40 mysql join 的实现
前言
join 是一个我们经常会使用到的一个 用法
我们这里 看一看各个场景下面的 join 的相关处理
测试数据表如下, 两张测试表, tz_test, tz_test03, 表结构 一致
CREATE TABLE `tz_test` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`field1` varchar(128) DEFAULT NULL,
`field2` varchar(128) DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
UNIQUE KEY `field_1_2` (`field1`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8
CREATE TABLE `tz_test_03` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`field1` varchar(128) DEFAULT NULL,
`field2` varchar(128) DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
UNIQUE KEY `field_1_2` (`field1`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8
tz_test 数据如下
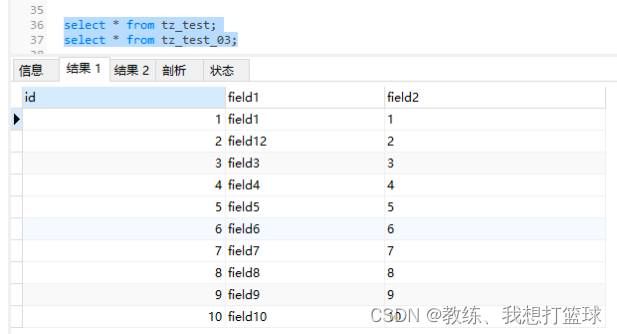
tz_test_03 数据如下
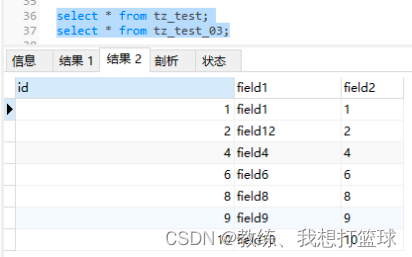
join条件基于主键
执行 sql 如下 ”select * from tz_test as t1 inner join tz_test_03 as t2 on t1.id = t2.id where 1 = 1”
sql 预处理的时候, 遍历各个 数据表, tz_test, tz_test_03, 将所有的字段列 merge 成为 all_fields, 传递个 qeb_tab->all_fields
这里是在迭代 tz_test, tz_test_03 的字段列表信息, 将其添加到 field_list
tz_test 的情况如下
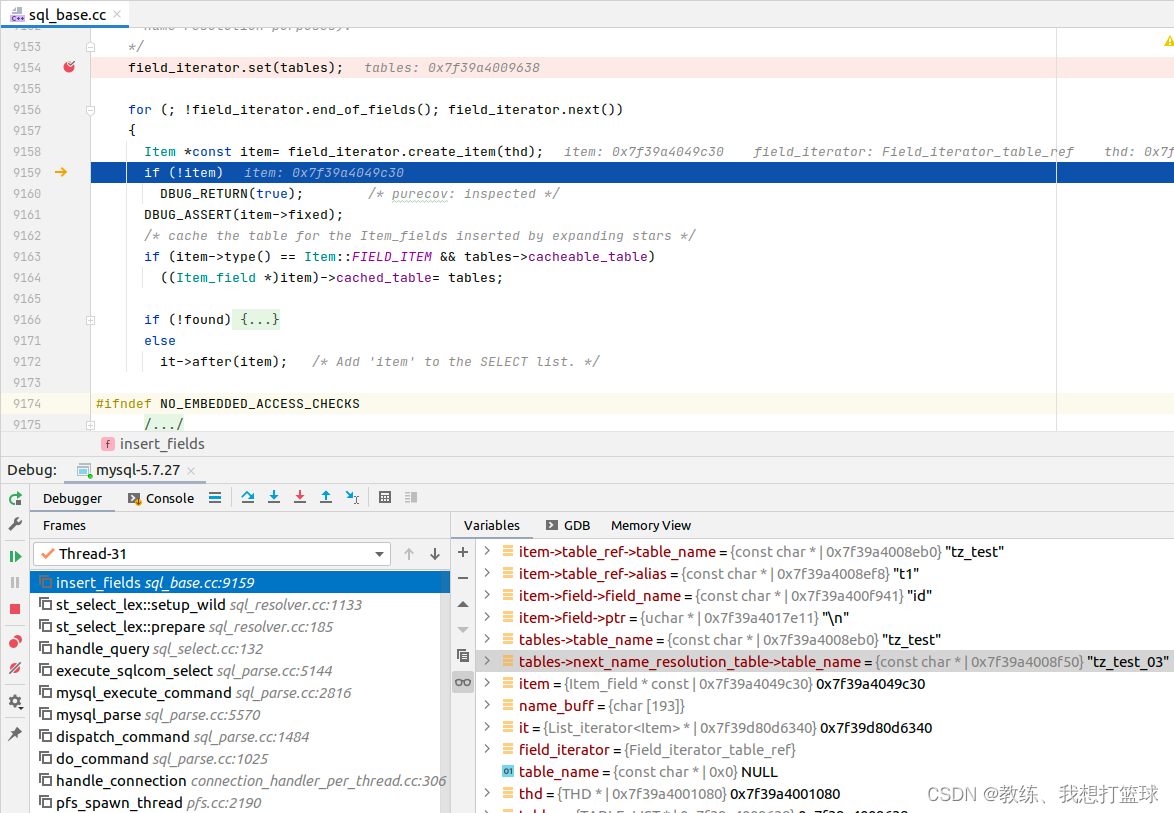
tz_test_03 的情况如下
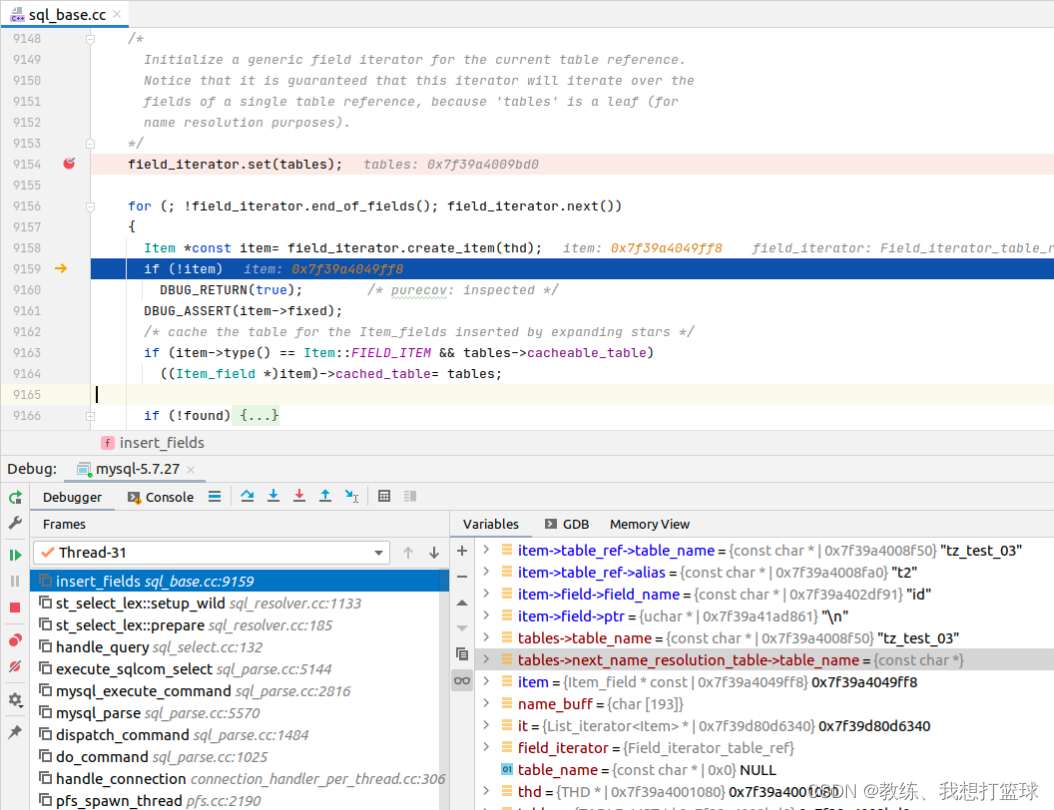
然后 field_list 传到后面的 JOIN
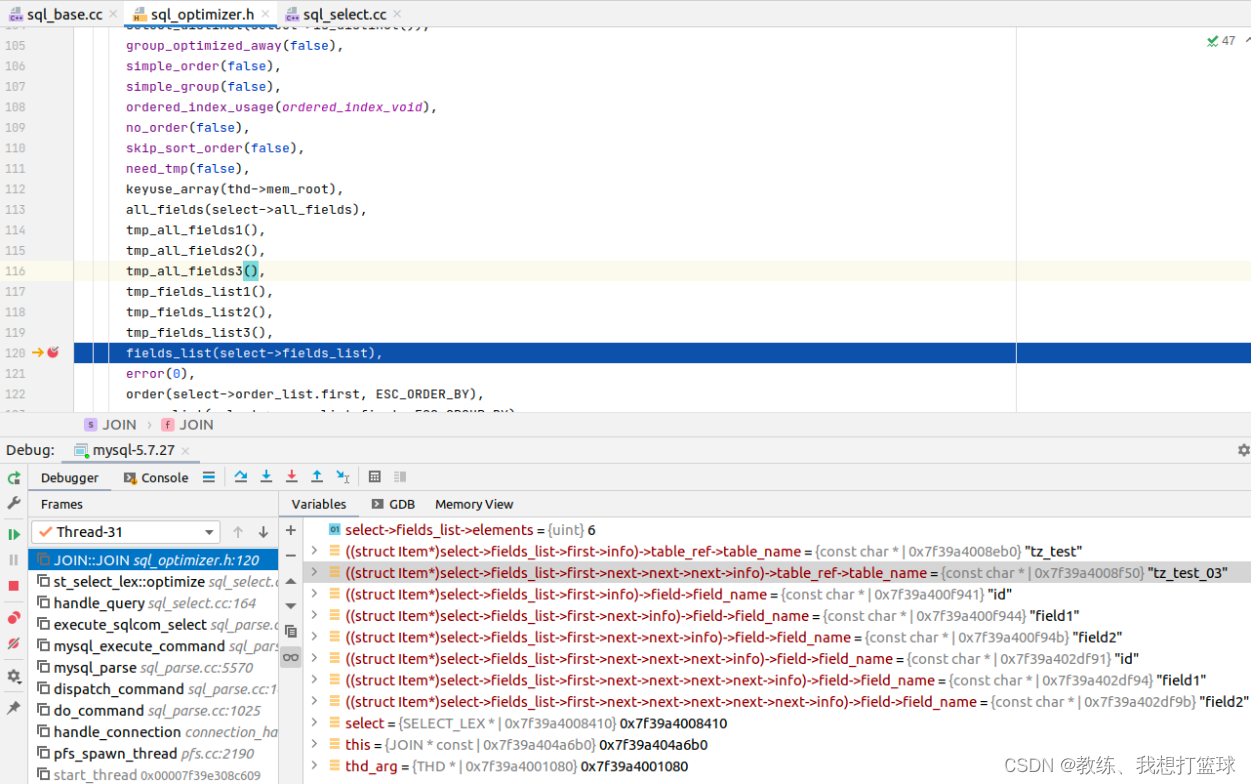
具体的 join 的实现
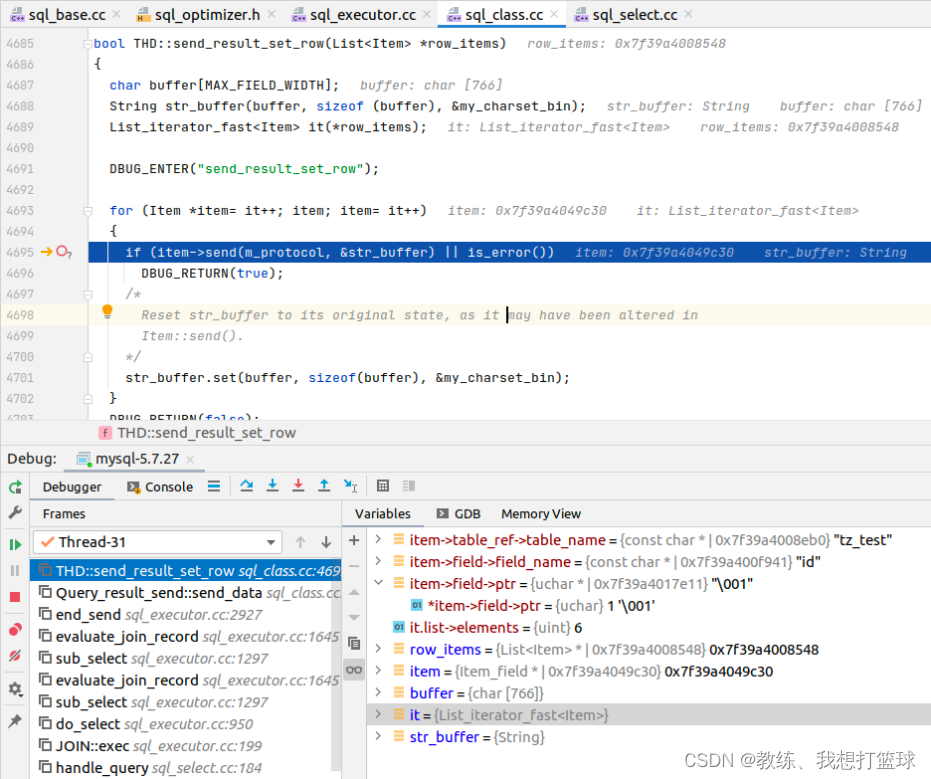
外层循环, 基于主驱动表的循环, 这里是基于 普通的查询, 根据 主键索引, 普通索引, 全表扫描 去遍历记录, 可以看到 主驱动表 是 tz_test_03
这里填充的是 tz_test_03 的 field_list, 对应于 qep_tab->fields 中的 [3-5] 项
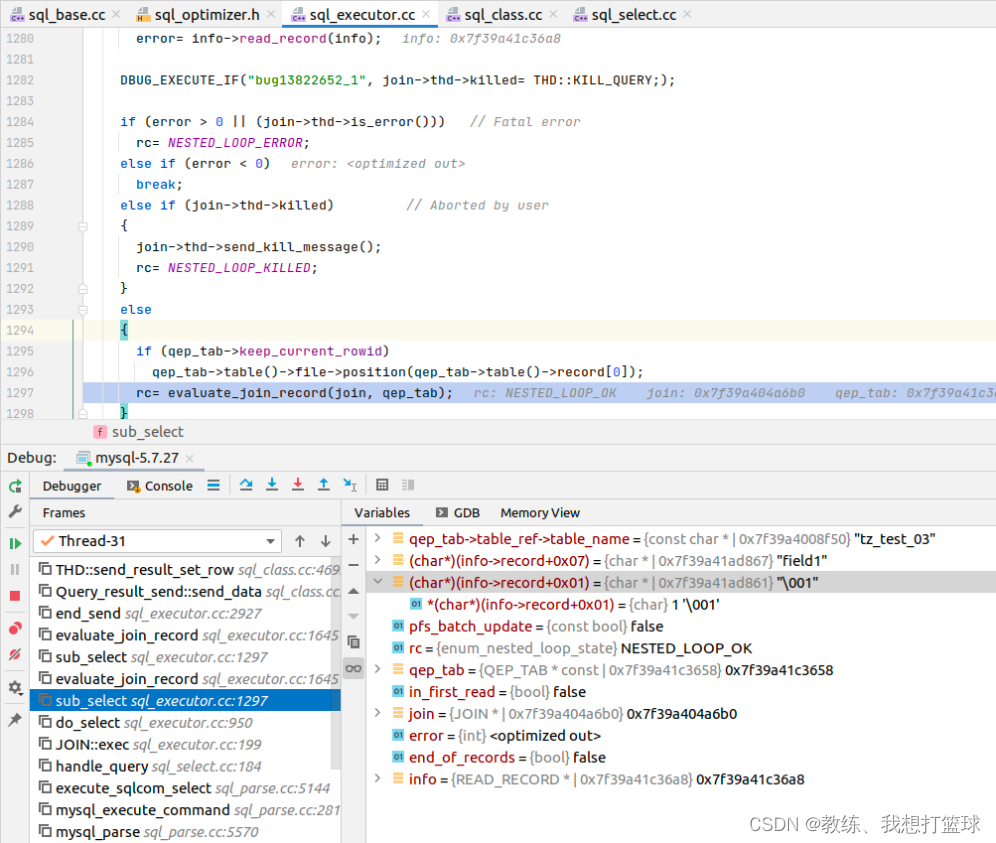
内层的循环是基于 外层的循环条件 来限定的查询, 假设 tz_test_03 拿到的记录为 "{"id":1, "field1":"field1", "field2":"2"}"
然后内层的循环的查询就是 "select * from tz_test where id = 1"
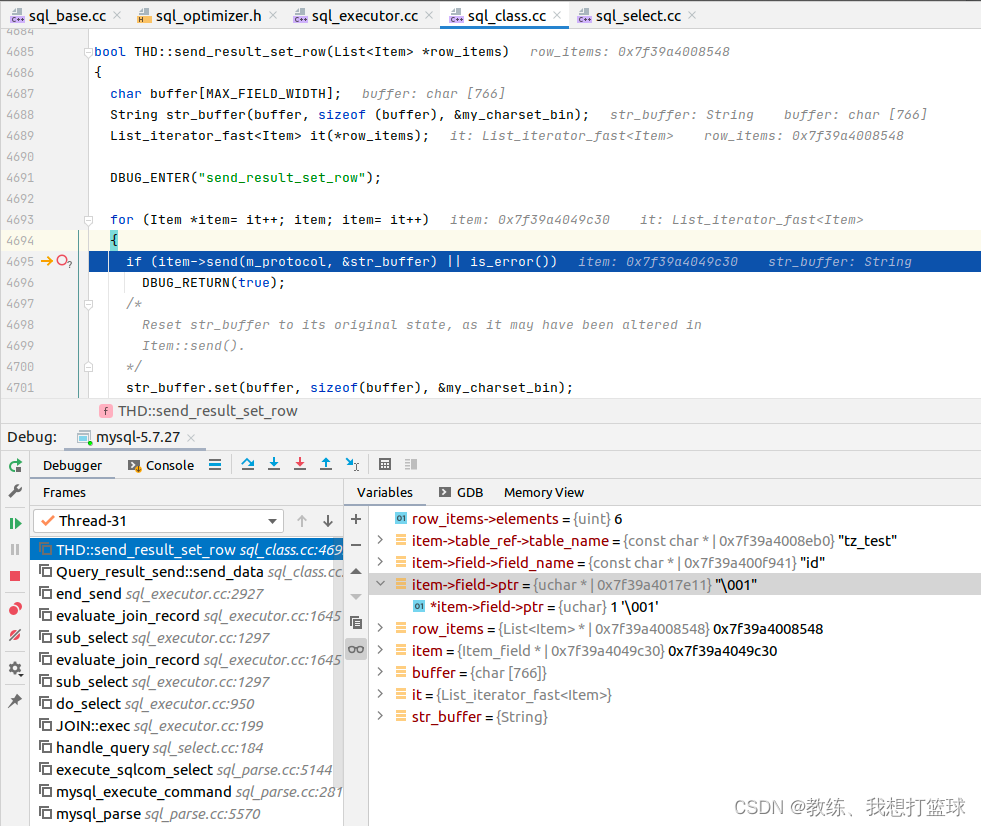
这里填充的是 tz_test 的 field_list, 对应于 qep_tab->fields 中的 [0-2] 项
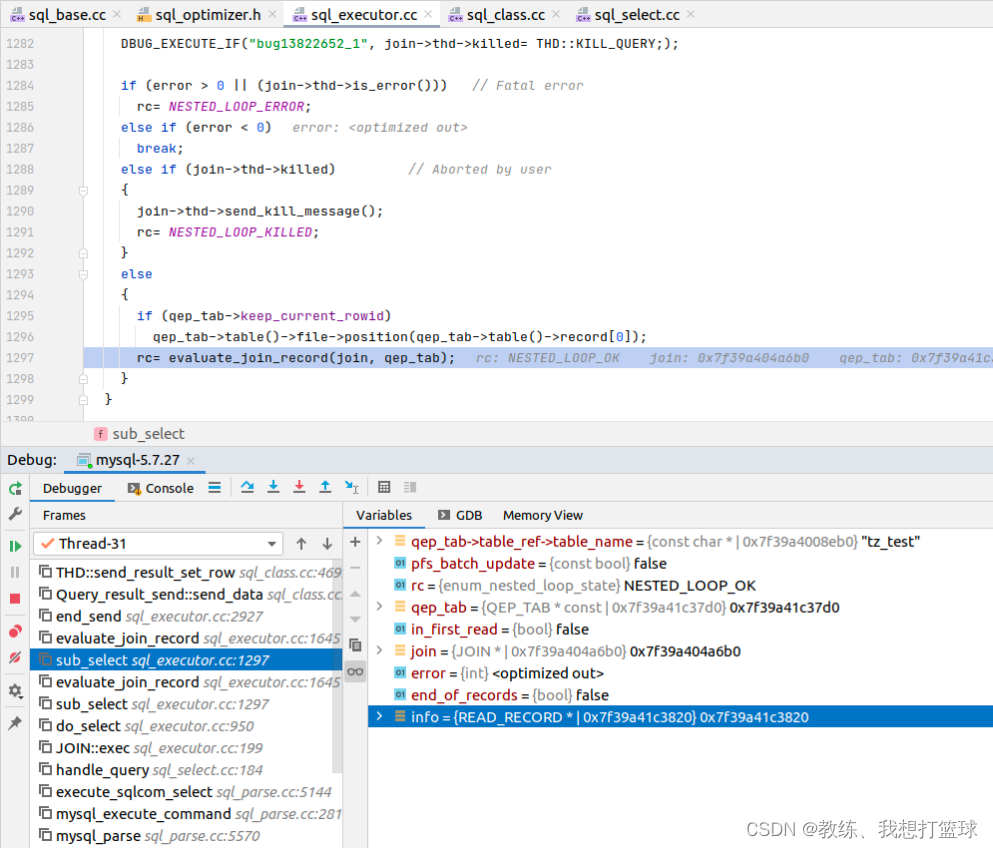
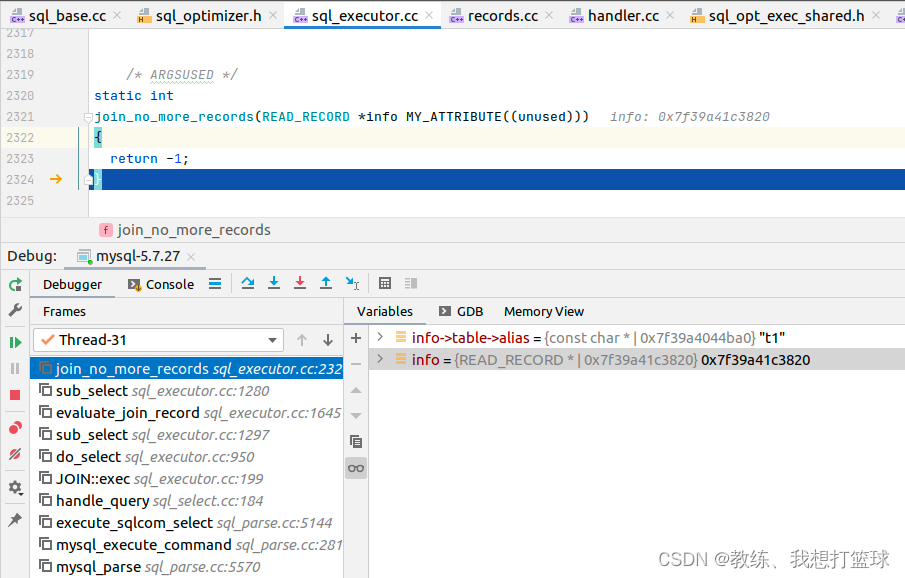
因为是主键关联查询, 因此 info->read_record 是 join_no_more_records, qup_tab->reqd_first_record 会查询出 内层循环需要关联的 tz_test 中的记录
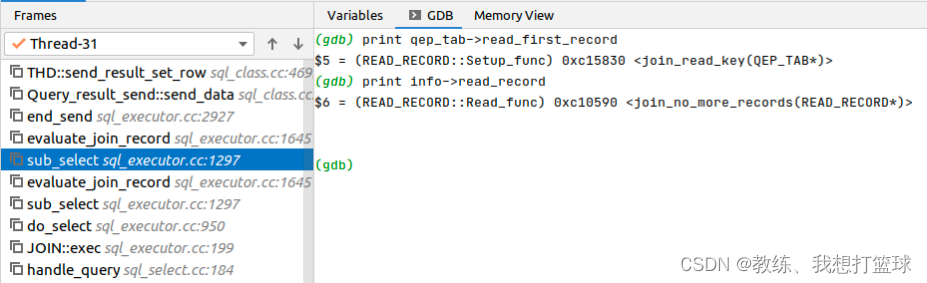
然后上面 外层循环填充了 qep_tab->fields 中的 [0-2] 项
然后上面 内层循环填充了 qep_tab->fields 中的 [3-5] 项
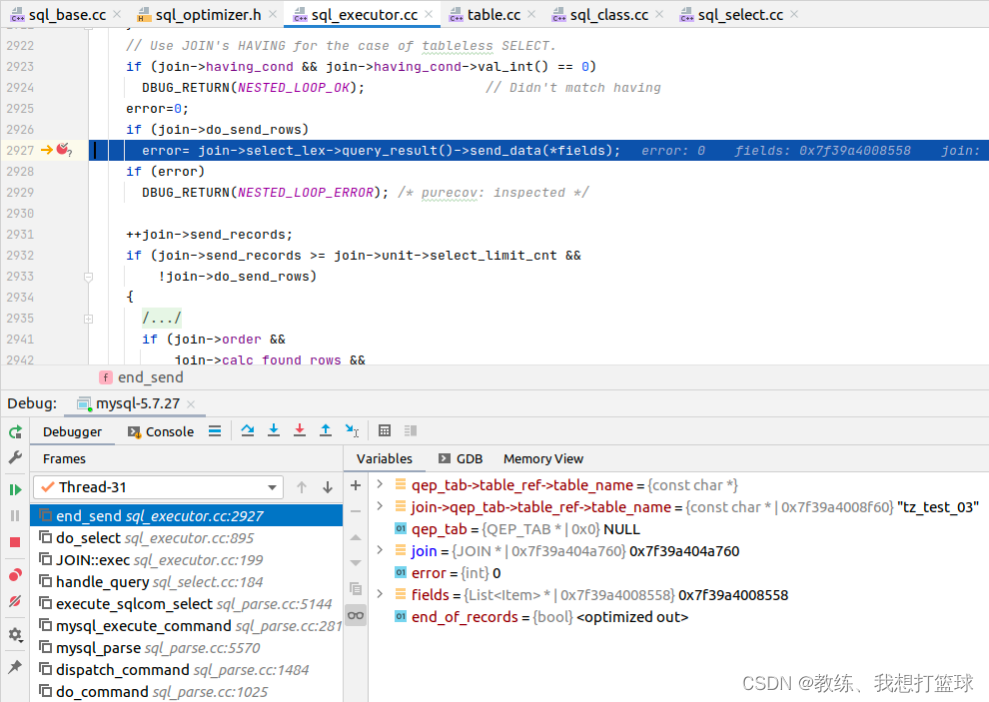
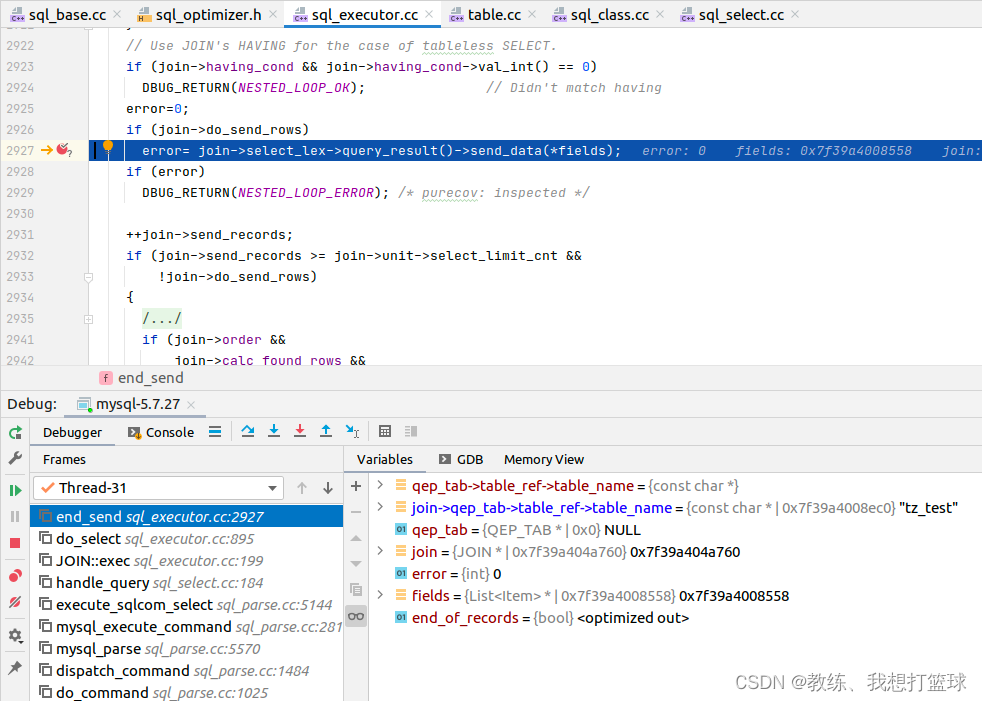
这里就是输出 qep_tab->fields 中的数据到客户端, 即为所求
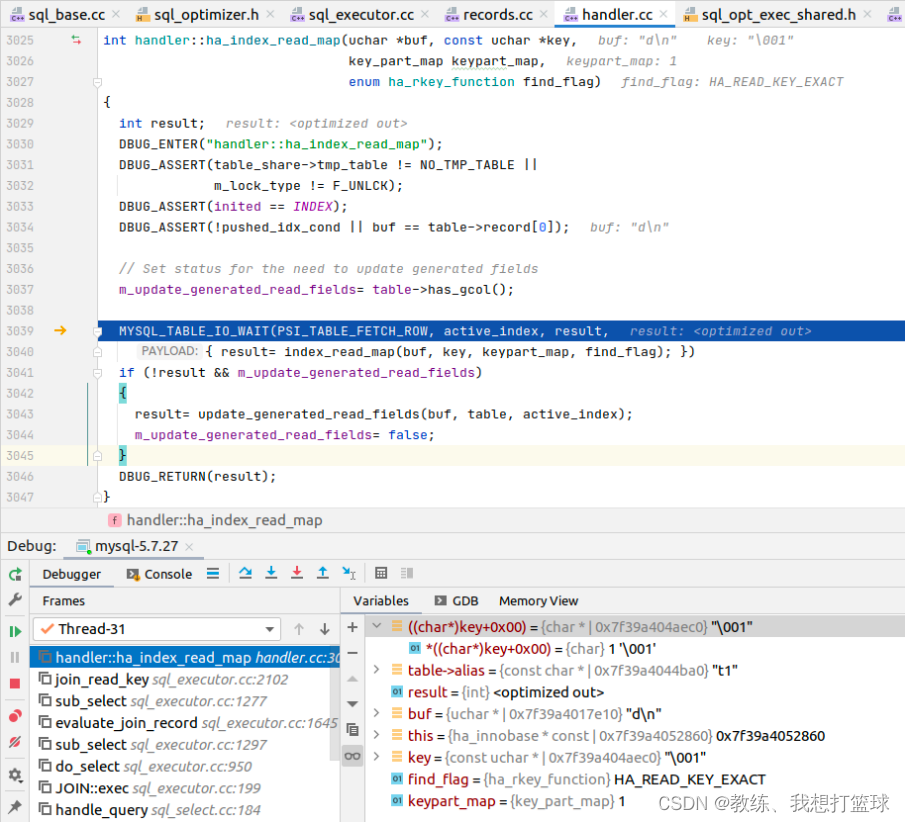
内层循环首次迭代基于 join_read_key 函数
内层循环后续迭代基于 join_no_more_records 函数, 是直接响应 跳出 sub_select 循环
主驱动表的选择规则
选择的是 符合条件记录较少的表 作为主驱动表
假设执行 sql 如下, 按照上述规则推导 会选择 tz_test_03 作为主驱动表
select * from tz_test as t1
inner join tz_test_03 as t2 on t1.field1 = t2.field1
where t2.id = 2;
确实如此, 选择了 tz_test_03 作为主驱动表
假设执行 sql 如下, 按照上述规则推导 会选择 tz_test 作为主驱动表
select * from tz_test as t1
inner join tz_test_03 as t2 on t1.field1 = t2.field1
where t1.id = 2;
确实如此, 选择了 tz_test 作为主驱动表
join条件基于索引
执行 sql 如下 ”select * from tz_test as t1 inner join tz_test_03 as t2 on t1.field1 = t2.field1 where 1 = 1”
基于 field1 作为 join 条件处理类似
只是, 这边 内层循环迭代的时候, 可能迭代多条记录, 这边是通过 内层循环表 的 field1 的索引进行迭代的
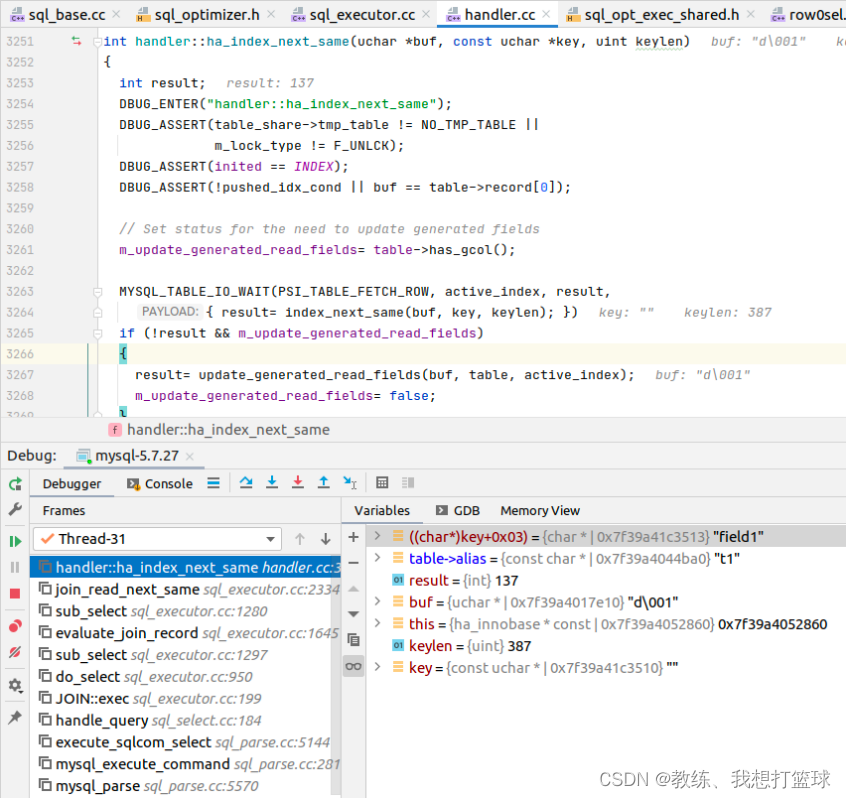
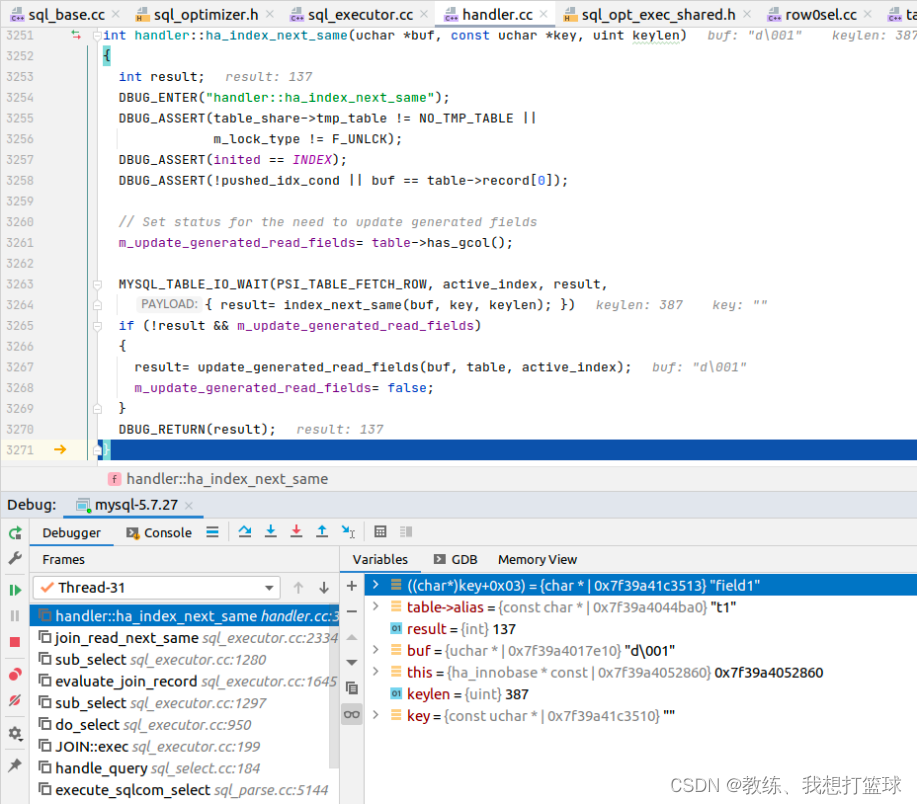
内层循环首次迭代基于 join_read_always_key 函数

内层循环后续迭代基于 ha_index_next_same 函数
join条件基于普通字段
执行 sql 如下 ”select * from tz_test as t1 inner join tz_test_03 as t2 on t1.field2 = t2.field2 where 1 = 1”
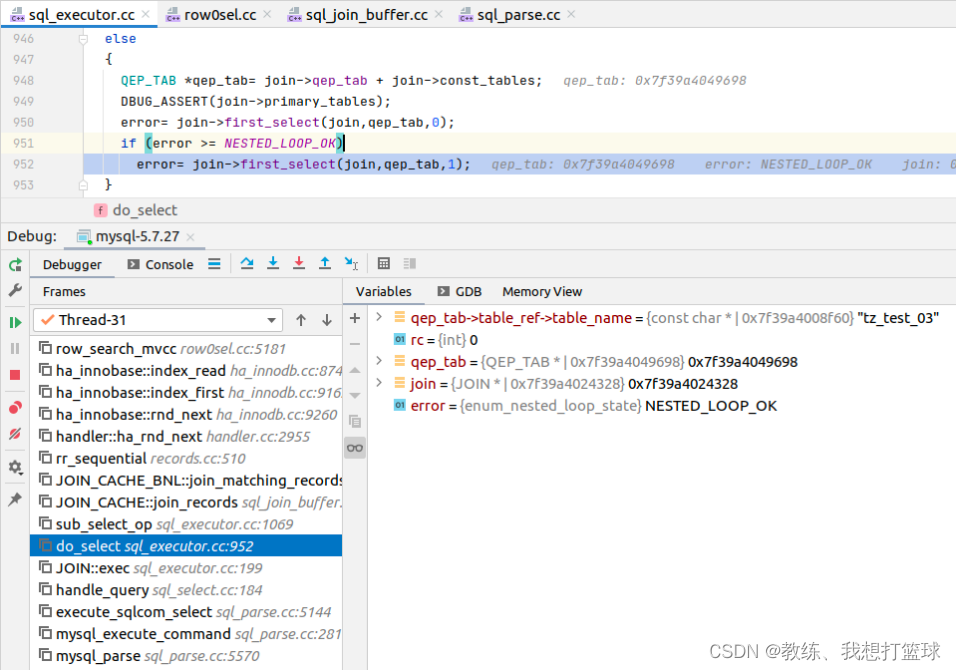
外层循环为 第一个 join->first_select, 走的普通的 sub_select 的流程, 基于 qep_tab->read_first_record 和 info->read_record 进行迭代
迭代的过程中会将数据 放到 join_buffer, 主驱动表是 tz_test_03
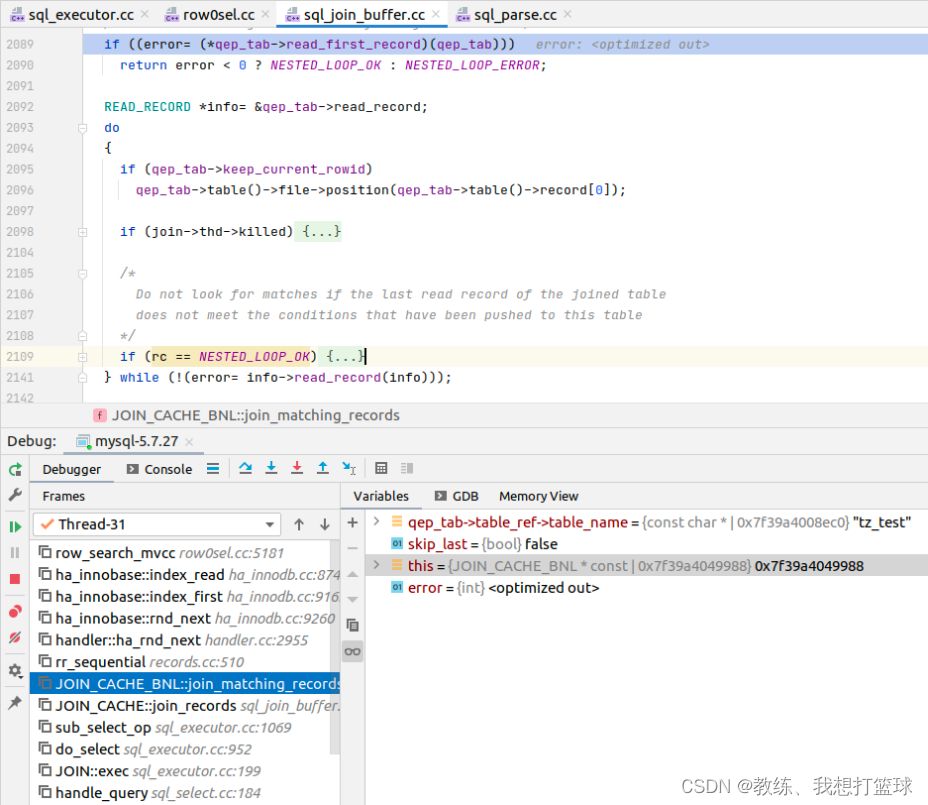
基于 field2 作为 join 条件处理类似
只是, 这里是基于 qep_tab->read_first_record 和 info->read_record 进行迭代, 然后 比较的是 join_buffer 中的 tz_test_03 表的数据
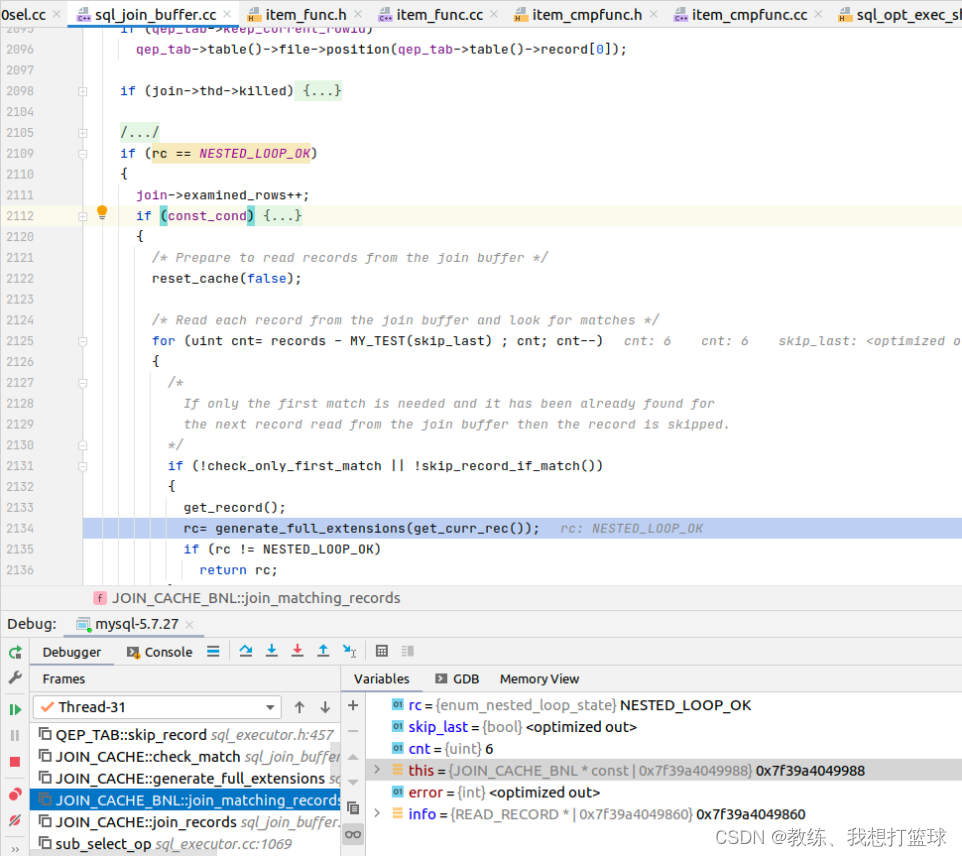
两层循环的比较处理是在这里, 这里 外层 while 遍历的是 tz_test 表的所有数据
for 中遍历的是 join_buffer 中的数据, 这里对应的是 tz_test_03 表中的所有数据
然后 generate_full_extensions 中去做的是否符合 join 的条件, 以及输出 数据到客户端
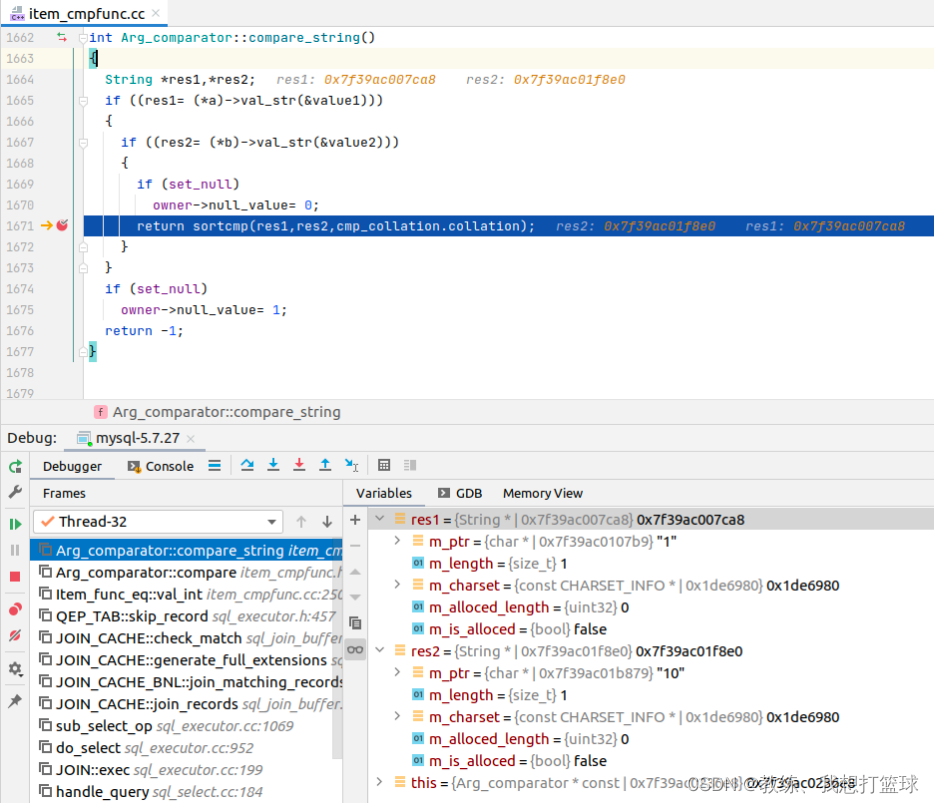
比如这里比较的是 tz_test 的第一条记录的 field2, 值为 “1”
和 join_buffer 中 tz_test_03 的第一条记录的 field2, 值为 “1”, 比较成功
比如这里比较的是 tz_test 的第一条记录的 field2, 值为 “1”
和 join_buffer 中 tz_test_03 的第一条记录的 field2, 值为 “2”, 比较不成功
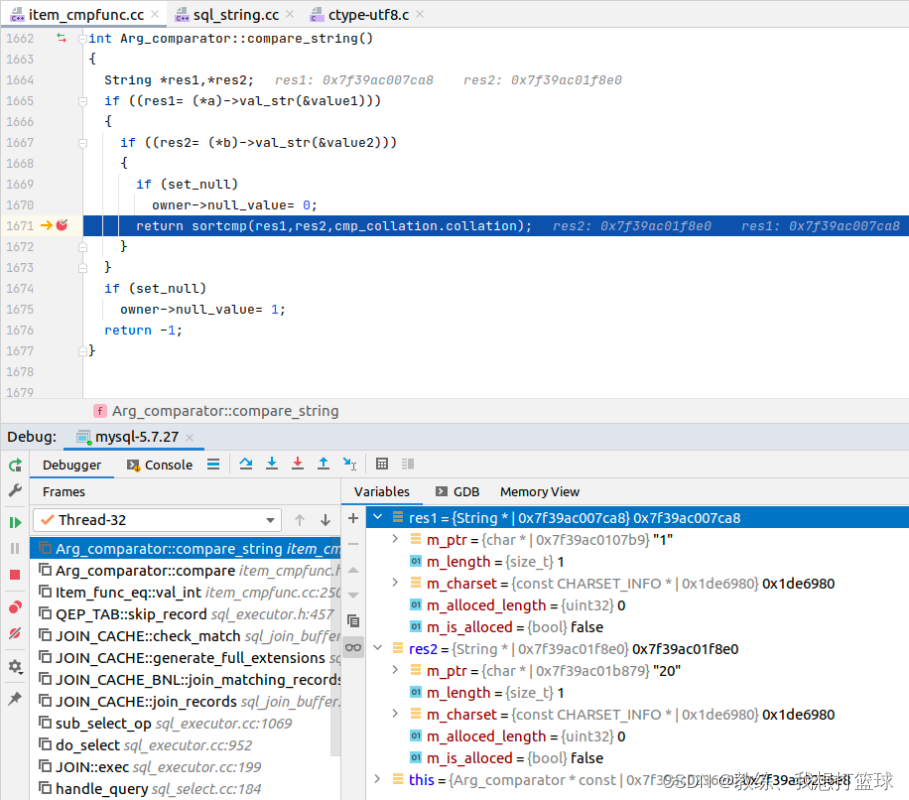
比较成功之后, 向客户端输出结果信息
比较不成功, 迭代 下一条记录
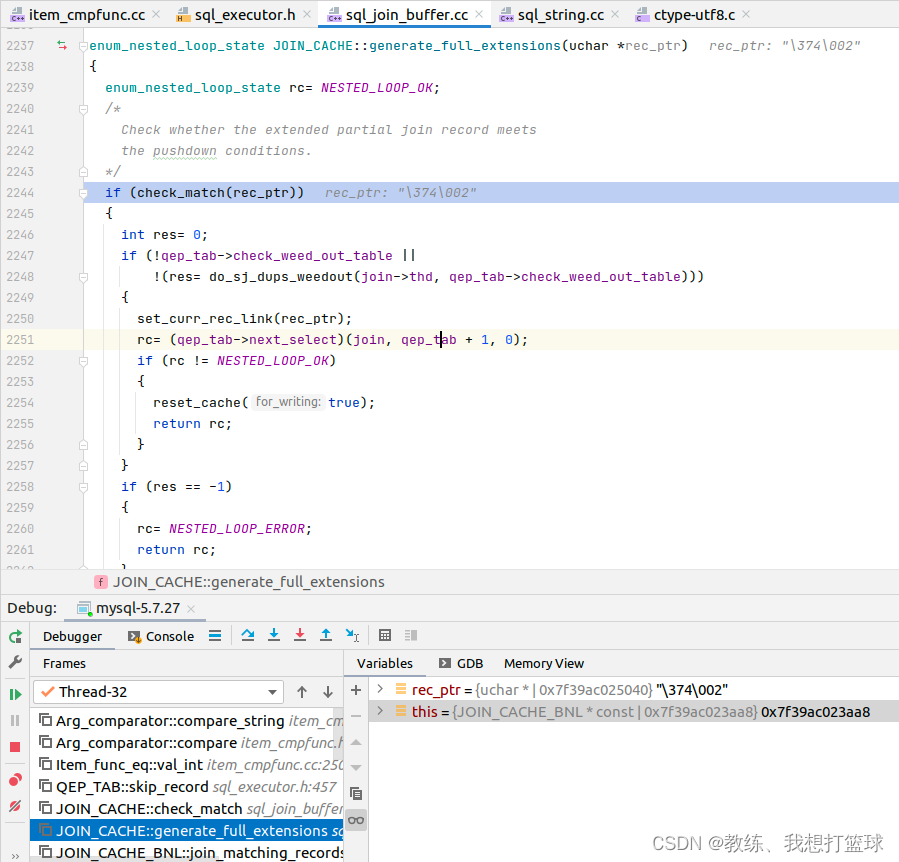
join_buffer 和 fields 的数据是如何关联上的?
tz_test 中的数据, JOIN_CACHE_BNL::join_matching_records 的迭代中依次将记录信息填充到 qep_tab->read_record 中, 其实就是填充到 all_fields[0-2]
然后 我们看一下 join_buffer 和 fields 的数据是如何关联上的?
初始化的时候 我们看一下各个 fields 的信息
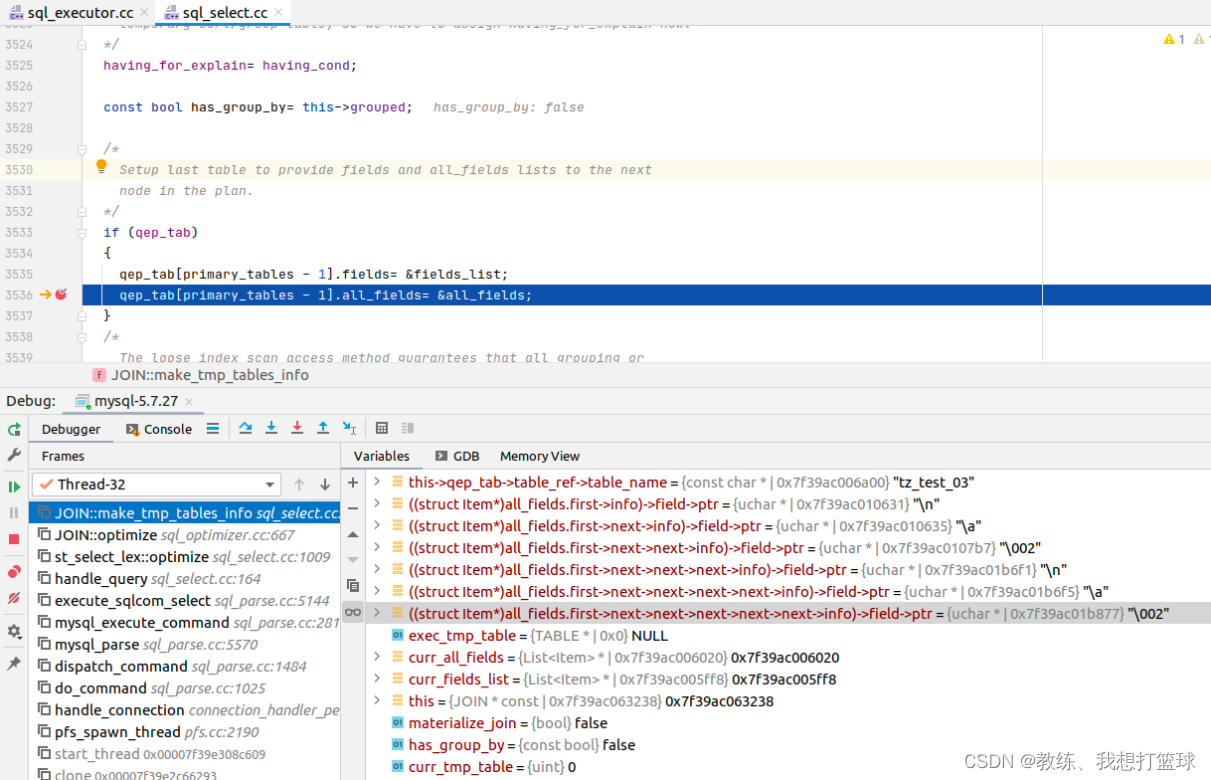
向客户端输出结果信息的时候 各个 fields 的信息如下, 可以看到 和 初始化的时候是一致的, 是属于各个 Table 下面的各个 Field, buf 使用的是 table->record[0]
因此 上面 join_buffer 处理的时候讲数据记录填充到了 all_fields[3-5]

join_buffer 中 field_descr 和 Table 中的 Field 关联是在 join_buffer 初始化的地方
(*fld_ptr)->fill_cache_field 中会初始化 CACHE_FIELD 的 ptr, length, field 等等信息
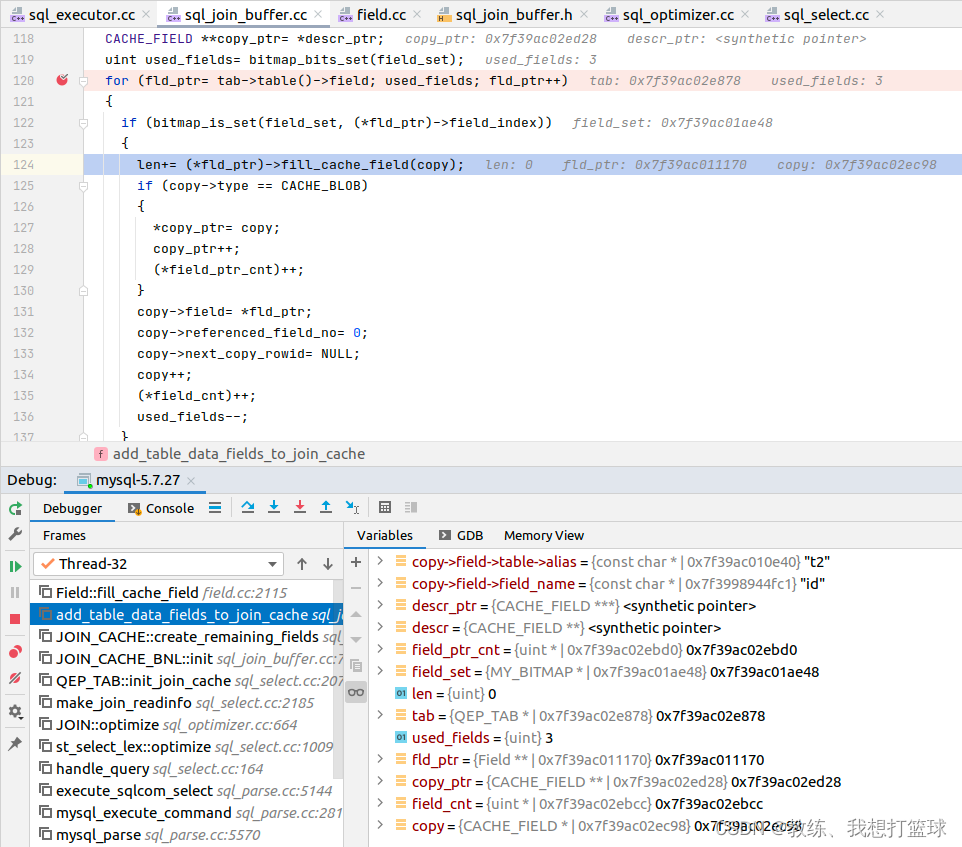
拷贝的地方如下, pos 为当前 join_buffer 读取到的位置, 读取之后 id 值为 2, field1 值为 ”field12”, field2 值为 2
这里会将 join_buffer 中的数据读取到 CACHE_FIELD 的各个列中, 对应的就是 Table 中的各个 Field, 也等价于填充到了 all_fields[3-5]
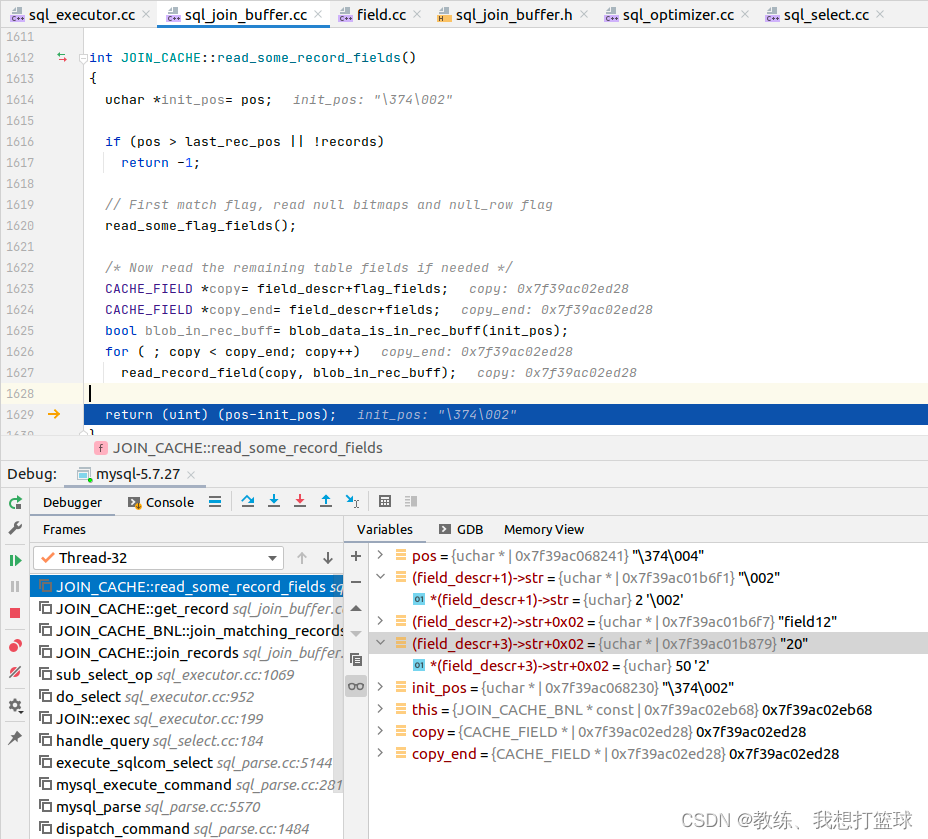
其内容如下, 内容拆解如下, 主要是 四个部分, 这里对应的是记录 “{"id":"2", "field1":"field12", "field2":"2"}”
然后 紧接着是 id 为 4 的这一条记录, 再接着是 id 为 6 这条记录
主驱动表的数据填充到 join_buffer 的地方在哪里?
主驱动表查询的每一条记录 都是直接往 join_buffer 中放
这里显示的 qep_tab->table_ref->table_name 为 tz_test, 但是实际上查询的表示 tz_test_03

大数据表join条件基于主键是否有优化?
构造 大表如下
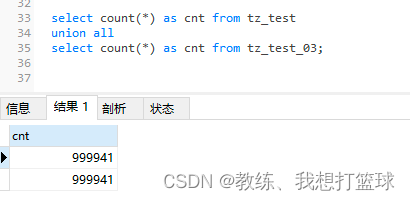
执行 sql 如下 “select * from tz_test as t1
inner join tz_test_03 as t2 on t1.id = t2.id
where 1 = 1;”
可以看到的是 查询实现是一样的, 主驱动表为的 tz_test_03, 然后 内层循环表为 tz_test
完