SQL-正则表达式和约束
文章目录
主要内容
- 正则表达式
- 约束
一.正则表达式
正则表达式是一种用来描述字符串模式的工具,它可以用于匹配、查找、替换等操作。正则表达式由字符和特殊字符组成,可以使用这些字符来定义匹配规则。
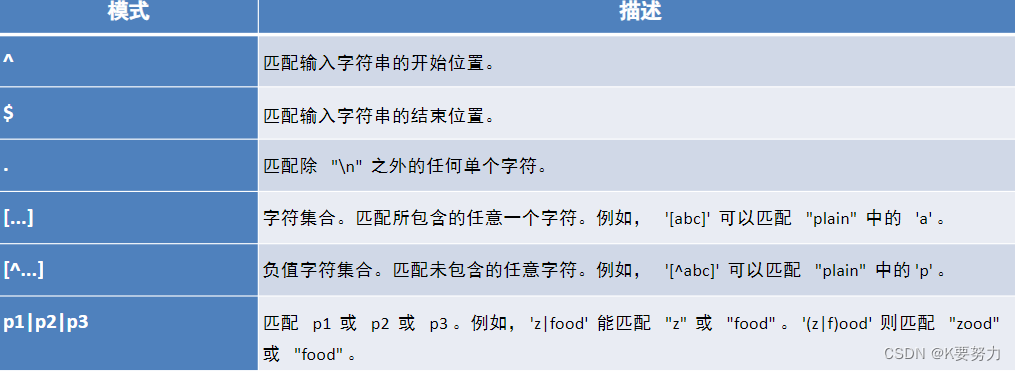
常用的正则表达式字符和特殊字符有:
- 普通字符:表示匹配该字符本身,如
a表示匹配字母"a"。 - 元字符:具有特殊含义的字符,如
.表示匹配除换行符以外的任意字符。 - 字符类:用
[]表示,表示匹配括号内的任意一个字符,如[abc]表示匹配字符"a"、“b"或"c”。 - 反义字符类:用
[^]表示,表示匹配除括号内字符以外的任意字符,如[^abc]表示匹配除"a"、“b”、"c"以外的任意字符。 - 重复字符:用
*、+、?表示,分别表示匹配前一个字符0次或多次、1次或多次、0次或1次。 - 边界匹配:用
^、$表示,分别表示匹配字符串的开头和结尾。 - 分组:用
()表示,可以将多个字符组合为一个整体,如(ab)+表示匹配"ab"、“abab”、"ababab"等。 - 转义字符:用
\表示,可以将特殊字符转义为普通字符,如\.表示匹配字符"."。
正则表达式的用法有:
- 匹配:使用
match()函数可以在字符串中查找匹配正则表达式的部分,并返回一个包含匹配结果的数组。 - 查找:使用
search()函数可以在字符串中查找匹配正则表达式的部分,并返回第一个匹配的位置。 - 替换:使用
replace()函数可以将字符串中匹配正则表达式的部分替换为指定的内容。 - 分割:使用
split()函数可以根据正则表达式将字符串分割为多个部分,并返回一个数组。
其他用法
-
量词:用来指定前面的字符或字符类的重复次数。常用的量词有:
*:匹配前一个字符0次或多次。+:匹配前一个字符1次或多次。?:匹配前一个字符0次或1次。{n}:匹配前一个字符恰好n次。{n,}:匹配前一个字符至少n次。{n,m}:匹配前一个字符至少n次,最多m次。
-
特殊字符:
.:匹配除换行符以外的任意字符。\d:匹配数字字符。\D:匹配非数字字符。\w:匹配字母、数字、下划线字符。\W:匹配非字母、数字、下划线字符。\s:匹配空白字符(空格、制表符、换行符等)。\S:匹配非空白字符。\b:匹配单词边界。\B:匹配非单词边界。
-
分组和引用:
():将多个字符组合为一个整体。(?:):非捕获分组,用于只匹配但不捕获。\1、\2、…:引用前面的分组,用于匹配相同的内容。
-
断言:
(?=...):正向肯定前瞻,用于匹配满足某个条件的位置。(?!...):正向否定前瞻,用于匹配不满足某个条件的位置。(?<=...):反向肯定后顾,用于匹配位于某个条件之后的位置。(?<!...):反向否定后顾,用于匹配不位于某个条件之后的位置。

正则表达式的用法非常灵活,可以根据具体的需求来选择合适的字符、特殊字符、量词、分组等来构建匹配规则。同时,正则表达式还支持一些高级的特性,如贪婪模式、非贪婪模式、修饰符等,可以进一步扩展正则表达式的功能。
正则表达式的详细用法还有很多,可以根据具体的需求来选择合适的正则表达式和相应的函数来进行操作。
1.操作1
代码如下(示例):
-- ^ 在字符串开始处进行匹配
SELECT 'abc' REGEXP '^a';
-- $ 在字符串末尾开始匹配
SELECT 'abc' REGEXP 'a$';
SELECT 'abc' REGEXP 'c$’;
-- . 匹配任意字符
SELECT 'abc' REGEXP '.b';
SELECT 'abc' REGEXP '.c';
SELECT 'abc' REGEXP 'a.';
-- [...] 匹配括号内的任意单个字符
SELECT 'abc' REGEXP '[xyz]';
SELECT 'abc' REGEXP '[xaz]';
2.操作2
代码如下(示例):
-- [^...] 注意 ^ 符合只有在 [] 内才是取反的意思,在别的地方都是表示开始处匹配
SELECT 'a' REGEXP '[^abc]';
SELECT 'x' REGEXP '[^abc]';
SELECT 'abc' REGEXP '[^a]';
-- a* 匹配 0 个或多个 a, 包括空字符串。 可以作为占位符使用 . 有没有指定字符都可以匹配
到数据
SELECT 'stab' REGEXP '.ta*b';
SELECT 'stb' REGEXP '.ta*b';
SELECT '' REGEXP 'a*';
-- a+ 匹配 1 个或者多个 a, 但是不包括空字符
SELECT 'stab' REGEXP '.ta+b';
SELECT 'stb' REGEXP '.ta+b';
3.操作3
代码如下(示例):
-- [^...] 注意 ^ 符合只有在 [] 内才是取反的意思,在别的地方都是表示开始处匹配
SELECT 'a' REGEXP '[^abc]';
SELECT 'x' REGEXP '[^abc]';
SELECT 'abc' REGEXP '[^a]';
-- a* 匹配 0 个或多个 a, 包括空字符串。 可以作为占位符使用 . 有没有指定字符都可以匹配
到数据
SELECT 'stab' REGEXP '.ta*b';
SELECT 'stb' REGEXP '.ta*b';
SELECT '' REGEXP 'a*';
-- a+ 匹配 1 个或者多个 a, 但是不包括空字符
SELECT 'stab' REGEXP '.ta+b';
SELECT 'stb' REGEXP '.ta+b';
4.操作4
代码如下(示例):
-- a{m,n} 匹配 m 到 n 个 a, 包含 m 和 n
SELECT 'auuuuc' REGEXP 'au{3,5}c';
SELECT 'auuuuc' REGEXP 'au{4,5}c';
SELECT 'auuuuc' REGEXP 'au{5,10}c';
-- (abc) abc 作为一个序列匹配,不用括号括起来都是用单个字符去匹配,如果要把多个字符
作为一个整体去匹配就需要用到括号,所以括号适合上面的所有情况。
SELECT 'xababy' REGEXP 'x(abab)y';
SELECT 'xababy' REGEXP 'x(ab)*y';
SELECT 'xababy' REGEXP 'x(ab){1,2}y';
二.约束
SQL约束是用于限制数据库表中数据的完整性和一致性的规则。它们定义了对表中数据的操作所允许的条件和限制。约束可以应用于表的列或整个表。
约束的分类:
- 主键约束(Primary Key Constraint):用于标识表中的唯一记录。主键约束要求列中的值是唯一的且不为空。
- 外键约束(Foreign Key Constraint):用于建立表之间的关系。外键约束要求一个表的列的值必须是另一个表的主键值。
- 唯一约束(Unique Constraint):用于确保列中的值是唯一的。唯一约束要求列中的值不能重复。
- 非空约束(Not Null Constraint):用于确保列中的值不为空。非空约束要求列中的值不能为NULL。
- 检查约束(Check Constraint):用于定义列中值的范围或条件。检查约束要求列中的值必须满足指定的条件。
约束的作用:
- 数据完整性:约束可以确保表中的数据满足特定的条件和规则,防止无效或不一致的数据进入数据库。
- 数据一致性:约束可以确保表之间的关系是正确的,避免了数据冗余和不一致。
- 数据安全性:约束可以防止对表中数据的非法操作,保护数据的安全性。
约束的用法:
- 创建约束:在创建表时,可以使用CREATE TABLE语句来定义约束。例如,可以使用PRIMARY KEY关键字定义主键约束,使用UNIQUE关键字定义唯一约束,使用FOREIGN KEY关键字定义外键约束等。
- 修改约束:可以使用ALTER TABLE语句来修改表的约束。例如,可以使用ADD CONSTRAINT关键字来添加新的约束,使用DROP CONSTRAINT关键字来删除约束等。
- 禁用约束:可以使用ALTER TABLE语句来禁用约束。例如,可以使用DISABLE CONSTRAINT关键字来禁用约束,以便在需要时可以绕过约束进行操作。
- 启用约束:可以使用ALTER TABLE语句来启用约束。例如,可以使用ENABLE CONSTRAINT关键字来启用约束,以便在禁用后重新启用约束。
总结起来,SQL约束是用于限制数据库表中数据的完整性和一致性的规则。它们可以应用于表的列或整个表,通过定义特定的条件和规则来确保数据的有效性和安全性。
1.主键约束
添加单列主键
方法1:
--在create table语句时,通过primary key
-- 在定义字段的同时指定主键,语法格式如下:
create table 表名 (
...
< 字段名 > < 数据类型 > primary key
...
)
方式 1- 实现:
create table emp1(
eid int primay key,
name VARCHAR(20),
deptId int,
salary double
);
方法2:
-- 在定义字段之后再指定主键,语法格式如下:
create table 表名 (
...
[constraint < 约束名 >] primary key [ 字段名]
);
方式 2- 实现:
create table emp2(
eid INT,
name VARCHAR(20),
deptId INT,
salary double,
constraint pk1 primary key(id)
);
添加多列主键(联合主键)
语法:
create table 表名(
...
primary key (字段1,字段2,...,字段n)
);
实现:
create table emp3(
name varchar(20),
deptId int,
salary double,
primary key(name,deptId)
);
通过修改表结构添加主键
主键约束不仅可以在创建表的同时创建,也可以在修改表时添加。
语法;
create table 表名 (
...
);
alter table < 表名 > add primary key (字段列表 );
实现:
-- 添加单列主键
create table emp4(
eid int,
name varchar(20),
deptId int,
salary double,
);
alter table emp4 add primary key ( eid);
删除主键约束
格式:
alter table <数据表名> drop primary key;
实现:
-- 删除单列主键
alter table emp1 drop primary key;
-- 删除联合主键
alter table emp5 drop primary key;
2.自增长约束
在 MySQL中,当主键定义为自增长后,这个主键的值就不再需要用户输入数据了,而由数据库系统根据定义自动赋值。每增加一条记录,主键会自动以相同的步长进行增长。
通过给字段添加 auto_increment 属性来实现主键自增长
语法:
字段名 数据类型 auto_increment
实现:
create table t_user1(
id int primary key auto_increment,
name varchar(20)
);
特点:
- 默认情况下, auto_increment 的初始值是 1 ,每新增一条记录,字段值自动加 1 。
- 一个表中只能有一个字段使用auto_increment 约束,且该字段必须有唯一索引,以避免序号重复(即为主键或 主键的一部分)。
- auto_increment约束的字段必须具备 NOT NULL 属性。 auto_increment 约束的字段只能是整数类型( TINYINT 、SMALLINT 、 INT 、 BIGINT 等。
- auto_increment 约束字段的最大值受该字段的数据类型约束,如果达到上限, auto_increment 就会失效。
指定自增字段初始值
-- 方式 1 ,创建表时指定
create table t_user2 (
id int primary key auto_increment,
name varchar(20)
)auto_increment=100;
--方式2,创建表之后指定
create table t_user3 (
id int primary key auto_increment,
name varchar(20)
);
alter table t_user2 auto_increment=100;
delete 和 truncate 在删除后自增列的变化:
delete:数据之后自动增长从断点开始
truncate:数据之后自动增长从默认起始值开始
3.非空约束
语法:
方式 1 : < 字段名 >< 数据类型 > not null;
方式 2 : alter table 表名 modify 字段 类型 not null;
添加非空约束
--方法1,创建表时指定
create table t_user6 (
id int ,
name varchar(20) not null,
address varchar(20) not null
);
--方法2,之后指定
create table t_user7 (
id int ,
name varchar(20) , -- 指定非空约束
address varchar(20) -- 指定非空约束
);
alter table t_user7 modify name varchar(20) not null;
alter table t_user7 modify address varchar(20) not null;
删除非空约束:
-- alter table 表名 modify 字段 类型
alter table t_user7 modify name varchar(20) ;
alter table t_user7 modify address varchar(20) ;
4.唯一约束
代码如下(示例):
语法:
方式 1 : < 字段名 > < 数据类型 > unique
方式 2 : alter table 表名 add constraint 约束名 unique( 列 );
添加唯一约束 - 方式 1
-- 创建表时指定
create table t_user8 (
id int ,
name varchar(20) ,
phone_number varchar(20) unique -- 指定唯一约束
);
添加唯一约束 - 方式 2
create table t_user9 (
id int ,
name varchar(20) ,
phone_number varchar(20) -- 指定唯一约束
);
alter table t_user9 add constraint unique_ph unique(phone_number);
删除唯一约束
-- alter table < 表名 > drop index < 唯一约束名 >;
alter table t_user9 drop index unique_ph;
5.默认约束
语法
方式 1 : < 字段名 > < 数据类型 > default < 默认值 >;
方式 2: alter table 表名 modify 列名 类型 default 默认值 ;
添加默认约束 - 方式 1
create table t_user10 (
id int ,
name varchar(20) ,
address varchar(20) default ‘ 北京’ -- 指定默认约束
);
添加默认约束 - 方式 2
--alter table 表名 modify 列名 类型 default 默认值
create table t_user11 (
id int ,
name varchar(20) ,
address varchar(20)
);
alter table t_user11 modify address varchar(20) default ‘ 北京’ ;
删除默认约束
-- alter table < 表名 > modify column < 字段名 > < 类型 > default null;
alter table t_user11 modify column address varchar(20) default null;
6.零填充约束
- 插入数据时,当该字段的值的长度小于定义的长度时,会在该值的前面补上相应的 0
- zerofill 默认为 int(10)
- 当使用 zerofill 时,默认会自动加 unsigned (无符号)属性,使用 unsigned 属性后,数值范围 是原值的 2 倍,例如,有符号为 -128~+127 ,无符号为 0~256 。
代码如下(示例):
create table t_user12 (
id int zerofill , -- 零填充约束
name varchar(20)
);
删除
alter table t_user12 modify id int;
总结
MySQL的视图
以上是今天要讲的内容,学到了正则表达式和约束,包括正则表达式的字符和特殊字符,约束的分类,约束的作用,约束的用法。