数据类型扩展02
1、字符串拓展
所有的字符本质还是数字。
char c1 = 'a';
char c2 = '中';
System.out.println("c1:"+c1);
System.out.println("c1转换:"+(int)c1);
System.out.println("c2:"+c2);
System.out.println("c2转换:"+(int)c2);执行结果
c1:a
c1转换:97
c2:中
c2转换:200131.1、字符
字符(Character) 是对文字和符号的总称,例如汉字、拉丁字母、emoji 都是字符。在计算机中,一个字符由 2 部分组成:
- 1、用户看到的图画
- 2、字符的编码
1.2、字符集
字符集(Character Set) 是多个字符与字符编码组成的系统,由于历史的原因,曾经发展出多种字符集。

Unicode
Unicode是一种用于字符编码的国际标准,它定义了世界上所有字符的唯一编号,并提供了一种将这些字符在计算机中表示和处理的方式。自从1991年开始发展以来,Unicode已经成为全球广泛使用的字符集和编码方案之一,无论是在传统的文字处理领域还是在现代化的互联网和移动应用程序中。
1990年开始研发,1994年正式发布1.0版本,2022年9月13日发布15.0版本。
Unicode 字符集的编码范围是 0x0000 - 0x10FFFF , 可以容纳一百多万个字符, 每个字符都有一个独一无二的编码,也即每个字符都有一个二进制数值和它对应,这里的二进制数值也叫 码点 , 比如:汉字 "中" 的 码点是 0x4E2D, 大写字母 A 的码点是 0x41, 具体字符对应的 Unicode 编码可以查询 Unicode字符编码表。
1.3、编码格式
Unicode 本身只定义了字符与码点的映射关系,相当于定义了一套标准,而这套标准真正在计算机中落地时,则有多种编码格式。目前常见到的有 3 种编码格式:UTF-8、UTF-16 和 UTF-32。
UTF-8 编码
UTF-8 是 1~4 个字节的变长编码,相对来说最节省空间。 下述规则表述与你在任何文章 / 百科里看到的规则表述不一样,但是逻辑上是一样的。因为我认为按照 “前缀无歧义” 的概念来理解最易懂。
- 规则 1: 不同范围的码点值使用不同长度的编码;
- 规则 2: 字节编码总长度为 1 时前缀为
0、总长度为 2 时前缀为110、总长度为 3 时前缀为1110、总长度为 4 时前缀为11110; - 规则 3: 除了首个字节,字符编码中其余字节的前缀为
10。
可以看到,这种编码方式是不会存在前缀歧义的,也比较好理解。
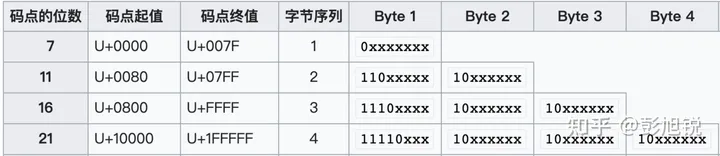
用一张表总结一下 3 种编码格式:
| ASCII | UTF-8 | UTF-16 | UTF-32 | |
|---|---|---|---|---|
| 编码空间 | 0~7F | 0~10FFF | 0~10FFF | 0~10FFF |
| 最小存储占用 | 1 | 1 | 2 | 4 |
| 最大存储占用 | 1 | 4 | 4 | 4 |
2、Java常用的转义字符
“\t”为制表符,作用是对齐。长度不足8的字符会以8个长度为格式来输出,长度大于或等于8的字符会以8的倍数为格式输出。(注意:中文占两个字符,数字字母占一个)
“\n”为换行符,作用是实现换行,功能类似回车。
“\\”为一个\,作用就是输出一个\。
“\"”为一个",作用就是输出一个\。“\'”为一个',作用就是输出一个' 。
“\r”为一个回车,其功能为:
1.将光标移至首字符串头“|caimingjie”
2.将转义字符后的数字替换 从光标后开始的字符