基于多种算法实现鸢尾花聚类
基于多种聚类算法实现鸢尾花聚类
描述
聚类(Clustering)属于无监督学习的一种,聚类算法是根据数据的内在特征,将数据进行分组(即“内聚成类”),本任务我们通过实现鸢尾花聚类案例掌握Scikit-learn中多种经典的聚类算法(K-Means、MeanShift、Birch)的使用。
本任务的主要工作内容:
1、K-均值聚类实践
2、均值漂移聚类实践
3、Birch聚类实践
源码下载
环境
-
操作系统:Windows 10、Ubuntu18.04
-
工具软件:Anaconda3 2019、Python3.7
-
硬件环境:无特殊要求
-
依赖库列表
matplotlib 3.3.4 pandas 1.1.5 scikit-learn 0.24.2
分析
本实验使用鸢尾花(iris)数据集的花瓣长度(petal length)和花瓣宽度(petal width)两个特征,共150行。运用不同模型对这两个特征数据进行聚类,并将聚类结果与实际的类别标签做对比(使用Matplotlib)。
本任务涉及以下几个环节:
a)获取鸢尾花花瓣特征数据
b)分别使用K-Means、MeanShift、Birch等算法进行聚类
d)获得聚类结果标签
e)评估聚类模型成绩
f)使用Matplotlib将聚类结果可视化
实施
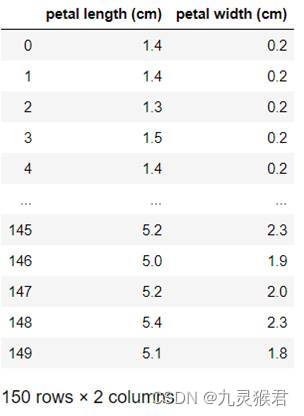
1、获取花瓣特征数据(花瓣长度、花瓣宽度)
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans, MeanShift, Birch, DBSCAN
from sklearn.metrics import adjusted_rand_score # 聚类模型评估工具
from IPython.display import display
import matplotlib.pyplot as plt
import pandas as pd
# 加载鸢尾花数(Iris)据集
iris = load_iris()
data = iris.data[:,2:] # 取后两列(花瓣长、宽)作为特征数据
target = iris.target # 标签数据
feature_names = iris.feature_names[2:] # 后两列的名字
df = pd.DataFrame(data, columns=feature_names)# 创建数据框
display(df) # 显示数据集
显示结果:
2、使用多种聚类算法,并评估成绩
# 注意:聚类模型的评估使用sklearn.metrics.adjusted_rand_score函数
# 参数1-实际类别标签
# 参数2-聚类结果标签
# 调用聚类算法
model = KMeans(3).fit(data) # K-均值聚类
# model = MeanShift().fit(data) # 均值漂移聚类
# model = Birch().fit(data) # Birch聚类
c_target = model.labels_ # 聚类结果标签
# 使用adjusted_rand_score函数来评估聚类效果
# 参数1-实际类别标签
# 参数2-聚类结果标签
print('accuracy: ', adjusted_rand_score(target, c_target))
结果如下:
accuracy: 0.8856970310281228
3、使用Matplotlib将聚类结果可视化
将聚类结果与样本的实际分类可视化,直观对比聚类效果。
# 定义画板尺寸
fig = plt.figure(figsize=(15, 5))
# 画第一幅子图——实际类别标签
ax1 = fig.add_subplot(1, 2, 1)
ax1.set_title('Real ')
ax1.scatter(data[:,0], data[:,1], c=target)
# 画第二幅子图——聚类结果
ax2 = fig.add_subplot(1, 2, 2)
ax2.set_title('Clustering ')
ax2.scatter(data[:,0], data[:,1], c=c_target)
# 显示图形
plt.show()
显示结果:
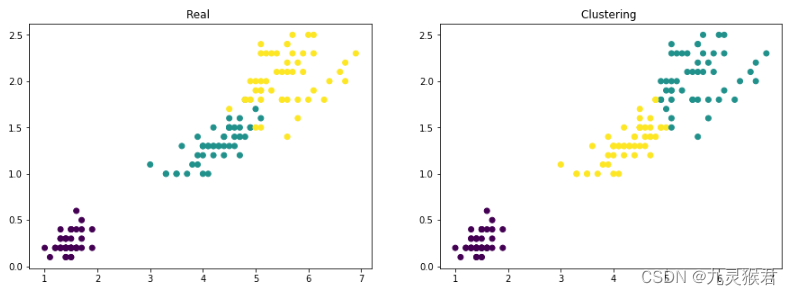
注:两幅图中从上到下依次为3种鸢尾花的特征分布(颜色随机),左图是实际情况,右图是聚类结果,可以看到聚类算法比较准确地还原了实际类别。