深度强化学习用于博弈类游戏-基础测试与说明【1】
深度强化学习用于博弈类游戏-基础【1】
- 1. 强化学习方法
- 2. 强化学习在LOL中的应⽤
- 2.1 环境搭建
- 2.2 游戏特征元素提取
- 1)小地图人物位置:
- 2)人物血量等信息
- 3)在整个图像上寻找小兵、防御塔的位置
- 4)自编码器提取
- 3. 策略梯度算法简介
- 参考资料
1. 强化学习方法
伴随着人工智能的潮起潮落,强化学习的从最早期的最优控制发展至今,这段时间里存
在两个重要的时间点。第⼀个关键点是 1998年,Alex M. Andrew出版 Reinforcement
Learning:An Introduction。
该书系统地总结了 1998年以前强化学习算法的各种进展。在此之前,学者们关注和发展得最多的算法是表格型强化学习算法,形成了强化学习的基本理论框架。不过这⼀时期基于直接策略搜索的⽅法也被提出来了,如 1992年 R.J.Williams提出了 Reinforce算法直接对策略梯度进⾏估计。在 1998年到 2013年,学术界继续发展出了各种直接策略搜索的⽅法。
第⼆个关键点是 2013年 DeepMind提出 DQN,将深度⽹络与强化学习算法结合形成深度强化学习,并在 alphago系列中取得了成功应⽤。在这之后深度强化学习继续发展,形成了更多的算法,例如 DDPG,TRPO,A2C,ACER,PPO等,并取得了很⼤的应⽤进展,如 openAI的 dota,以及 DeepMind的 alpha star。
强化学习要解决的是序列决策问题,它不关心输⼊⻓什么样,只关心当前输⼊下应该采
⽤什么动作才能实现最终的⽬标,作为⾏为主义的代表,它依靠与环境进⾏交互来学习。这
与监督学习和⾮监督学习有本质的区别,监督学习知道学习过程中的正确结果是什么,希望
结果运⽤到未知的数据中去,要求结果可推广化,可泛化。强化学习不知道学习过程中的结
果,通过奖励信号学习。⾮监督学习旨在发现数据之间的隐含结构(如聚类分析),强化学
习有着明确的数值⽬标(最⼤化奖励)。
⽬前的强化学习算法可以分为有模型学习和无模型学习,如果知道了环境的数学模型,
也即知道了 P(s’,r|s,a)——在 s状态下采取 a动作,会进⼊到 s’状态并获得 a收益的概率,那
么则是有模型学习,这⼀块主要是动态规划⽅法和直接求解贝尔曼⽅程法求取动作价值函数
和状态价值函数。无模型学习则是不知道环境数学模型,⽬前的研究基本都是不知道环境数学模型的,学习的经验通过与环境进⾏交互得到。强化学习问题求解的⽬标可以当作是对价值函数或者策略函数的求解,基于此在无模型学习中,便有蒙特卡洛⽅法,时序差分⽅法, 函数近似⽅法,在这些⽅法中根据学习的经验来源可以分为 on policy和 offpolicy。⽬前较热的深度强化学习主要使⽤了函数近似的思路,即利⽤神经⽹络得到状态输⼊与价值输出或者策略输出的函数。
2. 强化学习在LOL中的应⽤
2.1 环境搭建
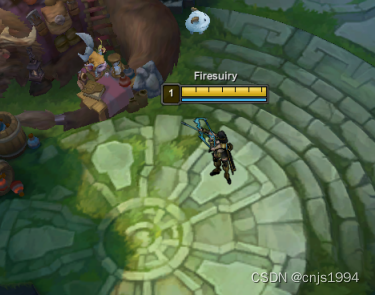
该部分主要包括如何搭建⼀个环境,该环境需要可以获知当前游戏状态,对当前游戏发送动作对环境进⾏改变。在本文中,从游戏获得的观测为游戏的图像,如图 1所⽰,对游戏的操作包括键盘操作和鼠标对应位置的点击。实现这些功能⽤到了 Vmware虚拟机,⼤漠插件,python等。由于与主题关系不⼤这里不再赘述。由于水平限制,游戏中使⽤的是训练模式,默认情况下没有敌⽅英雄,根据游戏结束时⻓来判断游戏水平。
PS: 但实际上,交互的有效性很大程度上取决于获取信息的精准性,对于LOL这种即时对战类游戏,获取当前状态下的生命值、攻击力等参数而不是通过OCR等技术去定性学习,可能效果会更好,但那就涉及到多模态信息的学习了,这里的方法采用的是完全基于图像信息的深度强化学习模型搭建。
2.2 游戏特征元素提取
游戏图像主要包括 UI功能模块,小地图,当前角色所在⼤地图等区域。我们从游戏获取的特征为:小地图上人物位置,当前人物血量,金钱等信息,⼤地图上小兵位置,防御塔位置信息,自编码器特征提取向量。
1)小地图人物位置:
获知当前英雄在小地图上的位置,实现⽅法为特征匹配,在小地图中可以明显看到,在我⽅英雄周围有⼀个白色的⽅框(如图 2所⽰),特征⾮常明显。具体算法:对图像使⽤阈值法进⾏⼆值化,将图像对⾏和列分别求和,得到像素位置分布,使⽤聚类算法得到矩形的边的具体位置。
2)人物血量等信息
主要是血量和金钱,使⽤图色识别等⽅法即可,不再赘述。
3)在整个图像上寻找小兵、防御塔的位置
游戏状态原图像如图 3所⽰,需要获取所有蓝色小兵和红色小兵的位置。鉴于此为⼀个多⽬标识别问题,初始尝试使⽤ Yolov3⽹络模型进⾏识别,但利⽤ labelImg标注⼀部分图片进⾏测试后发现效果不是很好。考虑到小兵的血条对于整个图像上来说是十分明显的,是⼀个黑色的矩形框,其中包含蓝色或者红色,这⾮常适合使⽤ cv2中的模板匹配⽅法,经过测试这种⽅法在小兵血条未遮盖的情况下效果很好。
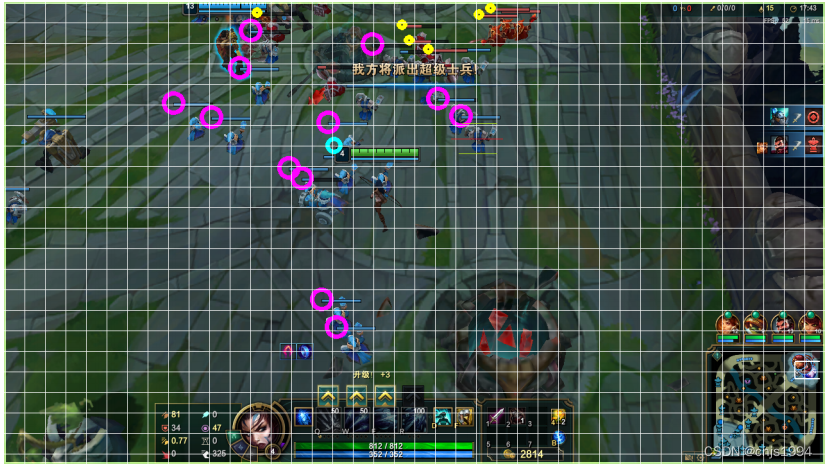
于是我们将⼀张图片划分为 22*44个区域,利⽤模板匹配识别小兵的⽅法给图片中小兵的血条区域进⾏标注,由此构建了样本集,并构造卷积神经⽹络进⾏小兵识别的训练,最终得到小兵的位置,防御塔识别的处理⽅法与小兵识别⽅法相同。
4)自编码器提取
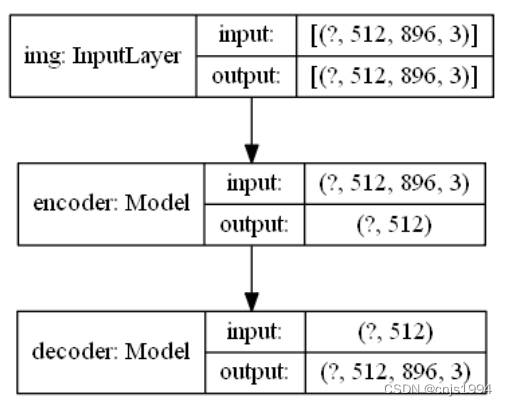
除了以上特征外,为了提供整个游戏状态的更多特征,加⼊了⼀个自编码器,模型如图,将原图进⾏ resize,再采⽤多层卷积加全连接的⽅式进⾏,神经⽹络结构为 encoder和 decoder。经过训练自编码器的效果可以勉强看出防御塔,效果比较⼀般,从图像得到⼀个 512⻓度的向量特征。
3. 策略梯度算法简介
策略梯度算法属于函数近似算法的⼀种,将策略参数化(Π(θ,s)),利⽤参数化的线性函数或⾮线性函数(如神经⽹络)表⽰策略,寻找最优的参数,使强化学习的⽬标(1),其中 P(t;θ)为第 t个轨迹出现的概率——累积回报的期望最⼤(2);这样求解问题变成了⼀个最优化问题,可以利⽤梯度上升法,对累计回报——⽬标函数计算梯度。
这里着重描述一下有限差分策略梯度:
到目前为止,我们学习的所有方法几乎都是价值函数方法,这些方法学习价值函数,然后根据价值函数来选择动作。如,上一讲的价值函数近似。而本讲我们将学习的内容不需要求助价值函数也能优化策略,即通过学习参数化的策略。所谓参数化的策略,指我们用
θ
\theta
θ作为策略的参数向量:
π ( a ∣ s , θ ) = P r { A t = a ∣ S t = s , θ t = θ } \pi \left( a|s,\theta \right) =Pr\left\{ A_t=a|S_t=s,\theta _t=\theta \right\} π(a∣s,θ)=Pr{At=a∣St=s,θt=θ}
上述公式是指,假设智能体处于状态s,时间t,在参数 的环境中,在时间t采取动作a的概率。简单地说,策略梯度直接对策略进行建模,然后进行优化,得到最优策略。
参考资料
【1】Github-AutoLOL