PostgreSQL InvalidMessage Cache 同步机制
文章目录
- 背景
- InvalidMessages 基本类型
- InvalidMessages 数据结构概览
- 共享内存 的 "ring-buffer" 结构
- Backend 本地的 InvalidMessages管理
- SharedInvalCatalogMsg
- SharedInvalCatcacheMsg
- SharedInvalRelcacheMsg
- SharedInvalSnapshotMsg
- SharedInvalSmgrMsg
- SharedInvalRelmapMsg
- InvalidMessages 消费
- 总结
背景
之前系统介绍过 PostgreSQL 对 系统表的管理 以及 SysCache 和 RelCache的实现,这一些Cache 其实都是 Backend(进程)级别的 Cache,一个 PG 实例可以起多个Backend,这一些Backend 会有数据共享的需求,比如 访问同一张用户表/系统表,那么就会有 RelCache 和 SysCache的同步需求了。
Cache 同步的需求在如今的软件设计或者硬件设计中是非常普遍的。 Cache 本质上利用DRAM 或者 集成在CPU 内部的 三级Cache 来实现数据的冷热分离,从而能够加速软件的读性能。像我们的CPU 的 MESI 就是为了保证多物理核 CacheLine 之间的变量一致性。这一些Cache 一致性协议的实现一般都是通过同步广播,即运行在当前物理核上的线程修改了一个变量值,会在总线同步广播这个变量的invalidate 信息,从而能够让其他核心上的线程知道这个变量被修改了。 当然 这样的实现会消耗总线的带宽,如今我们的服务器大多都是 NUMA 架构,CPU 之间的距离更远了,总线带宽也更珍贵了,所以会采用 Directory-based 仅同步到其他也在访问这个变量的 cpu核心。
当然 内存屏障也是做同样类似的事情,保障 cpu-cacheline 和 内存之间的数据同步,其他 cache 系统的实现也都是类似的,就是将数据的最新修改进行同步。
PG 的Cache同步机制实现有一些差异,不同的 Backend进程对于数据类型的访问需求是不同的,有一些backend 不需要其他backend修改的数据(比如不同表的relacache / syscache 内容),那就没有必要同步给所有的进程了。所以 PG 采用的是 Invalidation Messages 同步机制,会将当前 backend 修改内容以 失效消息的方式发给其他backend,其他 backend 收到消息之后将本地相应内容的缓存移除掉,后续对该内容的访问会因为缓存未命中转转为扫描 HEAP 存储,因为 HEAP 支持 MVCC 且被整个PG实例共享,所以是能保证不同Backend访问的一致性。
接下来看看 PG 在实现 Cache 一致性过程中的一些有趣 且 严谨的细节。
本文提到的 PG 代码版本是基于
REL_12_STABLE
InvalidMessages 基本类型
概览整个失效消息的存储形态之后,接下来看看具体的 msg 都是一些什么内容。
PG 总共提供了 六种 失效消息类型,用于失效存储于 进程各自本地内存中的缓存数据。
typedef union
{
int8 id; /* type field 唯一标识一个失效消息的类型 */
SharedInvalCatcacheMsg cc;
SharedInvalCatalogMsg cat;
SharedInvalRelcacheMsg rc;
SharedInvalSmgrMsg sm;
SharedInvalRelmapMsg rm;
SharedInvalSnapshotMsg sn;
} SharedInvalidationMessage;
- SharedInvalCatcacheMsg
指定 syscache 中某一个 tuple 的缓存失效。上一篇介绍 syscache的结构时应该知道某一个 系统表的 tuple 可能会存储在多个syscache中。这个 msg 会将该tuple的所有缓存都移除。对于 msgid >= 0 的表示要失效的 syscacheid,< 0时则表示不同的失效消息类型,能够有效节约存储空间。typedef struct { int8 id; // >=0 标识 syscache id Oid dbId; // 数据库 oid uint32 hashValue;// tuple 对应的 hash值,标识在cache中的唯一tuple } SharedInvalCatcacheMsg; - SharedInvalCatalogMsg 指定失效系统表的所有 syscache 内容
typedef struct { int8 id; // -1 Oid dbId; // 数据库 oid Oid catId; // 系统表 oid } SharedInvalCatalogMsg; - SharedInvalRelcacheMsg 指定失效 dyna_hash 管理的 某一个表的 RelationCache的缓存。
后面的这三种 msgs 类型并不属于 前面的 cache体系,其也是有对应的内存缓存,且有数据一致性的访问需求,所以需要有 invalid msgs.typedef struct { int8 id; // -2 Oid dbId; Oid relId; // 用户表 oid } SharedInvalRelcacheMsg; - SharedInvalSmgrMsg 标识 某一个表的 物理文件对应的 smgr-cache失效
typedef struct { int8 id; // -3 int8 backend_hi; // 保存backendId的高8位 uint16 backend_lo; // 保存 backendId 低16位,如果是temp表,backendId是有效的 RelFileNode rnode; // 唯一标识一个 relation的 物理文件访问链路 } SharedInvalSmgrMsg; - SharedInvalRelmapMsg 标识失效指定数据库的 relmapper
typedef struct { int8 id; // -4 Oid dbId; } SharedInvalRelmapMsg; - SharedInvalSnapshotMsg 指定失效 backend 保存的系统表的 snapshot
typedef struct { int8 id; // -5 Oid dbId; Oid relId; } SharedInvalSnapshotMsg;
InvalidMessages 数据结构概览
因为 InvalidMessages 是用来标识 cache内 部分内容无效的,所以仅保存一些标识性的信息,单个msg的数据量并不会很大,但是如果backend数量多且处于频繁的update 或者 ddl 压测状态下 msgs 的条数会有很多。 PG 对于 msgs 的管理采用的是 ring-buffer的形态。即维护一个容量有限的环形缓冲区,通过minMsgNum 和 maxMsgNum 来标识当前最新 以及 最旧的未被其他backend消费的 msg index。
对于msgs 的具体内容以及什么情况下发送msgs 或者接受 msgs 后文会详细展开,先概览一下其基本的管理结构。
整体的 Invalidation Messages 的数据管理形态如下:
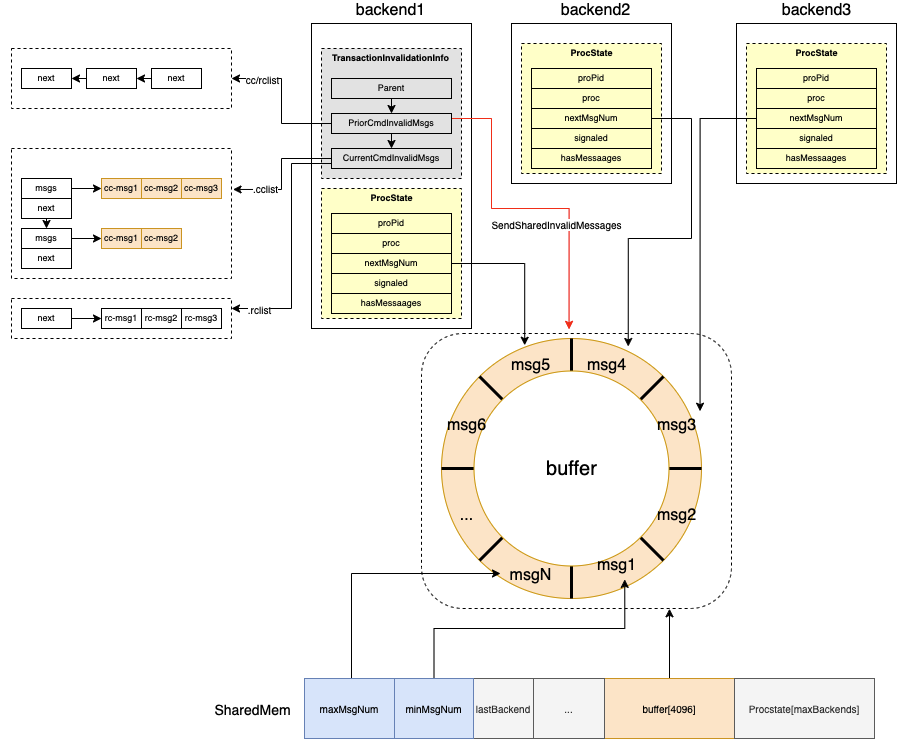
- 首先被所有的backend 共享的ring-buffer 是存储在共享内存中的,需要保证能被其他 backend消费。这一部分是通过
SISeg数据结构来管理。 - 每一个 backend 还会自管理本地的 InvalidMessages,即在这个 backend运行期间执行的 query 对自己的 cache 产生的 invalidation messages 会先放在 backend 本地的
TransactionInvalidationInfo数据结构中,等到 query 所在的事务 commit / abort 时再将自己管理的本地的msg 发送给由 共享内存中的 ring-buffer。 - 每一个 backend 除了维护自己 local 的invalidMessages 之外,还会将自己消费的 ring-buffer 中的msg-index 等信息 通过
ProcState结构管理起来,方便对 ring-buffer 中已经消费过的 或者 ring-buffer 超限情况下的 msgs 进行清理。
共享内存 的 “ring-buffer” 结构
画出上面的那个环形 “ring-buffer” 结构 本质上是一个msgs 数组,只是 PG 为了方便对这个数组进行管理,通过 minMsgNum 和 maxMsgNum 两个字段划分除了一个 MAXNUMMESSAGES - 4096 大小的buffer,两个字段的值随着 msgs 不断添加到数组中会持续增大,但是取 具体的数组内容的时候会通过 maxMsgNum % MAXNUMMESSAGES 做为 数组下标 来取。 这样 4096 大小的一个环形窗口区间就形成了,这个窗口内的msg都是有效的 invalidation messages ,需要被backend消费。小于 实际的 minMsgNum的 msg 则是无效的msgs,如果某一个backend 本地保存的 procstate->nextMsgNum 是 小于 minMsgNum,意味着 这个backend 因为一些原因(系统负载过大,产生的失效消息过多)cache内部的数据版本过低, 则这个backend 需要 reset 自己本地的所有cache,保证后续的读都走heap 表才能拿到正确的数据。
minMsgNum 和 maxMsgNum 是 int类型,即超过 2^(32-1)就发生回卷了,随着msgs 不断插入到 buffer中,也需要考虑这两个下标的回卷问题,而且需要确保回卷之后仍然能够维持 "ring-buffer"的形态。
SISeg的结构如下:
typedef struct SISeg
{
/*
* General state information
*/
int minMsgNum; /* oldest message still needed */
int maxMsgNum; /* next message number to be assigned */
int nextThreshold; /* # of messages to call SICleanupQueue */
int lastBackend; /* index of last active procState entry, +1 */
int maxBackends; /* size of procState array */
slock_t msgnumLock; /* spinlock protecting maxMsgNum */
/*
* Circular buffer holding shared-inval messages
*/
SharedInvalidationMessage buffer[MAXNUMMESSAGES];
/*
* Per-backend invalidation state info (has MaxBackends entries).
*/
ProcState procState[FLEXIBLE_ARRAY_MEMBER];
} SISeg;
可以看到 这个数据结构中也保存了 ProcState,用于快速访问 其中的 nextMsgNum字段,从而能够确定清理 buffer 的下界。这个类型有一个全局的变量 shmInvalBuffer 在如下栈中完成初始化 并存储在共享内存中:
CreateSharedInvalidationState
CreateSharedMemoryAndSemaphores // 初始化所有的共享内存相关的变量
InitCommunication
BaseInit
PostgresMain
BackendRun // 初始化backend
BackendStartup
ServerLoop
PostmasterMain
main
其中的 ProcState 字段实在下面这个栈完成初始化的,因为初始化 共享内存变量时还没有完成 PROC 相关结构的构造:
SharedInvalBackendInit // 完成 SISeg->procState 的初始化
InitPostgres // 初始化 postgres 即 backend进程
PostgresMain
BackendRun // 初始化backend
BackendStartup
ServerLoop
PostmasterMain
Backend 本地的 InvalidMessages管理
Backend 会在本地临时存放一些 invalid msgs,用于管理当前backend 本地执行中事务产生的 invalidation-messages,在事务commit/abort时 集中发送到共享内存中的buffer结构中。
query 执行过程中 msg 是会保存到 全局变量 TransInvalidationInfo中,通过函数 AddInvalidationMessage 或者 AppendInvalidationMessageList完成:
AddInvalidationMessage
AddCatalogInvalidationMessage // inval 指定syscache 所有tuple
AddCatcacheInvalidationMessage // inval 指定tuple
AddRelcacheInvalidationMessage // inval relcache
AddSnapshotInvalidationMessage // inval snapshot
AppendInvalidationMessageList
AppendInvalidationMessages(2 usages)
AtEOSubXact_Inval // 子事务结束 abort/commit
AtEOXact_Inval // 事务结束 abort/commit
CommandEndInvalidationMessages // 子事务或者事务 中的一个 query结束
在 AddInvalidationMessage函数中,会将msg 添加到 CurrentCmdInvalidMsgs->cclist 或者 CurrentCmdInvalidMsgs->rclist 链表,分别保存 syscache 和 relcache 相关的msg,如果链表容量不足,则需要扩容。
AppendInvalidationMessageList函数 是说将一个 invalidation message list 和 另一个进行合并。它的应用场景是在事务结束边界 或者 事务内部query执行完成的命令边界进行的,比如当前事务执行完毕,在 AtEOXact_Inval 中,如果事务是commit,则需要合并一下 transInvalInfo 中保存的msg list,主要是将 transInvalInfo->CurrentCmdInvalidMsgs 合并到 transInvalInfo->PriorCmdInvalidMsgs 中。然后统一将 transInvalInfo->PriorCmdInvalidMsgs 添加到共享内存中的 invalidation messages。PriorCmdInvalidMsgs 保存的是上一个命令(query)的 msg-list,一个事务内会有多条 query,每一个query执行完都通过 CommandEndInvalidationMessages 完成msg 向上一个 query msg-list的合并,最后在 AtEOXact_Inval 完成事务的所有 query,统一发送到共享内存。
void
AtEOXact_Inval(bool isCommit)
{
...
if (isCommit) // 事务 commit
{
...
// msg lists 合并, CurrentCmdInvalidMsgs --> PriorCmdInvalidMsgs
AppendInvalidationMessages(&transInvalInfo->PriorCmdInvalidMsgs,
&transInvalInfo->CurrentCmdInvalidMsgs);
// 通过 SendSharedInvalidMessages 添加到共享内存的结构中
ProcessInvalidationMessagesMulti(&transInvalInfo->PriorCmdInvalidMsgs,
SendSharedInvalidMessages);
if (transInvalInfo->RelcacheInitFileInval)
RelationCacheInitFilePostInvalidate();
}
else // 事务 abort
{
// 将上一个 query的 invalid-message 应用到本地,因为事务已经abort了
ProcessInvalidationMessages(&transInvalInfo->PriorCmdInvalidMsgs,
LocalExecuteInvalidationMessage);
}
...
}
有一个细节需要注意,就是在事务 abort 的时候 我们需要将 PriorCmdInvalidMsgs 链表中的 msgs 应用到 backend 本地的 cache中,即标识对应的缓存失效,将相应的record 从缓存中移除。这其实是 invalid-msgs 在cache中回滚的一种方式,当然是比较间接的实现,就是事务abort时将旧的修改过的缓存内容从cache中移除,让下一个事务 中 query对相同内容的访问从 heap中直接读。毕竟 cache 没有支持 MVCC,只能通过这种牺牲性能节约内存的方式来实现了。
AppendInvalidationMessageList 函数只会在事务、命令执行的边界调度, AddInvalidationMessage 函数则是构建 CurrentCmdInvalidMsgs 链表,我们通过 AddInvalidationMessage 函数被调度四个场景看看 不同的invalidMessages 都是在什么场景下产生的。
SharedInvalCatalogMsg
这个类型的 invalid-msg 是说将指定的 syscache 内所有的内容都标记失效。它主要用在 对系统表进行 VACUUM FULL/CLUSTER 或者 Alter table 时的对应cache内容的统一清理。因为对系统表进行 ALTER 以及 CLUSTER 意味着需要对系统表中巨量的行进行修改,这个时候显然需要产生大量的 invalid msgs.
SharedInvalCatcacheMsg
这个 msg 是标记 指定 syscache 中的指定 tuple 失效,所以这个 msg 显然是tuple粒度。对系统表中的指定 tuple 进行修改,会生成这个 msg。
有如下几个场景(调用栈是从下向上的 😃 … 我直接用的是clion的 calltree,极为方便):
RegisterCatcacheInvalidation
CacheInvalidateHeapTuple
AlterDomainAddConstraint
AlterDomainDropConstraint
heap_delete
heap_inplace_update
heap_insert
heap_multi_insert
heap_update
在 CacheInvalidateHeapTuple 函数中 会确保只有 catalog-relation 且 不是toast 的情况才会注册 invalid msg。
void
CacheInvalidateHeapTuple(Relation relation,
HeapTuple tuple,
HeapTuple newtuple)
{
...
// catalog relation
if (!IsCatalogRelation(relation))
return;
// toast relation
if (IsToastRelation(relation))
return;
// 初始化 transInvalInfo 本地 msg结构
PrepareInvalidationState();
tupleRelId = RelationGetRelid(relation);
if (RelationInvalidatesSnapshotsOnly(tupleRelId))
{
// 当前tuple的系统表是没有syscache的,发送 SharedInvalSnapshotMsg msg
databaseId = IsSharedRelation(tupleRelId) ? InvalidOid : MyDatabaseId;
RegisterSnapshotInvalidation(databaseId, tupleRelId);
}
else
// 有syscache
PrepareToInvalidateCacheTuple(relation, tuple, newtuple,
RegisterCatcacheInvalidation);
...
}
其中也有一个有趣的细节,就是对于没有 syscache 的系统表通过 RegisterSnapshotInvalidation 发送 SharedInvalSnapshotMsg。虽然这个系统表没有 syscache,但是其内容发生了修改,需要让其它的backend能够知道当前系统表发生了修改。标记对应backend的 CatalogSnapshot 为空,并从管理 CatalogSnapshotData的 paringheap中移除堆顶的数据, 后续需要访问catalog时需要重新获取最新的 CatalogSnapshot。
通过 paringheap 管理的
CatalogSnapshotData是为了防止事务在没有 系统表修改的情况下通过GetSnapshotData获取snapshot(性能优化)。GetSnapshotData这个函数太重了且系统表没有修改,完全没有必要走这个逻辑。只有系统表发生了修改,接收到 invalid snapshot msg之后,再重新拿snapshot 才更加高效。
对于拥有 syscache的系统表,则通过 RegisterCatcacheInvalidation 注册 catCache invalid msg就好了。
该msg 被其他backend或者 自己 在 LocalExecuteInvalidationMessage函数中 的处理逻辑是通过如下三个函数完成:
// 因为也是系统表发生了修改,需要标记snapshot无效,下次拿新的snapshot
InvalidateCatalogSnapshot();
// 将对应的tuple 从syscache的结构中移除,即将syscache中与 hashValue一样的 `CatCTup` 从数据链表中移除(需保证 refcount 为0)
SysCacheInvalidate(msg->cc.id, msg->cc.hashValue);
// 有一些其他的类似plancache/trigger 等存储于内存中且于 syscache相关的内容也需要调用对应的 reset 函数,统一执行一次它们注册的callback.
CallSyscacheCallbacks(msg->cc.id, msg->cc.hashValue);
SharedInvalRelcacheMsg
这个 msg 是标识 relcache 中的内容失效,传入 数据库oid + 表oid。 RelCache 中通过 dyna_hash 保存的是 RelationData,通过这个数据结构可以描述一个表信息。
也就是如果有对 RelationData 中修改的任何操作都会导致 RelCache中保存的内容失效,主要产生的函数如下:
RegisterRelcacheInvalidation
CacheInvalidateHeapTuple
CacheInvalidateRelcache
CacheInvalidateRelcacheAll
CacheInvalidateRelcacheByTuple
因为 Relation 或者说表的描述信息 的构建是需要在 pg_class,pg_type,pg_attribute,pg_auth,pg_index等这样的系统表中添加 某一个表的描述信息,所以如果这一些系统表中某一个表的内容发生改变,那么需要让对应表的 RelCache失效,其他的 backend 需要重新构造 Relation信息。
所以 上面的四种函数主要是处理不同场景中 Relation 中对应的描述信息的修改需要被其他 backend知道。
比如 CacheInvalidateRelcache 需要处理 index信息 被修改的情况,像是发生了 index_create,index_drop, reindex_index。
对于 SharedInvalRelcacheMsg 的本地消费 则同样是在 LocalExecuteInvalidationMessage函数中:
if (msg->rc.dbId == MyDatabaseId || msg->rc.dbId == InvalidOid)
{
int i;
if (msg->rc.relId == InvalidOid)
// CacheInvalidateRelcacheAll 清理 relcache中所有的内容
RelationCacheInvalidate(false);
else
// 清理指定 relid的 relcache内容
RelationCacheInvalidateEntry(msg->rc.relId);
// 处理与 relcache相关联的所有的 cache callback
for (i = 0; i < relcache_callback_count; i++)
{
struct RELCACHECALLBACK *ccitem = relcache_callback_list + i;
ccitem->function(ccitem->arg, msg->rc.relId);
}
}
SharedInvalSnapshotMsg
这个msg 类型前面已经介绍过了,如果没有syscache的系统表发生修改,需要通过这个 msg告知其他 backend 重新拿最新的 catalogsnapshot就好了,其生成场景和 SharedInvalCatcacheMsg 是一样的。
RegisterSnapshotInvalidation
CacheInvalidateHeapTuple
AlterDomainAddConstraint
AlterDomainDropConstraint
heap_delete
heap_inplace_update
heap_insert
heap_multi_insert
heap_update
对于 这种msg的本地消费,则是通过如下函数完成:
/* 共享系统表 类似 pg_auth,pg_database (声明在 BKI_SHARED_RELATION),则dbId会设置为 InvalidOid */
if (msg->sn.dbId == InvalidOid)
InvalidateCatalogSnapshot();
else if (msg->sn.dbId == MyDatabaseId)
InvalidateCatalogSnapshot();
在 InvalidateCatalogSnapshot 将 CatalogSnapshot从全局snapshot的paringheap中移除,并标记 CatalogSnapshot 为NULL。下次获取 catalogsnapshot的时候会重新从 GetNonHistoricCatalogSnapshot获取。
还有最后两种与 smgr 和 relmap 相关的msg,直接看看这两种 msg的应用场景。
SharedInvalSmgrMsg
这个 msg 用于指定 backend 强制关闭 smgr 引用。如果一个 backend 对某一个表的 heap文件内容进行了修改、删除、截断等操作时,需要让其他的bakend关闭对当前 heap文件的引用。
CacheInvalidateSmgr
smgrdounlink
smgrdounlinkall
smgrdounlinkfork
smgrtruncate
vm_extend
msg的本地消费是通过如下逻辑完成,如果从 backend 本地的hash表 SMgrRelationHash 找到 要失效的 rnode,则将本地保存的所有rnode信息都从内存移除,关闭文件句柄。
else if (msg->id == SHAREDINVALSMGR_ID)
{
/*
* We could have smgr entries for relations of other databases, so no
* short-circuit test is possible here.
*/
RelFileNodeBackend rnode;
rnode.node = msg->sm.rnode;
rnode.backend = (msg->sm.backend_hi << 16) | (int) msg->sm.backend_lo;
smgrclosenode(rnode);
}
这个msg类型 和下面的
SharedInvalRelmapMsg一样都没有事务语义,产生之后会直接放进共享内存中等待被消费。
SharedInvalRelmapMsg
这个msg 会指定其他的backend 重新加载 pg_filenode.map。关于pg_filenode.map,可以参考之前的介绍,其主要用于 nailed 系统表数据的本地文件管理,比如 pg_class 系统表本身无法自管理自己的relfilenode,因为initdb的时候 pg_class,pg_type,pg_attribute等这样的系统表需要被先加载,需要有一个地方去拿这一些系统表的heap文件(正常的用户表的heap文件是可以从pg_class拿到,但是pg_class本身初始化数据库的时候没有地方拿),就都放在了 pg_filenode.map中。
如果 某一个数据库的这个文件内容发生了修改了,比如reindex/cluster nailed系统表,它们的磁盘文件生成新的。意味着其他backend需要能够获取最新的数据文件,所以需要重新加载这个文件。即通过如下逻辑 消费 SharedInvalRelmapMsg :
else if (msg->id == SHAREDINVALRELMAP_ID)
{
// InvalidOid 表示共享数据库 global目录下的 文件被修改了。
if (msg->rm.dbId == InvalidOid)
RelationMapInvalidate(true);
else if (msg->rm.dbId == MyDatabaseId) // 当前数据库目录下的文件被修改,重新加载就好了
RelationMapInvalidate(false);
}
InvalidMessages 消费
前面介绍了这几种 msgs 类型在何种场景下被生成并缓存到本地 以及对应的处理逻辑。接下来我们看看这一些 msgs 在共享内存如何被处理。
在事务执行结束时会通过 AtEOXact_Inval --> SendSharedInvalidMessages --> SIInsertDataEntries 将当前Backend本地收集到的 invalid-msgs 发送到共享内存。
在 SIInsertDataEntries 函数处理 msg 的逻辑如下:
- 将msg 拆分为
WRITE_QUANTUM最大 64个 msgs 一组,按照组集中插入msg 到 共享内存中的 SISeg 结构。 - 插入前先检查共享内存中维护的 buffer 是否已满,如果满则需要通过
SICleanupQueue清理。
判断满是通过检查(maxMsgNum - minMsgNum + nthistime(64)) > MAXNUMMESSAGES (4096),buffer中 加上当前bacth的 msgs 已经超过了4096,则需要进行清理。 - 如果没有满,就将当前batch的 msgs 循环插入到 共享内存中,并更新 共享内存的
maxMsgNum和procstate->hasMessages。
void
SIInsertDataEntries(const SharedInvalidationMessage *data, int n)
{
SISeg *segP = shmInvalBuffer;
while (n > 0)
{
// 计算要batch 的msgs 个数
int nthistime = Min(n, WRITE_QUANTUM);
int numMsgs;
int max;
int i;
n -= nthistime;
/* 如果满,则清理 */
for (;;)
{
numMsgs = segP->maxMsgNum - segP->minMsgNum;
if (numMsgs + nthistime > MAXNUMMESSAGES ||
numMsgs >= segP->nextThreshold)
SICleanupQueue(true, nthistime);
else
break;
}
/* 如果没满,则插入到共享内存 */
max = segP->maxMsgNum;
while (nthistime-- > 0)
{
segP->buffer[max % MAXNUMMESSAGES] = *data++;
max++;
}
/* 更新共享内存的 maxMsgNum */
SpinLockAcquire(&segP->msgnumLock);
segP->maxMsgNum = max;
SpinLockRelease(&segP->msgnumLock);
/* 更新 procstate, 标识当前 backend 是有msg 的 */
for (i = 0; i < segP->lastBackend; i++)
{
ProcState *stateP = &segP->procState[i];
stateP->hasMessages = true;
}
}
}
发送到共享内存之后其他的 backend 在一些特殊的时机会通过 AcceptInvalidationMessages --> ReceiveSharedInvalidMessages 来拉取 msgs到本地。
应用invalidation messages 到本地的场景如下:
- 事务开启的时候,通过
AtStart_Cache拉取共享内存的msg 并应用到本地。前面也提到事务结束时会发送invalid msgs 到共享内存。 - backend 或者 后台进程 启动时 也会应用一下 invalid-messages,初始化子进程时构造的syscache 内容可能被其他子进程修改(比如shared 系统表),这个时候就需要处理 invalid relmapper msg。
- 加锁场景:
LockDatabaseObject,LockRelation,LockRelationOid,LockSharedObject等。这一些加锁是常规锁(regular lock),能够确保有冲突的对象的访问是会有等待关系的,加锁时本地应用 invalid msgs 是能够确保后续访问该对象时 cache中的内容是一致的。
在 ReceiveSharedInvalidMessages 函数中会遍历所有的要应用到本地的invalid-msgs,逐个执行 LocalExecuteInvalidationMessage进行本地的msg处理。其中有一个也是前面提到的 清理共享内存 msg的函数 SICleanupQueue,这个函数比较核心,用来维护 共享内存 msg 缓冲区的可用性,主要做如下几个事情:
- 本地backend完成 msg消费之后 需要清理掉这一些msg
- 如果 buffer满了,必须要清理旧的msg
- 检查所有的backend的procstate,如果有procstate->nextMsgNum 小于 buffer的最小边界(这个backend有很长时间没有执行query/系统负载比较大,它的消费速度没有跟得上msg的生产速度),则需要标记其 resetState。后续它需要清理本地所有的cache内容,重新从heap表读数据并重新构建cache。
- 遍历其他backend过程中发现如果这个backend的 nextMsgNum < maxMsgNum - 2048,就触发一次 CATCHUP signal,可以让这个backend 在idle的时候消费一下共享内存的msg。
其中计算 buffer 清理的边界如下:
min = segP->maxMsgNum;
lowbound = min - MAXNUMMESSAGES + minFree; // minFree表示要释放的msgs个数
遍历procstate,检查每一个backend的msg消费情况,并做对应的清理逻辑如下:
for (i = 0; i < segP->lastBackend; i++)
{
ProcState *stateP = &segP->procState[i];
int n = stateP->nextMsgNum;
...
// 处理第三种情况,当前 proc 的msg消费太慢,以及低于 buffer的下界了,需要reste 该proc的所有缓存
if (n < lowbound)
{
stateP->resetState = true;
/* no point in signaling him ... */
continue;
}
// 记录 minMsgNum 边界
if (n < min)
min = n;
// 判定是否需要利用 CATCHUP 信号让当前proc 加速msg的消费
if (n < minsig && !stateP->signaled)
{
minsig = n;
needSig = stateP;
}
}
总结
到此,整个 Invalidation Messages 如何实现Cache一致性就介绍完了。
- Backend 本地会缓存 本地命令执行期间的invalid message,在事务提时 batch发送 invalid-message到共享内存;终止时本地应用invalid-message。
- 共享内存中利用 min/maxMsgNum 维护了的 环形缓冲区来保存每一个backend生产的msg。每一个Backend 也在各自启动事务、或者加锁访问数据库对象时消费共享内存的 msg,根据msg 类型移除对应的缓存内容,来让backend本地的query访问的 MVCC数据和其他的backend访问的一致。消费完成之后需要做 msg 的清理,确保缓冲区不会消耗过多的内容。