爬虫代理技术与构建本地代理池的实践
爬虫中代理的使用:
- 什么是代理
- 代理服务器
- 代理服务器的作用
- 就是用来转发请求和响应
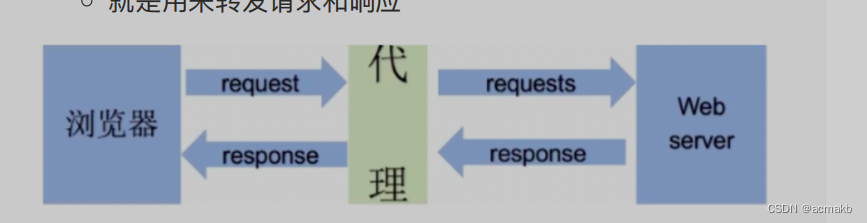
在爬虫中为何需要使用代理?
- 隐藏真实IP地址:当进行爬取时,爬虫程序会发送大量的请求到目标网站。如果每个请求都使用相同的IP地址,可能会触发目标网站的反爬虫机制,导致IP被封禁或限制访问。使用代理可以隐藏真实IP地址,轮流使用多个代理IP来发送请求,降低被封禁的风险。
- 绕过访问限制:某些网站可能会对特定IP地址或特定地区的访问进行限制,例如地理位置限制或登录限制。通过使用代理,可以模拟不同的IP地址和地理位置,绕过这些限制,获取需要的数据。
- 提高访问速度:有些代理服务器可能位于目标网站的较近位置或具有更好的网络连接,通过使用这些代理,可以减少网络延迟,提高爬取速度。
- 数据采集分布:使用代理可以将爬虫请求分布到不同的代理IP上,实现数据采集的分布式和并发处理,提高数据获取效率。
代理服务器可以根据其功能和使用方式分为以下几种类型:
- 匿名代理:匿名代理服务器隐藏了客户端的真实IP地址,并将代理服务器的IP地址作为请求源地址发送给目标服务器。目标服务器无法直接识别客户端的真实身份。
- 透明代理:透明代理服务器在转发请求时不修改客户端的IP地址,目标服务器可以直接获取到客户端的真实IP地址。透明代理主要用于缓存和访问控制,但无法提供匿名性。
- 高匿代理:高匿代理服务器不仅隐藏了客户端的真实IP地址,还隐藏了代理服务器的存在。目标服务器无法检测到请求来自代理服务器。
代理从哪里获得:
- 代理平台
- 自己搭建一个本地代理池
- 爬取公共代理
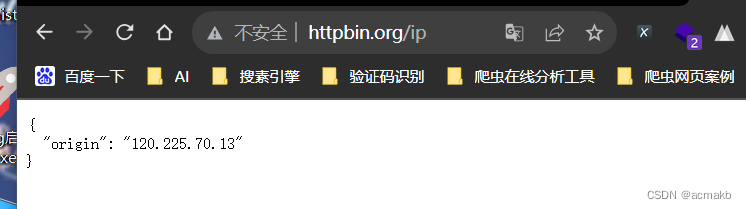
如何查询本地ip呢,网站:http://httpbin.org/ip,网页查看
import requests
from fake_useragent import UserAgent
ua = UserAgent()
url='http://httpbin.org/ip'
headers = {
'User-Agent':ua.chrome
}
ip=requests.get(url,headers=headers).json()['origin']
print('本地ip:',ip)

代理模板:
proxies={‘代理类型’:‘ip:port’}
proxies = {
'http': '42.57.150.150:4278',
'https': '42.57.150.151:4279',
'ftp': '42.57.150.152:4280',
# 添加更多协议和相应的代理
}
import requests
url = "你的目标网址"
headers = {"User-Agent": "你的用户代理"}
# 发送带有头部和代理的 GET 请求
page_text = requests.get(url=url, headers=headers, proxies=proxies)
# 现在,你可以通过 page_text.content、page_text.text 等来访问响应的内容。
如果我请求是http ,但只有https,就会使用本机ip。
-
使用代理发起请求,查看是否可以返回代理服务器的ip
-
import requests from lxml import etree headers = { 'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.80 Safari/537.36', } url='http://httpbin.org/ip' #使用代理服务器发起请求 #proxies={'代理类型':'ip:port'} data = requests.get(url=url,headers=headers,proxies{'https':'42.57.150.150:4278'}).json()['origin'] print(data)
构建本地代理池:
根据代理IP提供的API构建本地代理池:
from bs4 import BeautifulSoup
from lxml import etree
import requests
import time
import random
headers = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36'
}
url='http://http.tiqu.letecs.com/getip3?num=15&type=2&pro=&city=0&yys=0&port=1&pack=304028&ts=0&ys=0&cs=0&lb=6&sb=-&pb=4&mr=1®ions=&gm=4'
json_data = requests.get(url=url,headers=headers).json()
# "code":0,"data":[{"ip":"120.34.156.191","port":4234,"outip":"120.34.156.191"},{"ip":"27.29.156.55","port":4267,"outip":"27.29.156.55"}
# ,{"ip":"60.17.154.30","p
json_list = json_data['data']
proxy_list = [] #代理池,每次请求,可以随机从代理池中选择一个代理来用
for dic in json_list:
ip = dic['ip']
port = dic['port']
n_dic = {
'https':ip+':'+str(port) # {'https':'111.1.1.1:1234'}
}
proxy_list.append(n_dic)
print(proxy_list)
proxies=random.choice(proxy_list)
print(proxies)