【论文解读】GPT Understands, Too
一.论文
1.1 P-tuning
区别于之前的工作,这篇工作认为promote可以在句子中的任意位置起到作用,可以将它们插入上下文或目标中

上图中,左图是不使用任何操作,右图是选择在居首和目标前插入promote的embedding,插入promote的过程可以表示为

其中x代表一系列离散的输入令牌,y代表目标(可以理解为希望模型想要给你的回答),e()表示对应的embedding,其实就是将其参数化映射成为伪tokens,即
![]()
通过最小化这些参数

1.2 promote生成
嵌入的promote实际上可以理解为不一定离散且不相互关联的,而实际上的promote其实应该是高度离散的且具有关联性的,因此作者选择使用双向长短期记忆网络(LSTM),激活函数和MLP来建模这种关系
在推理中,我们只需要输出嵌入h,并且可以丢弃LSTM头
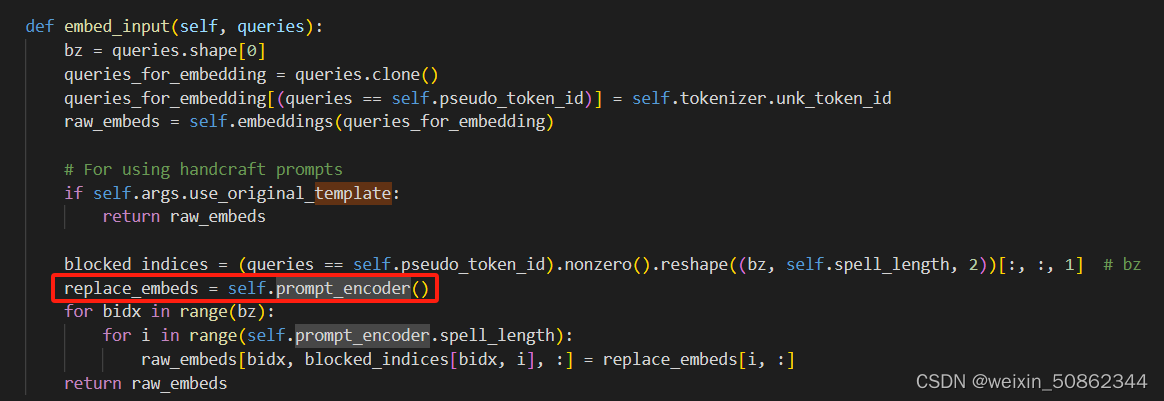
二.代码
本质上是使用一个PromptEncoder来生成伪的embedding添加到原先的embedding中
2.1 训练
训练过程只更新promote_encoder中的参数
2.1.1 PromptEncoder
在PTuneForLAMA中实例化了PromptEncoder

PromptEncoder本质上是一个(嵌入 + LSTM + MLP)
import torch
import torch.nn as nn
class PromptEncoder(torch.nn.Module):
def __init__(self, template, hidden_size, tokenizer, device, args):
super().__init__()
self.device = device
self.spell_length = sum(template)
self.hidden_size = hidden_size
self.tokenizer = tokenizer
self.args = args
# ent embedding
self.cloze_length = template
self.cloze_mask = [
[1] * self.cloze_length[0] # first cloze
+ [1] * self.cloze_length[1] # second cloze
+ [1] * self.cloze_length[2] # third cloze
]
self.cloze_mask = torch.LongTensor(self.cloze_mask).bool().to(self.device)
self.seq_indices = torch.LongTensor(list(range(len(self.cloze_mask[0])))).to(self.device)
# embedding
self.embedding = torch.nn.Embedding(len(self.cloze_mask[0]), self.hidden_size).to(self.device)
# LSTM
self.lstm_head = torch.nn.LSTM(input_size=self.hidden_size,
hidden_size=self.hidden_size // 2,
num_layers=2,
dropout=self.args.lstm_dropout,
bidirectional=True,
batch_first=True)
self.mlp_head = nn.Sequential(nn.Linear(self.hidden_size, self.hidden_size),
nn.ReLU(),
nn.Linear(self.hidden_size, self.hidden_size))
print("init prompt encoder...")
def forward(self):
input_embeds = self.embedding(self.seq_indices).unsqueeze(0)
output_embeds = self.mlp_head(self.lstm_head(input_embeds)[0]).squeeze()
return output_embeds
2.1.2 调用
在PTuneForLAMA的forward函数中调用了embed_input来实现