应用层自定义协议
文章目录
- 一、前言
- 二、应用层自定义协议
- 三、通用协议格式
- 3.1 xml
- 3.2 josn
- 3.3 protobuffer
后端开发必须掌握的知识点!
一、前言
应用层主要是干嘛的呢??
应用层协议定义了应用程序之间通信的规则和标准。定义了数据的格式、数据交换的标准和接口规范。
应用层协议包括:HTTP/HTTPS、FTP、SMTP 等。本篇暂时不介绍这些应用层协议。
二、应用层自定义协议
应用层自带的协议有很多,但也有很多时候,是需要程序员自己定义协议。
假如,外卖现在打开某个外卖软件,显示的是商家列表,每一个商家都包含了很多信息,包括:商家的名称、商家图片、好评率、距离你的位置、评分等…
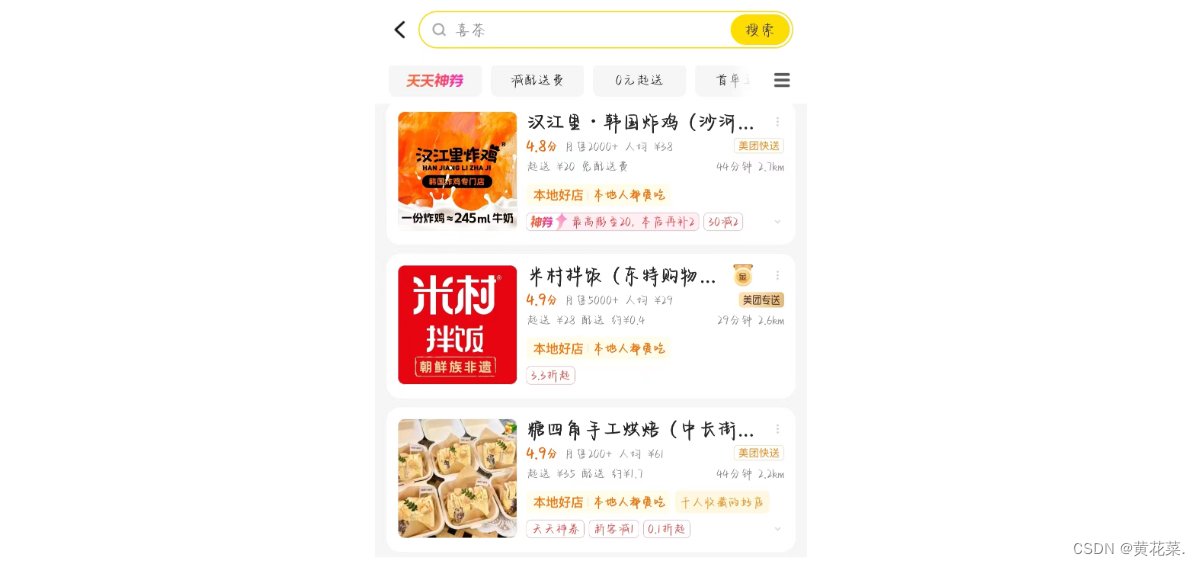
这些信息都是通过网络,从服务器获取的。客户端,需要给服务器发起一个请求,服务器收到请求之后,就给客户端返回一个响应。
外卖软件和服务器之间的沟通,有很多种方式。展示商家列表,只是其中一个。因此,在开发设计这个程序的时候,就需要提前做好规划。(这里的设计是非常灵活的,最主要的是要有一个固定的标准)
现做出如下设计:
-
先明确当前请求和响应中包含那些信息(根据需求来)
请求:用户身份、用户当前位置
响应:商家名称、商家图片、月售、距离你的位置、评分……
-
明确具体的请求和响应的格式
所谓的“明确格式"就是看你按照啥样的方式,构造出一个字符串后续这个字符串就可以作为tcp 或者udp 的 payload进行传输,具体例子如下:
-
示例一:
请求:1234,80 100 //1234为用户身份,80 100为用户当前位置
响应:韩国炸鸡,1.jpg,2000,2.7km,4.8 \n
米村拌饭,2.jpg,5000,2.6km,4.9 \n
唐四角手工烘焙,3.jpg,200,2.2km,4.9 \n
-
示例二:
请求:80,100;1234
响应:韩国炸鸡;1.jpg;2000;2.7km;4.8 !米村拌饭;2.jpg;5000;2.6km;4.9 !唐四角手工烘焙;3.jpg;200,2.2km;4.9! //使用!分割每个商家。商家的每个信息使用;来分割
-
示例三:
请求:

响应:

上述方式,就可以看到,请求和响应,具体的数据组织形式,是非常灵活的。程序猿想怎么组织都行!!只需要保证客户端和服务器这边使用的是相同的规则即可!!
-
三、通用协议格式
虽然我们说,自定义的协议格式,是可以任意的。但是为了避免出现过于天马行空的设计。有些大佬就搞出了一些"通用的协议格式",参考这些格式,就可以对咱们的协议设计产生重要的指导作用。
3.1 xml
是以成对的标签,来表示“键值对”信息,同时标签支持嵌套,就可以构成一些更复杂的树形结构数据。
对象,本质上也是键值对。属性的名字就是键,属性的值就是值。
请求:
<requset>
<userId> 1234 </userId>
<position> 100 80 </position>
</requset>
响应:
<response>
<shops>
<shop>
<name> 韩国炸鸡 </name>
<image> 1.jpg </image>
<distance> 2.7km </distance>
<sale> 5000 </sale>
<star> 4.8 </star>
</shop>
<shop>
<name> 米村拌饭 </name>
<image> 2.jpg </image>
<distance> 2.6km </distance>
<sale> 2000 </sale>
<star> 4.9 </star>
</shop>
</shops>
</response>
优点: xml 非常清晰的把结构化数据表示出来了。
缺点: 表示数据需要引入大量的标签,看起来繁琐,同时也会占用不少的网络带宽。
国内,最贵的硬件资源,就是网络带宽。
3.2 josn
最流行的一种数据组织格式,本质上也是键值对,看起来,比 xml 要干净不少。
json 对于换行并不敏感,如果这些内容全都放在同一行,也是完全合法的。
一般网络传输的时候,会对json进行压缩(去掉不必要的换行和空格),同时把所有数据都放到一行去。整体占用的带宽就更降低了。(影响到可读性)
请求:
{
userId: 1234
position:"100 80"
}
响应:
[
{
name:'韩国炸鸡'
iamge:'1.jpg'
distance:'2.7km'
sale:5000
star:4.8
},
{
name:'米村拌饭'
image:'2.jpg'
distance:'2.6km'
sale:2000
star:4.9
}
]
优势: 相比于xml,表示的数据简洁很多,可读性非常好的。方便程序猿观察中间结果,方便调试问题。
劣势: 终究是需要花费一定的带宽来传输 key 的名字的。
3.3 protobuffer
谷歌提出的一套,二进制的数据序列化方式。
使用二进制的方式,约定某几个字节,表示哪个属性…最大程度的节省空间(不必传输key,根据位置和长度,区分每个属性)
这个主要用于,对于性能要求更高的场景。牺牲了开发效率,换来运行效率。(对于一个程序来说开发效率更重要一点)
优点: 节省带宽,最大化效率。
缺点: 二进制数据,无法肉眼直接观察,不方便调试。使用起来比较复杂。需要专门编写一个 proto 文件,描述数据的格式是咋样的。开发效率低。
除了上述的这三种之外,还存在很多其他的序列化方式(数据组织格式) ,Java标准库就提供了方式。其他的第三方库,提供的方式更丰富了。
像 HTTP 这样的协议,后面会出一篇博客来专门讨论。