【Java面试八股文宝典之RabbitMQ篇】备战2023 查缺补漏 你越早准备 越早成功!!!——Day17

大家好,我是陶然同学,软件工程大三即将实习。认识我的朋友们知道,我是科班出身,学的还行,但是对面试掌握不够,所以我将用这100多天更新Java面试题🙃🙃。
不敢苟同,相信大家和我一样,都有一个大厂梦,作为一名资深Java选手,深知面试重要性,接下来我准备用100天时间,基于Java岗面试中的高频面试题,以每日3题的形式,带你过一遍热门面试题及恰如其分的解答。当然,我不会太深入,因为我怕记不住!!
因此,不足的地方希望各位在评论区补充疑惑、见解以及面试中遇到的奇葩问法,希望这100天能够让我们有质的飞越,一起冲进大厂!!,让我们一起学(juan)起来!!!
RabbitMQ工作原理
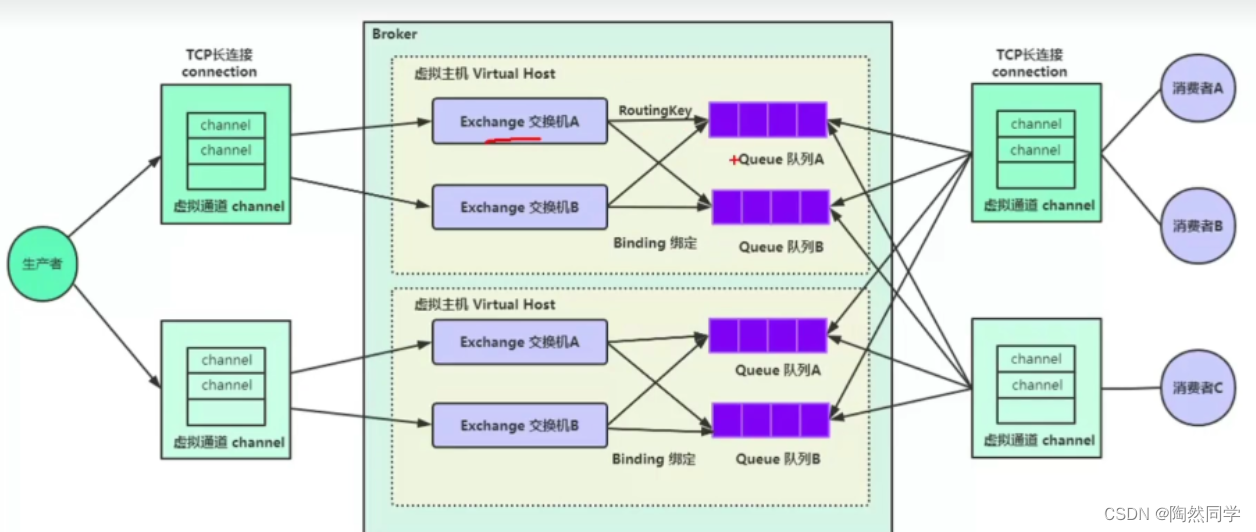
Broker:接收和分发消息的应用,RabbitMQ Server 就是 Message Broker
Virtual host:出于多租户和安全因素设计的,把 AMQP 的基本组件划分到一个虚拟的分组中,类
似于网络中的 namespace 概念。当多个不同的用户使用同一个 RabbitMQ server 提供的服务时,
可以划分出多个 vhost,每个用户在自己的 vhost 创建 exchange/queue 等
Connection:publisher/consumer 和 broker 之间的 TCP 连接
Channel:如果每一次访问 RabbitMQ 都建立一个 Connection,在消息量大的时候建立 TCP
Connection 的开销将是巨大的,效率也较低。Channel 是在 connection 内部建立的逻辑连接,如
果应用程序支持多线程,通常每个 thread 创建单独的 channel 进行通讯,AMQP method 包含了
channel id 帮助客户端和 message broker 识别 channel,所以 channel 之间是完全隔离的。
Channel 作为轻量级的Connection 极大减少了操作系统建立 TCP connection 的开销
面试题:rabbitmq为什么是基于channel(通道)去处理而不是连接?
一个应用有多个线程需要从rabbitmq中消费,或是生产消息,如果建立很多个Connection连接,对
操作系 统而言,建立和销毁tcp连接是很昂贵的开销,如果遇到使用高峰,性能瓶颈也随之显现。
rabbitmq采用类似nio的做法,连接tcp连接复用,不仅可以减少性能开销,同时也便于管理。
Queue:消息最终被送到这里等待 consumer 取走
Binding:exchange 和 queue 之间的虚拟连接,binding 中可以包含 routing key,Binding
信息被保存到 exchange 中的查询表中,用于 message 的分发依据
RabbitMQ消息丢了怎么办

其中的每一步都可能导致消息丢失,常见的丢失原因包括:
- 发送时丢失:
- 生产者发送的消息未送达exchange
- 消息到达exchange后未到达queue
- MQ宕机,queue将消息丢失
- consumer接收到消息后未消费就宕机
针对这些问题,RabbitMQ分别给出了解决方案:
- 生产者确认机制
- mq持久化
- 消费者确认机制
- 失败重试机制
生产者确认机制
RabbitMQ提供了publisher confirm机制来避免消息发送到MQ过程中丢失。这种机制必须给每个消
息指定一个唯一ID。消息发送到MQ以后,会返回一个结果给发送者,表示消息是否处理成功。
返回结果有两种方式:
- publisher-confirm,发送者确认
- 消息成功投递到交换机,返回ack消息未投递到交换机,返回nack
- publisher-return,发送者回执
- 消息投递到交换机了,但是没有路由到队列。返回ACK,及路由失败原因。

消息持久化
生产者确认可以确保消息投递到RabbitMQ的队列中,但是消息发送到RabbitMQ以后,如果突然宕
机,也可能导致消息丢失。
要想确保消息在RabbitMQ中安全保存,必须开启消息持久化机制。
- 交换机持久化
- 队列持久化
- 消息持久化
消费者消息确认
RabbitMQ是阅后即焚机制,RabbitMQ确认消息被消费者消费后会立刻删除。
而RabbitMQ是通过消费者回执来确认消费者是否成功处理消息的:消费者获取消息后,应该向
RabbitMQ发送ACK回执,表明自己已经处理消息。
消费失败重试机制
当消费者出现异常后,消息会不断requeue(重入队)到队列,再重新发送给消费者,然后再次异常,再次requeue,无限循环,导致mq的消息处理飙升,带来不必要的压力。
本地重试
- 开启本地重试时,消息处理过程中抛出异常,不会requeue到队列,而是在消费者本地重试
- 重试达到最大次数后,Spring会返回ack,消息会被丢弃
失败策略
在之前的测试中,达到最大重试次数后,消息会被丢弃,这是由Spring内部机制决定的。
在开启重试模式后,重试次数耗尽,如果消息依然失败,则需要有MessageRecovery接口来处
理,它包含三种不同的实现:
- RejectAndDontRequeueRecoverer:重试耗尽后,直接reject,丢弃消息。默认就是这种方式
- ImmediateRequeueMessageRecoverer:重试耗尽后,返回nack,消息重新入队
- RepublishMessageRecoverer:重试耗尽后,将失败消息投递到指定的交换机
比较优雅的一种处理方案是RepublishMessageRecoverer,失败后将消息投递到一个指定的,专门
存放异常消息的队列,后续由人工集中处理。
RabbitMQ消息重复消费
造成重复消费的原因:
MQ向消费者推送message,消费者向MQ返回ack,告知所推送的消息消费成功。但是由于网络波
动等原因,可能造成消费者向MQ返回的ack丢失。MQ长时间(一分钟)收不到ack,于是会向消
费者再次推送该条message,这样就造成了重复消费。
解决重复消费的办法:
用从存储(redis或者mysql)记录一下已经消费的message的id,当message被消费前先去存储中
查一下消费记录,没有该条message的id则正常消费返回ack,有该条message的id的话不用消费
直接返回ack给MQ。
当然实际生产中的话选用redis是比较好的选择,毕竟查mysql要进行磁盘IO,效率要低得多,而且
绝大多数重复消费都是由于MQ没有收到消费者的ack于是造成MQ再次向消费者进行同一条
message的投递。所以message的消费记录其实我们并不需要一直记录,只需要保存一段时间,当
下次投递过来的时候消费者能查到消费记录然后准确返回ack给MQ就行。
以下是一个使用redis解决重复消费的示例步骤:
监听器接收MQ队列中的数据。
利用redis的setnx命令,以消息唯一id为key,以消息内容为value,超时时间设置为10分钟,存入
redis中。
如果能够成功存入,说明没有重复消费,则处理业务,处理完业务后返回ack或者nack确认。
如果存不进去,则说明重复消费,直接返回ack确认的回调信息就可以了。