IO流复习
目录
- 字符集
- git pull origin master --allow-unrelated-histories
- CTRL+ ALT + T进行整块代码的操作(会出现一个选项栏)
- 字符集的编码和解码操作
- IO流
- 字节输入流和字节输出流
- 文件拷贝
- 资源释放的方式
- 字符输入流和字符输出流
- 缓冲流
- 字节缓冲流的性能分析
- 字符缓冲流
- 字符缓冲流来复制以及自定义比较器规则
- 转换流
- 序列化对象
- 打印流
- properties 属性集合
字符集
git pull origin master --allow-unrelated-histories
CTRL+ ALT + T进行整块代码的操作(会出现一个选项栏)
- 由于计算机只能存储二进制的数字, 不能够直接存储字符, 所以就用相应的二进制数字来表示字符, 这些二进制数字的集合就是字符集。
- 编码前和编码后(解码)的字符集必须一致, 否则会出现中文乱码。
- 英文和数字在任何字符集中都不会出现乱码, 因为他们都用一个字节来表示。
- 什么是字符集:
- 用数字来表示对应的字符.
- 字符集分类:
- ASCII 字符集:
- 只能表示英文, 符号, 数字
- 用一个字节也就是8个二进制位来表示一个字符,总共可以表示128个字符
- GBK码表:
- 这是我们window默认的码表, 兼容了ASCII
- 用2个字节来存储一个中文, 也就是16个二进制位, 总共可以表示65535个字符。
- 其中包含了几万个汉字, 以及部分日韩文字。
- Unicode码表
- 万国码, 是业界字符编码标准。
- UTF-8是Unicode的一种实现形式, 用三个字节来表示一个中文 。
- 我们程序员必须使用UTF-8来编码。
- ASCII 字符集:
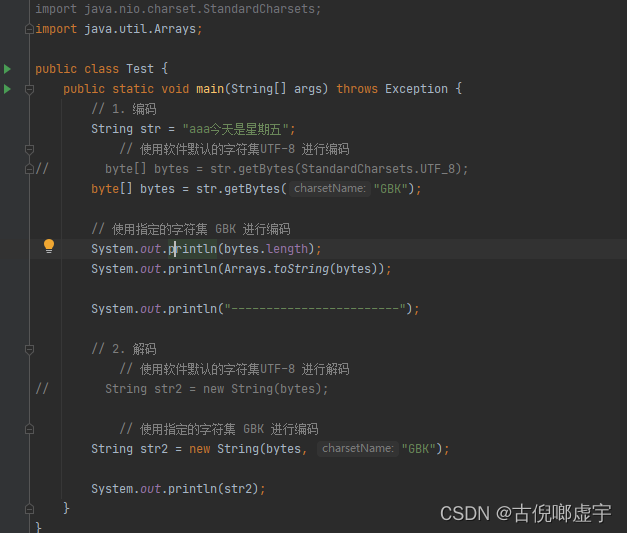
字符集的编码和解码操作
- 编码: 直接以字节的形式输入数据,形成字节数组, 或者调用getBytes(String charsetName) 这个方法, 把一个字符串转成字节数组。
- 解码: 直接通过String 的构造方法传入一个字节数组,在指定解码的字符集, 就可以把一个字节数组解码成对应的字符串。
IO流
- IO流的作用
- 读取文件
- IO流分类
- 按照方向:
- 输入流 : 内存从硬盘中读文件。
- 输出流: 从内存把数据输入到硬盘 。
- 按照最小单位:
- 字节流: InputStream, OutputStream
- 字符流:Reader Writer
- 上述的都是抽象类, 我们要使用他们的具体实现类。
- 按照方向:
字节输入流和字节输出流
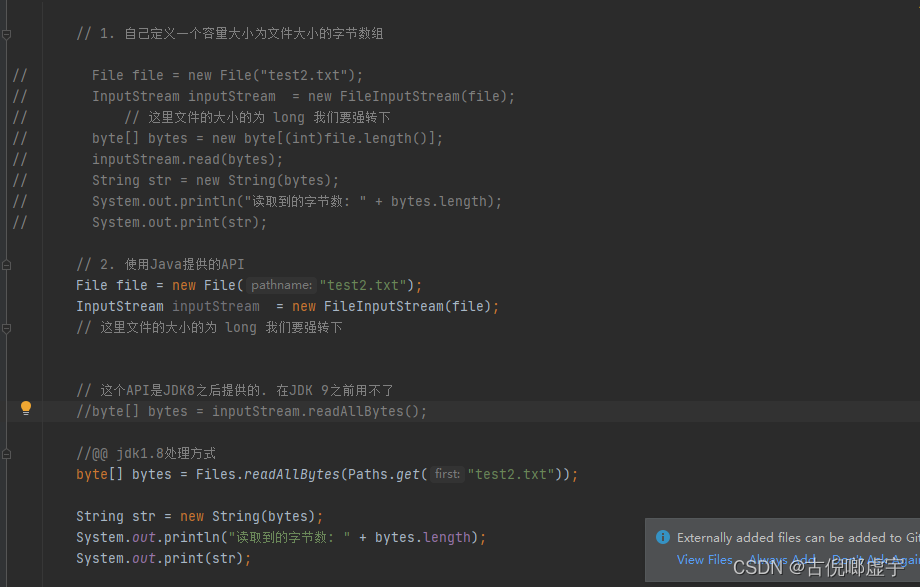
- 读取单个字节
- 通过read()方法读取流中的数据,返回值为实际字节所对应的int值
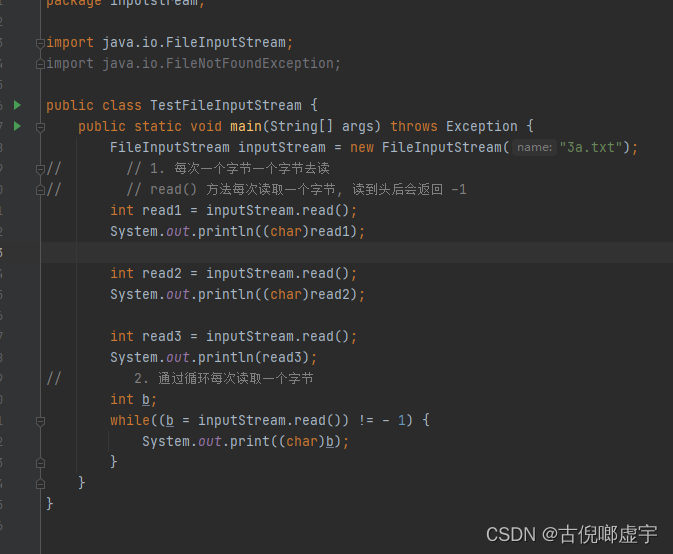
- 通过read()方法读取流中的数据,返回值为实际字节所对应的int值
- 读取字节数组
- 通过read(byte[]) 这个方法来读取输入流中的数据, 返回值为读取到的字节数量(具体读取的字节数量根据我们创建的字节数组的容量有关), 如果读完数据, 就会返回 -1.
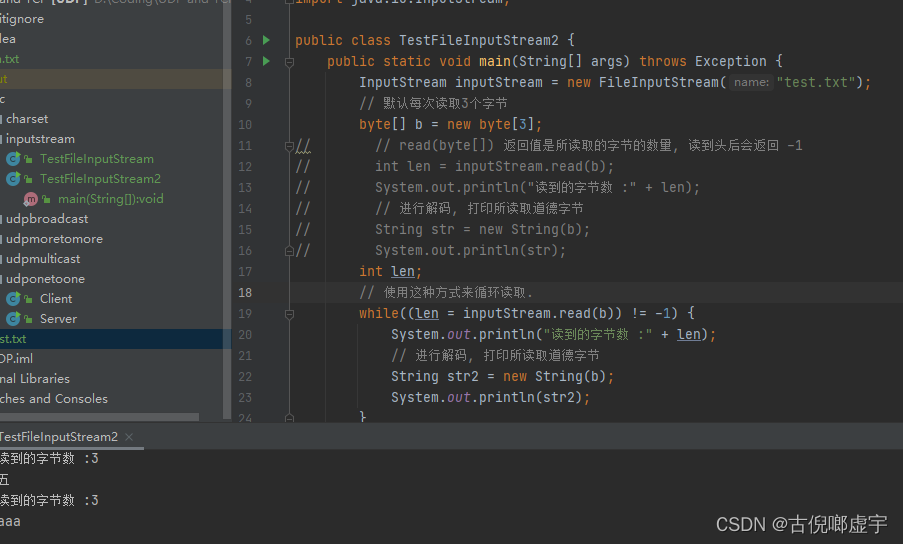
- 读取全部字节
- 这样可以避免中文乱码问题。
- 两种方式: 自己创建一个可以容纳文件中所有字节的一个字节数组 或者调用readAllBytes()这个API。
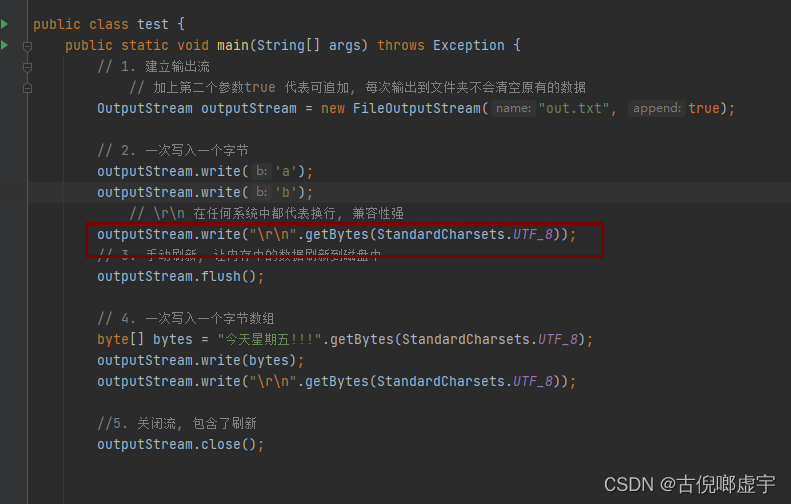
- 输出单个字节, 输出字节数组
- write() write(byte[])
- 追加: 第二个参数设为true
- OutputStream(path, append = true)
- 换行 \r\n
- os.write(“\r\t”.getBytes());
- 手动刷新, 关闭流
- flush() close()
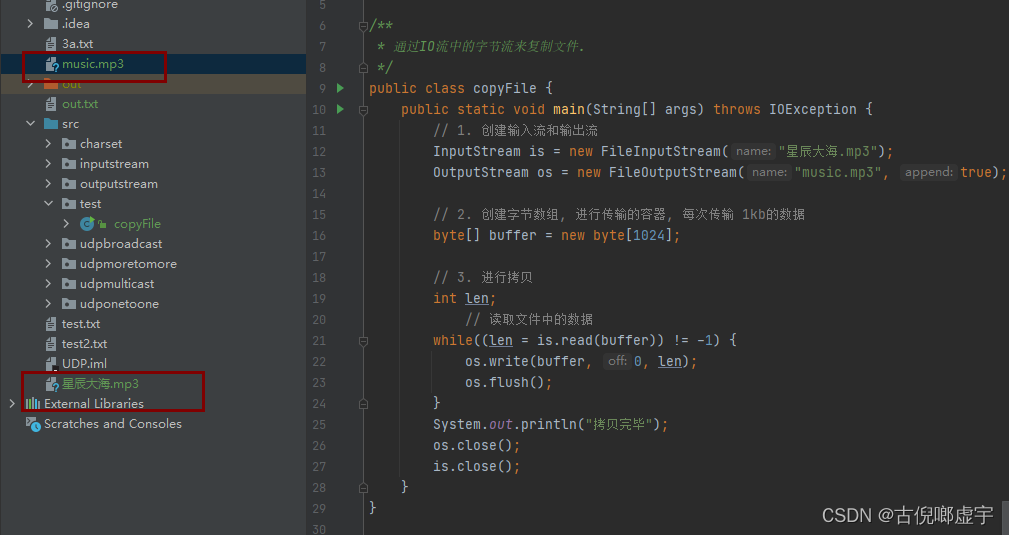
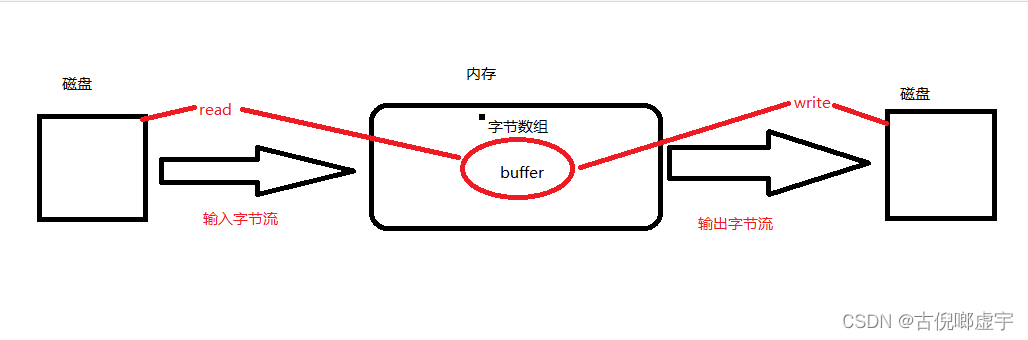
文件拷贝
- 进行字节输出流和字节输入流的测试。
资源释放的方式
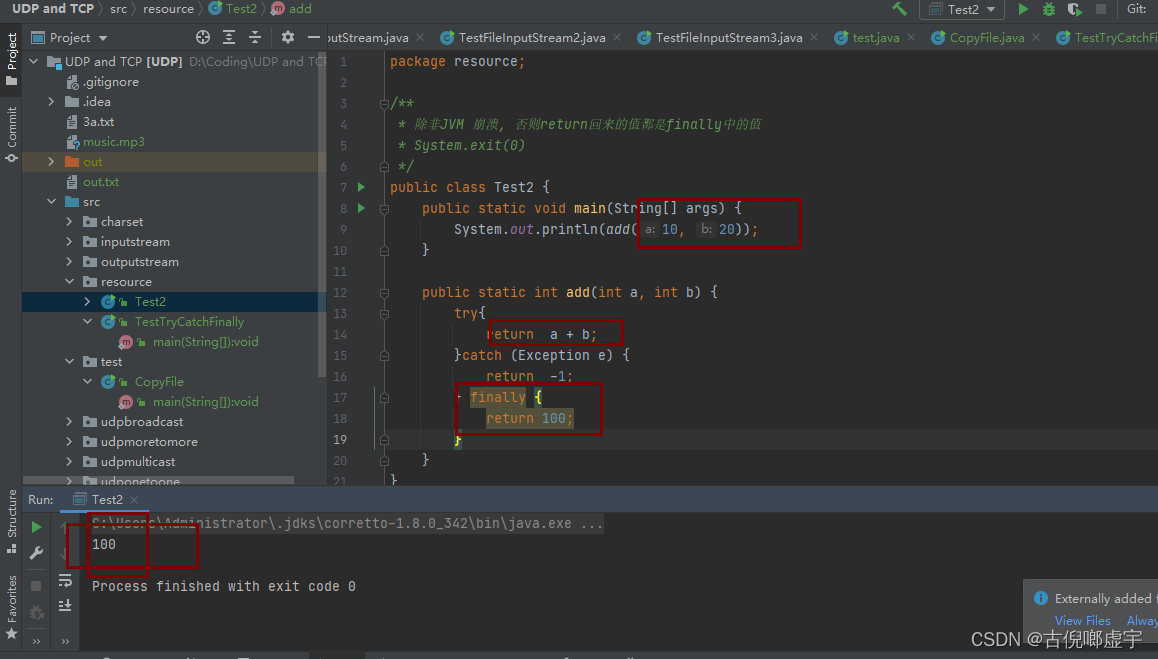
- try - catch - finally
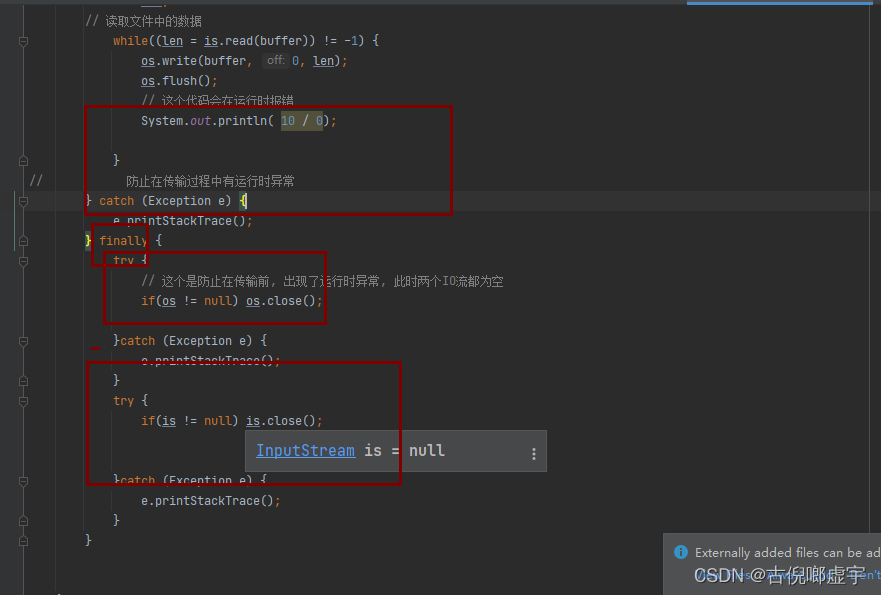
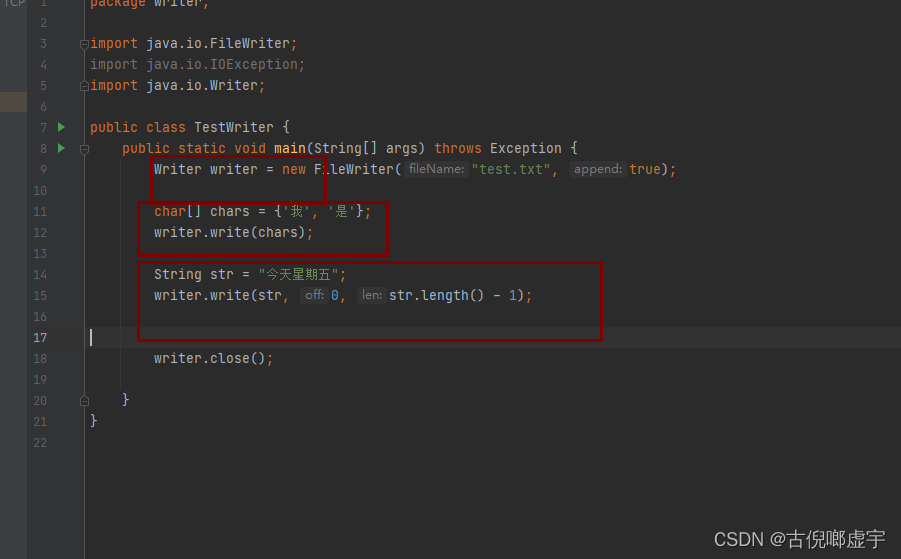
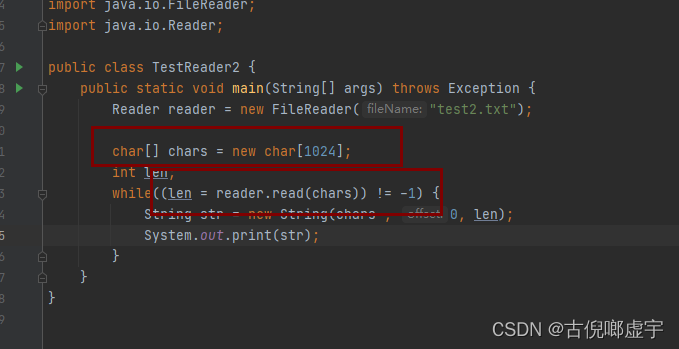
字符输入流和字符输出流
- 读的是字符串或字符数组: String char[]
- Reader 和 Writer
- 整体操作和字节输出流和输入流差不多, 只不过容器不是字节数组了, 而是字符数组 char[] chars
缓冲流
- 缓冲流原理:
- 有一个缓冲区, 其实是在内存中存在一个8kb的缓冲区, 用来缓存数据, 每次读和取数据的时候都从缓冲区中读取数据。
- 缓冲流作用:
- 自带缓冲区, 可以提高原始的字节流和字符流的读取数据的性能。
- API
- BufferedInputStrean(InputStream is)
- BufferedOutputStream(OutputStream ot)
- 本质就是对原来的字节流进行了封装,多了一个缓冲区, 其他的方法都跟字节流一样, 代码就不写了
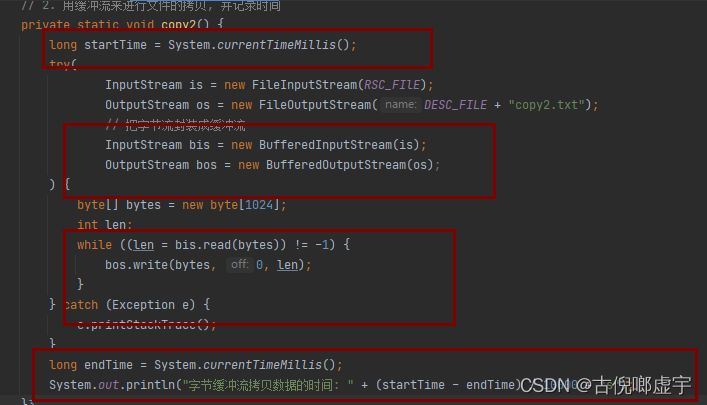
字节缓冲流的性能分析
- 就是分别用字节流和字节缓冲流来拷贝文件, 看具体拷贝所花的时间。
字符缓冲流
-
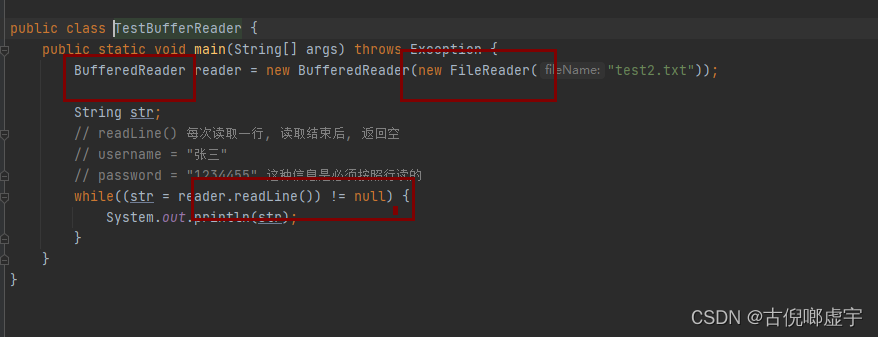
字符输入缓冲流:BufferedReader
- 多了一个方法, readLine()按行读取, 如果读到末尾就会返回空
- readLine() 的好处:
- 不需要我们在内存中创建一个字符数组了, 节省了空间
- 每次读取一行数据, 对于 user = ‘张三‘ password = '123’这种必须按照行读的数据, 不会出现那种按照字符读数据只读到关键信息的前部分。
-
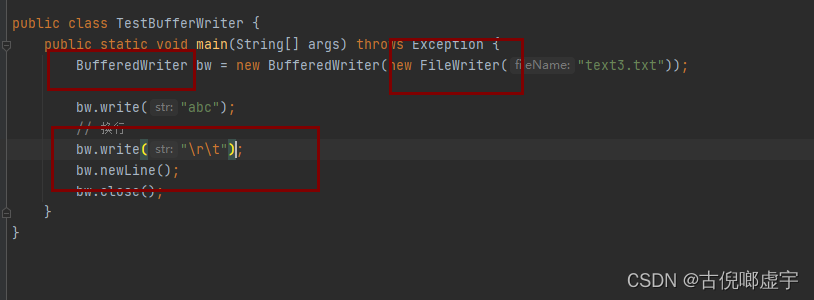
字符输出缓冲流: BufferedWriter
- 多了一个方法, newLine() 换行读取, 相当于 write(“\r\t”).
字符缓冲流来复制以及自定义比较器规则
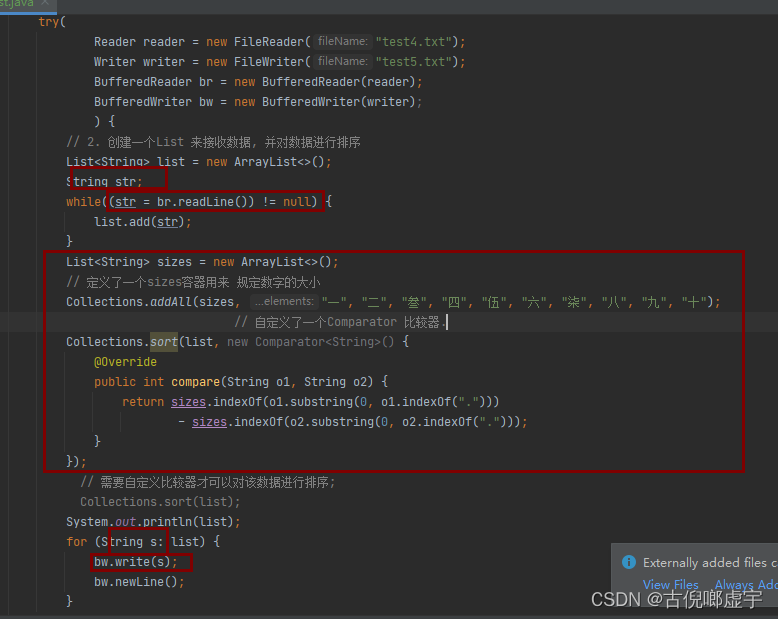
- 创建字符缓冲流对象
- 用输出缓冲流读取文件中的数据, 并放到自定义的List容器中
- 对List中的数据进行排序
- 通过Collections 工具类来实现排序, 但是需要通过自定义比较器对象 Comparator 来实现排序。
- 将List中排好序的数据通过循环的方式用字符输出缓冲流来输出到指定的文件中
- 代码:
6.
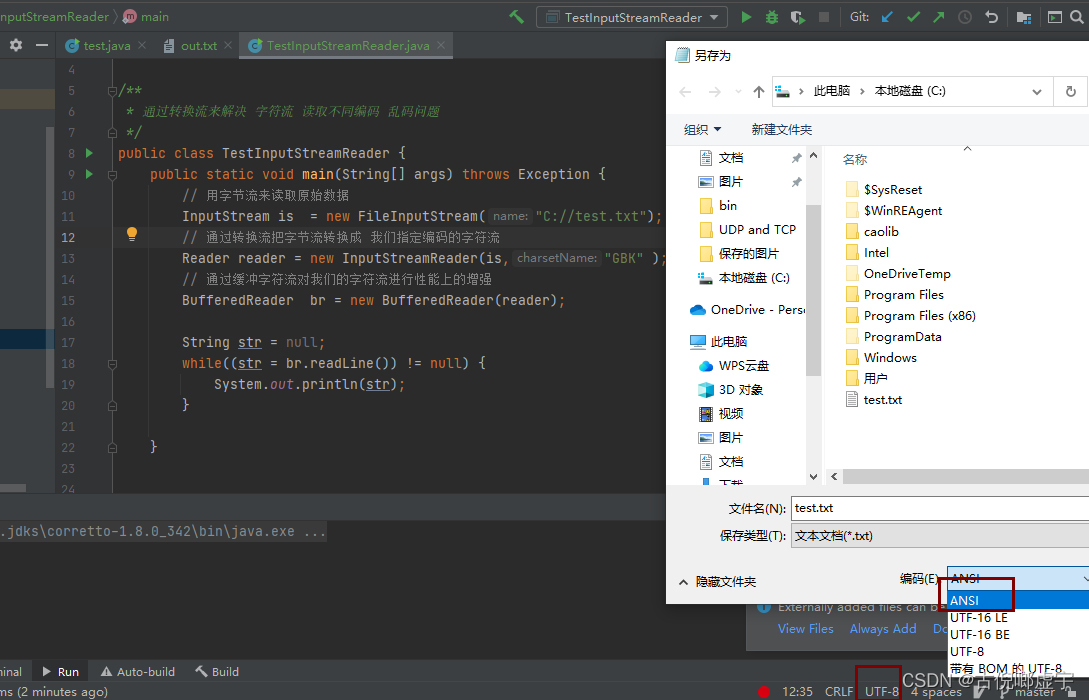
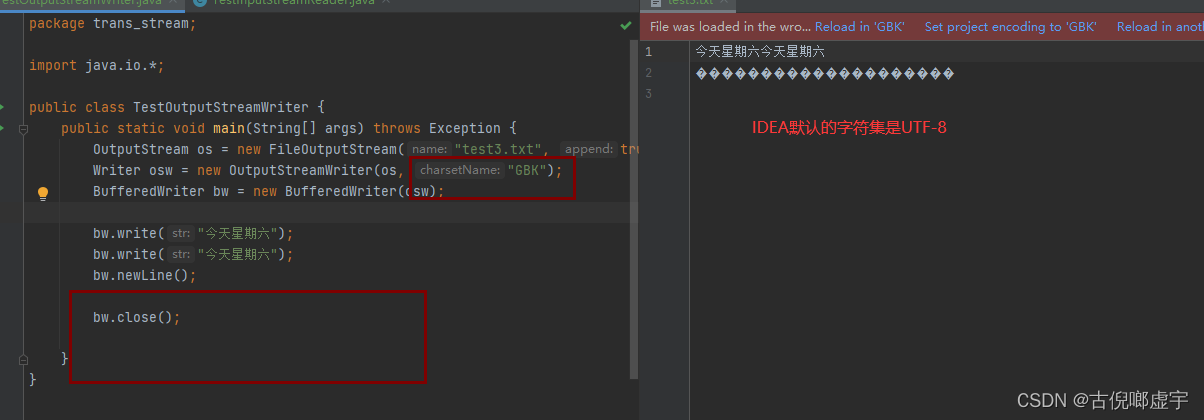
转换流
- 目的:
- 用来解决不同编码进行读取时, 出现乱码的问题。 针对的是字符流读取乱码问题。
- 转换的方式:
- 把原始数据按照字节流的方式进行读取, 这样不会出问题, 因为字节是最基本的单位, 最后把这些按照字节读取的数据按照指定的编码进行转换, 转换成对应的字符流。
- 字符输入转换流: InputStreamReader(InputStream is, String charSetName)
- 字符输出转换流: OutPutStreamWriter(OutputStream os, String charSetName)
序列化对象
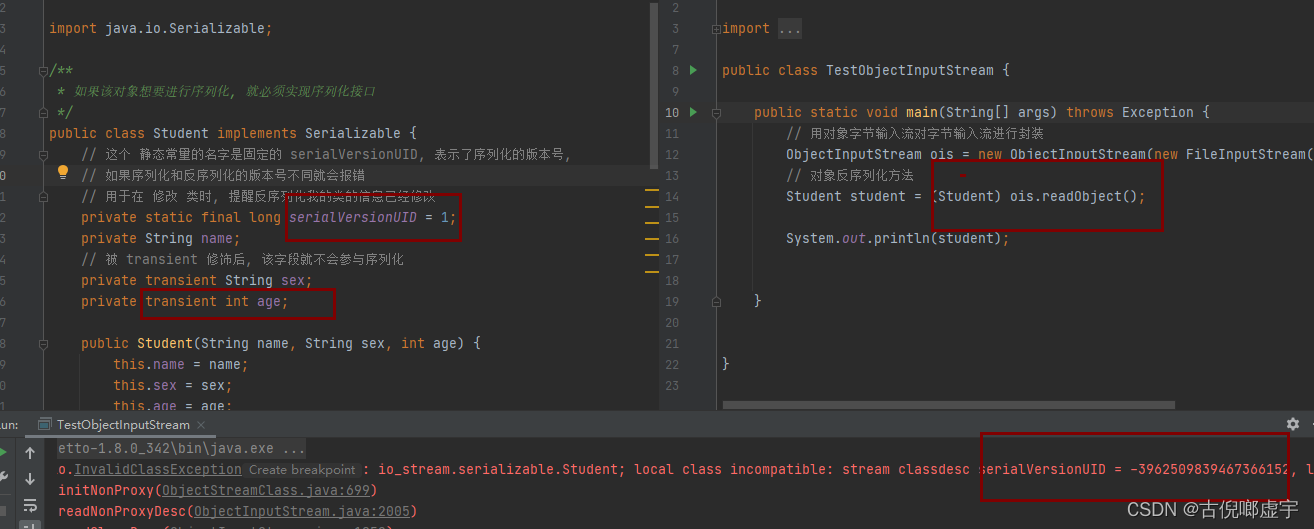
- 什么是对象序列化:
- 把对象从内存中存到磁盘中叫做序列化, 被存储的对象必须要实现Serializable接口
- ObjectOutputStream( FileOutputStrean os) writeObject(Object o)

- 反序列化:
- 把磁盘中的对象读取到内存中
- 直接看代码
- 被序列化的类, 可以加上 transient 这个关键字, 表示这个字段不会被序列化
- 可以设置序列化版本号, 静态常见并且名字必须为 serialVersionUID
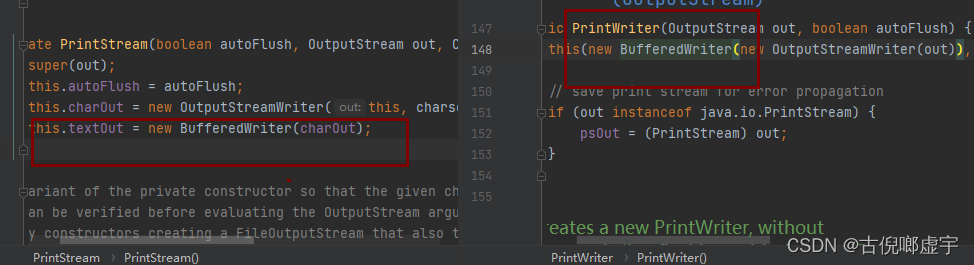
打印流
- 可以打印任何类型的数据,有字节打印流和字符打印流
- 这两种打印的方式都是一样的, 唯一区别就是在写数据的时候有区别, 但是我们写数据用字节/字符输出流
- 优势:
- 由于源码中内部都new了 缓冲流, 所以打印的很快, 很高效
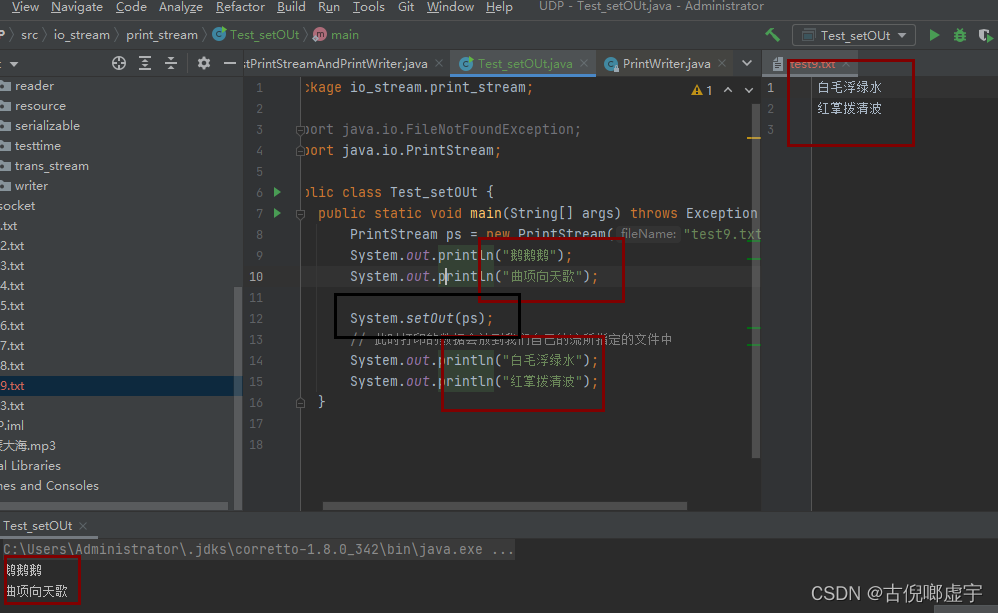
- 打印流实现重定向
- 主要就是System.setOut("我们自己的流“) 这个方法, 把系统的打印流改成我们自己的打印流
- sout的原理就是一个打印流, out是一个打印流对象
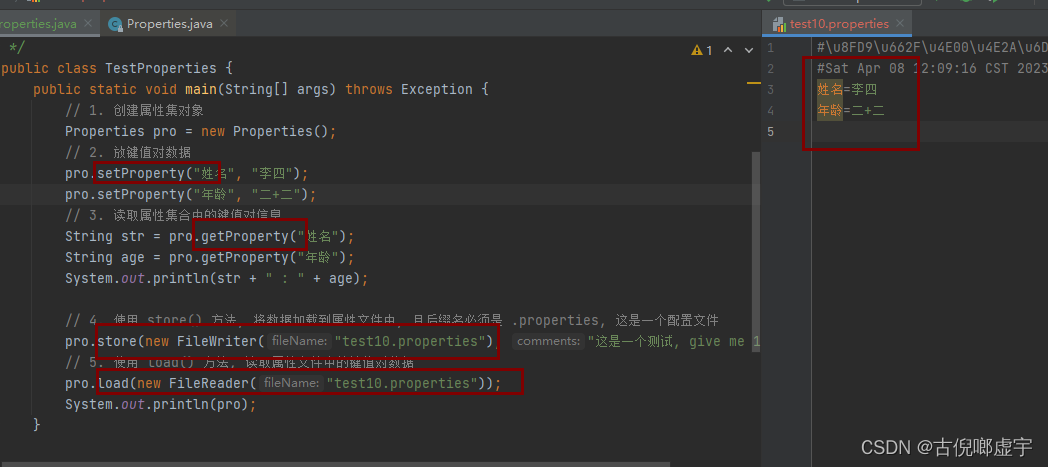
properties 属性集合
- 是Map家族的一员, 不过已经离家出走了
- 这个类的作用:
- 可以把属性 集合的键值对数据存放到属性文件中, 其实也是个IO流
- store(Writer w, String commons);
- 将键值对数据加载到指定的属性文件中
- load(Reader r)
- 从指定的属性文件中读取键值对数据
- 代码图片