卷积神经网络CNN识别MNIST数据集
这次我们将建立一个卷积神经网络,它可以把MNIST手写字符的识别准确率提升到99%,读者可能需要一些卷积神经网络的基础知识才能更好的理解本节的内容。
程序的开头是导入TensorFlow:
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data
接下来载入MNIST数据集,并建立占位符。占位符x的含义为训练图像,y_为对应训练图像的标签。
# 读入数据 mnist = input_data.read_data_sets( "MNIST_data/" , one_hot = True ) # x为训练图像的占位符,y_为训练图像标签的占位符 x = tf.placeholder(tf.float32, [ None , 784 ]) y_ = tf.placeholder(tf.float32, [ None , 10 ])
运行后会在当前目录下得到一个名为MINST_data的数据集。如下图所示
由于使用的是卷积神经网络对图像进行分类,所以不能再使用784维的向量表示输入的x,而是将其还原为28*28的图片形式。[-1,28,28,1]中的-1表示形状第一维的大小是根据x自动确定的。
# 将单张图片从784维向量重新还原为28*28的矩阵图片 x_image = tf.reshape(x, [ - 1 , 28 , 28 , 1 ])
x_image就是输入的训练图像,接下来,我们对训练图像进行卷积计算,第一层卷积的代码如下:
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev = 0.1 )
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant( 0.1 , shape = shape)
return tf.Variable(initial)
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides = [ 1 , 1 , 1 , 1 ], padding = 'SAME' )
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize = [ 1 , 2 , 2 , 1 ], strides = [ 1 , 2 , 2 , 1 ], padding = 'SAME' )
# 第一层卷积层
W_conv1 = weight_variable([ 5 , 5 , 1 , 32 ])
b_conv1 = bias_variable([ 32 ])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
首先定义了四个函数,函数weight_variable可以返回一个给定形状的变量,并自动以截断正态分布初始化,bias_variable同样返回一个给定形状的变量,初始化所有值是0.1,可分别用这两个函数创建卷积的核(kernel)与偏置(bias)。h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)是真正进行卷积运算,卷积计算后选用ReLU作为激活函数。h_pool1 = max_pool_2x2(h_conv1)是调用函数max_pool_2x2进行一次池化操作。卷积、激活函数、池化,可以说是一个卷积层的“标配”,通常一个卷积层都会包含这三个步骤,有时也会去掉最后的池化操作。
对第一次卷积操作后产生的h_pool1再做一次卷积计算,使用的代码与上面类似。
# 第二层卷积 W_conv2 = weight_variable([ 5 , 5 , 32 , 64 ]) b_conv2 = bias_variable([ 64 ]) h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2) h_pool2 = max_pool_2x2(h_conv2)
两层卷积层之后是全连接层:
# 全连接层,输出为1024维的向量 W_fc1 = weight_variable([ 7 * 7 * 64 , 1024 ]) b_fc1 = bias_variable([ 1024 ]) h_pool2_flat = tf.reshape(h_pool2, [ - 1 , 7 * 7 * 64 ]) h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1) # 使用Dropout,keep_prob是一个占位符,训练时为0.5,测试时为1 keep_prob = tf.placeholder(tf.float32) h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
在全连接层中加入了Dropout,它是防止神经网络过拟合的一种手段。在每一步训练时,以一定概率“去掉”网络中的某些连接,但这种去除不是永久性的,只是在当前步骤中去除,并且每一步去除的连接都是随机选择的。在这个程序中,选择的Dropout概率是0.5,也就是说训练时每一个连接都有50%的概率被去除。在测试时保留所有连接。
最后,再加入一层全连接,把上一步得到的h_fc1_drop转换为10个类别的打分。
# 把1024维的向量转换为10维,对应10个类别 W_fc2 = weight_variable([ 1024 , 10 ]) b_fc2 = bias_variable([ 10 ]) y_conv = tf.matmul(h_fc1_drop, W_fc2) + b_fc2
y_conv相当于Softmax模型中的Logit,当然可以使用Softmax函数将其转换为10个类别的概率,再定义交叉熵损失。但其实TensorFlow提供了一个更直接的tf.nn.softmax_cross_entropy_with_logits函数,它可以直接对Logit定义交叉熵损失,写法为:
# 不采用先softmax再计算交叉熵的方法 # 而是采用tf.nn.softmax_cross_entropy_with_logits直接计算 cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels = y_, logits = y_conv)) # 同样定义train_step train_step = tf.train.AdamOptimizer( 1e - 4 ).minimize(cross_entropy)
定义测试的准确率
# 定义测试的准确率 correct_prediction = tf.equal(tf.argmax(y_conv, 1 ), tf.argmax(y_, 1 )) accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
在控制台显示在验证集上训练时模型的准确度,方便监控训练的进度,也可以据此来调整模型的参数。
# 创建Session,对变量初始化
sess = tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
# 训练20000步
for i in range ( 20000 ):
batch = mnist.train.next_batch( 50 )
# 每100步报告一次在验证集上的准确率
if i % 100 = = 0 :
train_accuracy = accuracy. eval (feed_dict = {
x: batch[ 0 ], y_: batch[ 1 ], keep_prob: 1.0
})
print ( "step %d,training accuracy %g" % (i, train_accuracy))
train_step.run(feed_dict = {x: batch[ 0 ], y_: batch[ 1 ], keep_prob: 0.5 })
训练结束后,打印在全体测试集上的准确率:
# 训练结束后报告在测试集上的准确率
print ( "test accuracy %g" % accuracy. eval (feed_dict = {
x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0
}))
最后得到的结果在控制台显示为
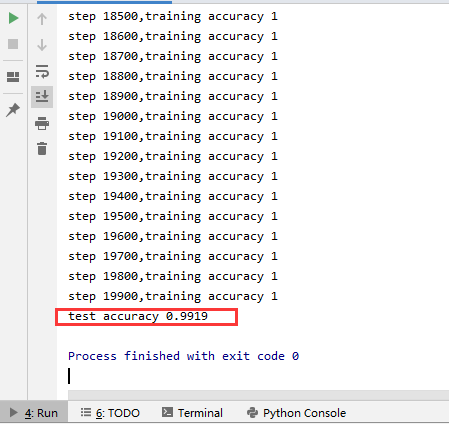
可以最终测试得到的准确率结果应该在99%左右。与Softmax回归模型相比,使用两层卷积的神经网络模型借助了卷积的威力,准确率有非常大的提升。