人工智能-优化算法和深度学习
优化和深度学习
对于深度学习问题,我们通常会先定义损失函数。一旦我们有了损失函数,我们就可以使用优化算法来尝试最小化损失。在优化中,损失函数通常被称为优化问题的目标函数。按照传统惯例,大多数优化算法都关注的是最小化。如果我们需要最大化目标,那么有一个简单的解决方案:在目标函数前加负号即可。
优化的目标
尽管优化提供了一种最大限度地减少深度学习损失函数的方法,但本质上,优化和深度学习的目标是根本不同的。前者主要关注的是最小化目标,后者则关注在给定有限数据量的情况下寻找合适的模型。例如,训练误差和泛化误差通常不同:由于优化算法的目标函数通常是基于训练数据集的损失函数,因此优化的目标是减少训练误差。但是,深度学习(或更广义地说,统计推断)的目标是减少泛化误差。为了实现后者,除了使用优化算法来减少训练误差之外,我们还需要注意过拟合。
%matplotlib inline
import numpy as np
import torch
from mpl_toolkits import mplot3d
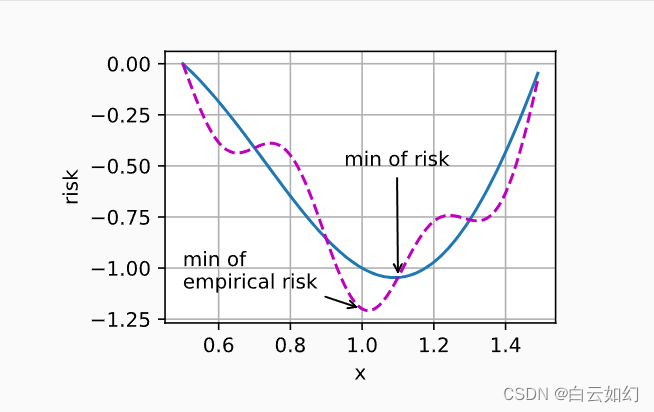
from d2l import torch as d2l下图说明,训练数据集的最低经验风险可能与最低风险(泛化误差)不同。
def annotate(text, xy, xytext): #@save
d2l.plt.gca().annotate(text, xy=xy, xytext=xytext,
arrowprops=dict(arrowstyle='->'))
x = torch.arange(0.5, 1.5, 0.01)
d2l.set_figsize((4.5, 2.5))
d2l.plot(x, [f(x), g(x)], 'x', 'risk')
annotate('min of\nempirical risk', (1.0, -1.2), (0.5, -1.1))
annotate('min of risk', (1.1, -1.05), (0.95, -0.5))