使用 Lhotse 高效管理音频数据集
Lhotse 是一个旨在使语音和音频数据准备更具灵活性和可访问性的 Python 库,它与 k2 一起,构成了下一代 Kaldi 语音处理库的一部分。
主要目标:
1. 以 Python 为中心的设计吸引更广泛的社区参与语音处理任务。
2. 为有经验的 Kaldi 用户提供富有表现力的命令行接口。
3. 为常用的语料库提供标准的数据准备方案。
4. 为与语音和音频相关的任务提供 PyTorch 数据集类。
5. 通过音频剪辑的概念实现模型训练中的灵活数据准备。
6. 提高效率,特别是在 I/O 带宽和存储容量方面。
使用 Lhotse 对数据集结构化抽象、存储和转换成 PyTorch 数据管道,可以很方便实现语音识别和语音合成工程项目。

无论是音频大文件和小文件,都可以使用 cut 来有效表达:




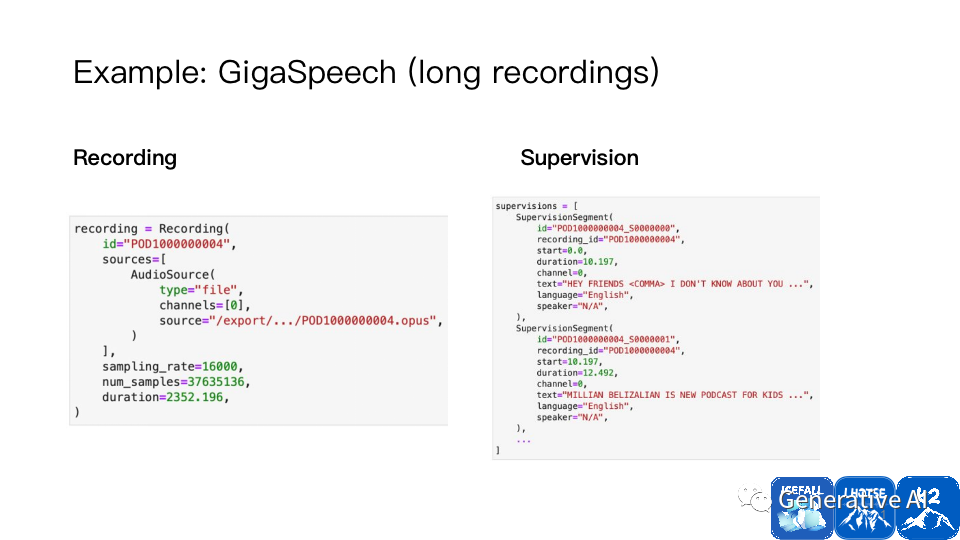
Lhotse 支持了近百个数据集,开箱即用,新的数据集可参考这些例子来完成。

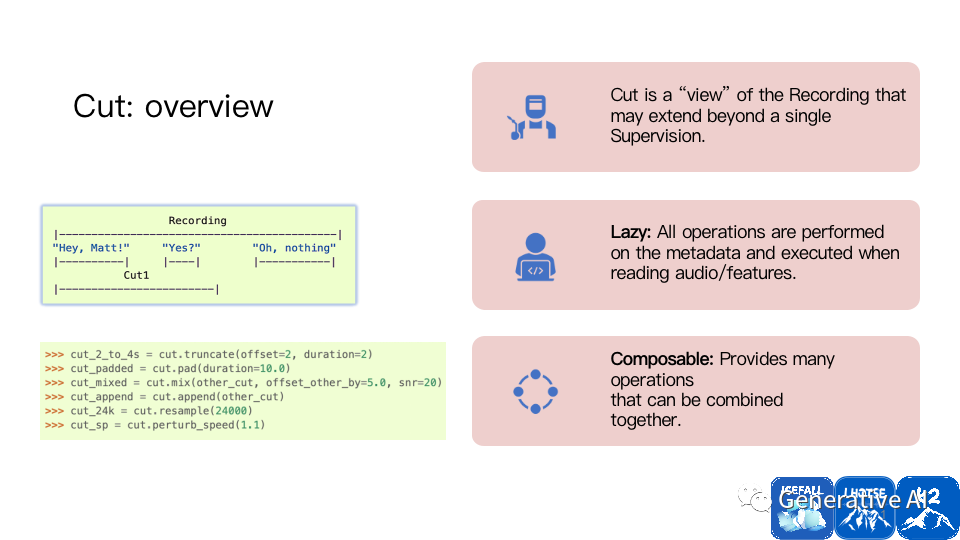
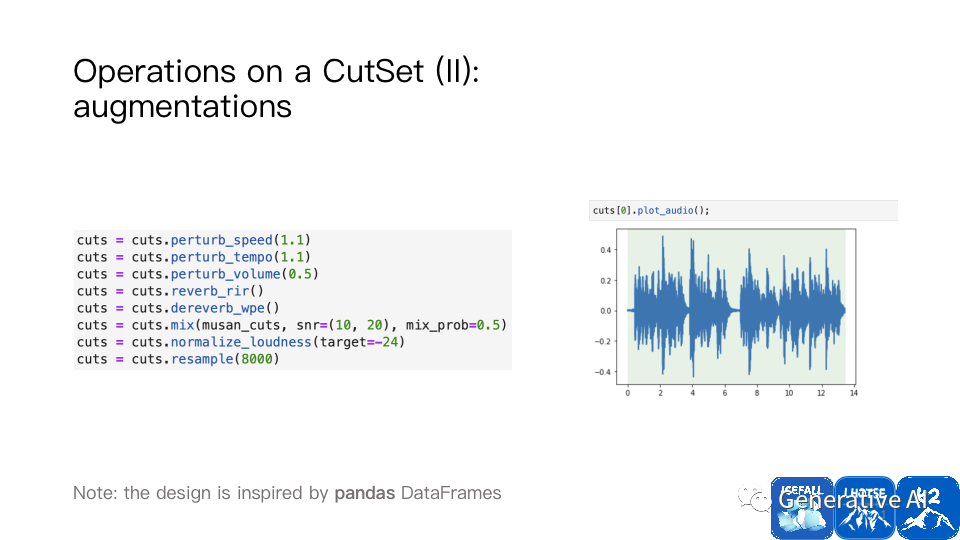
操作数据集也很方便

很方便地与 PyTorch 集成

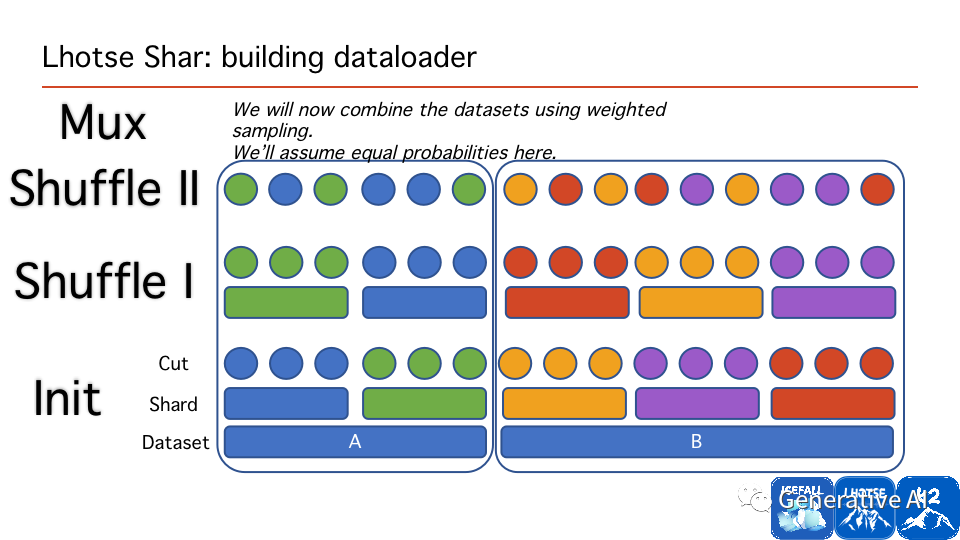
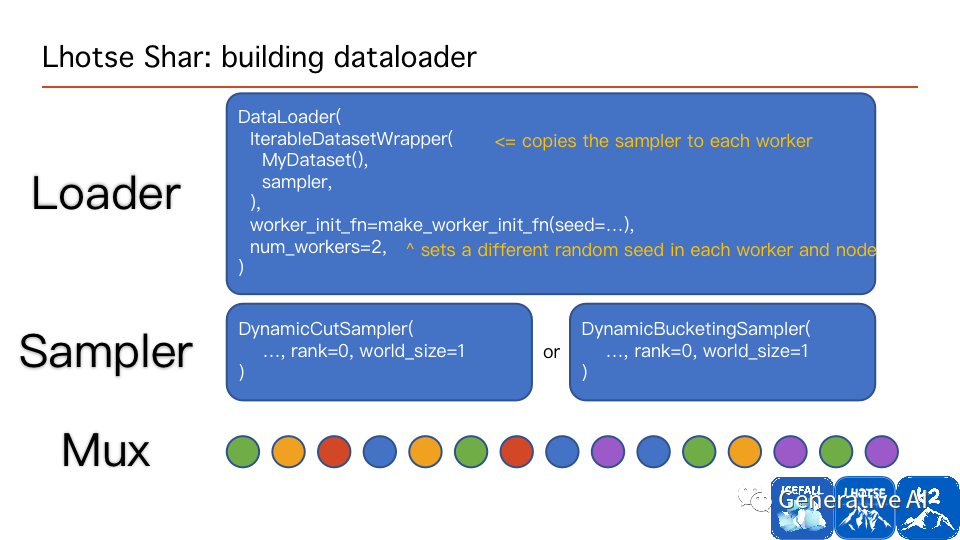
Lhotse 的可扩展性

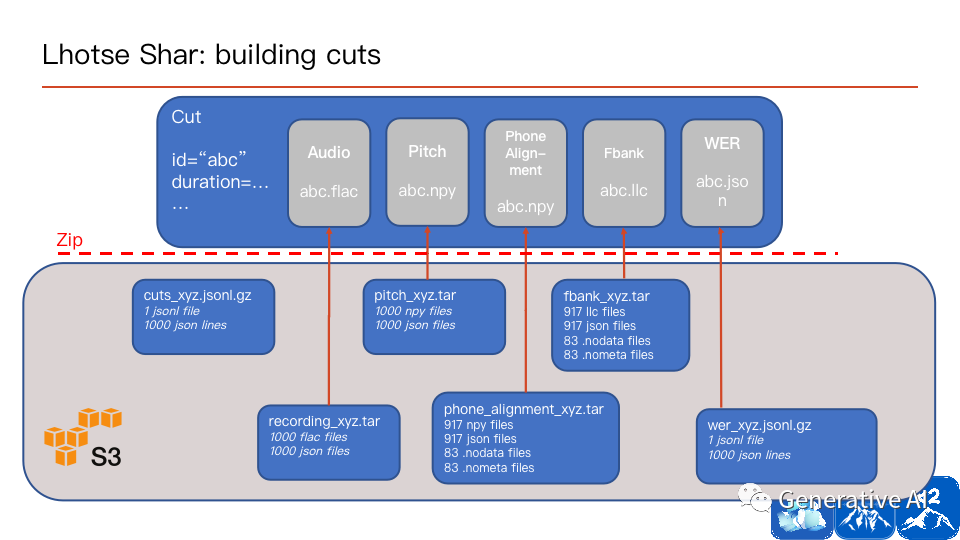


除了文本与语音信息外,Lhotse 还可以 custom 许多信息:强制对齐、duration、pitch 等,可以方便地支持多种语音任务。
对于特征抽取的存储,Lhotse 的写入效率会随着文件大小逐渐变慢,必要的时候需要 CutSet.split 成多个 JOB 执行来提高效率。
此外,尽管 Lhotse 提供了命令行工具,但缺乏 web 工具去分析数据集、样例数据。
依赖 Lhotse 的项目
-
https://github.com/k2-fsa/icefall
-
https://github.com/lifeiteng/vall-e
参考资料:
-
https://lhotse.readthedocs.io/en/latest/index.html
-
Slides for the Interspeech 2023 tutorial
-
https://github.com/k2-fsa/icefall/issues/1230
-