Kafka 集群实现数据同步
Kafka 介绍
Kafka 是一个高吞吐的分布式消息系统,不但像传统消息队列(RaabitMQ、RocketMQ等)那样能够【异步处理、流量消峰、服务解耦】
还能够把消息持久化到磁盘上,用于批量消费。除此之外由于 Kafka 被设计成分布式系统,吞吐量和可用性大大提高
Kafka 角色
- kafka 客户端
- 生产者(producer):也叫发布者,负责创建消息
- 消费者(consumer):也叫订阅者,负责消费(读取)消息
- Kafka 服务端(broker)
- leader:对外提供读写服务
- follower:不提供服务,负责向 leader 同步数据
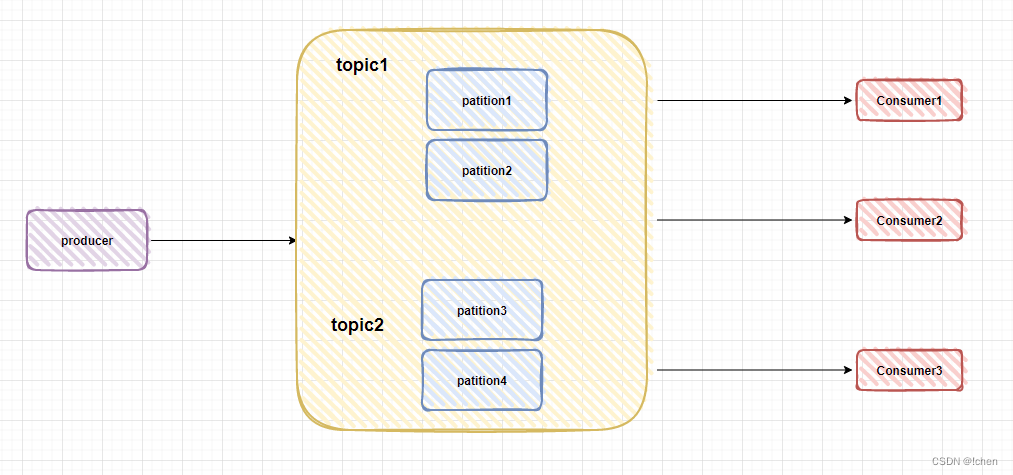
Topic(主题)和 partition(分区)
topic 就是消息发布的地方,消费者通过订阅 topic 来消费到对应的消息
为了提高吞吐量,实现 topic 的负载均衡,Kafka 在 topic 下又引用了分区(partition)的概念,每个 topic 可以被划分成多个分区
分区允许消息在 Topic 下水平分割和存储,每个分区都是一个有序且不可变的消息队列,消费者可以以并行的方式消费同一个 topic 中的消息
log(日志)

每个分区都是一个有序的、不可变的消息队列,且可以持续地添加消息。消息在分区中分配了唯一的序列号,被称为偏移量(Offset)
offset 用来唯一的标识分区中每一条记录
Kafka 会保留所有分区中的消息,不会自动删除消息。消息的保留策略由 Kafka 配置参数控制,消息可以在一定时间或达到一定大小后过期,过期的消息会被删除
消费者在 Kafka 中只保留自己的 Offset,用于标识它在分区中的位置。通常情况下,当 消费者消费消息时,它的 Offset 会线性增加,表示它已经消费了这些消息
消费者可以选择将 Offset 重置为更旧的值,从而重新开始读取消息
每个消费者实例唯一负责一个分区,Kafka 只保证分区内的记录是有序的,而不保证主题中不同分区的顺序
Kafka 集群
Kafka 是分布式架构,有集群(cluster)的概念
Kafka 中的一个实例被称为 broker,它接收生产者的消息并存入磁盘,消费者连接 broker 消费消息
多个 broker 组成一个 Kafka cluster,集群内某个 broker 会成为集群控制器(cluster controller),负责管理整个 Kafka 集群,包括分配分区给 broker,监控 broker 等
分区被复制成了多个副本(replica)然后均分在不同的 broker 上 ,其中一个副本 Leader,其他的是 Follower
创建副本的单位是 topic 的 分区
正常情况下,每个分区都有一个 leader 和零或多个 followers 。这样即使某个 broker 发生故障,其他 broker上的副本仍然可以继续提供服务
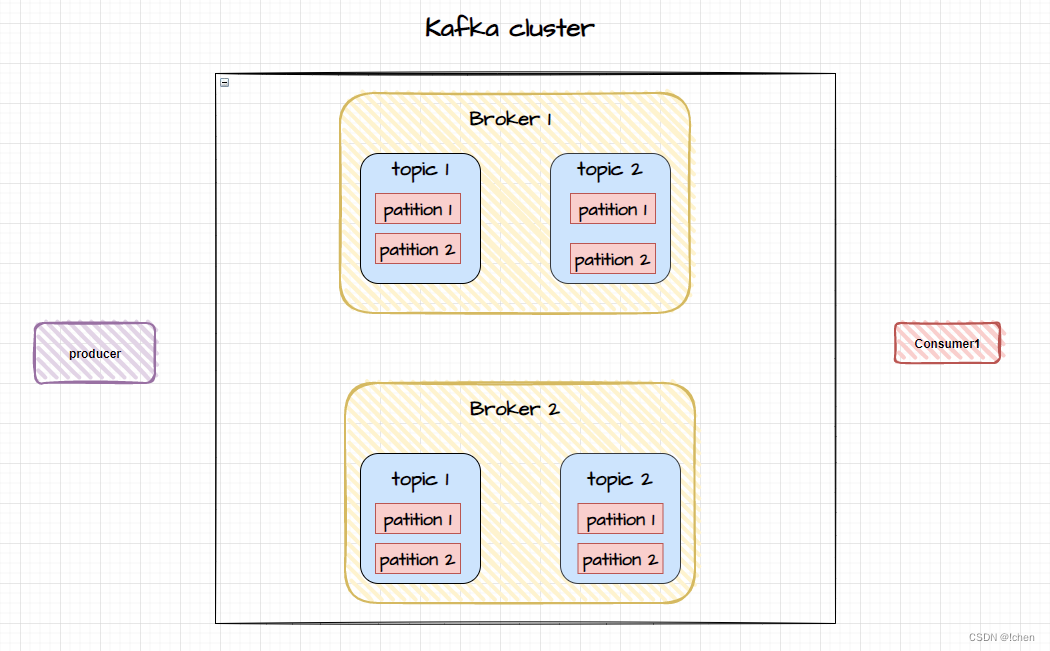
那如何将所有的副本均匀分布在不同 broker 上呢?
分配副本的算法如下:
- 将所有 broker(假设共
n个 broker)和待分配的分区排序 - 将第
i个分区分配到第(i mod n)个 broker上 - 将第
i个分区的第j个副本分配到第((i + j) mode n)个 broker 上
如何实现数据同步?
我们先来看下 Kafka 中的 ISR(In-Sync Replicas) 机制
既然每个 leader 下面都有至少一个 follower,于是便有了 ISR,ISR 就是 Kafka 动态维护的一组同步副本集合
ISR 中所有的 follower 都与 leader 保持同步状态,而且 leader 也在 ISR 列表中,只有在自己 ISR 列表中的副本才能参与 leader 竞选
当生产者写入数据时,leader 更新数据,follower 是怎么知道 leader 更新然后去同步数据的呢?
follower 会通过定期向 leader 发送 fetch 请求来实现数据同步,这个是由 fetcher 线程来负责的
当一个副本被选举成为 follower 后,会启动副本的 fetcher 线程,随后 Follower 会定期向 Leader 发送心跳请求,以保持连接,并发送 fetch 请求来获取最新的数据。
如果 follower 发现自己的 LEO(Log End Offset,日志结束偏移量)与 Leader 的 LEO 有差距时,会触发同步数据请求,以便将自身日志同步至 Leader 的对应位置,确保与 Leader 的数据保持一致
如果一个 follower 在指定时间内(配置字段为 replica.lag.time.max.ms)没有发送 fecth 请求或者没有追上 leader 的 LEO,就会从 ISR 中移除
最后总结一下:
- Kafka 中的 topic 是逻辑概念,每个 topic 可以被划分为多个分区,而分区才是存储消息的实体
- 每一个分区会被复制成多个副本,然后选取其中一个副本当作 leader,剩下的则是 follower
- follower 会定期去向 leader 发送 fetch 请求来保证数据的同步
- leader 不会关心 follower 的数据是不是同步好了的,只要你在指定时间内没有找我来 fetch ,我就把你从 ISR 中剔除出来