【深度学习】Adversarial Diffusion Distillation,SDXL-Turbo 一步出图
代码:
https://huggingface.co/stabilityai/sdxl-turbo
使用
SDXL-Turbo 是SDXL 1.0的精炼版本,经过实时合成训练。SDXL-Turbo 基于一种称为对抗扩散蒸馏 (ADD) 的新颖训练方法(请参阅技术报告),该方法允许在高图像质量下以 1 到 4 个步骤对大规模基础图像扩散模型进行采样。这种方法使用分数蒸馏来利用大规模现成的图像扩散模型作为教师信号,并将其与对抗性损失相结合,以确保即使在一个或两个采样步骤的低步骤状态下也能确保高图像保真度。
pip install diffusers transformers accelerate --upgrade
文本到图像:
SDXL-Turbo 不使用guidance_scale或negative_prompt,我们使用 禁用它guidance_scale=0.0。优选地,模型生成尺寸为 512x512 的图像,但更高的图像尺寸也可以。只需一个步骤就足以生成高质量的图像。
from diffusers import AutoPipelineForText2Image
import torch
pipe = AutoPipelineForText2Image.from_pretrained("stabilityai/sdxl-turbo", torch_dtype=torch.float16, variant="fp16")
pipe.to("cuda")
prompt = "A cinematic shot of a baby racoon wearing an intricate italian priest robe."
image = pipe(prompt=prompt, num_inference_steps=1, guidance_scale=0.0).images[0]
图像到图像:
当使用 SDXL-Turbo 进行图像到图像生成时,请确保num_inference_steps*strength大于或等于 1。图像到图像管道将运行多个int(num_inference_steps * strength)步骤,例如,在下面的示例中,0.5 * 2.0 = 1 个步骤。
from diffusers import AutoPipelineForImage2Image
from diffusers.utils import load_image
pipe = AutoPipelineForImage2Image.from_pretrained("stabilityai/sdxl-turbo", torch_dtype=torch.float16, variant="fp16")
init_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/cat.png").resize((512, 512))
prompt = "cat wizard, gandalf, lord of the rings, detailed, fantasy, cute, adorable, Pixar, Disney, 8k"
image = pipe(prompt, image=init_image, num_inference_steps=2, strength=0.5, guidance_scale=0.0).images[0]
论文
https://stability.ai/research/adversarial-diffusion-distillation
摘要
我们引入了对抗性扩散蒸馏(Adversarial Diffusion Distillation,简称ADD),这是一种新颖的训练方法,能够在仅1-4步内高效采样大规模基础图像扩散模型,同时保持高图像质量。我们利用分数蒸馏来利用大规模现成的图像扩散模型作为教师信号,结合对抗损失以确保在一两个采样步骤的低阶段仍保持高图像保真度。我们的分析表明,我们的模型在单步中明显优于现有的少步方法(GANs、潜在一致性模型),并在仅四步中达到了最先进的扩散模型(SDXL)的性能水平。ADD是第一种能够解锁基础模型的单步、实时图像合成方法。
- 引言
扩散模型(DMs)[20, 63, 65]在生成建模领域发挥了核心作用,最近在高质量图像[3, 53, 54]和视频[4, 12, 21]合成方面取得了显著进展。DMs的关键优势之一是其可扩展性和迭代性质,使其能够处理诸如从自由文本提示中合成图像等复杂任务。然而,DMs中的迭代推理过程需要大量采样步骤,这目前阻碍了其实时应用。生成对抗网络(GANs)[14, 26, 27]则以其单步公式和固有速度为特点。但是,尽管尝试扩展到大型数据集[25, 58],GANs在样本质量方面通常不及DMs。本工作的目标是将DMs的卓越样本质量与GANs的固有速度结合起来。
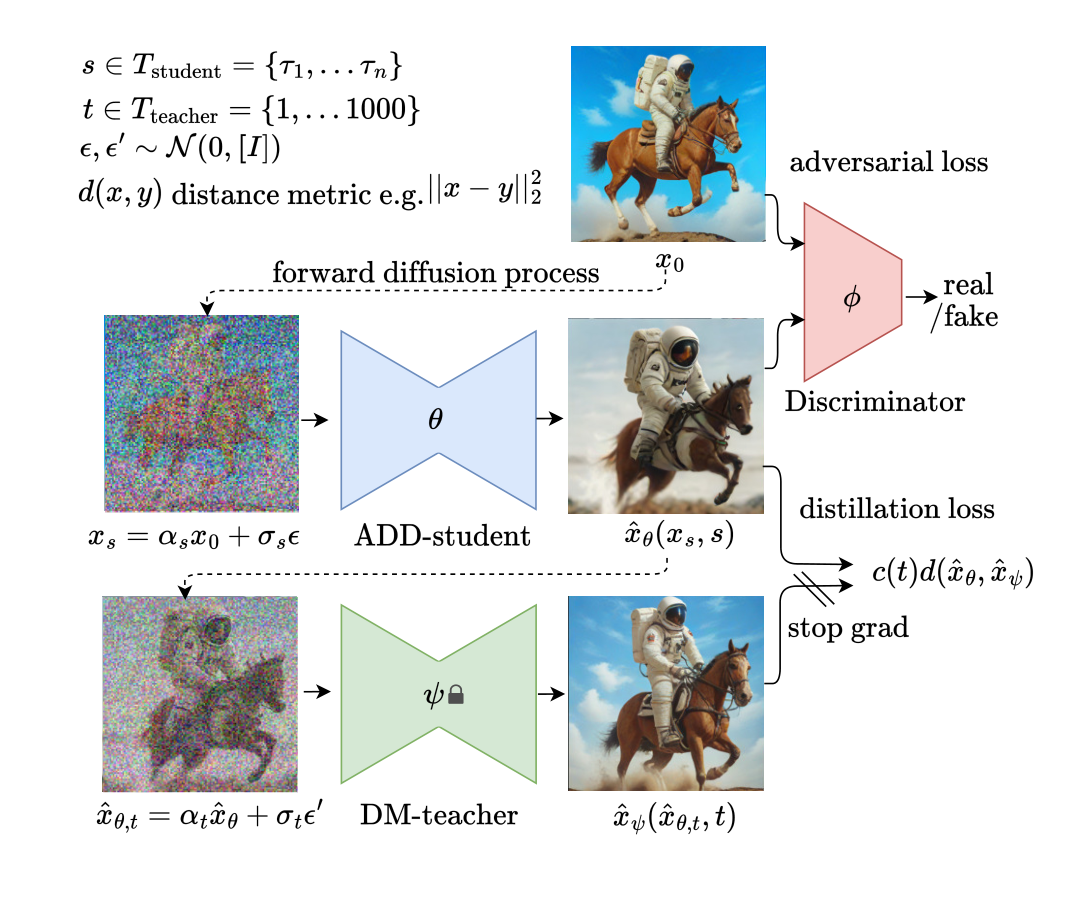
我们的方法在概念上很简单:我们提出了对抗性扩散蒸馏(Adversarial Diffusion Distillation,简称ADD),这是一种通用方法,将预训练扩散模型的推理步骤减少到1-4个采样步骤,同时保持高采样保真度,可能进一步提高模型的整体性能。为此,我们引入了两个训练目标的组合:(i)对抗性损失和(ii)对应于分数蒸馏采样(SDS)[51]的蒸馏损失。对抗性损失迫使模型在每次前向传递中直接生成位于真实图像流形上的样本,避免了在其他蒸馏方法[43]中通常观察到的模糊和其他伪像。蒸馏损失使用另一个预训练(且固定的)DM作为教师,以有效利用预训练DM的丰富知识,并保留大型DM中观察到的强组合性。在推理过程中,我们的方法不使用无分类器引导[19],进一步减少了内存需求。我们保留了模型通过迭代细化改进结果的能力,这是相对于先前的单步GAN-based方法[59]的优势。
我们的贡献可以总结如下:
- 我们引入了ADD,一种将预训练扩散模型转化为高保真度、实时图像生成器的方法,仅使用1-4个采样步骤。
- 我们的方法使用对抗训练和分数蒸馏的新颖组合,我们仔细分析了几个设计选择。
- ADD在很大程度上优于LCM、LCM-XL [38]和单步GANs [59]等强基线,并且能够处理复杂的图像组合,同时在仅一个推理步骤中保持高图像逼真度。
- 使用四个采样步骤,ADD-XL在分辨率为5122 px时优于其教师模型SDXL-Base。
- 背景
虽然扩散模型在合成和编辑高分辨率图像[3, 53, 54]和视频[4, 21]方面取得了显著的性能,但它们的迭代性质阻碍了实时应用。潜在扩散模型[54]尝试通过在一个计算上可行的潜在空间中表示图像来解决这个问题[11],但它们仍然依赖于具有数十亿参数的大型模型的迭代应用。除了利用扩散模型的更快采样器[8, 37, 64, 74]之外,还有越来越多关于模型蒸馏的研究,如渐进蒸馏[56]和引导蒸馏[43]。这些方法将迭代采样步骤减少到4-8步,但可能显著降低原始性能。此外,它们需要迭代的训练过程。一致性模型[66]通过对ODE轨迹强制执行一致性正则化解决了后者问题,并在少样本设置中对基于像素的模型表现出强大性能。LCMs [38]专注于蒸馏潜在扩散模型,并在4个采样步骤上取得了令人印象深刻的性能。最近,LCM-LoRA [40]引入了一种低秩适应[22]训练,以有效学习LCM模块,可以插入到不同的SD和SDXL [50, 54]的检查点中。InstaFlow [36]提出使用矫正流[35]来促进更好的蒸馏过程。
所有这些方法都共享共同的缺陷:**在四个步骤中合成的样本通常看起来模糊,并显示明显的伪像。**在更少的采样步骤中,这个问题会进一步放大。**GANs [14]也可以作为独立的单步模型进行文本到图像合成的训练[25, 59]。它们的采样速度令人印象深刻,但性能落后于基于扩散的模型。**部分原因可以归因于用于稳定对抗目标训练的GAN特定架构的微妙平衡。在不干扰平衡的情况下扩展这些模型并整合神经网络架构的进展是非常具有挑战性的。此外,目前最先进的文本到图像GANs没有类似于扩散模型规模的无分类器引导方法。分数蒸馏采样[51],也被称为分数雅可比链[68],是一种最近提出的方法,旨在将基础T2I模型的知识蒸馏到3D合成模型中。尽管大多数基于SDS的工作[45, 51, 68, 69]在上下文是图像编辑[16]。
最近,[13]的作者展示了基于分数的模型与GANs之间的强关系,并提出了Score GANs,这些GANs是使用来自扩散模型的基于分数的扩散流进行训练的,而不是使用鉴别器。类似地,Diff-Instruct [42]是一种泛化SDS的方法,可以将预训练的扩散模型蒸馏成一个没有鉴别器的生成器。
相反,还有一些方法旨在通过对抗性训练来改进扩散过程。为了实现更快的采样,Denoising Diffusion GANs [70]被引入作为一种能够通过少数步骤进行采样的方法。为了提高质量,在Adversarial Score Matching [24]中,将鉴别器损失添加到分数匹配目标中,而在CTM [29]的一致性目标中添加了一致性目标。
我们的方法结合了对抗性训练和分数蒸馏,形成了一个混合目标,以解决当前表现最佳的少步生成模型存在的问题。
- 方法
我们的目标是在尽可能少的采样步骤中生成高保真度的样本,同时匹配最先进的模型的质量[7, 50, 53, 55]。对抗目标[14, 60]自然地适用于快速生成,因为它训练一个能够在单个前向步骤中输出图像流形上的样本的模型。然而,将GANs扩展到大型数据集的尝试[58, 59]观察到,不仅仅依赖于鉴别器,还要使用预训练的分类器或CLIP网络来改善文本对齐至关重要。正如在[59]中所指出的,过度使用判别网络会引入伪像,影响图像质量。相反,我们利用预训练扩散模型的梯度通过分数蒸馏目标来改善文本对齐,并在推理期间生成纯噪声。
对于对抗目标,生成的样本xˆθ和真实图像x0被传递给鉴别器,鉴别器的目标是区分它们。鉴别器的设计和对抗性损失的详细描述在第3.2节中。为了从DM教师中提取知识,我们将学生样本xˆθ通过教师的前向过程扩散到xˆθ,t,并使用教师的降噪预测xˆψ(xˆθ,t, t)作为分数蒸馏损失Ldistill的重建目标,详见第3.3节。
略
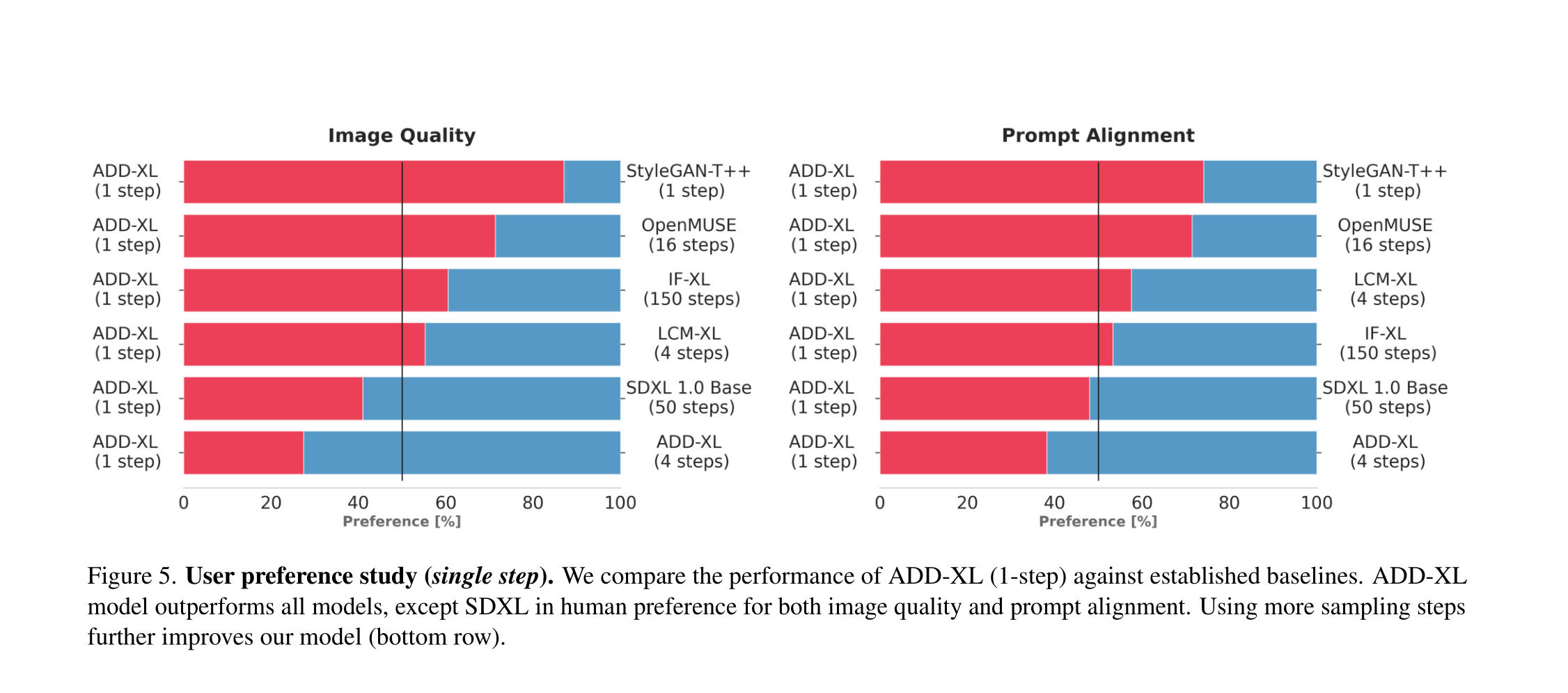
看下图 ADD-XL这一步法看起来确实牛。

- 实验
在我们的实验中,我们训练了两个不同容量的模型,ADD-M(860M参数)和ADD-XL(3.1B参数)。对于对ADD-M进行消融实验,我们使用了稳定扩散(SD)2.1骨干[54],为了与其他基线进行公平比较,我们使用了SD1.5。ADD-XL利用了SDXL [50]骨干。所有实验都在标准分辨率512x512像素下进行;生成更高分辨率的模型的输出被降采样到这个大小。
我们在所有实验中使用了蒸馏权重因子 λ = 2.5。此外,R1惩罚强度 γ 设置为10^−5。对于鉴别器的条件,我们使用预训练的CLIP-ViT-g-14文本编码器[52]来计算文本嵌入 ctext,以及DINOv2 ViT-L编码器[47]的CLS嵌入来计算图像嵌入 cimg。对于基线,我们使用了最好的公开可用模型:潜在扩散模型[50, 54](SD1.5 1,SDXL 2),级联像素扩散模型[55](IF-XL 3),蒸馏扩散模型[39, 41](LCM-1.5,LCM-1.5-XL 4),以及OpenMUSE[48],MUSE[6]的重新实现,这是专门为快速推理开发的变压器模型。请注意,我们将其与SDXL-Base-1.0模型进行比较,没有其额外的细化模型;这是为了确保公平比较。由于没有公开的最先进GAN模型,我们使用改进的鉴别器重新训练StyleGAN-T [59]。这个基线(StyleGAN-T++)在FID和CS方面明显优于以前最好的GANs,详见附录。我们通过FID [18]量化样本质量,通过CLIP分数 [17]量化文本对齐。对于CLIP分数,我们使用在LAION-2B [61]上训练的ViT-g-14模型。这两个指标都在来自COCO2017 [34]的5k个样本上进行评估。
4.1 消融研究
我们的训练设置在对抗性损失、蒸馏损失、初始化和损失相互作用方面打开了许多设计空间。我们在表1中对几个选择进行了消融研究;每个表格下面都强调了一些关键的见解。我们将在接下来讨论每个实验。
鉴别器特征网络(表1a)。最近Stein等人的研究[67]表明,使用CLIP [52]或DINO [5, 47]目标训练的ViTs特别适用于评估生成模型的性能。同样,这些模型似乎也有效作为鉴别器特征网络,其中DINOv2成为最佳选择。
鉴别器条件(表1b)。与先前的研究类似,我们观察到鉴别器的文本条件会增强结果。值得注意的是,图像条件优于文本条件,同时使用ctext和cimg的组合产生最佳结果。
学生预训练(表1c)。我们的实验表明,预训练ADD-student的重要性。能够使用预训练的生成器是纯GAN方法的重要优势。GAN的一个问题是缺乏可扩展性;Sauer等人[59]和Kang等人[25]观察到,在达到一定网络容量后,性能会出现饱和。这一观察与DMs的一般平稳缩放规律形成对比[49]。然而,ADD可以有效利用更大的预训练DMs(见表1c),并受益于稳定的DM预训练。
损失项(表1d)。我们发现两种损失都是必不可少的。蒸馏损失本身并不有效,但与对抗性损失结合时,结果明显改善。不同的权重计划导致不同的行为,指数计划倾向于产生更多样化的样本,如FID较低所示,SDS和NFSD计划改善了质量和文本对齐。虽然在所有其他消融中我们都将指数计划作为默认设置,但我们选择了NFSD权重来训练我们的最终模型。选择最佳权重函数提供了改进的机会。另外,考虑在训练过程中调整蒸馏权重的时间表,正如3D生成建模文献中所探讨的[23],也是一个考虑的选择。
教师类型(表1e)。有趣的是,更大的学生和教师并不一定导致更好的FID和CS。相反,学生会采用教师的特征。SDXL通常获得更高的FID,可能是因为其输出不太多样化,但它展示了更高的图像质量和文本对齐[50]。
教师步骤(表1f)。虽然我们的蒸馏损失公式允许通过构建采用教师的连续步骤,但我们发现多个步骤并不能明确导致更好的性能。
4.2 与最先进技术的定量比较
对于我们与其他方法的主要比较,我们避免使用自动化指标,因为用户偏好研究更可靠[50]。在这项研究中,我们旨在评估提示的遵循和整体图像。作为性能度量,我们计算了成对比较的获胜百分比和比较4.3 定性结果
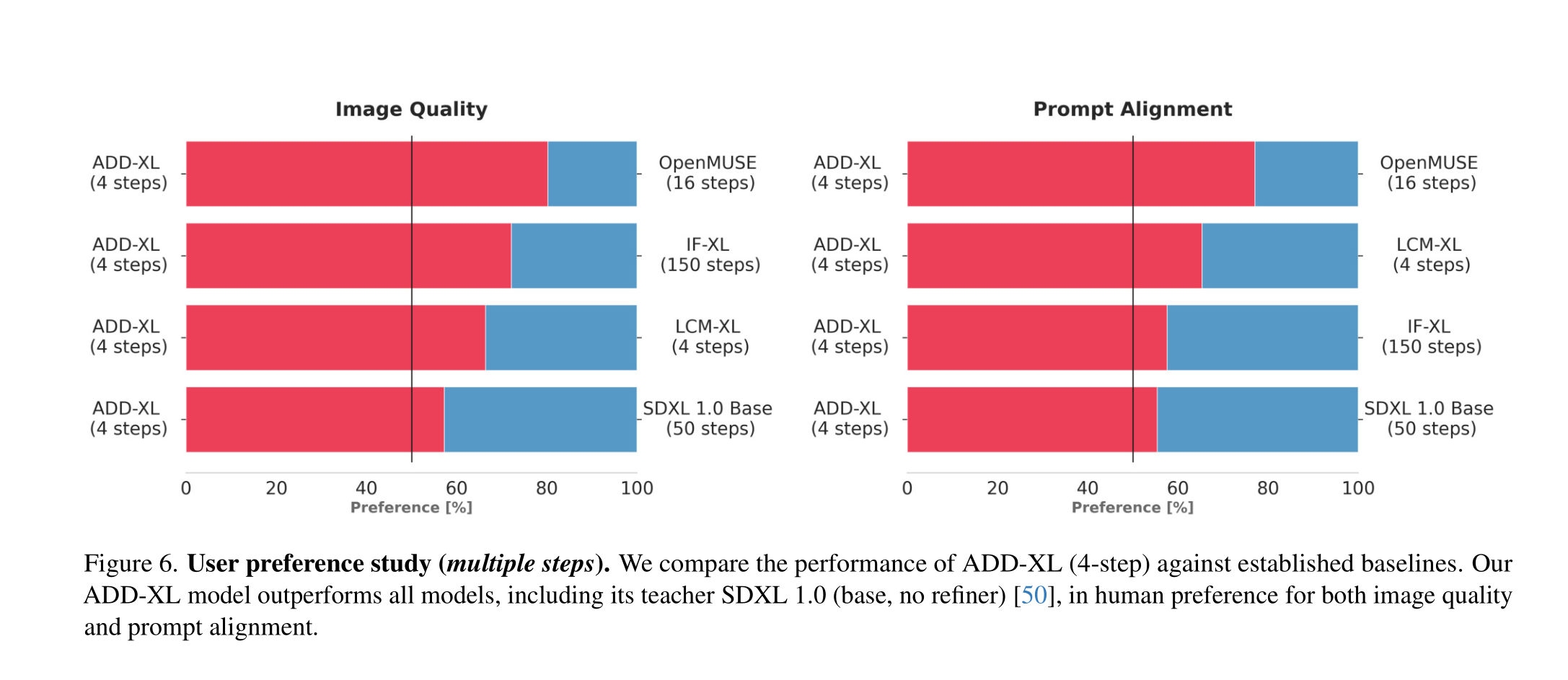
为了补充上述的定量研究,我们在本节中呈现定性结果。为了呈现一个更完整的画面,我们在附录中提供了额外的样本和定性比较。图3比较了ADD-XL(1步)与当前最佳基线在少步骤方案中的效果。图4说明了ADD-XL的迭代采样过程。这些结果展示了我们模型在改善初始样本方面的能力。这种迭代改进代表了与纯GAN方法(如StyleGAN-T++)相比的另一个显著优势。最后,图8直接将ADD-XL与其教师模型SDXL-Base进行了比较。正如在第4.2节的用户研究中所指出的,ADD-XL在质量和提示对齐方面均优于其教师。增强的逼真感是以稍微降低样本多样性为代价的。
- 讨论
本研究介绍了Adversarial Diffusion Distillation,这是一种将预训练扩散模型蒸馏成快速、少步图像生成模型的通用方法。我们结合对抗目标和分数蒸馏目标,对Stable Diffusion [54]和SDXL [50]模型进行蒸馏,通过鉴别器利用真实数据和通过扩散教师利用结构理解。我们的方法在一步或两步的超快速采样方案中表现特别好,我们的分析表明,在这个方案中,它优于所有同时期的方法。此外,我们保留了使用多步骤来细化样本的能力。事实上,使用四个采样步骤,我们的模型胜过了广泛使用的多步生成器,如SDXL、IF和OpenMUSE。
我们的模型使得在单步中生成高质量图像成为可能,为基础模型的实时生成开辟了新的可能性。
使用ADD-XL四步就能更牛:
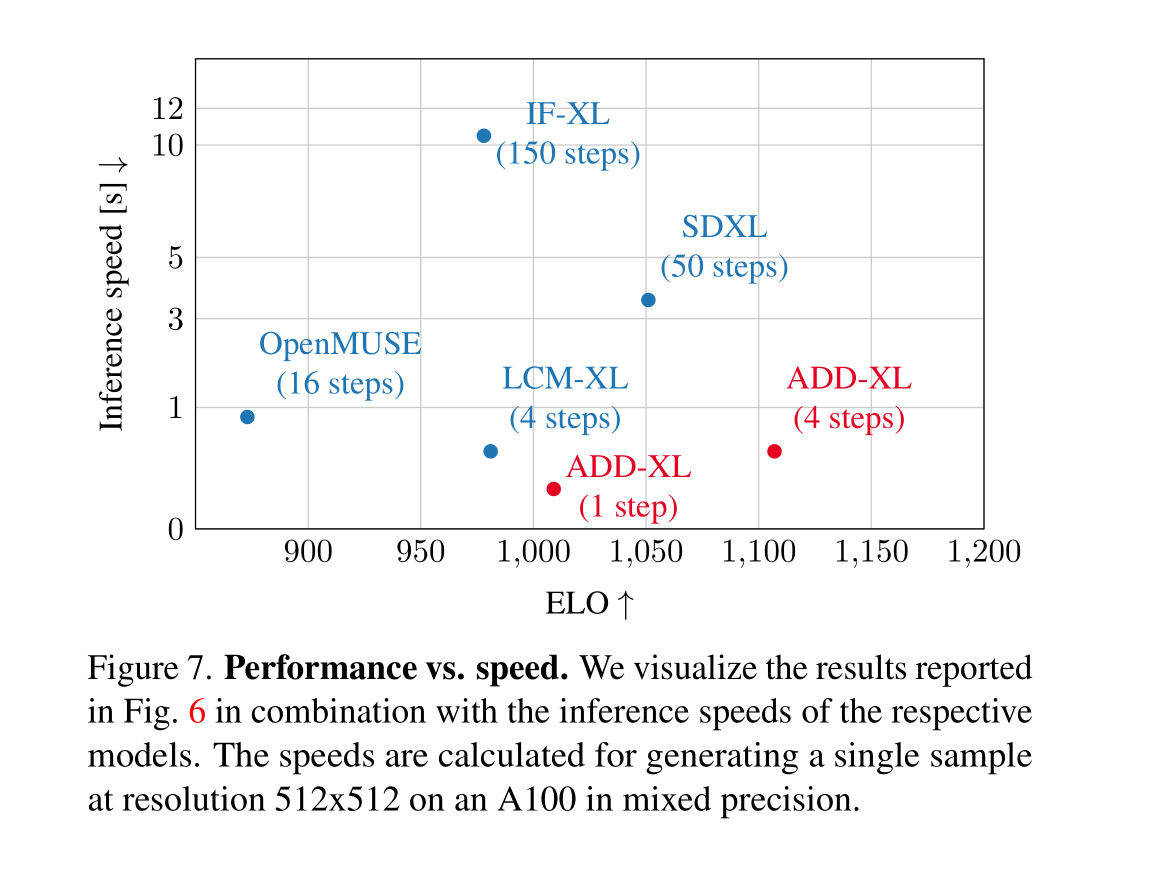
推理速度顶级:
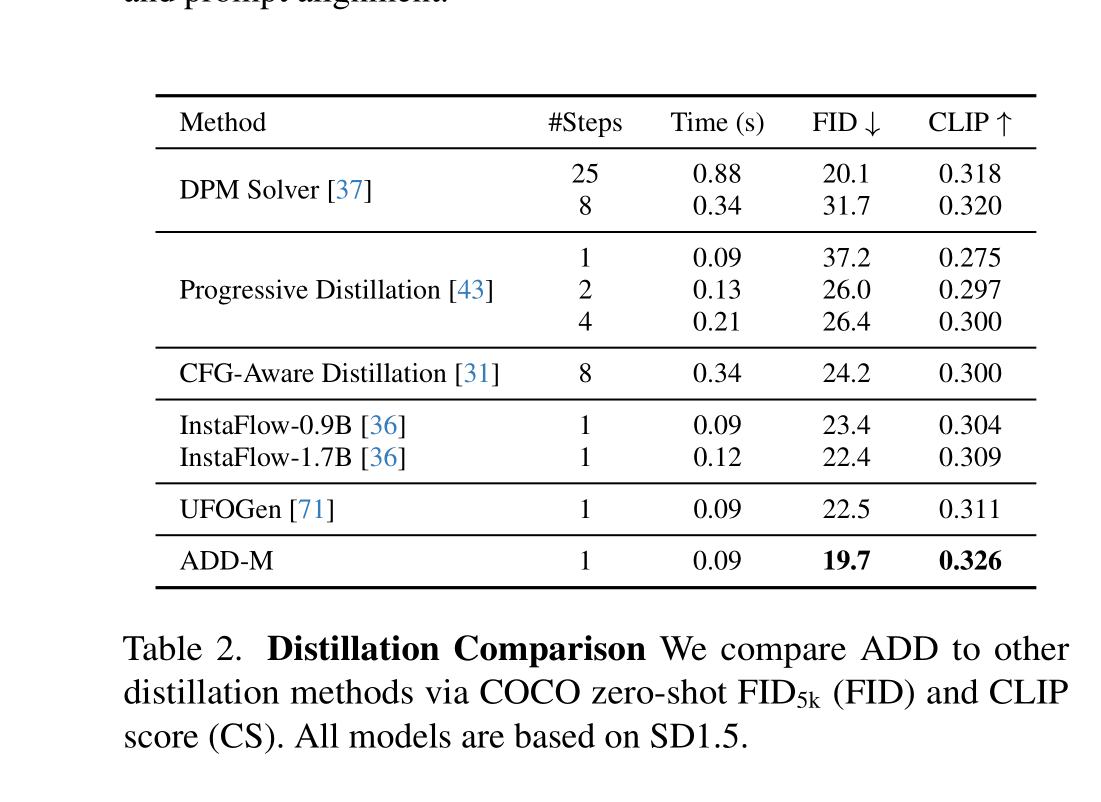
图像质量出色,并且和文本贴合:
一步也不是很差: