第三节:支持向量机分类预测
0、介绍
监督学习(英语:Supervised learning)是机器学习中最为常见、应用最为广泛的分支之一。本次实验将带你了解监督学习中运用十分广泛的支持向量机,并学会使用 scikit-learn 来构建预测模型,用于解决实际问题。
知识点
- 理论基础
- 线性分类
- 非线性分类
1、线性支持向量机
在上一节关于线性模型的课程中,我们学习了通过感知机构建一个线性分类器,完成二分类问题。
感知机的学习过程由误分类驱动,即当感知机寻找到没有实例被错误分类时,就确定了分割超平面。这样虽然可以解决一些二分类问题,但是训练出来的模型往往容易出现过拟合。

如上图所示,当感知机在进行分类时,为了照顾左下角的两个红色标记样本,分割线会呈现出如图所示的走向。你应该通过观察就能发现,这条分割线不是特别合理。
于是,Vapnik 于 1963 年提出了支持向量机理论,并将其用于解决线性分类问题。支持向量机也被看成是感知机的延伸。简单来讲,支持向量机就是通过找出一个最大间隔超平面来完成分类。

如图所示,中间的实线是我们找到的分割超平面。这个超平面并不是随手一画,它必须满足两个类别中距离直线最近的样本点,与实线的距离一样且最大。这里的最大,也就是上面提到的最大间隔超平面。
许多朋友在一开始接触支持向量机时,对它这个奇怪的名字比较疑惑。其实,支持向量机中的「支持向量」指的是上图中,距离分割超平面最近的样本点,即两条虚线上的一个实心点和两个空心点。
接下来我们就来通过 scikit-learn 对上面的红蓝样本数据分别进行线性支持向量机和感知机分类实验。

首先,我们需要先导入数据文件,这里使用到了 Pandas。如果你没有用过也不必担心,我们只是使用了其中导入 CSV 文件的一个方法。
import pandas as pd # 导入 pandas 模块
import warnings
warnings.filterwarnings('ignore')
# 读取 csv 数据文件
df = pd.read_csv(
"https://labfile.oss.aliyuncs.com/courses/866/data.csv", header=0)
df.head()
你可以直接通过 df.head() 语句查看一下这个数据集头部,对里面的数据组成初步熟悉一下。
| x | y | class | |
|---|---|---|---|
| 0 | 0.178681 | 0.300682 | 0 |
| 1 | 0.202033 | 0.320188 | 0 |
| 2 | 0.175568 | 0.290042 | 0 |
| 3 | 0.156886 | 0.284722 | 0 |
| 4 | 0.144432 | 0.302455 | 0 |
我们可以看到,有两个类别。其中 0 即表示上面图中的蓝色样本点,1 对应着红色样本点。
和上一节课的过程相似,下面导入分割模块,将整个数据集划分为训练集和测试集两部分,其中训练集占 70%。
from sklearn.model_selection import train_test_split # 导入数据集划分模块
# 读取特征值及目标值
feature = df[["x", "y"]]
target = df["class"]
# 对数据集进行分割
train_feature, test_feature, train_target, test_target = train_test_split(
feature, target, test_size=0.3)
接下来,导入线性支持向量机分类器。
from sklearn.svm import LinearSVC # 导入线性支持向量机分类器
# 构建线性支持向量机分类模型
model_svc = LinearSVC()
model_svc.fit(train_feature, train_target)
# LinearSVC(C=1.0, class_weight=None, dual=True, fit_intercept=True,
# intercept_scaling=1, loss='squared_hinge', max_iter=1000,
# multi_class='ovr', penalty='l2', random_state=None, tol=0.0001,
# verbose=0)
然后,我们对模型在测试集上的准确度进行评估,之前使用了 accuracy_score ,这里使用模型带有的 score 方法效果是一样的。
# 支持向量机分类准确度
model_svc.score(test_feature, test_target)
# 1.0
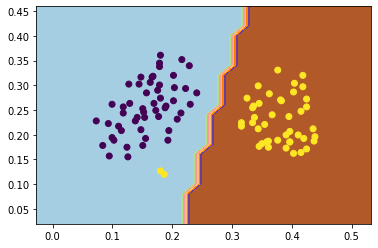
可以看出,线性支持向量机分类准确率还不错。我们使用前面相似的方法来绘制出分类器的决策边界。
import numpy as np
from matplotlib import pyplot as plt
%matplotlib inline
# 创建一个绘图矩阵方便显示决策边界线
X = feature.values
x_min, x_max = X[:, 0].min() - 0.1, X[:, 0].max() + 0.1
y_min, y_max = X[:, 1].min() - 0.1, X[:, 1].max() + 0.1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02))
fig, ax = plt.subplots()
# 绘制决策边界
Z = model_svc.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
ax.contourf(xx, yy, Z, cmap=plt.cm.Paired)
# 绘制训练和测试数据
ax.scatter(train_feature.values[:, 0], train_feature.values[:, 1], c=train_target)
ax.scatter(test_feature.values[:, 0], test_feature.values[:, 1], c=test_target)
# <matplotlib.collections.PathCollection at 0x7f8ad52d1c10>
2、非线性支持向量机
通过上面的内容,你应该对线性分类有所了解,并可以使用支持向量机构建一个简单的线性分类器了。而在实际生活中,我们大部分情况面对的却是非线性分类问题,因为实际数据往往都不会让你通过一个水平超平面就能完美分类。

上图展现的就是一个非线性分类问题,而支持向量机就是解决非线性分类的有力武器。那么支持向量机是如何实现非线性分类呢?
这里,支持向量机引入了核函数来解决非线性分类的问题。简单来讲,通过核函数,我们可以将特征向量映射到高维空间中,然后再高维空间中找到最大间隔分割超平面完成分类。而映射到高维空间这一步骤也相当于将非线性分类问题转化为线性分类问题。

如上图所示:
- 第一张图中,红蓝球无法进行线性分类。
- 使用核函数将特征映射到高维空间,类似于在桌子上拍一巴掌使小球都飞起来了。
- 在高维空间完成线性分类后,再将超平面重新投影到原空间。
在将特征映射到高维空间的过程中,我们常常会用到多种核函数,包括:线性核函数、多项式核函数、高斯径向基核函数等。其中,最常用的就算是高斯径向基核函数了,也简称为 RBF 核。
接下来,我们就通过 scikit-learn 来完成一个非线性分类实例。这次,我们选择了 digits 手写数字数据集。digits 数据集无需通过外部下载,可以直接由 scikit-learn 提供的 datasets.load_digits() 方法导入。该数据集的详细信息如下:
| 方法 | 描述 |
|---|---|
| ('images', (1797L, 8L, 8L)) | 数据集包含 1797 张影像,影像大小为 8x8 |
| ('data', (1797L, 64L)) | data 将 8x8 像素根据其灰度值转换为矩阵 |
| ('target', (1797L,)) | 记录 1797 张影像各自代表的数字 |
第一步,导入数据并进行初步观察。
from sklearn import datasets # 导入数据集模块
# 载入数据集
digits = datasets.load_digits()
# 绘制数据集前 5 个手写数字的灰度图
for index, image in enumerate(digits.images[:5]):
plt.subplot(2, 5, index+1)
plt.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest')
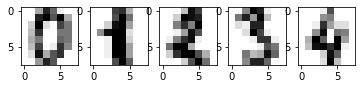
可以用 digits.target[:5] 查看前五张手写数字对应的实际标签。
digits.target[:5]
# array([0, 1, 2, 3, 4]) 通常,我们在处理图像问题时,都是将图像的每一个像素转换为灰度值或按比例缩放的灰度值。有了数值,就可以构建和图像像素大小相同的矩阵了。在这里,digits 已经预置了每一张图像对应的矩阵,并包含在 digits.images 方法中。
我们可以通过 digits.images[1] 输出第 1 张手写数字对应的 8x8 矩阵。很方便地,scikit-learn 已经将 8x8 矩阵转换成了方便作为特征变量输入 64x1 的矩阵,并放在了 digits.data 中。你可以使用 digits.data[1]查看。
digits.data[1]
# 输出如下
array([ 0., 0., 0., 12., 13., 5., 0., 0., 0., 0., 0., 11., 16.,
9., 0., 0., 0., 0., 3., 15., 16., 6., 0., 0., 0., 7.,
15., 16., 16., 2., 0., 0., 0., 0., 1., 16., 16., 3., 0.,
0., 0., 0., 1., 16., 16., 6., 0., 0., 0., 0., 1., 16.,
16., 6., 0., 0., 0., 0., 0., 11., 16., 10., 0., 0.])
如果你连续学习了前面的小节,你应该对接下来的实验步骤比较熟悉了。下面,我们需要划分训练集和测试集,然后针对测试集进行预测并评估预测精准度。
from sklearn.svm import SVC # 导入非线性支持向量机分类器
from sklearn.metrics import accuracy_score # 导入评估模块
feature = digits.data # 指定特征
target = digits.target # 指定目标值
# 划分数据集,将其中 70% 划为训练集,另 30% 作为测试集
train_feature, test_feature, train_target, test_target = train_test_split(
feature, target, test_size=0.33)
model = SVC() # 建立模型
model.fit(train_feature, train_target) # 模型训练
results = model.predict(test_feature) # 模型预测
scores = accuracy_score(test_target, results) # 评估预测精准度
scores
# 0.9781144781144782最后,模型预测准确度为 97.8%。由于每一次运行时,数据集都会被重新划分,所以你训练的准确度甚至会低于 97.8%。如果你还想提高一下准确度,准确度为什么这么低,让支持向量机的分类效果更好,可以通过调整参数来做到。
不要忘记了,我们在建立模型的时候使用的是默认参数。
model
# 输出如下
SVC(C=1.0, break_ties=False, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='scale', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)上面输出了默认模型的参数。我们可以看到,该模型的确使用了最常用的 RBF 高斯径向基核函数,这没有问题。问题出在了 gamma 参数,gamma 是核函数的因数,这里选择了 auto 自动(gamma当前的默认值“auto”将在0.22版本中更改为“scale”)。自动即表示 gamma 的取值为 1 / 特征数量,这里为 1/64。
你可以尝试将 gamma 参数的值改的更小一些,比如 0.001。重新建立模型
model = SVC(gamma=0.001) # 重新建立模型
model.fit(train_feature, train_target) # 模型训练
results = model.predict(test_feature) # 模型预测
scores = accuracy_score(test_target, results) # 评估预测精准度
scores
# 0.9932659932659933可以看到,这一次的预测准确度已经达到 99.3% 了,结果非常理想。所以说,会用 scikit-learn 建立模型只是机器学习过程中最基础的一步,更加重要的是理解模型的参数,并学会调参使得模型的预测性能更优。
小练习
通过 官方文档 了解 scikit-learn 中支持向量机分类器 sklearn.svm.SVC 中包含的参数,并尝试修改它们查看结果变化。
实验总结
支持向量机是机器学习中非常实用的模型之一。它理论基础完善,分类结果出色,深受数据科学家的喜欢。希望能通过本次实验,掌握支持向量机的基本原理,并学会使用 scikit-learn 构建一个支持向量机分类模型。