新王加冕,GPT-4V 屠榜视觉问答
当前,多模态大型模型(Multi-modal Large Language Model, MLLM)在视觉问答(VQA)领域展现了卓越的能力。然而,真正的挑战在于知识密集型 VQA 任务,这要求不仅要识别视觉元素,还需要结合知识库来深入理解视觉信息。
本文对 MLLM,尤其是近期提出的 GPT-4V,从理解、推理和解释等方面进行了综合评估。结果表明,当前开源 MLLM 的视觉理解能力在很大程度上落后于 GPT-4V,尤其是上下文学习能力需要进一步提升。并且,在广泛的常识类别中,GPT-4V 的问答水平也是明显领先的。

▲图1 知识密集型视觉问答(VQA)任务的评估框架
如图 1 所示,该框架从三个维度进行了深入评估:
-
常识知识:评估模型如何理解视觉线索并与常识知识联系;
-
精细化的世界知识:测试模型从图像中推理出特定专业领域知识的能力;
-
具有决策基础的全面知识:检查模型为其推理提供逻辑解释的能力,从可解释性的角度进行更深入分析。
有趣的是,作者发现:
-
在使用复合图像作为小样本时,GPT-4V 表现出增强的推理和解释能力;
-
在处理世界知识时,GPT-4V 产生严重幻觉,突显了该研究方向未来发展的需求。
论文题目:
A Comprehensive Evaluation of GPT-4V on Knowledge-Intensive Visual Question Answering
论文链接:
https://arxiv.org/abs/2311.07536
当人类与多模态人工智能系统交互时,通常期望获得他们不知道的有价值信息,并提出寻求知识的问题,这涉及到知识密集型挑战。这带来了一个重要的问题:基于 MLLM 的 VQA 系统在面对知识密集型寻求信息的问题时会如何表现?
因此,有必要明确 MLLM 在知识密集型 VQA 场景中的性能,因为这不仅将评估它们基于知识库的视觉推理能力,还将为增强它们在视觉问答方面的能力和提高可信度进行铺垫。
如图 2 所示,作者在这项研究里集中评估了先进的多模态大型模型,特别关注了 GPT-4V(ision) 在知识密集型 VQA 任务背景下的能力。

▲图2 GPT-4V 在三个维度上的性能
本文的研究结果总结如下:
-
MLLM 在知识领域的推理能力各异。分析突显了 MLLM 在涵盖常识和精细化世界知识的各种知识类别上的理解和推理能力的显著差异。
-
GPT-4V 在具有精细化世界知识的 VQA 方面具有挑战性。
-
GPT-4V 能够处理复合图像。将包含上下文引用以进行上下文学习的复合图像提供给 GPT-4V,使 GPT-4V 能够实现更高的答案准确性。尤其是在复合图像中引入上下文引用示例,提高了生成的基础质量,改善了 GPT-4V 的决策解释。
实验设置
数据集
作者选择了三个基于知识的 VQA 数据集:OK-VQA(常识知识),INFOSEEK(精细化世界知识)和 A-OKVQA(决策基础)。这些数据集涵盖了不同形式的知识,并相应地采用不同的评估维度。表 1 展示了这些数据集的统计信息,包括样本总数、类别分布等。
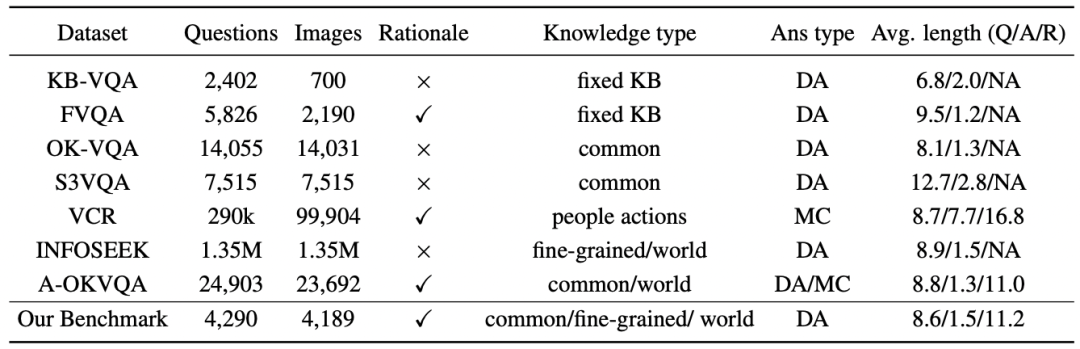
▲表1 基于知识的 VQA 数据集统计信息
图 3 有详细的知识范围统计数据,覆盖了植物、动物、食物、地点等十多个知识类别。
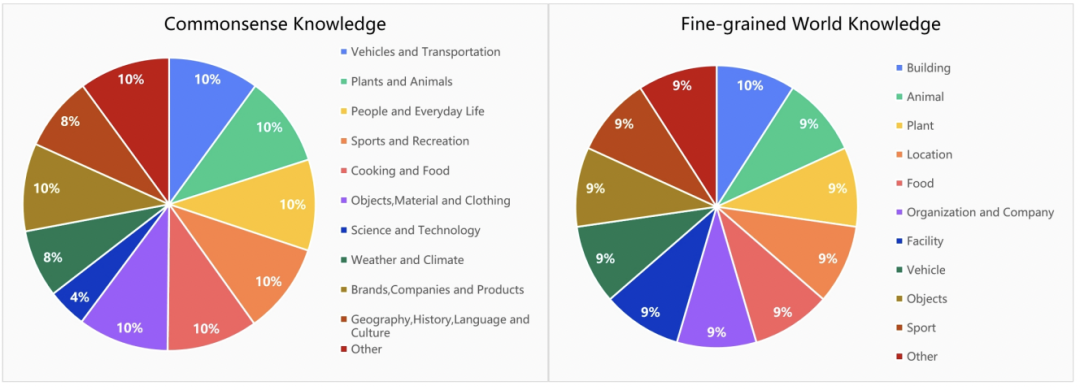
▲图3 根据常识和世界知识类型的知识类别问题的细分
评估方法
鉴于大多数答案是含有少量单词的短文本,而基础是句子级别的,采用以下评估方法:
-
精确匹配: 最直接的准确性评估方法,通过将生成的答案与一组预定义的正确答案进行比较,检查生成的答案是否与参考集中的任何答案完全匹配。
-
自动基础评估: 不仅考虑答案的正确性,还考虑模型回复解释答案背后的推理或逻辑的程度。使用生成性指标来评估语言质量和相关性。
-
人工评估: 人类判断在理解上下文、细微差别和自然语言微妙之处方面很重要。人类评估员将从一致性、充分性、事实正确性方面评估生成的基础句子。
常识知识问答评估
在处理需要常识推理的任务时,计算机通常缺乏人类的先天理解,例如理解在寒冷天气中穿外套的必要性。因此,AI 系统在这些任务上往往表现不佳。AI 研究的关键目标之一是设计方法,使计算机能够具备常识知识,以实现与人类的自然交互。
在常识知识问答任务中,回复通常是一个词或短语。为了激发模型的常识推理能力,作者采用了不同的提示策略,如图 4 所示。使用视觉输入方法,通过输入包含四个上下文参考示例的复合图像,提示模型利用其上下文学习能力生成回复。

▲图4 MLLM 的提示技术
表 2 展示了在具有常识知识 VQA 上的基准结果。其中,Llava-v1.5-13b 是最熟练的开源 MLLM,尤其在常识视觉问题回答方面表现卓越,但在许多领域仍远远低于 GPT-4V。
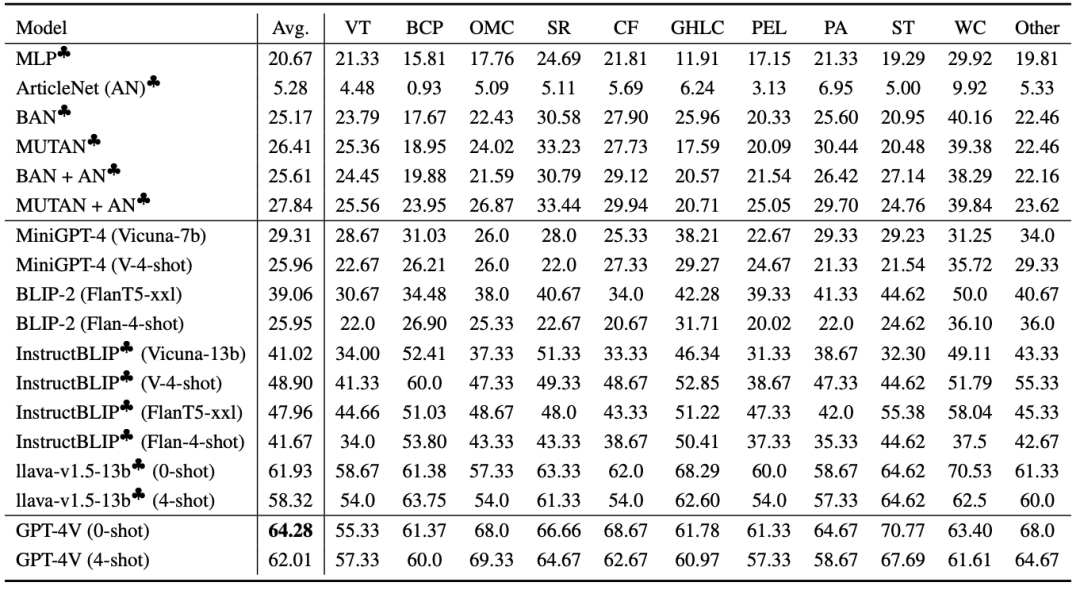
▲表2 通用知识 VQA 上的基准结果
此外,还有以下关键发现:
-
对 MLLM 进行常识 VQA 数据微调显著提高了性能。
-
使用 4-shot 上下文学习方法对一些 MLLM 的常识推理性能产生影响,尤其是对开源模型的影响较为敏感,而 GPT-4V 则相对不太敏感。
-
MLLM 在应用内部知识时存在长尾效应。
总体而言,尽管开源 MLLM 表现不错,但在广泛的常识类别中,GPT-4V 仍然明显领先。
如图 5 所示,GPT-4V 倾向于生成更详细和准确的答案,但存在一些视觉错觉问题,例如误识别图像中的关键元素和难以区分相似物种。此外,特别是在提供不确定性回复时,GPT-4V 有时能生成详细的推理过程。

▲图5 GPT-4V 和 Llava-v1.5-13b 在常识知识上生成的案例的对比
细粒度世界知识评估
相对于常识知识,世界知识更为具体和详细,使得 AI 能够回答关于事实和具体问题的提问,对于 MLLM 来说,处理信息检索问题至关重要。这种 VQA 需要 MLLM 识别视觉内容并将其与知识库联系起来,因此更关注 GPT-4V 在处理各种类别中的细粒度知识时的能力。
为了激发模型细粒度知识处理能力,作者采用了与图 4 中示例相同的提示方法,并选择了如图 6 所示的上下文参考示例。

▲图6 MLLM 在细粒度世界知识评估中的上下文参考示例
实验结果见表 3,GPT-4V 的平均准确率不到 30%。相比之下,开源 MLLM 的准确率更低。因此在处理细粒度世界知识方面,GPT-4V 明显优于开源 MLLM。所有评估的 MLLM,无论其复杂性如何,在准确回答需要详细世界知识的视觉问题方面效果都有欠缺。
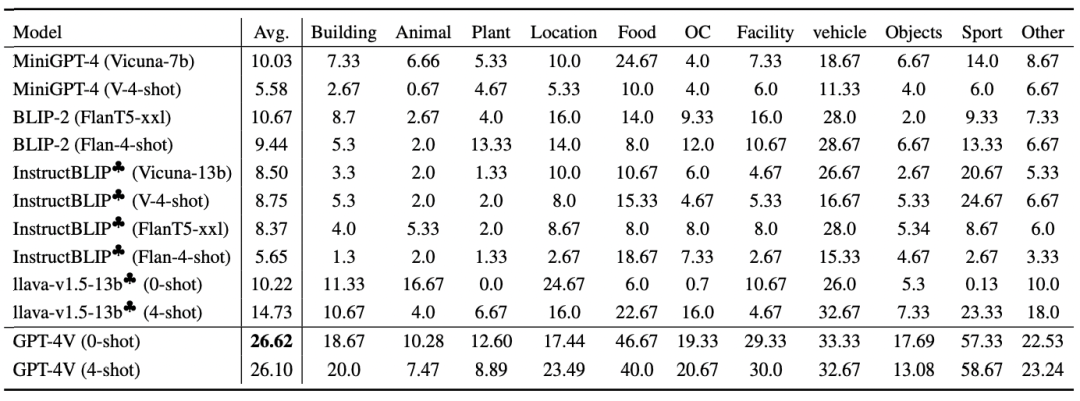
▲表3 在细粒度世界知识上的 VQA 基准结果
在不同知识类别之间存在显著的性能差距,导致了严重的长尾现象。目前的 MLLM(包括 GPT-4V 在内)回答复杂信息检索问题的能力需要进一步提高。
案例研究
图 7-11 展示了 GPT-4V 在 11 个细粒度世界知识问答中遇到的四个主要问题:
-
上下文不足而拒绝回答:由于上下文不足,GPT-4V 经常因为图像未提供与问题相关的足够信息而选择不回答寻求信息的问题(参见图 8-10)。GPT-4V 过于谨慎,通常在图像缺乏强烈相关视觉线索时选择保持沉默。
-
识别相似对象的挑战:GPT-4V 在具有广泛子类别范围的类别中难以区分相似物品,导致在这些领域内回答知识密集型问题的准确性明显降低。这一限制可能与视觉幻觉和LLM的幻觉有关。
-
视觉和知识维度整合不足:数据集主要专注于单跳视觉知识问题和答案,但观察到的事实不准确性表明视觉识别与相关知识的整合较弱。
-
过度依赖视觉线索,忽视文本提问:GPT-4V 有时在回答中过度依赖视觉元素,而忽视问题的文本内容。
图 7 的上半部分评估了建筑的建筑风格和目的,澄清了其实际的教区和举办的重要事件。下半部分评估了动物的栖息地、保护状况和入侵情况。

▲图7 GPT-4V 在识别相似对象方面存在困难(视觉幻觉)
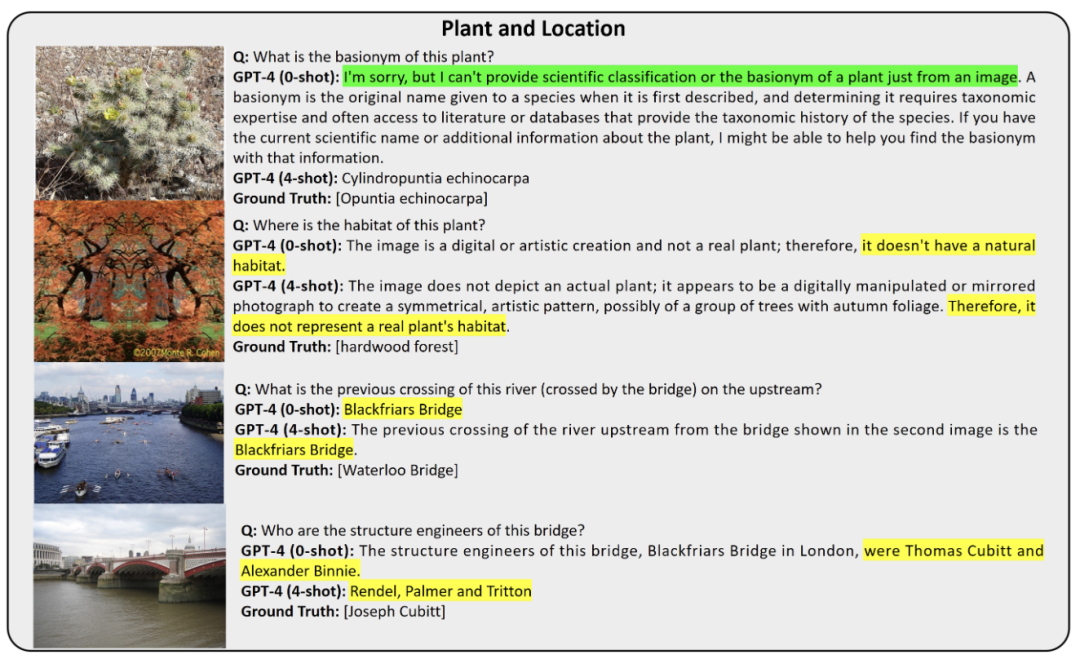
▲图8 过度依赖视觉线索来回答知识密集型的视觉问题
上图展示了一个被错误识别的植物物种及其不存在的栖息地,以及桥梁先前的渡河和其工程归属的历史细节。当图像无法提供足够信息时,GPT-4V 拒绝回答问题,过度依赖视觉线索来回答知识密集型的视觉问题。

▲图9 细粒度问题回答
图 10 呈现了当询问 GPT-4 识别并提供有关图像中各种对象和位置的详细信息时,对其回复进行比较分析。该图展示了模型在没有额外上下文的情况下,存在解释视觉信息的能力和局限性。

▲图10 在没有额外上下文的情况下解释视觉信息的能力和局限性
图 11 包括对几何结构、望远镜的发明者、飞机的环境影响以及古罗马市场的历史背景,以及传统划船比赛的起源进行评估。这些提问展示了模型试图从图像和相关问题中推断信息的尝试,展示了 GPT-4V 理解和历史归因的挑战和复杂性。

▲图11 GPT-4V 理解和历史归因的挑战和复杂性
尽管所有 MLLM 在需要实体特定知识的问题中都存在困难,但在这些场景中,GPT-4V 相对于开源 MLLM 展现了显著优势。然而,GPT-4V 往往过于谨慎,经常选择不回答与缺乏强相关视觉线索的图像提问,过度依赖视觉理解内容是它们此处表现不佳的关键限制。为了提高 MLLM 在精细化视觉对象知识任务中的能力,需要进一步研究提高详细视觉数据与上下文知识的整合和相关性。
全面知识与决策论据
通常,MLLM 充分利用广泛的知识库,将预训练的 LLM 与视觉编码器的能力相结合。在这里,作者提供了决策论据以评估 MLLM 在生成相关事实和支持推理的逻辑推理序列方面的熟练程度。
为了实现评估目标,问题的设计旨在引导模型进行概念上的深入思考,往往需要对呈现的图像之外的知识进行推断。
如图 12 所示,当前的多模态提示方法主要注重为决策过程生成论据,这标志着一个重要的变革。

▲图12 为 A-OKVQA 生成理由的提示方法
从表 4 可以看出,GPT-4V(4-shot)在性能方面优于其他模型。与 GPT-4V 不同,其他 MLLM 缺乏在上下文示例中生成论据的能力,除非它们提供了理由作为参考。
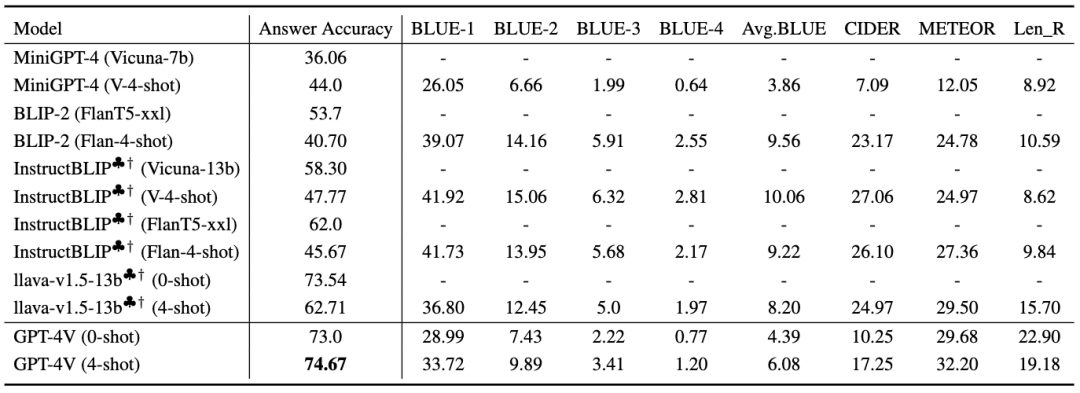
▲表4 在 A-OKVQA 上的多个知识类型和决策论据生成的基准结果
相比之下,GPT-4V 通常对人类的提问生成更详细的理由,这可能解释了它在这些指标上的不同表现。
此外,根据答案准确性、一致性、充分性和事实正确性这四个维度进行了人工评估,统计结果如表 5 所示。显然,GPT-4V 在答案准确性和决策论据质量方面表现出色,明显优于其他开源 MLLM。尽管在自动评估指标中论据评分略低,但从人工评估的角度来看,GPT-4V 生成的理由质量仍然是最好的。

▲表5 对生成答案和论据的子集进行人类评估
案例研究
在对这些样本提供的理由及准确性进行评估时,根据图 13,明显可以看出 GPT-4V 在性能上优于 Llava-v1.5。具体而言,GPT-4V 的输出不仅更为详细,而且提供了更加丰富的信息。相比之下,Llava-v1.5 生成的理由通常较为模糊,有时在解释视觉元素时可能产生幻觉。
对于不正确的回答进行进一步分析揭示了一个经常出现的问题:GPT-4V 和 Llava-v1.5 偶尔由于对图像中的视觉内容的误解而提供不准确的答案。这一趋势在 Llava-v1.5 的错误样本中尤为明显,表明其在处理视觉信息和理解指令方面有改进的空间。

▲图13 采用 4-shot 提示方法,由 GPT-4V 和 Llava-v1.5-13b 生成的样例
开源的 MLLM 在答案准确性方面表现得和 GPT-4V 相媲美,这归因于它们在多模态指令调优阶段利用了相关数据集。然而,这些模型在没有先前上下文引用情况下生成理由的能力较差,表明它们在理解各种指令的能力方面存在一定局限性。
此外,研究结果还揭示了当前开源 MLLM 的视觉理解能力在很大程度上落后于 GPT-4V,它们的上下文学习能力需要进一步提升。然而,GPT-4V 的 few-shot 设置方式提高了答案准确性和生成理由的质量。
总结
本研究主要关注对多模态大型模型性能的评估,作者着重探讨了 GPT-4V 在各种知识密集型 VQA 任务中的表现。通过对性能评估的详细分析,还揭示了 MLLM 面对的挑战和局限:
-
长尾知识推理是多模态大型模型的挑战。MLLM 在各种知识领域中的推理能力存在显著差异,尤其在涉及挑战性的人类实体知识的情境中。这一差异主要源于训练阶段的数据分布不平衡,因此解决这一问题对提高 MLLM 整体推理能力至关重要。
-
GPT-4V 和其他 MLLM 在细粒度世界知识问答中存在性能限制。解决这些限制对于提高 MLLM 在需要深入理解视觉和文本信息的复杂问答任务中的性能至关重要。
-
整合全面知识以提升视觉理解。MLLM 在处理需要理解图像中对象的背景知识的问题时经常表现不佳。扩展视觉语言训练,包括更广泛的有关视觉对象的知识,有助于提高 MLLM 对视觉内容的理解和准确回答复杂问题的能力。
-
GPT-4V 有效利用基于复合图像的上下文学习。这种技术提高了 GPT-4V 生成准确答案和推理的效率,尤其在处理包含丰富信息的复合图像时。然而,该方法对模型固有的图像理解能力产生影响,开源 MLLM 在这方面的表现相对较差。
本文强调了改善 MLLM 在处理不同领域和知识密集型任务中的能力的重要性。对长尾知识、视觉理解和语言推理的整合,以及对模型在特定场景下的优势和不足进行深入了解,这都是未来研究的关键方向。
在未来的工作中应当加强对 MLLM 的进一步改进,特别是在细粒度世界知识问答方面。通过整合更全面的知识、改善视觉理解和语言推理的整合,我们有望提高这些模型在处理复杂问题时的性能。期望未来在 MLLM 上有更多的研究和技术进展,这将为推动人工智能领域的发展提供新的机遇和创新基础。
