python—openpyxl操作excel详解
前言
openpyxl属于第三方模块,在python中用来处理excel文件。
可以对excel进行的操作有:读写、修改、调整样式及插入图片等。
但只能用来处理【 .xlsx】 后缀的excel文件。
使用前需要先安装,安装方法:
pip install openpyxl注:一个excel文件可看做是一个工作簿,工作簿中的一个Sheet就是一个工作表。
详细使用方法
1、创建一个excel工作簿对象
进行读写、修改等操作前,需要创建一个可供操作的excel工作簿对象。
分以下2种情况和方法:
第一种:新建一个excel工作簿对象
情况1:写入数据,本地没有现成可直接写入的excel工作簿时。
使用Workbook类,新建一个excel工作簿对象,用来后续进行读写等处理。
from openpyxl import Workbook
# 新建一个excel工作簿对象
wb = Workbook()
# 保存新建的excel工作簿
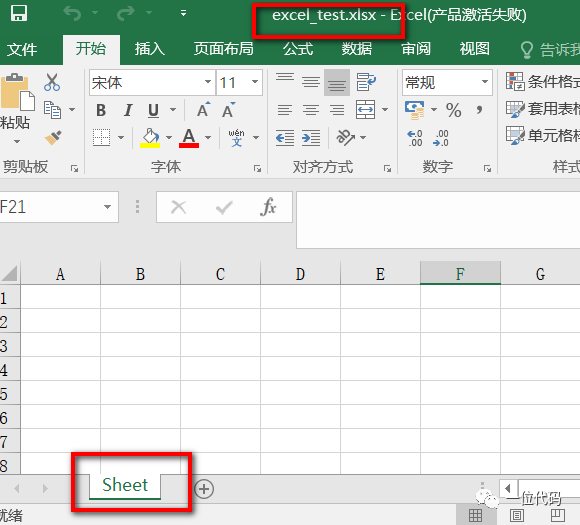
wb.save('excel_test.xlsx')注:(1)该类在新建excel工作簿的同时,也会新建了一个工作表(默认名为:Sheet)。
(2).save(保存路径)方法,对excel进行保存,写入或修改excel后,都需要保存。
(3)如果当前保存路径下,已经有一个同名excel文件,不会提示且原文件被覆盖。
上述代码,.save()保存,运行后,如下图:
第二种:读取已有excel
情况2:读取本地已存在的excel,用来后续进行读写等处理。
方法:load_workbook(已有excel文件路径),如果路径中excel文件不存在,将会报错。
from openpyxl import load_workbook
# 读取已存在的excel工作薄
wb = load_workbook('excel_test.xlsx')2、创建excel工作簿中的工作表
openpyxl提供了可自定义工作表的方法。
工作表,即是常见说法的【Sheet】。
创建自定义名称的工作表,语法如下:
Workbook.create_sheet(title,index)title:工作表的名称,可省略,系统自动命名(Sheet, Sheet1, Sheet2, ...)。 index:工作表的位置,可省略,默认插在工作表末尾,0表示插在第一个。
# 自定义工作表
ws1 = wb.create_sheet('test')
ws2 = wb.create_sheet()
# 保存
wb.save('excel_test.xlsx')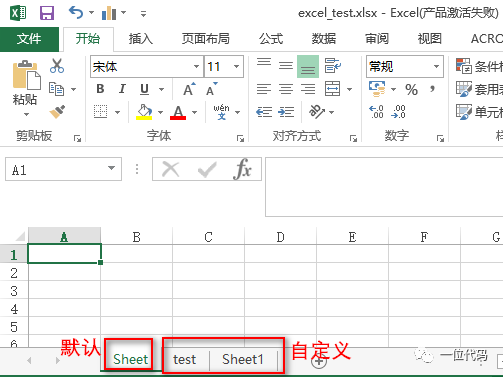
3、查看excel工作簿中的所有工作表
查看excel工作簿中已存在的所有工作表,有以下3种方法。
第一种:.sheetnames
# 查看所有工作表
sheet_lis = wb.sheetnames
print(sheet_lis)![]()
第二种:.get_sheet_names()
# 查看所有工作表
sheet_lis1 = wb.get_sheet_names()
print(sheet_lis1)![]()
第三种:循环得到所有工作表
# 查看所有工作表
for sheet in wb:
print(sheet.title)
4、获取工作表
进行读写、修改数据等操作时,首先需要获取工作簿中的工作表(即Sheet),作为操作对象。
3种获取工作表的方法,如下:
第一种:.active 方法
默认获取工作簿的第一张工作表
# 获取第一张工作表
ws = wb.active![]()
第二种:通过工作表名获取指定工作表
ws = wb['test']
print(ws)![]()
第三种:.get_sheet_name()
通过工作表名,使用方法:.get_sheet_name(工作表名)
ws3 = wb.get_sheet_by_name('Sheet1')
print(ws3)![]()
5、修改工作表的名称
使用.title属性,修改工作表名称。
修改工作表名称前,要先指定需要修改的工作表
# 获取要修改的工作表
ws1 = wb['text']
ws2 = wb['Sheet1']
# 修改工作表的名称
ws1.title = '测试'
ws2.title = '测试1'
# 保存
wb.save('excel_test.xlsx')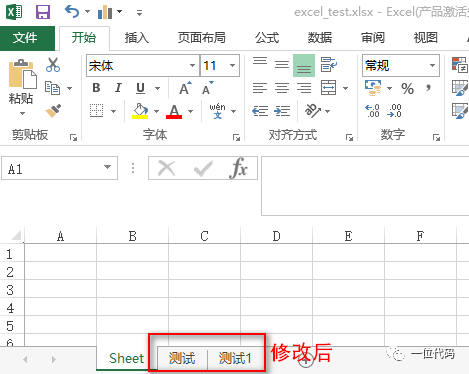
6、数据操作
以下是openpyxl最常用的【读写】操作。
在进行【读写】操作时,首先需要创建一个excel工作簿对象,然后对该对象中的工作表(sheet)进行操作。
以下,将以读取本地已存在的excel_test.xlsx作为工作簿对象wb,进行举例。
from openpyxl import load_workbook
# 读取已存在的excel工作薄
wb = load_workbook('excel_test.xlsx')注:在进行读写、修改等操作后,记得保存。
6.1、写入数据
(1)按单元格写入
直接赋值法
# 选择要写入的工作表
sheet1 = wb['测试']
# 写入单元格
cell = sheet1['A1']
cell.value = '测试数据'
# 保存
wb.save('excel_test.xlsx')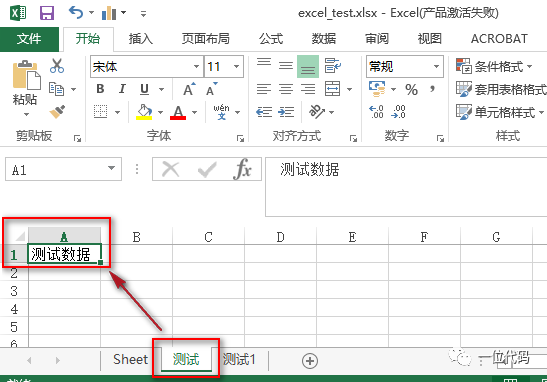
上述可以简化为:
# 选择要写入的工作表
sheet1 = wb['测试']
sheet1['A2'] = '姓名'
# 保存
wb.save('excel_test.xlsx')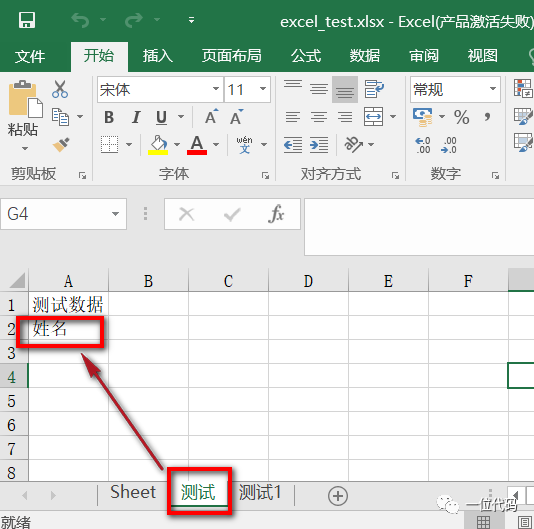
通过指定坐标赋值方式,将数据写入单元格。
方法:.cell(row,column,value)
row :行, column :列数,value:需要写入的数据。
# 选择要写入的工作表
sheet1 = wb['测试']
# 写入数据
sheet1.cell(row=3, column=4, value='一位代码')
# 保存
wb.save('excel_test.xlsx')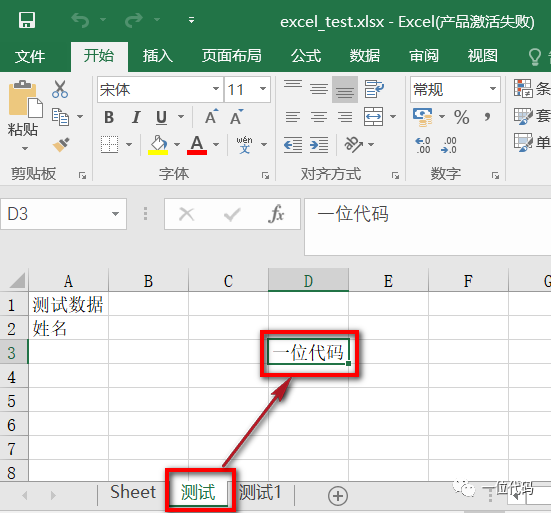
(2)按行写入数据
.append(data)方法,传一个单层列表格式数据。
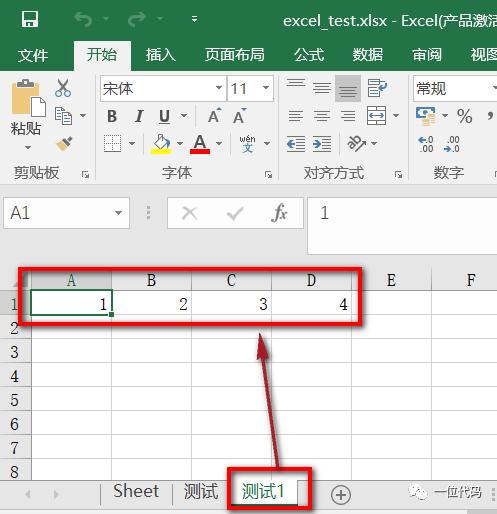
# 选择要写入的工作表
sheet1 = wb['测试1']
# 写入一行数据
data1 = [1, 2, 3, 4]
sheet1.append(data1)
# 保存
wb.save('excel_test.xlsx')注:append()只能接受单层列表格式数据,多层列表需要循环写入
6.2、读取数据
(1)获取工作表中已有全部数据
.values:获取目标工作表中已有全部数据,返回值是一个对象,需要进行转换。
# 选择需要获取的工作表
sheet1 = wb['测试1']
# 获取所有值
print('返回值:', sheet1.values)
print('返回值转换后:', list(sheet1.values))
以上方法,还可以用循环来写,如下:
# 选择需要获取的工作表
sheet1 = wb['测试1']
# 循环获取
for row in sheet1.values:
print(row)![]()
(2)获取指定范围内的值
获取指定单元格的值
# 选择需要获取的工作表
sheet1 = wb['测试1']
# 指定单位格的值
cell1 = sheet1['A1']
print(cell1.value)获取指定范围内单元格的值
# 选择需要获取的工作表
sheet1 = wb['测试1']
# 指定坐标范围
cells = sheet1['A1':'B2'] # 还可以写成['A1:B2']
print('指定范围:', cells)
# 获取单元格的值
for row in cells:
for cell in row:
print(cell.value)
获取指定列的值
# 选择需要获取的工作表
sheet1 = wb['测试1']
# 指定列
cells = sheet1['A']# 多列['A:c']
print('指定列:', cells)
for cell in cells:
print(cell.value)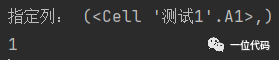
获取指定行的值
# 选择需要获取的工作表
sheet1 = wb['测试1']
# 指定行
cells = sheet1[1]# 多行[1:5]
print('指定行:', cells)
for cell in cells:
print(cell.value)
注:这里的行下标从[1]开始,区别于列表或元组等
(3)按行、列获取工作表中已有全部数据
.rows,获取工作表中存在数据的所有行
# 选择需要获取的工作表
sheet1 = wb['测试1']
# 获取所有的行
for row in sheet1.rows:
print(row)![]()
.columns,获取工作表中存在数据的所有列
# 选择需要获取的工作表
sheet1 = wb['测试1']
# 获取所有的列
for column in sheet1.columns:
print(column)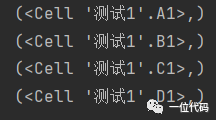
上述返回的值都是对象,需要根据for循环去取每个单元格的值。
如,获取所有列的值:
# 选择需要获取的工作表
sheet1 = wb['测试1']
# 获取所有的列的值
for column in sheet1.columns:
for cell in column:
print(cell.value)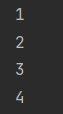
7、保存
.save() 方法:保存excel工作簿。
新建、写入或修改数据后都需要保存,处理操作才会生效。
这里需要再次注意一下,openpyxl只支持.xlsx后缀文件,如下:
wb.save('excel_test.xlsx') # excel_test.xlsx保存的路径、文件名以上就是openpyxl最常使用的方法,可供参考。