Notepad+正则表达式使用方法
常用的元字符和语法规则来构建你的表达式:
元字符是正则表达式的基本构成单位,它们代表了不同的含义,如下所示:
| 元字符 | 含义 |
|---|---|
| . | 代表任意字符,换行符除外 |
| ^ | 代表一行的开头 |
| $ | 代表一行的结尾 |
| * | 代表一个字符可以出现 0 次或多次 |
| + | 代表一个字符可以出现 1 次或多次 |
| ? | 代表一个字符可以出现 0 次或 1 次 |
| {n} | 代表一个字符可以出现 n 次 |
| {n,} | 代表一个字符可以出现 n 次或多次 |
| {n,m} | 代表一个字符可以出现 n~m 次 |
| […] | 代表括号中任意一个字符 |
| [^…] | 代表除括号中字符外的任意字符 |
| \ | 转义字符 |
特殊字符
在正则表达式中,还有一些特殊字符,它们代表了不同的意思:
| 特殊字符 | 含义 |
|---|---|
| \d | 代表任意一个数字,等价于 [0-9] |
| \D | 代表任意一个非数字字符,等价于 [^0-9] |
| \w | 代表任意一个字母、数字或下划线,等价于 [a-zA-Z0-9_] |
| \W | 代表任意一个非字母、数字或下划线字符,等价于 [^a-zA-Z0-9_] |
| \s | 代表任意一个空白字符,包括空格、制表符、换行符等 |
| \S | 代表任意一个非空白字符 |
汇总如下:
\ 转义字符 如:要使用 “\” 本身, 则应该使用“\”
\t Tab制表符 注:扩展和正则表达式都支持
\r 回车符CR 注:扩展支持,正则表达式不支持
\n 换行符LF 注:扩展支持,正则表达式不支持
\r\n 正则表达式可表示回车换行
. 匹配任意一个字符
^ 其右边的表达式被匹配在行首。如:^A匹配以“A”开头的行
$ 其左边的表达式被匹配在行尾。如:e$匹配以“e”结尾的行
| 或运算符,匹配表达式左边和右边的字符串。如:ab|bc匹配“ab”或“bc”
[] 匹配列表中任意单个字符。如:[ab]匹配“a”或“b”;[0-9]匹配任意单个数字
[^] 匹配列表之外的任意单个字符。如:[ab]匹配“a”和“b”以外的单个字符;[0-9]匹配任意单个非数字字符
*其左边的字符被匹配任意次(0次或多次)。如:be*匹配“b”,“be”或“bee”
+ 其左边的字符被匹配至少一次(1次或多次)。如:be+匹配“be”或“bee”,但不匹配“b”
? 其左边的字符被匹配0次或者1次。如:be?匹配“b”或“be”,但不匹配“bee”;\r?\n匹配行结尾符
() 影响表达式匹配的顺序(类似C++的小括号会影响表达式运算顺序),并且用作表达式的分组标记(标记从1开始)如:([a-z]bc)smn\1匹配“tbcsmntbc”;另见:看下文的示例
{} 指定前面的字符或分组的出现次数 如:abc{3}匹配abccc;a(bc){2}匹配abcbc
\d 匹配一个数字字符。等价于:[0-9]
\D \d取反,匹配一个非数字字符。等价于:[^0-9]
\s 匹配任意单个空白字符:包括空格、制表符等(注:不包括换车符和换行符)。等价于:[ \t]
\S \s取反的任意单个字符。
\w 匹配包括下划线的任意单个字符。等价于:[A-Za-z0-9_]
\W \w 取反的任意单个字符。等价于:[^A-Za-z0-9_]
\b 匹配单词起始处或结尾处
正则表达式需转义的字符包括:
* . ? + ^ $ | \ / [ ] ( ) { }
开始查找
在 Notepad 中,我们可以通过“查找”功能来查找特定的文本。首先,我们需要展开“查找”对话框,在菜单栏中选择“编辑”->“查找”,或者使用快捷键“Ctrl + F”。
在查找对话框中,我们可以输入要查找的文本。如果我们要使用正则表达式查找,需要在“查找选项”中勾选“使用正则表达式”。此时,我们就可以输入正则表达式了。
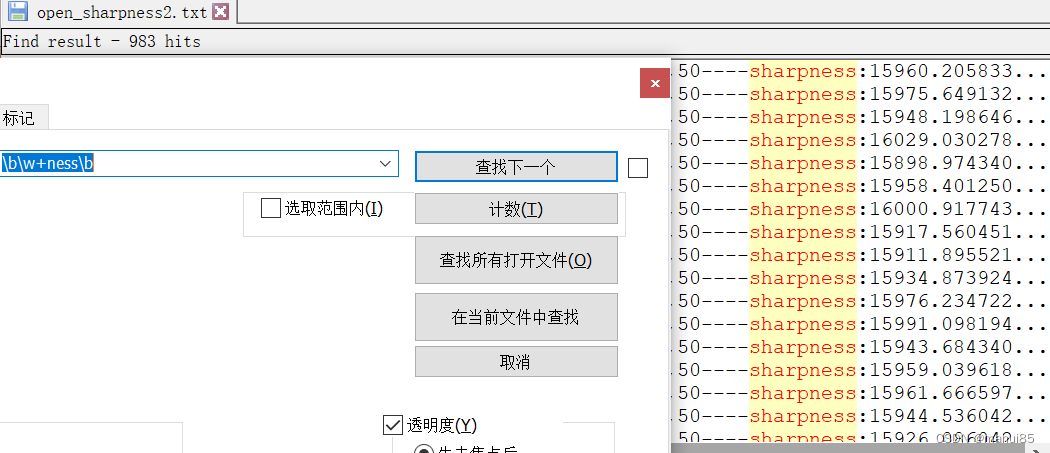
例如,我们要查找所有以“at”结尾的单词,可以使用正则表达式 \b\w+at\b,其中 \b 代表单词的边界,\w 代表任意一个字母、数字或下划线字符,+代表匹配前面的字符出现 1 次或多次。输入完正则表达式后,点击“查找下一个”或使用快捷键“F3”,Notepad 就会从当前光标位置开始查找符合条件的字符串了。
如果要替换符合条件的字符串,可以在“替换”栏中输入要替换的文本。同样,如果要使用正则表达式替换,需要勾选“使用正则表达式”。
例如,我们想将所有以“at”结尾的单词替换为“dog”,可以在“替换”栏中输入“dog”,然后点击“全部替换”或使用快捷键“Ctrl + H”。
比如我们要搜索以https://开头的并且以.com/结尾的字符串
正则表达式为:
开头字符串.+.结尾字符串
或者:
开头字符串.+结尾字符串
或者:
开头字符串.*结尾字符串
示例代码
以下是一个使用正则表达式在 Notepad 中查找和替换文本的示例代码:
查找:
1. 在查找对话框中输入正则表达式:\b\w+at\b
2. 勾选“使用正则表达式”
3. 点击“查找下一个”或使用快捷键“F3”
\b:匹配单词的边界。 例,\b\w+bug\b 查找含有bug的行

查找所有的数字:
-
- 正则表达式:
\d+ - 解释:匹配一个或多个连续的数字。
- 正则表达式:
^[*] 匹配以*为开头的字符,不加括号*就为全局匹配符号
查找以 "apple" 开头的行:
-
- 正则表达式:
^apple.* - 解释:以 "apple" 开头,后面可以有任意字符的行。
- 正则表达式:
查找包含邮箱地址的文本:
-
- 正则表达式:
\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}\b - 解释:匹配常见的邮箱地址格式
- 正则表达式:
\b: 表示单词的边界,确保匹配的电子邮件地址不包含在其他字符中。[A-Za-z0-9._%+-]+: 匹配一个或多个大小写字母、数字、点、下划线、百分号、加号和减号的字符,用于匹配电子邮件地址的用户名部分。@: 匹配电子邮件地址中的“at”符号。[A-Za-z0-9.-]+: 匹配一个或多个大小写字母、数字、点和破折号的字符,用于匹配电子邮件地址的域名部分(例如:example.com)。\.: 匹配一个点字符,用于分隔域名中的主机和顶级域。[A-Za-z]{2,}: 匹配两个或更多大小写字母的字符,用于匹配电子邮件地址的顶级域名部分(例如:com、net、org等)。\b: 再次表示单词的边界,确保匹配的电子邮件地址不包含在其他字符中。
查找重复的单词:
-
- 正则表达式:
\b(\w+)\b.*\b\1\b - 解释:匹配重复的单词(例如 "apple apple")
- 正则表达式:
以某一符号处分行:
比如,;替换为 /n或 /r/n
查找以“字符”结尾的行:
比如,条。$
替换:
1. 在“替换”栏中输入要替换的文本,例如“dog”
2. 勾选“使用正则表达式”
3. 点击“全部替换”或使用快捷键“Ctrl + H”
^:匹配行的开头。 例,^[1] 匹配行首含有这个字符; ^11-14 匹配行首含有“11-14”字符串

$:匹配行的结尾。

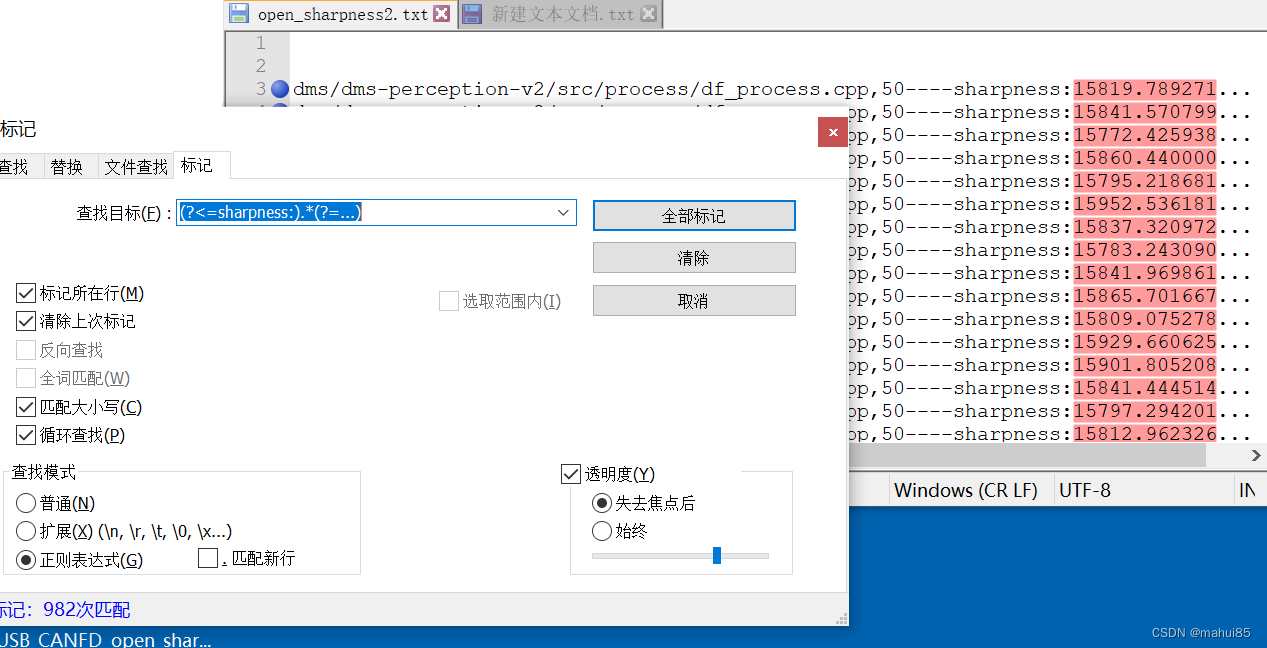
快速查找标记提取字符串
在标记窗口填写正则表达式(?<=sharpness:) .*(?=...) 然后勾选标记所在行、正则表达式,点击按钮“全部标记”,如图红色背景部分即为查找的标记结果。点击按钮“复制标记文本”然后新建文本进行粘贴,即可将所有标记的内容粘贴到文本中。