【RLChina2023】CCF 苏州 记录
目录
- RLChina介绍
- 主旨报告
- 专题报告
-
- 智能体学习理论(专题一)
- 智能体决策与规划(专题二)
- 智能体框架、体系结构与训练系统(专题六)
- 基于大语言模型的具身智能体与机器人研究 (专题八)
- 教学报告——强化学习入门
- 特别论坛——智能体和多智能体艺术的探索
- 会议照片
RLChina介绍

RLChina 2023 大会 11 月 24 日在苏州 CCF 业务总部召开,并于 25 日圆满结束。
近年来,大型语言模型(LLM)与智能体 (AI Agent) 的紧密结合逐渐成为人工智能领域的新研究热点和应用焦点。此次大会旨在邀请来自国内外的智能体研究领军人物,共同探讨智能体学习的前沿理论、大模型在智能体领域的应用、智能体的结构设计、思维链路、决策机制、价值对齐以及多智能体之间的博弈与合作等诸多核心议题。
会议为期三天,共设置主旨报告3场;专题报告9场;教学报告4场;特别论坛1场。由于时间限制,许多报告场次都是并行进行的。笔者根据自己兴趣选择了几场报告参加,摘录比较笼统,许多记录基于演讲者口头汇报,细节展示有限,还望理解。
主旨报告
Liu-Qun 刘群 : LLM的自我改进和自我进化
| Model | Training Data Size |
|---|---|
| GPT-3(OpenAl,2020.5) | 500 Bilion tokens |
| Palm (Google,2022.4) | 780 Billion tokens |
| Chinchilla (Deepmind) | 1.4 Trilion tokens |
| Llama (Meta) | 1.5 Trillion tokens |
| Llama2 (Meta) | 2 Trillion tokens |
| GPT-4 (OpenAl) | 13 Trilion tokens (text·2+code·4) + 2 Trillion tokens (image) |
大模型往后的训练数据量只会越来越大,但人类已有的知识是有限的,这就有一个问题:Will we run out of data ? 事实上,在生成模型提出以后,这个问题就得到了缓解。
SELF: Language-Driven Self-Evolution for Large Language Model
LLM 拥有自我批判(self-critiquing)的能力,并且该能力与模型体量呈正相关,模型越大,它拥有的自我批判能力越强,自我批判产生的提升也越明显。
作者提出两阶段学习过程:1、元技能学习阶段;2、自我进化学习阶段

Aligning Large Language Models with Human: A Survey
大模型训练的价值观与人类对齐
Gaining Wisdom from Setbacks: Aligning Large Language Models via Mistake Analysis
利用反例:人可以从错误中汲取教训,那么机器可以吗
Discrimination is easier than generation !

一个攻防实验,机器能否在人的指示下做出违背基本伦理的动作?
通过学习反例可以获得这种能力。
Deng-XiaoTie 邓小铁 : On Provable Bound of Nash Equilibrium Approximtor
AI in Math以一种建设性的方式处理数学,使推理变得自动化,不那么费力,也不容易出错。对于算法来说,问题变成了如何对特定问题进行自动化分析。这项工作首次为理论计算机科学中一个得到充分研究的问题提供了一种自动逼近分析方法:计算两人博弈中的近似纳什均衡(Approximate Nash Equilibria)。
The Search-and-Mix Paradigm in Approximate Nash Equilibrium Algorithms
目前最好的成果是得到 33% 近似的 Nash 均衡
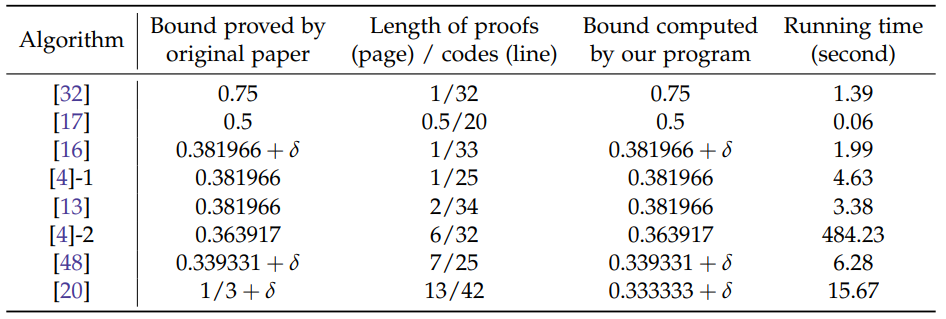 Is Nash Equilibrium Approximator Learnable?
Is Nash Equilibrium Approximator Learnable?
Are Equivariant Equilibrium Approximators Beneficial?
上述两篇文章从假设博弈矩阵服从一个分布出发,探讨纳什均衡的学习力和等纳什的有效性。
博弈论的基本原理是:在双方信息互相了解的情况下,我知道你,你知道我知道你…由此无限套娃,博弈层次会收敛到一个结果矩阵上。
但如果信息是不对称的,那么博弈的层次有限。对于优势方可以快速做出对自己有利的决策。
An-Bo 安波 :Towards Foundation Agents: Autonomous Agents, AI Agents, and Agents society
推销了一波 AAMAS ,谷歌一个比较有代表性的评论,就是领域内 most influential 的含金量罢了。 主要研究领域
主要研究领域
- 多智能体协调与规划
- 分布式约束满足与优化
- 算法博弈理论
- 多智能体学习
- 分布式机器学习
- 逻辑、仿真、agent-oriented programming等
应用
- 机器人,互联网经济,安全,可持续性,分布式系统,游戏
AI agent 正在成为一个新兴领域
| 工业界 | 学术界 | 框架 | 评估 |
|---|---|---|---|
| OpenAI GPTs | SayCan | Reasoning | World of bits |
| Microsoft Copilot | Code as policies | Planning | Mind2Web |
| Adept ACT-1 | ReAct | Grounding | WebArena |
| AutoGPT | Generative agents | Memory | AitW |
| Langchain | Voyager | Tool use | AgentBench |
| Llamalndex | Eureka | Reflection | RT-X |
Classifying ambiguous identities in hidden‑role Stochastic games with multi‑agent reinforcement learning


由人类 & 特殊AI agents & Foundation agents 组成的 Agent Society。
专题报告
智能体学习理论(专题一)
Wang-LiWei 王立威 : Chain of Thought (CoT) 大模型推理的关键技术
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models

Self-consistency improves chain of thought reasoning in language models

由于大多数 LLMs 都遵循 autoregressive 的结构范式,即输出结果的 token 是顺序产生的,并且加在已生成的 Sequence 后作为再输入。从架构层面解释了为什么 CoT prompt 所带来的提升这么明显。作者从理论角度对CoT进行解释,并在两个数学领域(四则运算、线性方程组)展开探讨。
Towards Revealing the Mystery behind Chain of Thought: A Theoretical Perspective
Yang Yuan 袁洋 : On the Power of Foundation Models
On the Power of Foundation Models
Yuan 提出一个观点:Intelligence is Positioning.
预训练算法是在学习一个类别中的态射(形态)
- 对比学习 : 相似性
- Masked modeling : Masked对象 -> 完整对象
- language model: 句子 -> next 句子
Wang-Jun 汪军 : On Physical foundations of AI Agents
学习是通过已知经验改变行为的过程。
AI Agent 的定义应该取决于其所处环境。
Agent 与 Maxwell’s Demon(Maxwell on Heat and Statistical Mechanics)
麦克斯韦妖是麦克斯韦在19世纪70年代提出的一个概念,它显然可以推翻热力学第二定律。被推翻的定律就不再是定律,因此,魔鬼的概念似乎对物理学的基本理解产生了怀疑,而物理学是一个强大的概念。恶魔(麦克斯韦称其为“agent”;威廉·汤姆森将其命名为“demon”)在一个被隔板隔开的气体盒子之间开了一个活板门,监视快速移动的分子,让它们进入一边,但保留慢速移动的分子。他也可以反过来做。例如,过了一段时间,一半的气体变热,一半变冷,而不消耗能量。事实上,现在我们可以做一些工作来恢复热平衡,但只要有这样一个恶魔,就可以提取无限的能量。

Demon 的另一个可能的动作是,他可以观察分子,只有当分子从右边接近陷阱门时才打开门。这将导致所有的分子最终都在左边。同样,此设置可用于运行引擎。这一次,人们可以在隔板中放置一个活塞,让气体流入活塞腔,从而推动一根杆,产生有用的机械功。这种假想的情况似乎与热力学第二定律相矛盾。为了解释这个悖论,科学家们指出,要实现这种可能性,Demon 仍然需要使用能量来观察分子(例如以光子的形式)。而 Demon 本身(加上陷阱门机制)会在移动陷阱门时从气体中获得熵。因此,系统的总熵仍然增加。Demon 试图从系统中创造比原来更多的有用能量。同样地,他减少了系统的随机性(通过按照一定的规则排列分子),从而减少了熵。目前还没有发现这种违反热力学第二定律的现象。更少的有用能量意味着更多的随机性和熵。
对于一个存在智能体的环境,在不施加任何功的情况下,可以降低系统的总熵。
Laurent Lafforgue : Reality and its representations: a mathematical model

劳老师数学造诣过高,个人水平有限,实在没听懂在讲啥,对不起。
Rasul Tutunov : Why Can Large Language Models Generate Correct Chain-of-Thoughts
Why Can Large Language Models Generate Correct Chain-of-Thoughts?
 与CoT生成相容的自然语言文本生成的概率图形模型。
与CoT生成相容的自然语言文本生成的概率图形模型。


Olivia Caramello : Syntactic Learning Via Topos Theory
On morphisms of relative toposes
智能体决策与规划(专题二)
Zhang-zongchang 章宗长: 驾驭信息:智能决策Agent的设计及挑战
DIKW金字塔理论

- D:数据,构成信息和知识的原始材料
- I:信息,数据所包含的意义,是数据描述的不确定性减少
- 信息熵 H = − ∑ i = 1 N p i ⋅ l o g p i H=-\sum_{i=1}^{N}p_i\cdot logp_i H=−∑i=1Npi⋅logp