RPC调用框架简单介绍
一.Thrift
Apache Doris目前使用的RPC调度框架。Thrift是一款基于CS(client -server)架构的RPC通信框架,开发人员可以根据定义Thrift的IDL(interface decription language)文件来定义数据结构和服务接口,灵活性高,支持多种语言,功能强大,不仅可以对数据进行网络传输,还可以存储数据。主要包括3种服务模式:
1.TSimpleServer: 单线程服务模式,一个客户端对应一个服务端线程,随着客户端的增加,服务端的线程数会直线增加,仅在测试使用;
2.TTreadPoolServer : 阻塞式IO,服务端通过线程池的方式来提供服务;
3.TNonblockingServer:非阻塞式IO,服务端通过线程池的方式来提供服务,与第二种方式的不同点在于,这种服务模式,在服务端采用了主从Reactor的方式,主Reactor主要用来与客户端进行通信,响应客户端请求;从Reactor用来对数据进行编码解码操作,这个需要配合 TFramedThransport传输方式。
目前在Doris种,默认采用的是第二种服务模式。
二.Netty
Apache Flink目前数据传输主要是基于Netty来实现的(Spark也是)。它基于CS(client -server)的NIO架构,是一款典型的基于Reactor模型的RPC通信框架。Netty消耗资源少,高吞吐,低延迟,最重要的一点是它是基于零拷贝技术来是减少数据的拷贝,Netty可以直接通过socket读取堆外内存中的数据进行读写。零拷贝主要体现在以下几点:
1.Netty接收和发送byteBuffer采用direct buffers,直接使用堆外内存进行socket对数据的读写操作,不需要将堆外内存中的数据拷贝至堆内存中。堆外内存的分配主要依靠ByteBufferAllocator通过ioBuffer来进行分配。
2.提供了CompositeByteBuf 类,可以将多个小的byteBuffer合并为一个逻辑上大的byteBuffer,避免了传统通过内存拷贝的方式将几个小byteBuffer合并为一个大byteBuffer的不足;
3.通过FileRegion包装的FileChannel.tranferTo()方式,直接将文件缓冲区的数据发送到目标Channel中,避免传统通过循环write的方式导致的内存拷贝问题。
参考文章:Netty原理总结
三.Akka
Apache Flink目前TaskManager,jobManager,jobClient之间通信主要是基于Akka来实现的。它是一种分布式,高并发,有容错的IO密集型的,基于协程来实现的RPC异步通信框架。
Akka是actor模型的一种实现。在actor模型的上下文中,所有代理实体都被认为是独立的actor,每个actor都有自己独立的邮箱,actor通过向彼此发送异步消息(邮件)与其他actor通信。actor模型的强度来自于这种异步操作。参看:Akka简介
Actor系统是所有actor存活的容器,它提供诸如调度、配置和日志记录之类的共享服务。Actor系统还包含从所有actor线程收集到的线程池。所有actor都按层次结构组织,每个新创建的actor将创建它的的actor作为父节点,分层次结构主要用于监督。每个父actor负责监督管理其创建的所有子actor。如果其中一个子actor出现错误,首先通知子actor,子actor可以通过重启或者恢复的方式解决问题。如果问题超出了子actor的处理范围,它可以将错误升级到自己的父actor。升级错误仅仅意味着当前层次之上的层次结构层现在负责解决问题。
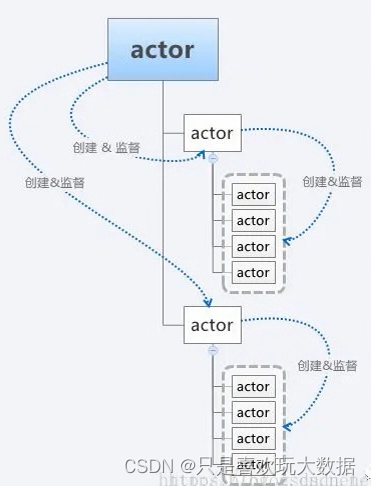
Akka是基于协程来实现通信框架。协程的粒度比线程更小,一个线程中可以有多个协程存在,多个协程之间相互协调处理。
线程包括内核线程和用户线程,通常我们所说的线程是指内核线程,每一个用户线程(协程)都必须关联一个内核线程,cpu只能感知到内核线程(内核空间),无法感知到用户线程(用户空间)。
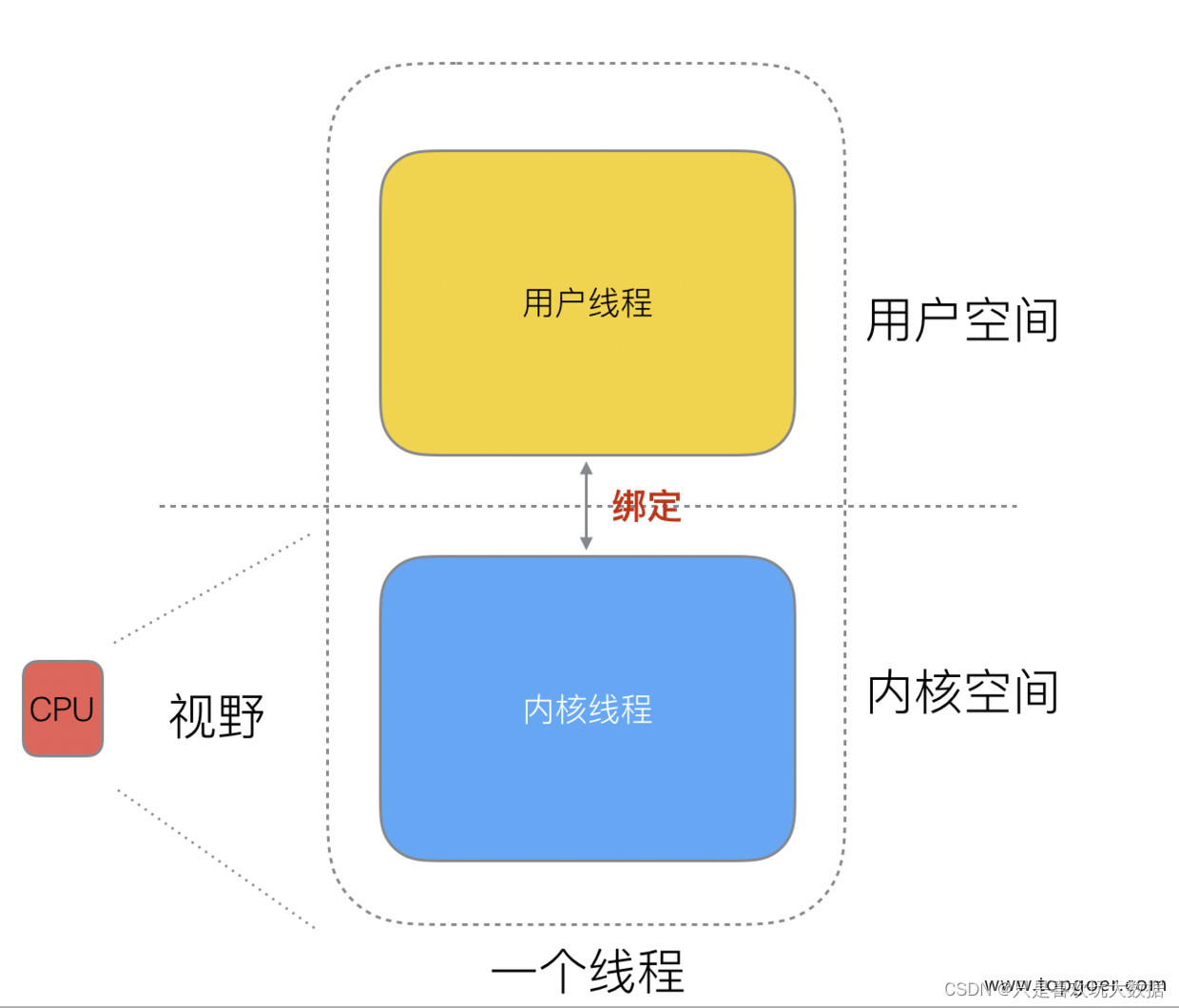
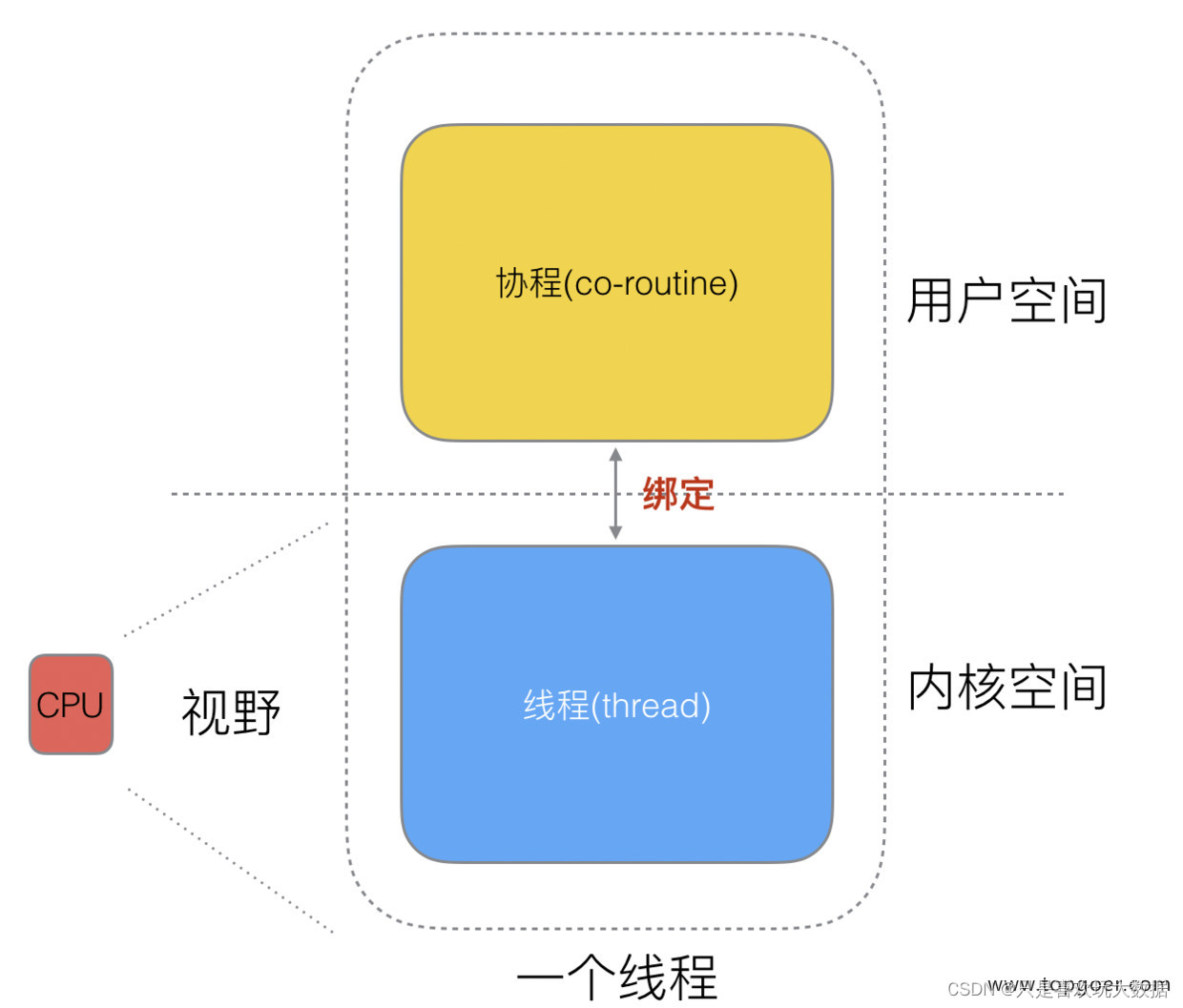
协程可以理解为一种轻量级的用户线程,每个协程都有自己的寄存器和栈,当一个协程再做状态切换时,只需要在用户态上切换即可,而线程之间的切换需要从用户态->内核态->用户态,因此协程切换之间的速度更快,耗费资源更少。线程栈空间通常是 2M, 协程栈空间最小 2K。
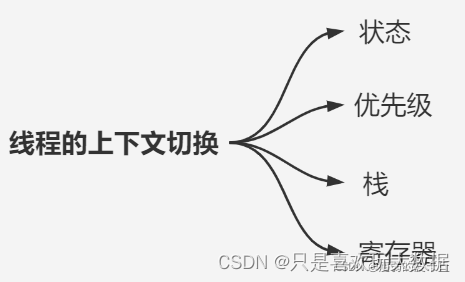
那为什么要进行上下文切换呢?比如一个通过命令行任务的提交吧。
比如当前有一个A进程正在等待命令行的输入,当提交作业过来后,A进程会调用一个系统函数(system call),来执行该请求,system call会将控制权传递给操作系统,操作系统此时会在内存和处理器当中保存A进程的上下文信息,同时创建一个新的进程B及其上下文,然后操作系统会把控制权传递给新的进程B。当进程B终止后,操作系统会恢复A的上下文,并将控制权重新传递给A,进程A等待下一个任务。
从上面这个实例我们可以得出结论:
(1)上一个进程的上下文信息还在内存和处理器当中,要保存这些信息的话,就必须陷入到内核态才可以。
(2)创建一个新的进程,以及它的上下文信息,并且将控制权交给这个新进程,这些都只有在内核态才能实现。
一个用户态线程必须要绑定一个内核态线程,那么是否可以多个用户态线程(协程)绑定一个内核态线程呢?
于是,Go 为了提供更容易使用的并发方法,使用了 goroutine。goroutine 来自协程的概念,让一组可复用的函数运行在一组线程之上,即使有协程阻塞,该线程的其他协程也可以被 runtime 调度,转移到其他可运行的线程上。最关键的是,程序员看不到这些底层的细节,这就降低了编程的难度,提供了更容易的并发。
注:所有图片均来自网络,如果侵权,请联系删除。