MySQL性能调优-2-实际优化案例
目录
SQL优化原则
案例一:千万级用户的运营查询优化-去掉半连接
案例二:亿级商品按类别/子类别查询的SQL优化-force index强制走某索引
案例三:十亿级评论表单商品几十万评论的深分页问题-优先主键全表扫描
案例四:千万级数据删除导致的慢查询-减少长事务
案例五:跨库查询如何优化
案例六:订单量少的商户才出现慢查询
SQL优化原则
1)不要让查询优化器为难
比如不要在索引列上加函数,因为对索引值加了函数后,值发生了变化,但是没有是存储了函数计算过后的值的,所以这个场景不会命中场景
查询2023年某一个月的全部订单,有些同学就可能会考虑使用Year+Month等函数,导致索引失效,所以,应该直接传入参数取startDate为这个月的第一天,endDate为下个月第一天,这样可以走一个range
不要使用转换大小写的函数,而应该使用忽略大小写的关键字
2)尽量缩短寻址路程,也就是尽量减少回表,合理使用联合索引
3)尽量减少IO:比如一次sql查询100w数据就是一个大IO,应该分批查询
其实很多时候,关系型数据库解决能力是有限的,所以,才出现了大数据技术,典型的用空间换时间,用分布式计算来解决数据处理的问题
关于SQL优化的思路,一般都是使用执行计划看看是否用到了索引,主要可能有两大类情况:
对业务字段建立了二级联合索引,但是MySQL错误地觉得走主键聚族索引全表扫描效率更高,而没有走二级索引
走二级索引,但是引起了几万、几十万的回表,此时还不如利用聚簇索引进行正序或者倒序的全表扫描,配合limit n,全表扫描只需要扫到符合条件的n条就停止
案例一:千万级用户的运营查询优化-去掉半连接




案例二:亿级商品按类别/子类别查询的SQL优化-force index强制走某索引



也就是说这里的问题,
其实如果就算MySQL判断走错了索引,但是,因为只limit 10,如果能在全表扫描的过程中很快的就找到了满足条件的10条元素,那么就能很快的截断执行流程并直接返回,从而避免对整张表一扫到底,结果还没有凑齐满足条件的10条元素
案例三:十亿级评论表单商品几十万评论的深分页问题-优先主键全表扫描




案例四:千万级数据删除导致的慢查询-减少长事务



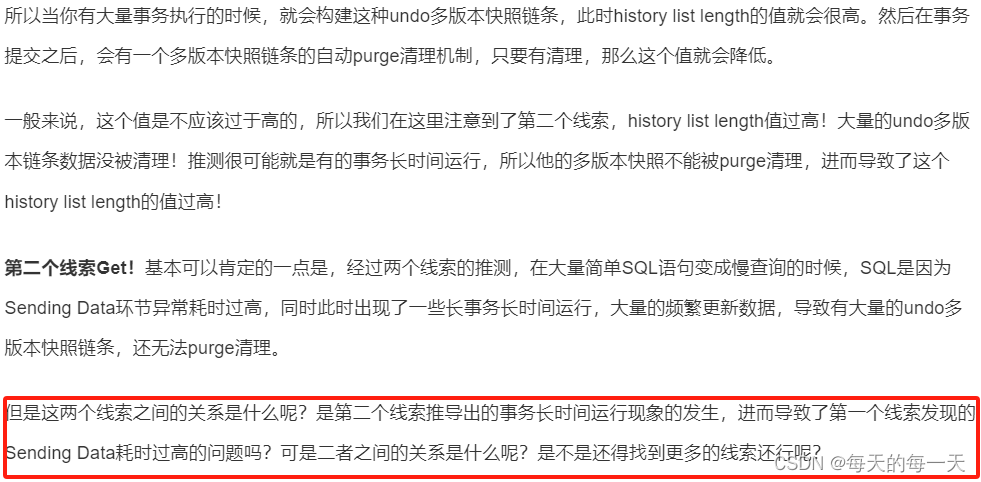



上面就是核心问题,就是每条数据都要去undo log中往前追溯,找属于自己能看到的版本对应的数据,一条两条可能速度不影响,如果上千万的数据都是这种,那么就影响很大了

案例五:跨库查询如何优化


案例六:订单量少的商户才出现慢查询
查询十月份某商户所有成功的订单,并取前10条

命中了十月份的时间索引数据有2300w条,并且这2300w的时间索引中没有商户id这个字段,就需要回表
如果该商户id下的订单非常多,那么在命中了十月份的时间索引里面,就很容易就查到了10条符合条件的数据,然后查询流程就截止并直接返回了

解决方法
- 直接去掉走强制索引,mysql就有很大的概率走merchant_id索引,而merchant_id是一个基数很大的索引字段,区分度很大
- 把时间和商户id做一个联合索引,时间如果是必选的,那么把时间放首位(但是,如果已有数据超过几千万上亿,重建联合索引耗费时间肯定巨大,所以优先考虑方法一)