对了单线程消费、单线程生产完成的同步互斥。如果面对多线程消费、多线程生产呢?生产者与生产者,消费者与消费者的互斥关系是没有维护的!
此时,就会出现线程安全问题。那么我们如何解决呢? 当然加锁是简单粗暴的。我们只允许一个生产者进入到这个队列中,或者一个消费者进到这个队列中,两者互不干涉地并发运行。
锁:
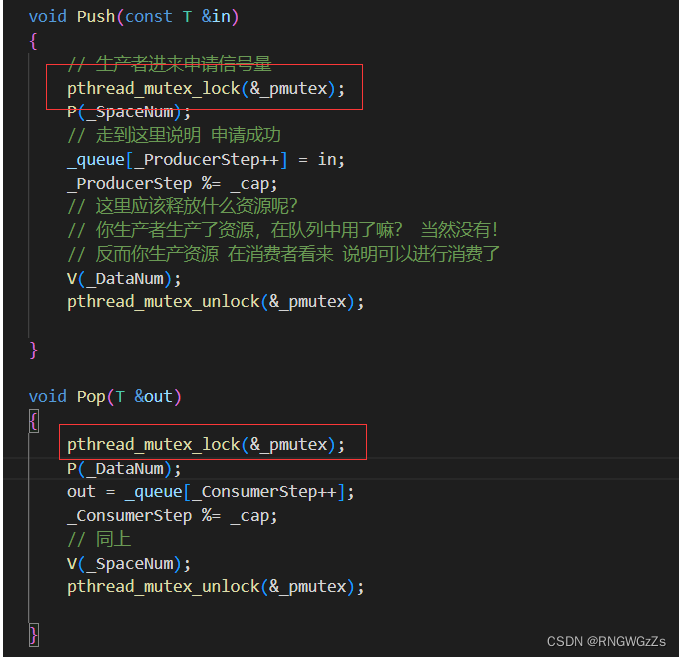
诶,你这样不对啊。基于阻塞队列的Push也是先加锁,再获取条件变量,而你这样一来又先加锁,再访问信号量。这不都是一个操作吗?都避免不了加锁的厄运~是的,这样写是有问题的。
信号量的P、V操作需要你加锁嘛?? 它自己就保证原子性,你需要保证它的线程安全吗???
你无非是要保证多个生产者不能访问同一个位置!
void Push(const T &in)
{
// 生产者进来申请信号量
P(_SpaceNum);
// PV操作后加锁
pthread_mutex_lock(&_pmutex);
_queue[_ProducerStep++] = in;
_ProducerStep %= _cap;
pthread_mutex_unlock(&_pmutex);
V(_DataNum);
}
void Pop(T &out)
{
P(_DataNum);
pthread_mutex_lock(&_pmutex);
out = _queue[_ConsumerStep++];
_ConsumerStep %= _cap;
pthread_mutex_unlock(&_pmutex);
V(_SpaceNum);
}这样,基于环形队列的生产者消费者模型,在多线程的环境下是可以安全运行的。
总结:
不管是基于阻塞队列的生产者消费者模型,还是基于环形队列的生产者消费者模型,它们的高效率都不在于Push任务、Pop任务,而是能够并发地 生产任务,消费任务。
POSIX信号量版本的生产者消费者模型能够事先让线程知道临界资源数量使用的情况,而不需要加锁、检测,如果不满足又得在条件变量下等待、释放锁……
本篇到此结束,感谢你的阅读。
祝你好运,向阳而生~
