了解了表索引的底层是B+树结构,我们也要学会如何将这个结构的优势发挥出来,我们先来回顾上一节的重点,也就是总结一下B+树的特点 索引对应的是一棵B+树,而B+树对应的很多层,每一层存储的数据对应的是下一层节点的位置,最底层存放的是用户数据记录 B+树中每层节点都是按照索引列值从小到大的顺序排序而组成了双向链表,而且每个页内的记录(不论是用户记录还是目录项记录)都是按照索引列的值从小到大的顺序而形成了一个单链表。如果是联合索引的话,则页面和记录先按照联合索引前面的列排序,如果该列值相同,再按照联合索引后边的列排序。 通过索引查找记录是从B+树的根节点开始,一层一层向下搜索。由于每个页面都按照索引列的值建立了Page Directory(页目录),所以在这些页面中的查找非常快。 一个东西的诞生肯定有好有坏,索引也有好处和坏处 好处:查询更快 坏处:
需要更多的空间去存放,我们知道每一个索引就是一棵b+树,所以索引建的越多,空间占用就会越大 对记录进行维护的性能消耗更大,因为我们是通过一个链表进行连接的,但你要对其中一个节点进行操作的时候,性能可想而知,并且你如果改变的是索引的相关数据,你还要将索引的B+树一起维护。 鉴于以上索引的缺点,我们需要合理的创建索引和使用索引,因为不规范的使用,会导致索引无法生效,下面根据常用的业务场景,我们从三个维度去讲解如何使用索引 为了方便理解我们也建一个表 CREATE TABLE person(
id INT NOT NULL auto_increment ,
name VARCHAR ( 100 ) NOT NULL ,
birthday DATE NOT NULL ,
phone_number CHAR ( 11 ) NOT NULL ,
country varchar ( 100 ) NOT NULL ,
PRIMARY KEY ( id) ,
KEY idx_name_birthday_phone_number ( name, birthday, phone_number)
) ;
主键索引我们这边就画图了,重点是联合索引,联合索引比较复杂,我们这边画一个图 联合索引的排序上一节也讲了,是根据字段的顺序来排序的,举个例子,idx_name_birthday_phone_number 这个索引树,排序是这样的: 先按照name排序 在name值相等的情况下,再根据birthday排序 在name和birthday值相等的情况下,再根据phone_number 排序 数值类型的排序相比大家都清楚,但是字符串的排序是怎么样的呢? 字符串的本质还是比较大小,不过他们是根据字母顺序的大小进行排序的,比如说 A 就比 B大,如果都是A 则比较第二个字母,比如 Aa 就比 Ab大,以此类推 总结一下就是下面的过程:
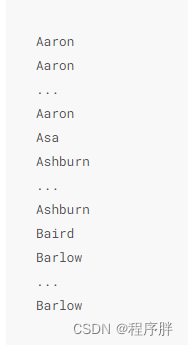
先比较字符串的第一个字符,第一个字符小的那个字符串就比较小 如果两个字符串的第一个字符相同,那就再比较第二个字符,第二个字符比较小的那个字符串就比较小。 如果两个字符串的第二个字符也相同,那就接着比较第三个字符,依此类推。 知道字符串时如何排序,我们就可以顺便讲讲,匹配列前缀的问题 假设我们在 person 表 根据name这个字段创建一个索引,则就会有一个以name排序好的B+树索引 如果我们只进行对应查询,只需要做几次二次排序就能找到对应的数据,比如 SELECT * FROM person WHERE name = 'Ashburn',数据如下图 我们知道真实场景中字符串的查询更多的是模糊查询,比如,我只想找 name 字段开头是A的名字,这种sql语句就会是这样:SELECT * FROM person WHERE name LIKE 'A%';,这种情况下会不会查询? 答案是会的,因为字符串的排序本身就是按照首字母比对以此下去的,所以你如果想找A 就比较每个叶子点的name首字母是否比A大或者小,就能找到 那假设我不按首字母顺序查找,我按最后一个,会吗?就比如 我查最后一个字母是a的 SELECT * FROM person WHERE name LIKE '%A',或者中间字母有A的 SELECT * FROM person WHERE name LIKE '%A%' 答案是 都不会,因为这样不符合字符串排序的方式,所以会全局查询 什么是全值匹配,就是搜索条件跟索引列一致,比如:SELECT * FROM person WHERE name = 'Ashburn' AND birthday = '1990-09-27' AND phone_number = '15123983239'; 全职怎么查,流程是下面:
先按照name的值查找对应的索引,定位到name列的值 name列相同的记录又是按照birthday值进行排序,所以我们可以快速定位到brthday的值 name 和 birthday都相同的值又会根据phone_number 进行排序,所以我们可以迅速定位到记录 看索引的查询就是这么简单快捷,避免了全局查询,那这些条件打乱顺序,索引还会触发吗? 答案是肯定的,为啥呢,因为底层有查询优化器在负重前行,会分析这些搜索条件并且按照可以使用的索引中列的顺序来决定先使用哪个搜索条件,后使用哪个搜索条件。 既然把条件都写上可以触发索引查询,那我少一个呢?比如我就查SELECT * FROM person WHERE name = 'Ashburn' AND birthday = '1990-09-27' 答案是会的,流程我们走一遍就知道了
先按照name的值查找对应的索引,定位到name列的值 name列相同的记录又是按照birthday值进行排序,所以我们可以快速定位到brthday的值 可以看出,我们就算不查phone_number ,也会触发查询 那再少一个呢,比如SELECT * FROM person WHERE name = 'Ashburn' 答案是 会的,流程我们再走一遍:
先按照name的值查找对应的索引,定位到name列的值 这两个例子可以看出,联合索引不需要全部都写上,也能触发索引查询 那我们再做个实验,比如:SELECT * FROM person WHERE birthday = '1990-09-27';,会触发索引吗? 答案是 不会,为什么? 因为B+树的数据页和记录先是按照name列的值排序的,在name列的值相同的情况下才使用birthday列进行排序,也就是说name列的值不同的记录中birthday的值可能是无序的。而现在你跳过name列直接根据birthday的值去查找,这跟全表查没有什么区别 由此我们看出,如果我们想要使用联合索引查询,我们搜索的条件就必须有联合索引中从最左边连续的列,比如 name,name+birthday,name+birthday+phone_number 所以选择联合索引列需要慎重,不然的容易导致不能命中索引的情况,浪费性能 上面讲到了我们搜索的条件就必须有联合索引中从最左边连续的列,但其实这还有个限制,这个限制就来源于范围索引 我们先来看看正常的范围搜索是咋样的,比如:SELECT * FROM person WHERE name > 'Asa' AND name < 'Barlow';
通过索引找到name = ‘Asa’ 通过索引找到name = ‘Barlow’ 把他们两中间的所有索引值拿出来 回表找出数据 那再多一个搜索条件呢,比如:SELECT * FROM person WHERE name > 'Asa' AND name < 'Barlow' AND birthday > '1990-01-01';
通过条件name > ‘Asa’ AND name < ‘Barlow’ 来对name进行范围,查找的结果可能有多条name值不同的记录, 对这些name值不同的记录继续通过birthday > '1980-01-01’条件继续过滤。 这样的话跟我们查询索引的流程不一样,因为只有name值相同的情况下才能用birthday列的值进行排序,而这个查询中通过name进行范围查找的记录中可能并不是按照birthday列进行排序的,所以在搜索条件中继续以birthday列进行查找时是用不到这个B+树索引的。 虽然对多个列都进行范围查找时只能用到最左边那个索引列,但是如果左边的列是精确查找,则右边的列可以进行范围查找,比方:SELECT * FROM person WHERE name = 'Ashburn' AND birthday > '1980-01-01' AND birthday < '2000-12-31' AND phone_number > '15100000000';
name = ‘Ashburn’,对name列进行精确查找,当然可以使用B+树索引了。 由于name值相同了,可以对birthday进行索引排序查找 由于birthday用了范围查找,对应的birthday值不一样,所以phone_number的查询不能用索引查询,只能遍历上一步查询得到的记录 也就是说,上一个查询是先通过name和birthday的索引找到对应的记录,再通过遍历这些记录找到对应的phone_number数据 排序的时候,索引也能派上用场,讲个例子:SELECT * FROM person ORDER BY name, birthday, phone_number LIMIT 10; 这个排序的流程:
先按照name排序 如果name值相同再按照birthday排序 如果name和birthday值都相同,再按照phone_number 排序 这个流程是不是很熟悉,这就是B+树的创建流程,所以排序的时候按照索引字段的规则,则可以直接根据索引排好序返回 并且联合索引的匹配左边的列的规则同样适用于排序,比如ORDER BY name、ORDER BY name, birthday,当name的值一样的时候 ORDER BY birthday, phone_number 也是能生效的 那什么情况,不能触发索引进行排序
ASC、DESC混用:对于使用联合索引进行排序的场景,我们要求各个排序列的排序顺序是一致的,也就是要么各个列都是ASC规则排序,要么都是DESC规则排序。为什么不能混用呢?
举个例子就明白了,假设 SELECT * FROM person_info ORDER BY name asc, birthday DESC LIMIT 10; 先从索引的最左边确定name列最小的值,然后找到name列等于该值的所有记录,然后从name列等于该值的最右边的那条记录开始往左找10条记录 如果name列等于最小的值的记录不足10条,再继续往右找name值第二小的记录,重复上面那个过程,直到找到10条记录为止。 这样的操作太消耗性能了,不如直接记录都加载到内存中,再用一些排序算法,比如快速排序、归并排序、等等排序等等在内存中对这些记录进行排序 WHERE子句中出现非排序使用到的索引列:因为这样压根用不到B+树,所以就算排序字段是索引,也没用 排序列包含非同一个索引的列:这个很简单,就是用不到B+索引树 排序列使用了复杂的表达式:修饰过的列,就是不是原先的列了,所以用不到索引的B+树 通过查询,排序,我们其实已经知道一个道理,就是B+树其实已经按照顺序将索引字段分组了,把相同的值放到一起,所以我们进行分组计算的时候,分组字段是索引字段并且满足索引字段的要求,就能很快地找到对应分组并且计算。 举个例子:SELECT name, birthday, phone_number, COUNT(*) FROM person GROUP BY name, birthday, phone_number
这个查询做了三次的分组: 第一次把记录按照name值进行分组,所有name值相同的记录划分为一组 第二次把每个相同的name值下面的birthday进行分组 第三次把每个相同的name和birthday值下面的phone_number进行分组 熟悉吗,当然,这直接可以使用B+树做对应的操作 因为二级索引是基于主键来做的B+树,意思就是我们查询完二级索引还得回表,也就是真正存放数据的地方找数据,所以如果需要回表得记录越多,使用二级索引的性能就越低,所以查询字段能不用*号就不用。 只为出现在WHERE子句中的列、连接子句中的连接列,或者出现在ORDER BY或GROUP BY子句中的列创建索引 最好为那些列的基数大的列建立索引,为基数太小列的建立索引效果可能不好,因为如果列数据只有0和1,每次查找跟全表没啥区别,没必要 索引列的类型尽量小 B+树索引在空间和时间上都有代价,所以创建索引要谨慎 B+树索引适用于下面这些情况:
全值匹配 匹配左边的列 匹配范围值 精确匹配某一列并范围匹配另外一列 用于排序 用于分组 在使用索引时需要注意下面这些事项:
只为用于搜索、排序或分组的列创建索引 为列的基数大的列创建索引 索引列的类型尽量小 可以只对字符串值的前缀建立索引 只有索引列在比较表达式中单独出现才可以适用索引 为了尽可能少的让聚簇索引发生页面分裂和记录移位的情况,建议让主键拥有AUTO_INCREMENT属性。 定位并删除表中的重复和冗余索引 尽量使用覆盖索引进行查询,避免回表带来的性能损耗。