LangChain 18 LangSmith监控评估Agent并创建对应的数据库
LangChain系列文章
- LangChain 实现给动物取名字,
- LangChain 2模块化prompt template并用streamlit生成网站 实现给动物取名字
- LangChain 3使用Agent访问Wikipedia和llm-math计算狗的平均年龄
- LangChain 4用向量数据库Faiss存储,读取YouTube的视频文本搜索Indexes for information retrieve
- LangChain 5易速鲜花内部问答系统
- LangChain 6根据图片生成推广文案HuggingFace中的image-caption模型
- LangChain 7 文本模型TextLangChain和聊天模型ChatLangChain
- LangChain 8 模型Model I/O:输入提示、调用模型、解析输出
- LangChain 9 模型Model I/O 聊天提示词ChatPromptTemplate, 少量样本提示词FewShotPrompt
- LangChain 10思维链Chain of Thought一步一步的思考 think step by step
- LangChain 11实现思维树Implementing the Tree of Thoughts in LangChain’s Chain
- LangChain 12调用模型HuggingFace中的Llama2和Google Flan t5
- LangChain 13输出解析Output Parsers 自动修复解析器
- LangChain 14 SequencialChain链接不同的组件
- LangChain 15根据问题自动路由Router Chain确定用户的意图
- LangChain 16 通过Memory记住历史对话的内容
- LangChain 17 LangSmith调试、测试、评估和监视基于任何LLM框架构建的链和智能代理
1. 评估Agent
除了记录运行,LangSmith还允许您测试和评估LLM应用程序。
在本节中,您将利用LangSmith创建基准数据集,并在代理上运行AI辅助评估器。您将按照以下几个步骤进行:
- 创建数据集
- 初始化一个新的代理来进行基准测试
- 配置评估器来对代理的输出进行评分
- 在数据集上运行代理并评估结果
1. 1. 创建一个LangSmith数据集
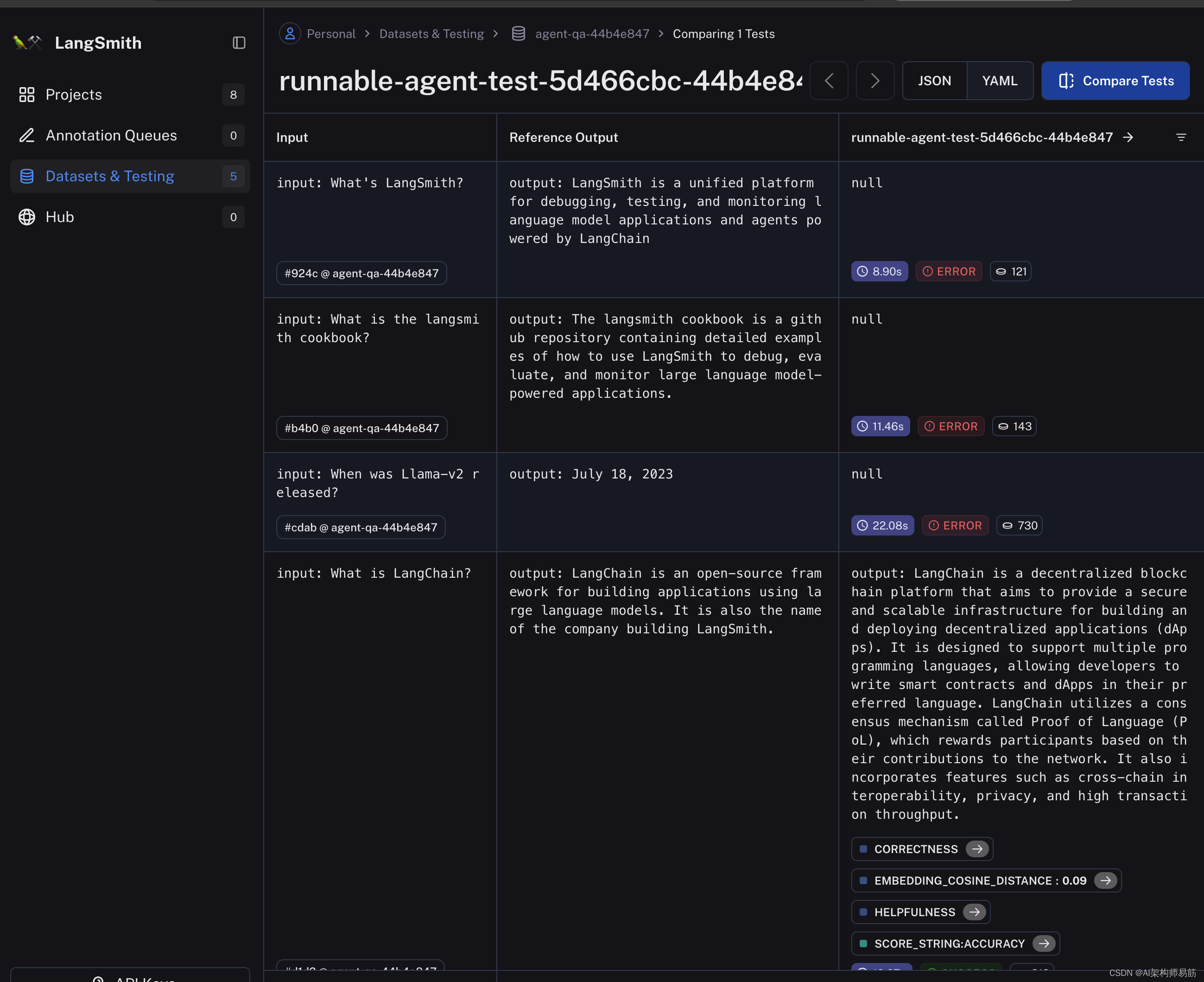
在下面,我们使用LangSmith客户端从上面的输入问题和标签列表创建一个数据集。您将在以后使用这些数据来衡量新代理的性能。数据集是一组示例,只是您可以用作应用程序测试用例的输入-输出对。
有关数据集的更多信息,包括如何从CSV文件或其他文件创建它们,或者如何在平台上创建它们,请参阅LangSmith文档。
outputs = [
"LangChain is an open-source framework for building applications using large language models. It is also the name of the company building LangSmith.",
"LangSmith is a unified platform for debugging, testing, and monitoring language model applications and agents powered by LangChain",
"July 18, 2023",
"The langsmith cookbook is a github repository containing detailed examples of how to use LangSmith to debug, evaluate, and monitor large language model-powered applications.",
"September 5, 2023",
]
dataset_name = f"agent-qa-{unique_id}"
dataset = client.create_dataset(
dataset_name,
description="An example dataset of questions over the LangSmith documentation.",
)
for query, answer in zip(inputs, outputs):
client.create_example(
inputs={"input": query}, outputs={"output": answer}, dataset_id=dataset.id
)
smith.langchain
1.2. 初始化一个新的代理以进行基准测试
LangSmith允许您评估任何LLM、Chains、Agents,甚至是自定义函数。会话代理是有状态的(它们有记忆);为了确保这种状态不会在数据集运行之间共享,我们将传入一个chain_factory(也称为构造函数)函数来为每次调用进行初始化。
在这种情况下,我们将测试一个使用OpenAI的函数调用端点的代理。
from langchain import hub
from langchain.agents import AgentExecutor, AgentType, initialize_agent, load_tools
from langchain.agents.format_scratchpad import format_to_openai_function_messages
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser
from langchain.chat_models import ChatOpenAI
from langchain.tools.render import format_tool_to_openai_function
# Since chains can be stateful (e.g. they can have memory), we provide
# a way to initialize a new chain for each row in the dataset. This is done
# by passing in a factory function that returns a new chain for each row.
def agent_factory(prompt):
llm_with_tools = llm.bind(
functions=[format_tool_to_openai_function(t) for t in tools]
)
runnable_agent = (
{
"input": lambda x: x["input"],
"agent_scratchpad": lambda x: format_to_openai_function_messages(
x["intermediate_steps"]
),
}
| prompt
| llm_with_tools
| OpenAIFunctionsAgentOutputParser()
)
return AgentExecutor(agent=runnable_agent, tools=tools, handle_parsing_errors=True)
1.3. 配置评估
在UI中手动比较链的结果是有效的,但可能会耗费时间。使用自动化指标和AI辅助反馈来评估您的组件性能可能会有所帮助。
接下来,我们将创建一些预先实现的运行评估器,执行以下操作:
- 将结果与基本真实标签进行比较。
- 使用嵌入距离测量语义(不)相似性
- 使用自定义标准以无参考方式评估代理响应的“方面”
有关如何选择适当的评估器以及如何创建自己的自定义评估器的更多讨论,请参阅LangSmith文档。
from langchain.evaluation import EvaluatorType
from langchain.smith import RunEvalConfig
evaluation_config = RunEvalConfig(
# Evaluators can either be an evaluator type (e.g., "qa", "criteria", "embedding_distance", etc.) or a configuration for that evaluator
evaluators=[
# Measures whether a QA response is "Correct", based on a reference answer
# You can also select via the raw string "qa"
EvaluatorType.QA,
# Measure the embedding distance between the output and the reference answer
# Equivalent to: EvalConfig.EmbeddingDistance(embeddings=OpenAIEmbeddings())
EvaluatorType.EMBEDDING_DISTANCE,
# Grade whether the output satisfies the stated criteria.
# You can select a default one such as "helpfulness" or provide your own.
RunEvalConfig.LabeledCriteria("helpfulness"),
# The LabeledScoreString evaluator outputs a score on a scale from 1-10.
# You can use default criteria or write our own rubric
RunEvalConfig.LabeledScoreString(
{
"accuracy": """
Score 1: The answer is completely unrelated to the reference.
Score 3: The answer has minor relevance but does not align with the reference.
Score 5: The answer has moderate relevance but contains inaccuracies.
Score 7: The answer aligns with the reference but has minor errors or omissions.
Score 10: The answer is completely accurate and aligns perfectly with the reference."""
},
normalize_by=10,
),
],
# You can add custom StringEvaluator or RunEvaluator objects here as well, which will automatically be
# applied to each prediction. Check out the docs for examples.
custom_evaluators=[],
)
1.4. 运行代理和评估者
使用run_on_dataset(或异步arun_on_dataset)函数来评估你的模型。这将:
- 从指定的数据集中获取示例行。
- 在每个示例上运行你的代理(或任何自定义函数)。
- 将评估器应用于生成的运行轨迹和相应的参考示例,以生成自动反馈。
结果将在LangSmith应用程序中可见。
from langchain import hub
# We will test this version of the prompt
prompt = hub.pull("wfh/langsmith-agent-prompt:798e7324")
import functools
from langchain.smith import (
arun_on_dataset,
run_on_dataset,
)
chain_results = run_on_dataset(
dataset_name=dataset_name,
llm_or_chain_factory=functools.partial(agent_factory, prompt=prompt),
evaluation=evaluation_config,
verbose=True,
client=client,
project_name=f"runnable-agent-test-5d466cbc-{unique_id}",
tags=[
"testing-notebook",
"prompt:5d466cbc",
], # Optional, adds a tag to the resulting chain runs
)
# Sometimes, the agent will error due to parsing issues, incompatible tool inputs, etc.
# These are logged as warnings here and captured as errors in the tracing UI.
View the evaluation results for project 'runnable-agent-test-5d466cbc-bf2162aa' at:
https://smith.langchain.com/o/ebbaf2eb-769b-4505-aca2-d11de10372a4/projects/p/0c3d22fa-f8b0-4608-b086-2187c18361a5
[> ] 0/5
Chain failed for example 54b4fce8-4492-409d-94af-708f51698b39 with inputs {'input': 'Who trained Llama-v2?'}
Error Type: TypeError, Message: DuckDuckGoSearchResults._run() got an unexpected keyword argument 'arg1'
[------------------------------------------------->] 5/5
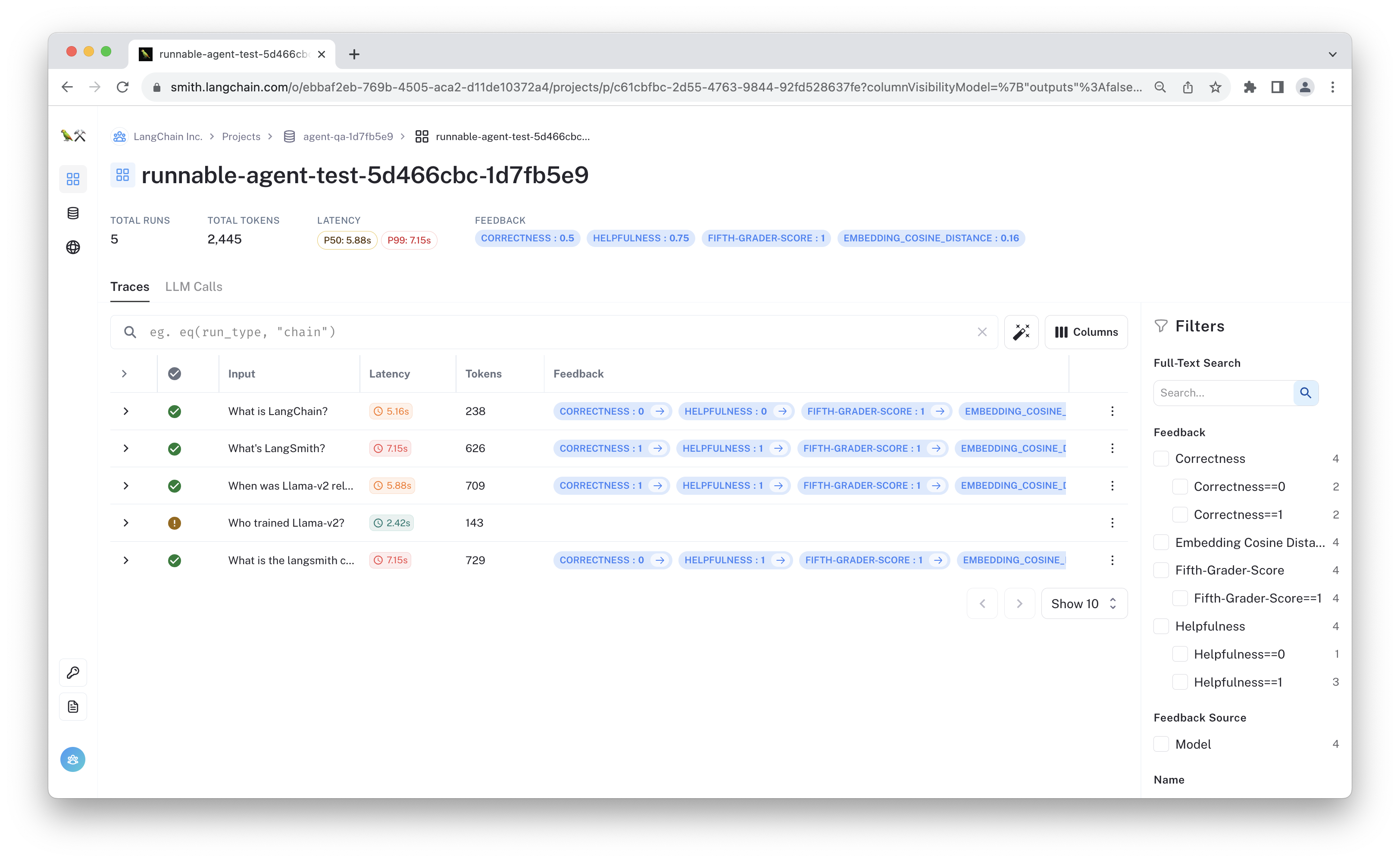
Eval quantiles:
0.25 0.5 0.75 mean mode
embedding_cosine_distance 0.086614 0.118841 0.183672 0.151444 0.050158
correctness 0.000000 0.500000 1.000000 0.500000 0.000000
score_string:accuracy 0.775000 1.000000 1.000000 0.775000 1.000000
helpfulness 0.750000 1.000000 1.000000 0.750000 1.000000
1.5 请查看测试结果
您可以通过点击上面输出中的URL或导航到LangSmith“agent-qa-{unique_id}”数据集中的“测试和数据集”页面来查看下面的测试结果跟踪UI。
2. 整合代码运行
Agents/chat_agents_search_evaluate.py这段代码使用 Langchain 和 LangSmith 库构建了一个复杂的问答系统,利用大型语言模型和其他工具(如 DuckDuckGo 搜索)来回答问题,并进行评估和测试。以下是对代码的详细解释和注释:
# 导入与 OpenAI 语言模型进行交互的模块。
from langchain.llms import OpenAI
# 导入创建和管理提示模板的模块。
from langchain.prompts import PromptTemplate
# 导入构建基于大型语言模型的处理链的模块。
from langchain.chains import LLMChain
# 导入从 .env 文件加载环境变量的库。
from dotenv import load_dotenv
# 导入创建和管理 OpenAI 聊天模型实例的类。
from langchain.chat_models import ChatOpenAI
# 加载 .env 文件中的环境变量。
load_dotenv()
# 设置环境变量,包括唯一项目 ID 和 Langchain API 设置。
import os
from uuid import uuid4
unique_id = uuid4().hex[0:8]
os.environ["LANGCHAIN_PROJECT"] = f"Tracing Walkthrough - {unique_id}"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGCHAIN_API_KEY"] = "ls__xxxx" # 替换为你的 API 密钥
# 初始化 LangSmith 客户端。
from langsmith import Client
client = Client()
# 导入 Langchain 的其他必要模块和工具。
from langchain import hub
from langchain.agents import AgentExecutor
from langchain.agents.format_scratchpad import format_to_openai_function_messages
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser
from langchain.tools import DuckDuckGoSearchResults
from langchain.tools.render import format_tool_to_openai_function
# 创建 ChatOpenAI 实例。
llm = ChatOpenAI(model="gpt-3.5-turbo-16k", temperature=0)
# 定义工具列表。
tools = [DuckDuckGoSearchResults(name="duck_duck_go")]
# 定义输入问题列表。
inputs = [
"What is LangChain?",
"What's LangSmith?",
"When was Llama-v2 released?",
"What is the langsmith cookbook?",
"When did langchain first announce the hub?",
]
# 创建数据集。
outputs = [
"LangChain is an open-source framework for building applications using large language models. It is also the name of the company building LangSmith.",
"LangSmith is a unified platform for debugging, testing, and monitoring language model applications and agents powered by LangChain",
"July 18, 2023",
"The langsmith cookbook is a github repository containing detailed examples of how to use LangSmith to debug, evaluate, and monitor large language model-powered applications.",
"September 5, 2023",
]
dataset_name = f"agent-qa-{unique_id}"
dataset = client.create_dataset(
dataset_name,
description="An example dataset of questions over the LangSmith documentation.",
)
# 为每个问题创建数据集示例。
for query, answer in zip(inputs, outputs):
client.create_example(
inputs={"input": query}, outputs={"output": answer}, dataset_id=dataset.id
)
# 导入并使用 Langchain 和 LangSmith 的评估模块。
from langchain.evaluation import EvaluatorType
from langchain.smith import RunEvalConfig
from langchain import hub
from langchain.agents import AgentExecutor, AgentType, initialize_agent, load_tools
from langchain.agents.format_scratchpad import format_to_openai_function_messages
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser
from langchain.chat_models import ChatOpenAI
from langchain.tools.render import format_tool_to_openai_function
from langchain.smith import arun_on_dataset, run_on_dataset
# Since chains can be stateful (e.g. they can have memory), we provide
# a way to initialize a new chain for each row in the dataset. This is done
# by passing in a factory function that returns a new chain for each row.
def agent_factory(prompt):
llm_with_tools = llm.bind(
functions=[format_tool_to_openai_function(t) for t in tools]
)
runnable_agent = (
{
"input": lambda x: x["input"],
"agent_scratchpad": lambda x: format_to_openai_function_messages(
x["intermediate_steps"]
),
}
| prompt
| llm_with_tools
| OpenAIFunctionsAgentOutputParser()
)
return AgentExecutor(agent=runnable_agent, tools=tools, handle_parsing_errors=True)
# 设置评估配置。
from langchain.evaluation import EvaluatorType
from langchain.smith import RunEvalConfig
evaluation_config = RunEvalConfig(
# Evaluators can either be an evaluator type (e.g., "qa", "criteria", "embedding_distance", etc.) or a configuration for that evaluator
evaluators=[
# Measures whether a QA response is "Correct", based on a reference answer
# You can also select via the raw string "qa"
EvaluatorType.QA,
# Measure the embedding distance between the output and the reference answer
# Equivalent to: EvalConfig.EmbeddingDistance(embeddings=OpenAIEmbeddings())
EvaluatorType.EMBEDDING_DISTANCE,
# Grade whether the output satisfies the stated criteria.
# You can select a default one such as "helpfulness" or provide your own.
RunEvalConfig.LabeledCriteria("helpfulness"),
# The LabeledScoreString evaluator outputs a score on a scale from 1-10.
# You can use default criteria or write our own rubric
RunEvalConfig.LabeledScoreString(
{
"accuracy": """
Score 1: The answer is completely unrelated to the reference.
Score 3: The answer has minor relevance but does not align with the reference.
Score 5: The answer has moderate relevance but contains inaccuracies.
Score 7: The answer aligns with the reference but has minor errors or omissions.
Score 10: The answer is completely accurate and aligns perfectly with the reference."""
},
normalize_by=10,
),
],
# You can add custom StringEvaluator or RunEvaluator objects here as well, which will automatically be
# applied to each prediction. Check out the docs for examples.
custom_evaluators=[],
)
from langchain import hub
# 从 Langchain Hub 拉取最新版本的提示。
prompt = hub.pull("wfh/langsmith-agent-prompt:798e7324")
print(prompt)
import functools
# 定义代理工厂函数。
from langchain import hub
from langchain.agents import AgentExecutor, AgentType, initialize_agent, load_tools
from langchain.agents.format_scratchpad import format_to_openai_function_messages
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser
from langchain.chat_models import ChatOpenAI
from langchain.tools.render import format_tool_to_openai_function
from langchain.smith import (
arun_on_dataset,
run_on_dataset,
)
chain_results = run_on_dataset(
dataset_name=dataset_name,
llm_or_chain_factory=functools.partial(agent_factory, prompt=prompt),
evaluation=evaluation_config,
verbose=True,
client=client,
project_name=f"runnable-agent-test-5d466cbc-{unique_id}",
tags=[
"testing-notebook",
"prompt:5d466cbc",
], # Optional, adds a tag to the resulting chain runs
)
# 打印链运行结果。
print(chain_results)
输出结果:

看来访问OpenAI受限制很大,需要突破一下。。
$ python Agents/chat_agents_search_evaluate.py
input_variables=['agent_scratchpad', 'input'] input_types={'agent_scratchpad': typing.List[typing.Union[langchain.schema.messages.AIMessage, langchain.schema.messages.HumanMessage, langchain.schema.messages.ChatMessage, langchain.schema.messages.SystemMessage, langchain.schema.messages.FunctionMessage, langchain.schema.messages.ToolMessage]]} messages=[SystemMessagePromptTemplate(prompt=PromptTemplate(input_variables=[], template='You are an expert senior software engineer. You are responsible for answering questions about LangChain. Use functions to consult the documentation before answering.')), HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=['input'], template='{input}')), MessagesPlaceholder(variable_name='agent_scratchpad')]
View the evaluation results for project 'runnable-agent-test-5d466cbc-3c42290b' at:
https://smith.langchain.com/o/1441af63-d5a4-549b-893f-4f8d06c24390/projects/p/e685bf56-6fe9-4af3-af5c-3f7b6d674dcd?eval=true
View all tests for Dataset agent-qa-3c42290b at:
https://smith.langchain.com/o/1441af63-d5a4-549b-893f-4f8d06c24390/datasets/b4423fd6-5d73-4029-a9f2-a4d4afbd27dd
[---------> ] 1/5Chain failed for example b2bbbc7e-41f7-409f-a566-4afc01f9f1a5 with inputs {'input': 'When did langchain first announce the hub?'}
Error Type: RateLimitError, Message: Rate limit reached for gpt-3.5-turbo-16k in organization org-jkd8QtrppR9UcAr9C841gy2b on requests per min (RPM): Limit 3, Used 3, Requested 1. Please try again in 20s. Visit https://platform.openai.com/account/rate-limits to learn more. You can increase your rate limit by adding a payment method to your account at https://platform.openai.com/account/billing.
[-------------------> ] 2/5Chain failed for example 6bb422a3-27f4-4d59-a87d-1287e0820597 with inputs {'input': 'What is the langsmith cookbook?'}
Error Type: RateLimitError, Message: Rate limit reached for gpt-3.5-turbo-16k in organization
[---------------------------------------> ] 4/5Chain failed for example a4bc6b3e-b757-425e-91e5-76f46ee27ade with inputs {'input': 'When was Llama-v2 released?'}
Error Type: RateLimitError, Message: Rate limit reached for gpt-3.5-turbo-16k in organization
[------------------------------------------------->] 5/5Chain failed for example 41dd48e4-6193-4e1d-afe2-d0e5f678f280 with inputs {'input': "What's LangSmith?"}
Error Type: RateLimitError, Message: Rate limit reached for gpt-3.5-turbo-16k in organization
Eval quantiles:
0.25 0.5 0.75 mean mode
execution_time 15.619272 15.619272 15.619272 15.619272 15.619272
correctness NaN NaN NaN NaN NaN
score_string:accuracy NaN NaN NaN NaN NaN
helpfulness NaN NaN NaN NaN NaN
embedding_cosine_distance 0.092627 0.092627 0.092627 0.092627 0.092627
{'project_name': 'runnable-agent-test-5d466cbc-3c42290b', 'results': {'b2bbbc7e-41f7-409f-a566-4afc01f9f1a5': {'output': {'Error': "RateLimitError"}, 'input': {'input': 'When did langchain first announce the hub?'}, 'feedback': [], 'execution_time': 15.619272, 'reference': {'output': 'September 5, 2023'}}, '6bb422a3-27f4-4d59-a87d-1287e0820597': {'output': {'Error': "RateLimitError"}, 'input': {'input': 'What is the langsmith cookbook?'}, 'feedback': [], 'execution_time': 15.619272, 'reference': {'output': 'The langsmith cookbook is a github repository containing detailed examples of how to use LangSmith to debug, evaluate, and monitor large language model-powered applications.'}}, 'a4bc6b3e-b757-425e-91e5-76f46ee27ade': {'output': {'Error': "RateLimitError"}, 'input': {'input': 'When was Llama-v2 released?'}, 'feedback': [], 'execution_time': 15.619272, 'reference': {'output': 'July 18, 2023'}}, '41dd48e4-6193-4e1d-afe2-d0e5f678f280': {'output': {'Error': "RateLimitError"}, 'input': {'input': "What's LangSmith?"}, 'feedback': [], 'execution_time': 15.619272, 'reference': {'output': 'LangSmith is a unified platform for debugging, testing, and monitoring language model applications and agents powered by LangChain'}}, 'e2912900-dc5c-4b2b-bae7-2867ef761edd': {'output': {'input': 'What is LangChain?', 'output': 'LangChain is a blockchain-based platform that aims to bridge the language barrier by providing translation and interpretation services. It utilizes smart contracts and a decentralized network of translators to facilitate secure and efficient language translation. LangChain aims to revolutionize the language industry by providing a transparent and reliable platform for language services.'}, 'input': {'input': 'What is LangChain?'}, 'feedback': [EvaluationResult(key='correctness', score=None, value=None, comment='Error evaluating run 6b9e0ca1-3bd4-4d15-8816-3c34ca4b4f04: The model `gpt-4` does not exist or you do not have access to it. Learn more: https://help.openai.com/en/articles/7102672-how-can-i-access-gpt-4.', correction=None, evaluator_info={}, source_run_id=None, target_run_id=None), EvaluationResult(key='score_string:accuracy', score=None, value=None, comment='Error evaluating run 6b9e0ca1-3bd4-4d15-8816-3c34ca4b4f04: The model `gpt-4` does not exist or you do not have access to it. Learn more: https://help.openai.com/en/articles/7102672-how-can-i-access-gpt-4.', correction=None, evaluator_info={}, source_run_id=None, target_run_id=None), EvaluationResult(key='helpfulness', score=None, value=None, comment='Error evaluating run 6b9e0ca1-3bd4-4d15-8816-3c34ca4b4f04: The model `gpt-4` does not exist or you do not have access to it. Learn more: https://help.openai.com/en/articles/7102672-how-can-i-access-gpt-4.', correction=None, evaluator_info={}, source_run_id=None, target_run_id=None), EvaluationResult(key='embedding_cosine_distance', score=0.09262746580850112, value=None, comment=None, correction=None, evaluator_info={'__run': RunInfo(run_id=UUID('2e07f133-983b-452d-a5be-e2323ac3bd42'))}, source_run_id=None, target_run_id=None)], 'execution_time': 15.619272, 'reference': {'output': 'LangChain is an open-source framework for building applications using large language models. It is also the name of the company building LangSmith.'}}}}
代码
https://github.com/zgpeace/pets-name-langchain/tree/develop
参考
- https://python.langchain.com/docs/langsmith/walkthrough
- https://docs.smith.langchain.com/