大语言模型的三阶段训练
为了训练专有领域模型,选择LLaMA2-7B作为基座模型,由于LLaMA模型中文词表有限,因此首先进行中文词表的扩展,然后进行三阶段训练(增量预训练,有监督微调,强化学习)。
代码将全部上传到github:
https://github.com/hjandlm/LLM_Train
1. 中文词表扩展
原生词表大小是32K,在词表扩展后,词表大小是63608。
2. 增量预训练
为了防止模型的通用能力减弱或消失,将通用数据和领域数据混合,经过调研决定设置5:1的数据配比进行增量预训练。由于资源有限,显卡是一块A100,40G,因此训练较慢。
目前还处于预训练阶段,情况如下:
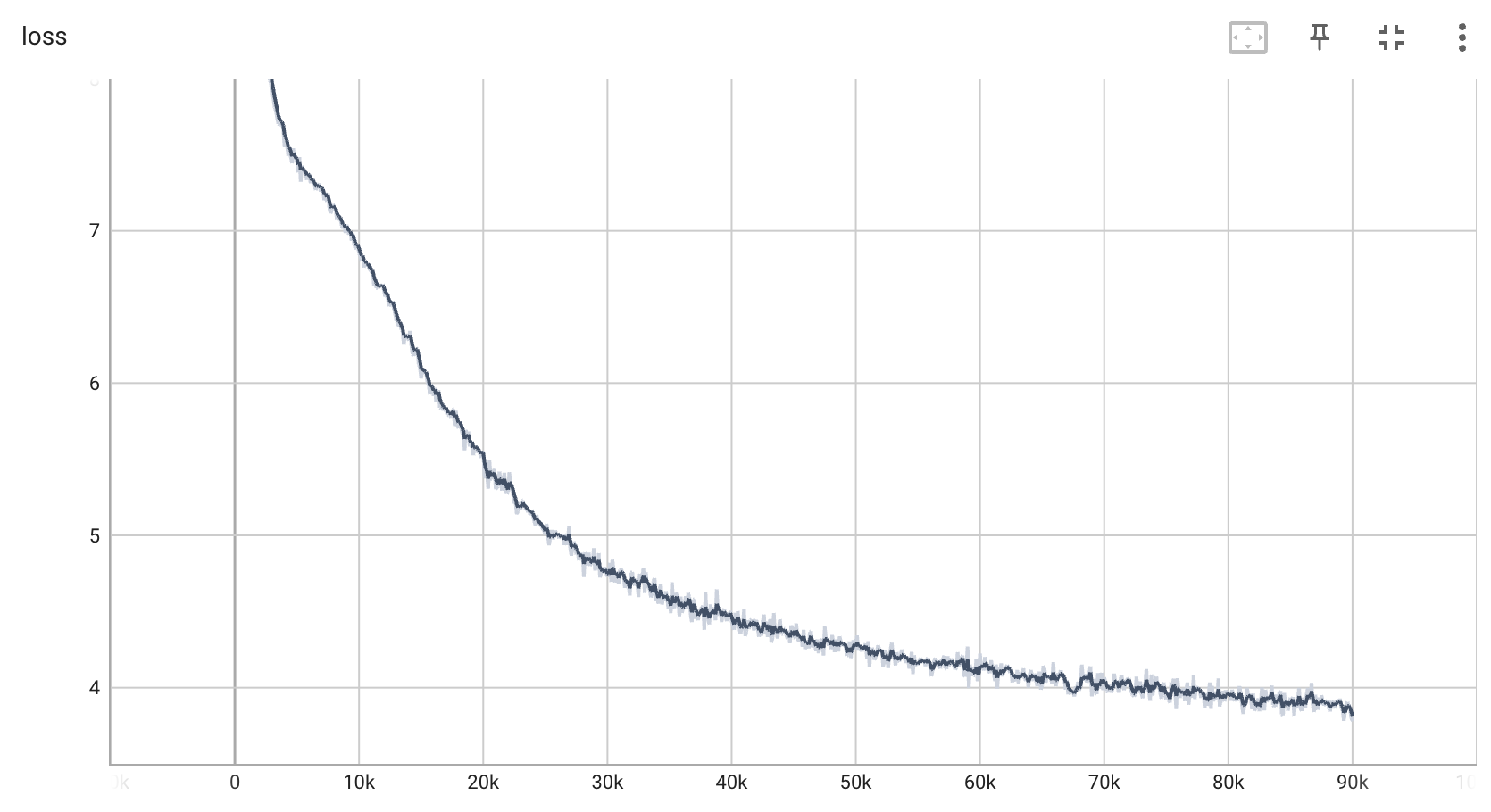
训练集损失曲线:
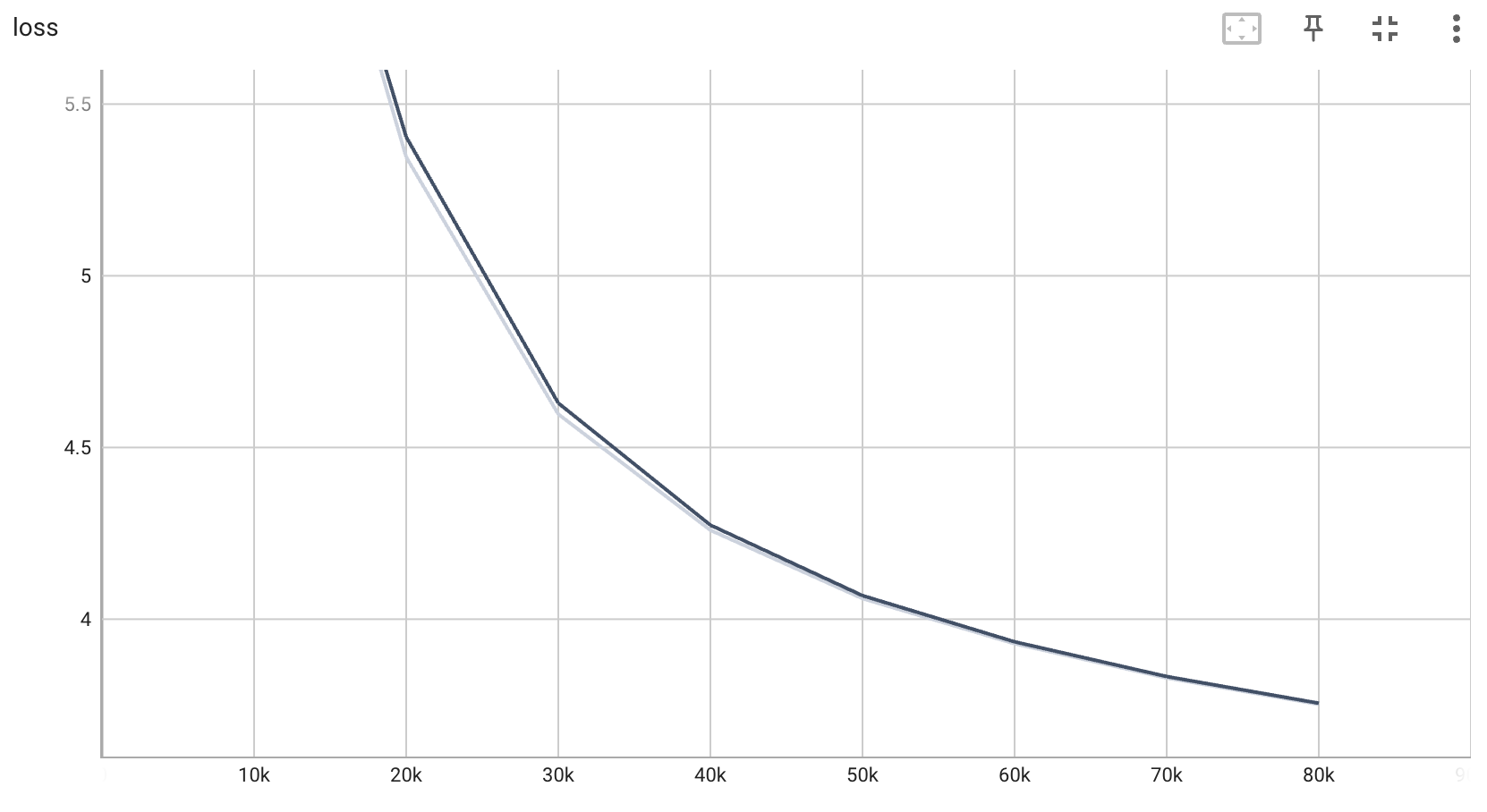
测试集损失曲线:
后续将继续研究如何“炼丹“,敬请期待!
3. 有监督微调
…
4. 强化学习
…