【深度学习 | Transformer】释放注意力的力量:探索深度学习中的 变形金刚,一文带你读通各个模块 —— 总结篇(三)

🤵♂️ 个人主页: @AI_magician
📡主页地址: 作者简介:CSDN内容合伙人,全栈领域优质创作者。
👨💻景愿:旨在于能和更多的热爱计算机的伙伴一起成长!!🐱🏍
🙋♂️声明:本人目前大学就读于大二,研究兴趣方向人工智能&硬件(虽然硬件还没开始玩,但一直很感兴趣!希望大佬带带)

摘要: 本系列旨在普及那些深度学习路上必经的核心概念,文章内容都是博主用心学习收集所写,欢迎大家三联支持!本系列会一直更新,核心概念系列会一直更新!欢迎大家订阅
该文章收录专栏
[✨— 《深入解析机器学习:从原理到应用的全面指南》 —✨]
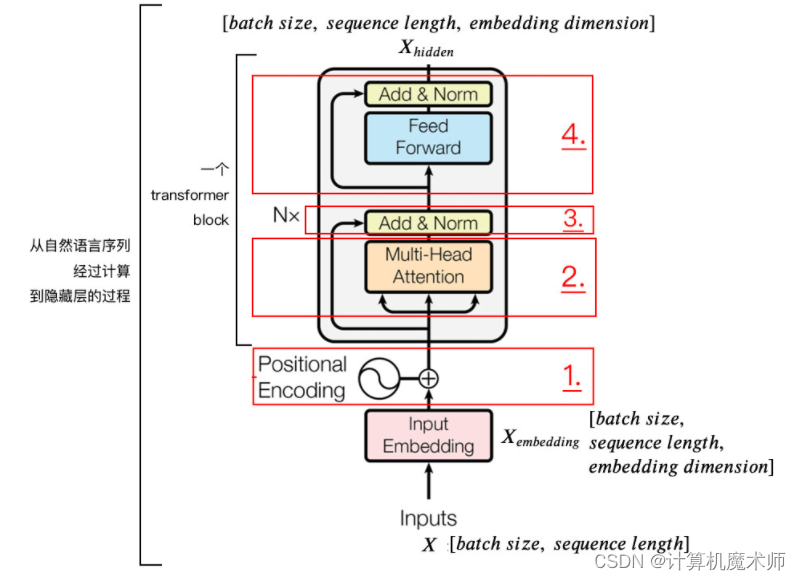
残差链接和层归一化
Transformer 模型使用残差连接(residual connections)来使梯度更容易传播,在进行self(自我)-attention 加权之后输出,也就是 Self(自我)-Attention(Q, K, V),然后把他们加起来做残差连接
X e m b e d d i n g + S e l f − A t t e n t i o n ( Q , K , V ) Xembedding+Self-Attention(Q, K, V) Xembedding+Self−Attention(Q,K,V)
以及层归一化(layer normalization)来加速训练过程和提高模型性能。 [classical concept.md](classical concept.md) 这里有讲解关于层归一化的概念
下面的图总结了以上 encode 的部分,接下来我们看关于decode的部分
Deocoder中的 Masked Encoder-Decoder Attention 唯一不同的是这里的 K,V 为 Encoder 的输出,Q 为 Decoder 中 Masked(掩盖) Self(自我)-Attention 的输出
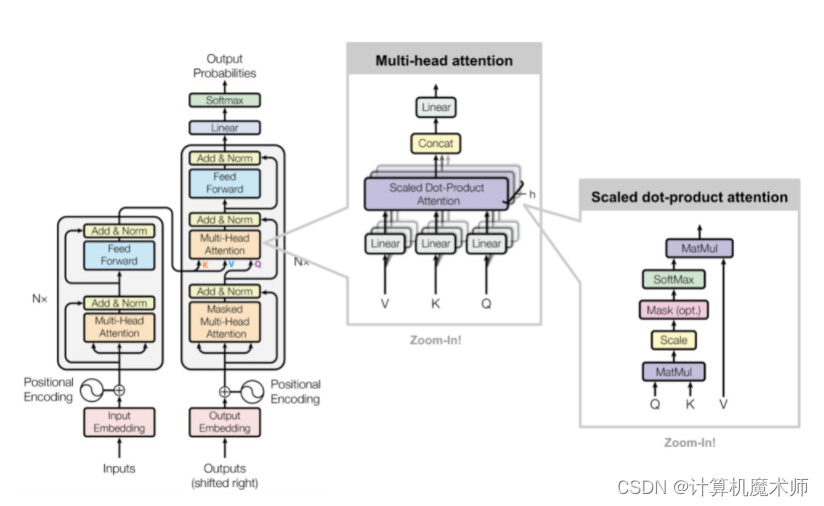
该方法将输入的信息作为键值传入,并将对于输入的序列查询信息糅合,达到学习关联二者序列的关系,并通过最终结果训练得到最优参数。
English to French 机器翻译案例
在机器翻译任务中,输入是一个源语言句子(例如英文句子),输出是该句子的目标语言翻译(例如法文句子)。
-
输入(Input):
- 源语言句子:将源语言句子进行编码,通常使用词嵌入(Word Embedding)来表示每个单词。例如,将英文句子"Hello, how are you?"转换为一系列词嵌入向量。
- 位置编码(Positional Encoding):为了捕捉单词在句子中的位置信息,Transformer模型引入位置编码,将位置信息与词嵌入向量相结合。
- 输入嵌入(Input Embedding):将词嵌入向量和位置编码向量相加,得到每个单词的最终输入表示。
-
输出(Output):
- 目标语言句子:目标语言句子也会进行类似的处理,将目标语言句子进行编码和嵌入表示。
- 解码器输入(Decoder Input):解码器的输入是目标语言句子的编码表示,通常会在每个目标语言句子的开头添加一个特殊的起始标记(例如<start>)来表示解码器的起始位置。
- 解码器输出(Decoder Output):解码器的输出是对目标语言句子的预测结果,通常是一个单词或一个单词的词嵌入向量。解码器会逐步生成目标语言句子,每一步生成一个单词,直到遇到特殊的结束标记(例如<end>)或达到最大长度。
下面是一个机器翻译任务的例子:
源语言句子(英文): “Hello, how are you?”
目标语言句子(法文): “Bonjour, comment ça va ?”
在这个例子中,输入是源语言句子的编码表示,输出是目标语言句子的解码器输入和解码器输出。
输入(Input):
- 源语言句子编码:[0.2, 0.3, -0.1, …, 0.5] (词嵌入向量表示)
- 位置编码:[0.1, 0.2, -0.3, …, 0.4]
- 输入嵌入:[0.3, 0.5, -0.4, …, 0.9]
输出(Output):
- 解码器输入:[<start>, 0.7, 0.2, -0.8, …, 0.6]
- 解码器输出:[0.1, 0.5, -0.6, …, 0.2]
通过训练,Transformer模型会根据输入的源语言句子和目标语言句子进行参数优化,使得模型能够生成准确的目标语言翻译。
需要注意的是,具体任务中的输入和输出的表示方式可能会有所不同,这只是一个简单的机器翻译示例。不同任务和模型架构可能会有不同的输入和输出定义。
一些值得思考的问题
为什么说 Transformer 在 seq2seq 能够更优秀?
RNN等循环神经网络的问题在于将 Encoder 端的所有信息压缩到一个固定长度的向量中,并将其作为 Decoder 端首个隐藏状态的输入,来预测 Decoder 端第一个单词 (token) 的隐藏状态。在输入序列比较长的时候,这样做显然会损失 Encoder 端的很多信息,而且这样一股脑的把该固定向量送入 Decoder 端,Decoder 端不能够关注到其想要关注的信息。Transformer 通过使用Multi-self-attention 模块,让源序列和目标序列首先 “自关联” 起来,并实现全局观和并行能力,模型所能提取的信息和特征更加丰富,运算更加高效。

关于代码
官方代码地址: https://github.com/tensorflow/tensor2tensor
http://nlp.seas.harvard.edu/2018/04/03/attention.html (Pytorch_实现)
如果有能力的话,大家可以尝试一下手撕代码哦,大佬嘿嘿。
参考文献:
https://wmathor.com/index.php/archives/1438/
https://www.youtube.com/watch?v=ugWDIIOHtPA&list=PLJV_el3uVTsOK_ZK5L0Iv_EQoL1JefRL4&index=62
https://www.bilibili.com/video/BV1pu411o7BE/?spm_id_from=333.337.search-card.all.click&vd_source=2700e3c11aa1109621e9a88a968cd50c
https://wmathor.com/index.php/archives/1453/#comment-2101
https://kazemnejad.com/blog/transformer_architecture_positional_encoding/
http://jalammar.github.io/illustrated-transformer/
https://ifwind.github.io/2021/08/17/Transformer%E7%9B%B8%E5%85%B3%E2%80%94%E2%80%94%EF%BC%887%EF%BC%89Mask%E6%9C%BA%E5%88%B6/#xlnet%E4%B8%AD%E7%9A%84mask
代码详解:http://nlp.seas.harvard.edu/2018/04/03/attention.html (Pytorch_实现)
扩展模型
下面是一些对Transformer模型进行改进和扩展的其他模型:
-
BERT(Bidirectional Encoder Representations from Transformers):BERT是一种预训练的语言表示模型,通过双向Transformer编码器来学习句子的上下文相关表示。它利用了Transformer的自注意力机制和多层编码器的结构,通过大规模的无监督预训练和有监督微调,取得了在多项自然语言处理任务上的显著性能提升。
-
GPT(Generative Pre-trained Transformer):GPT是一种基于Transformer的预训练语言生成模型。它通过自回归的方式,使用Transformer的解码器部分来生成文本。GPT模型在大规模文本语料上进行预训练,并通过微调在各种任务上展现出出色的语言生成和理解能力。
-
XLNet:XLNet是一种自回归和自编码混合的预训练语言模型。不同于BERT模型的双向预训练,XLNet采用了排列语言模型(Permutation Language Model)的方法,通过随机遮盖和预测全局排列来学习句子的上下文表示。这种方法能够更好地捕捉句子内部的依赖关系,提高了模型的性能。
-
Transformer-XL:Transformer-XL是一种具有记忆能力的Transformer模型。它通过引入相对位置编码和循环机制,解决了标准Transformer模型在处理长文本时的限制。Transformer-XL能够有效地捕捉长距离依赖关系,并保持对先前信息的记忆,从而提高了模型的上下文理解能力。
-
Reformer:Reformer是一种通过优化Transformer模型的存储和计算效率的方法。它引入了可逆网络层和局部敏感哈希(Locality Sensitive Hashing)等技术,以减少内存消耗和加速自注意力计算。Reformer模型在大规模数据和长序列上具有很好的可扩展性,并在多项任务上取得了优异的性能。
这些模型都是对Transformer模型的改进和扩展,通过引入不同的结构和训练策略,提高了模型在自然语言处理和其他领域任务中的表现。它们的出现丰富了深度学习模型的选择,并推动了自然语言处理领域的发展。

🤞到这里,如果还有什么疑问🤞
🎩欢迎私信博主问题哦,博主会尽自己能力为你解答疑惑的!🎩
🥳如果对你有帮助,你的赞是对博主最大的支持!!🥳